Optimizing Data Analytics with AWS Athena: A Step-by-Step Guide
 Akshada Kakde
Akshada Kakde
Introduction
Amazon Athena is an interactive query service that you can use to analyze the data present in Amazon S3 Bucket. Data can be queried using standard SQL. You can quickly query large datasets stored in S3 without the need for complex data pipeline setups.
Why Use Athena?
Serverless: No infrastructure management is required. You can start querying data instantly.
Cost-Effective: You only pay for the queries you run, and the pricing is based on the amount of data scanned by each query.
Scalability: Athena scales automatically and can handle large datasets.
Integration: It integrates seamlessly with AWS Glue, making it easy to catalog and query data.
Standard SQL: Use SQL queries to interact with your data.
Step-by-Step Guide
Step 1: Prepare Your Data
You need to have your data stored in Amazon S3. Ensure that your data is in a format supported by Athena, such as CSV, JSON, Parquet, Avro etc.
In this guide we are going ahead with CSV File Format.
Alice,30,OpenAI,California,San Francisco
Bob,25,Amazon,Washington,Seattle
Charlie,28,Google,California,Mountain View
Diana,32,Microsoft,Washington,Redmond
Eve,29,Facebook,California,Menlo Park
Frank,27,Netflix,California,Los Gatos
Grace,31,Apple,California,Cupertino
Hank,26,Uber,California,San Francisco
Ivy,33,Salesforce,California,San Francisco
Jack,24,Twitter,California,San Francisco
- Save the above sample data as sampledata.csv
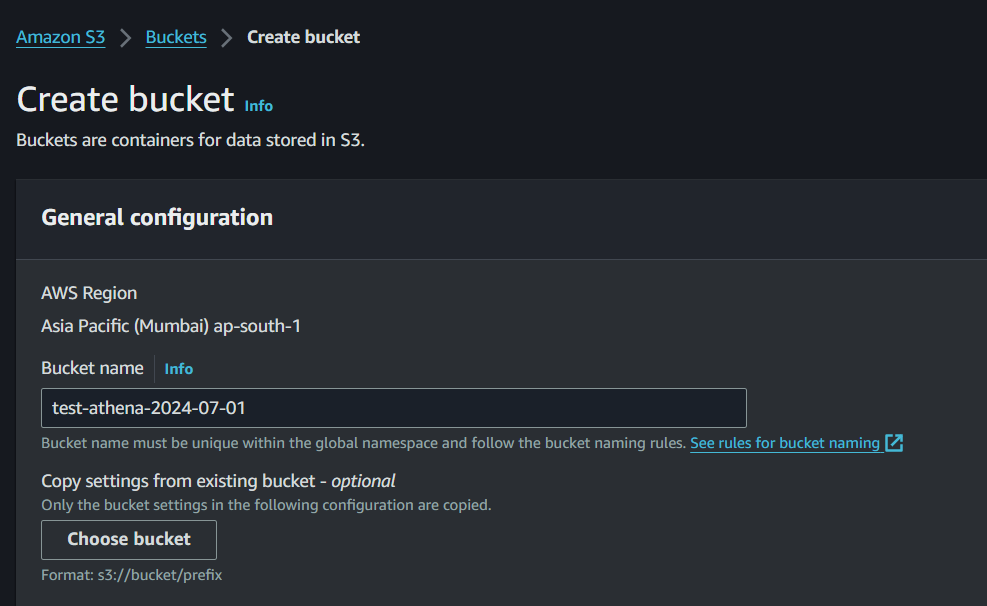
Step 2: Set Up an S3 Bucket
Create an S3 bucket:
Go to the S3 console.
Click on “Create bucket”
Enter a unique bucket name and select a region
Click “Create bucket”
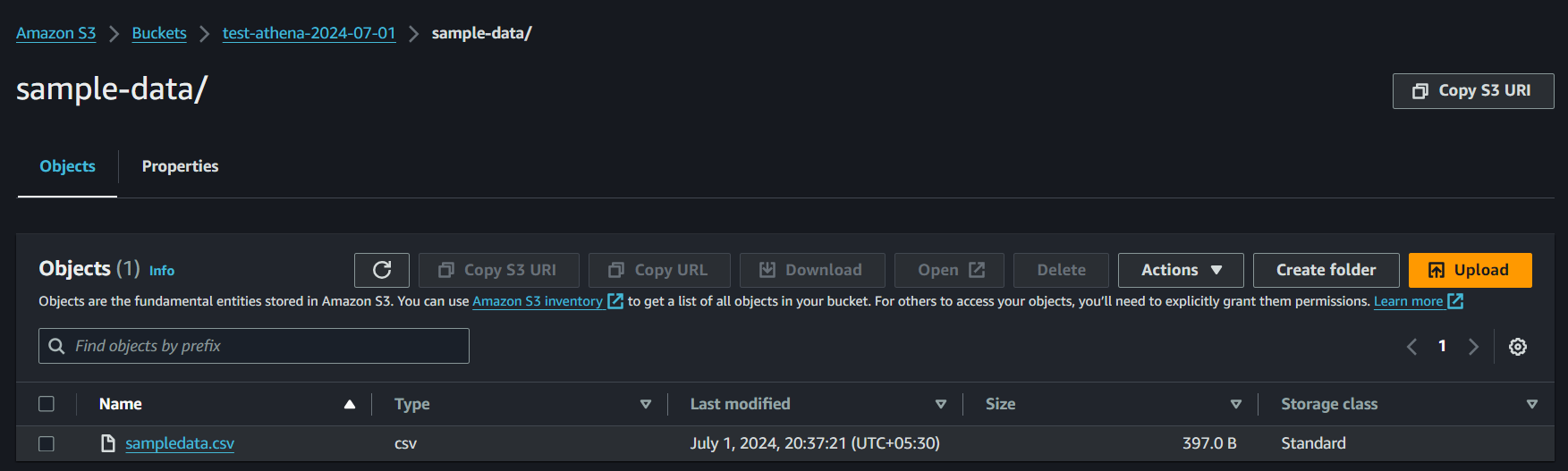
Upload your data:
Click on your newly created bucket.
Create folder sample-data
Upload sampledata.csv inside sample-data folder
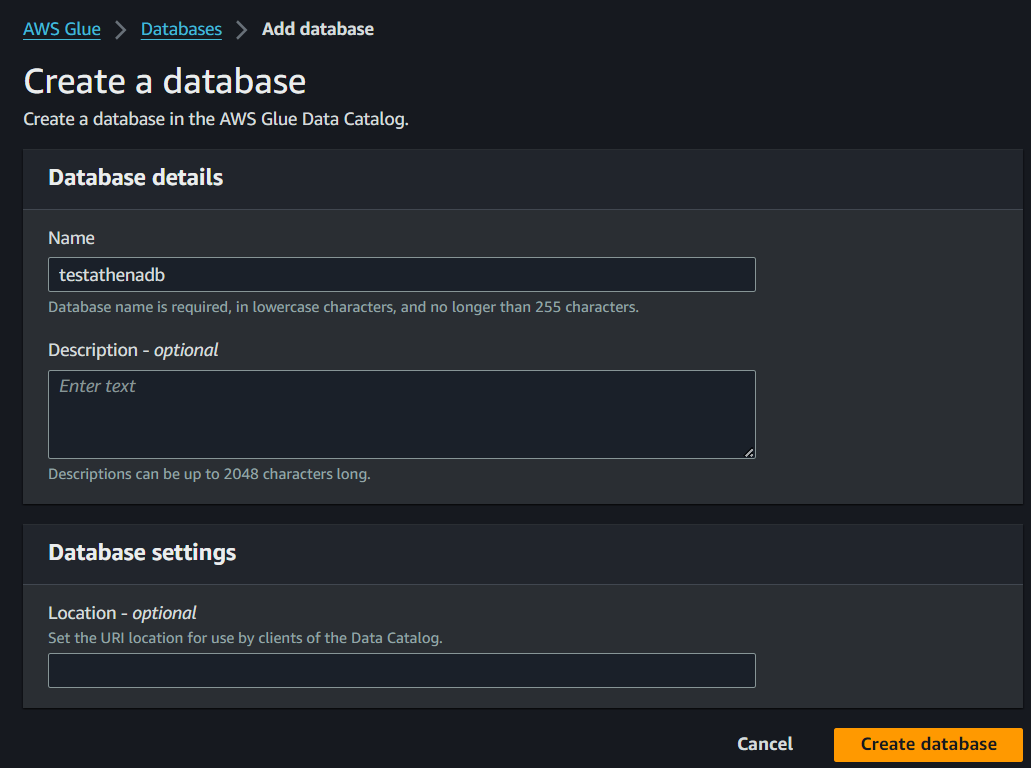
Step 3: Create Database
Open AWS Glue Console
In the left navigation pane, click on “Databases” and then “Add database”
Enter a name for your database (testathenadb) and click “Create database”
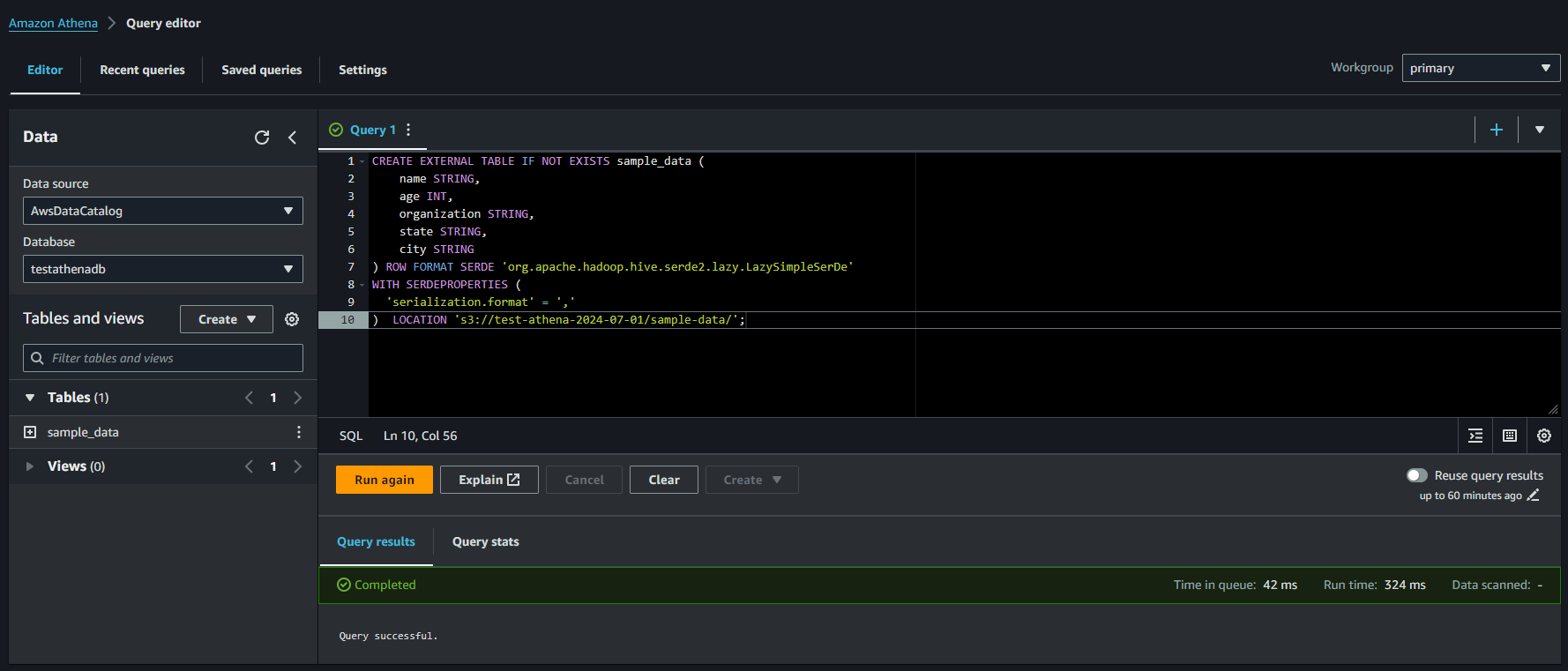
Step 4: Create Table in Athena
Open Athena Console
Select your Database
Inside Query Editor, create a table using the following SQL statement. Adjust the S3 path and columns according to your data
CREATE EXTERNAL TABLE IF NOT EXISTS sample_data (
name STRING,
age INT,
organization STRING,
state STRING,
city STRING
) ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = ','
) LOCATION 's3://test-athena-2024-07-01/sample-data/';
- Alternatively, we can also create the above table using AWS Glue Service
Step 5: Store Query Result in S3
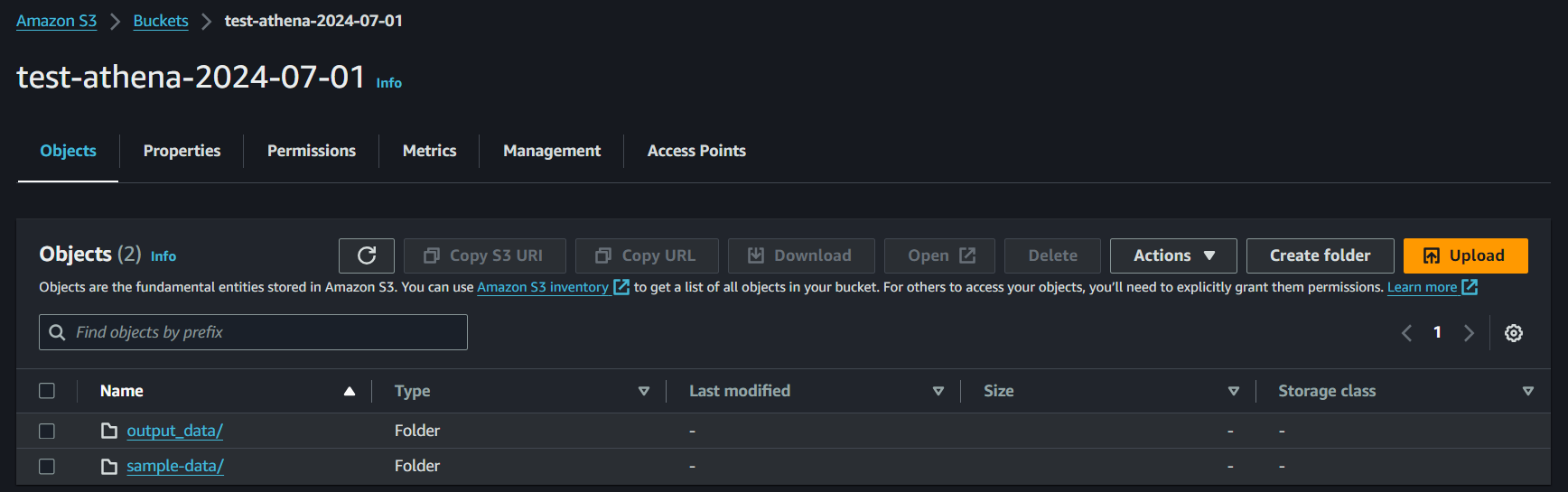
Go to S3 Bucket created in Step 2 (test-athena-2024-07-01)
Create a folder (output_data) inside the bucket
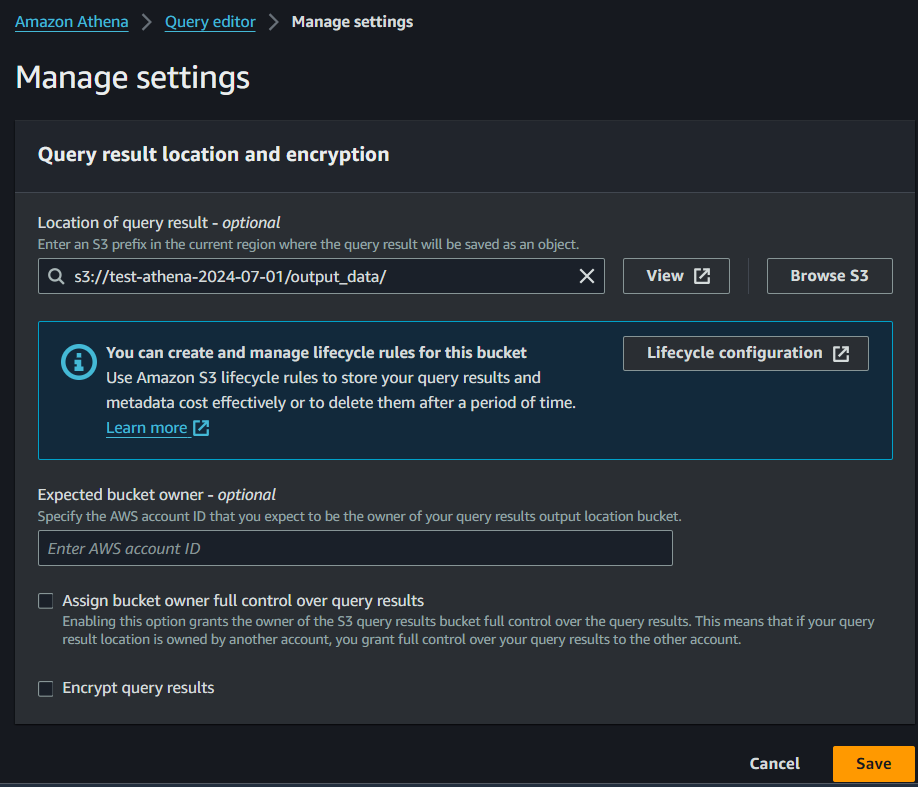
Go to Athena Console query editor
Click on “Settings” and then "Manage"
Set the S3 bucket path (s3://test-athena-2024-07-01/output_data/) where your query results will be stored.
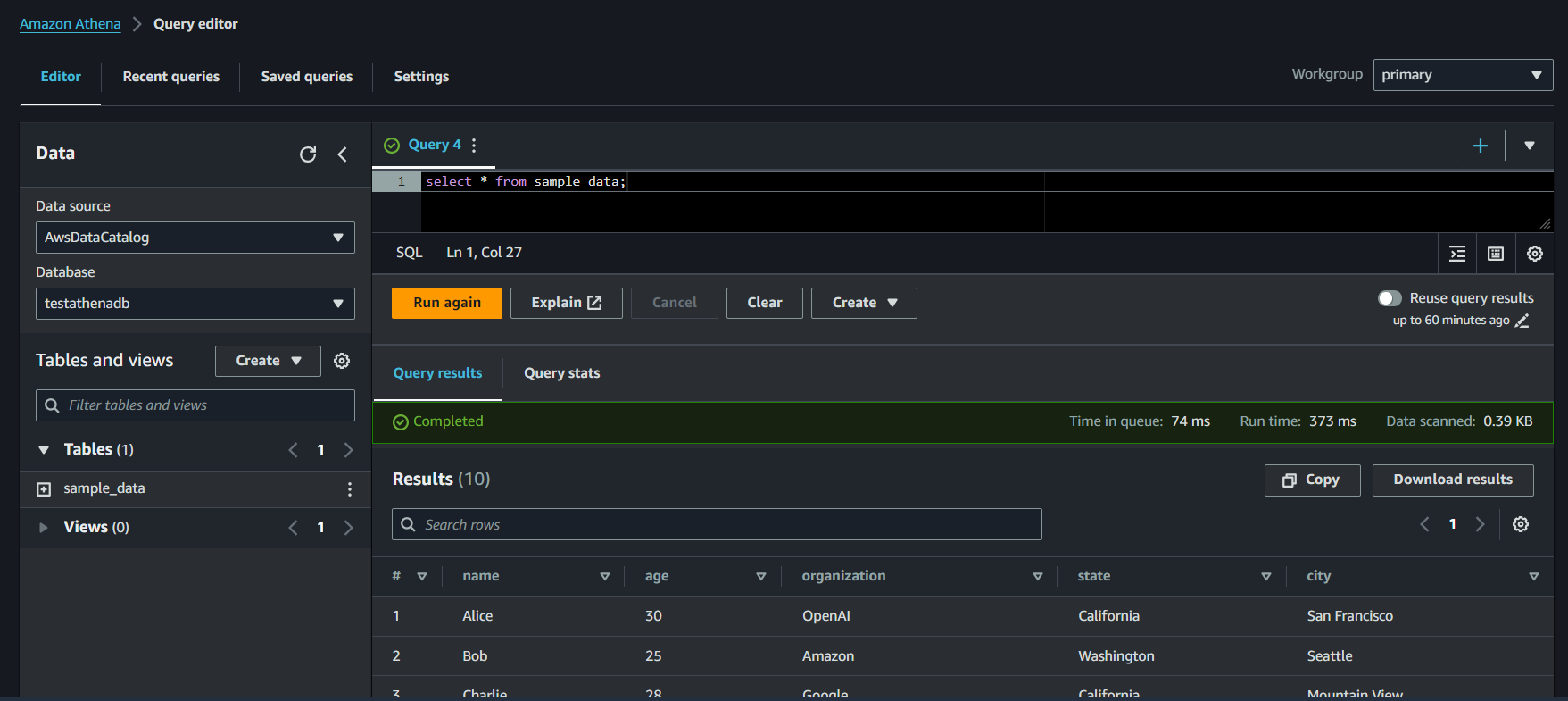
Step 6: Analyzing S3 Data
Enter a SQL query in the query editor by selecting proper Database
select * from sample_data;Execution of the query should give the following result
You can also download the results in CSV format
Conclusion
Amazon Athena is a tool for analyzing data stored in S3 using standard SQL. Its serverless architecture, cost-effectiveness and scalability make it an excellent choice for running quick and ad-hoc queries on large datasets. By integrating with AWS Glue, it simplifies data cataloging and querying processes thus allowing you to focus on extracting valuable insights from your data.
Using Athena, you can quickly turn your raw data into actionable information without the overhead of managing servers or complex ETL processes. Whether you're a data analyst, developer, or solution architect, Athena can help you streamline your data analysis workflow and make more informed decisions.
Subscribe to my newsletter
Read articles from Akshada Kakde directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by