Leveraging Codebase Knowledge Graphs for Agentic Code Generation
 Dhiren Mathur
Dhiren Mathur
An agent generating code with language models can face several challenges without sufficient context about the codebase:
Duplicating functionality due to lack of awareness of existing functions and classes
Violating design patterns and architectures, such as directly querying the database instead of using a repository pattern
Incorrectly using new libraries and frameworks due to knowledge gap.
Misaligning with business requirements and not fulfilling intended use cases due to lack of context
Unable to integrate with existing data models and schemas, leading to duplicate fields and data inconsistencies
This article presents an approach for providing complete codebase context to a ReAct agent by:
Mapping function call relationship graphs in a graph database, detecting entry points into the server.
Fetching relevant code at runtime along with file paths
Generating function and entry point level explanations for the corresponding flows for every entry point.
Serving the explanations and metadata through a vector database that the agent can query with natural language
Alternative systems we experimented with:
Iterative mapping of function > class > file relationships such that the RAG system has the data about every function, class, file and can provide much more specific answers.
The cons associated with this approach were that:
- It was slow
- It was expensive
- Caused us to hit rate limits on larger repositoriesFor a use case which only involves understanding existing flows to derive context from them, moving to a system where we generate a flow level inference both for constituting functions of that flow and an overall intent of the flow provided the perfect trade-off between time, cost and quality.
System Architecture:
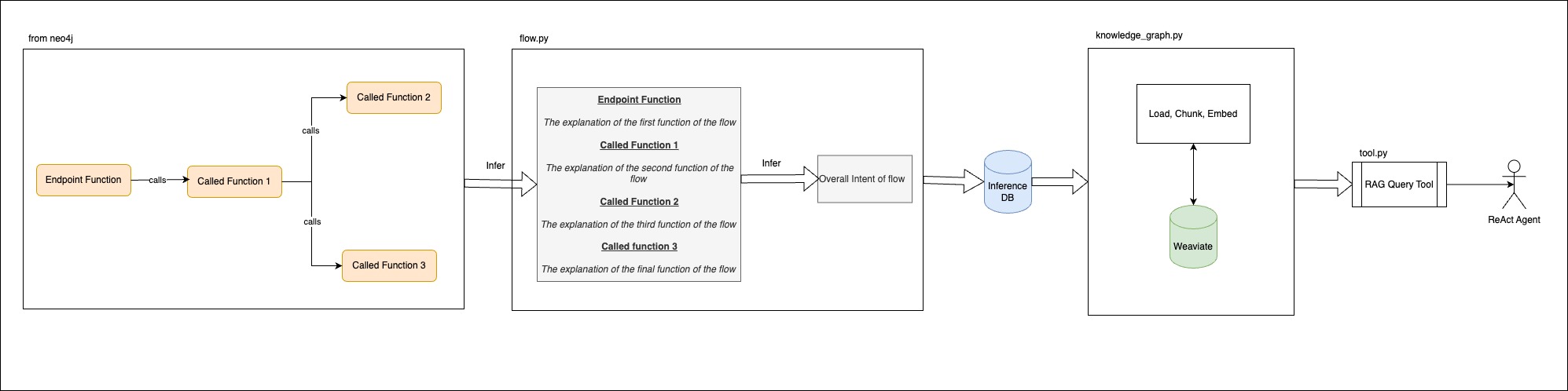
Key components:
Graph database (Neo4j) stores nodes representing functions and edges representing call relationships
Postgres database:
Endpoints table with API paths and identifiers
Inferences table with intent extracted from explanations
Explanations table with natural language descriptions of functions
Pydantic table with data model definitions
Relevant python services:
These services are part of the broader getmomentum/momentum-core project that is a code behaviour auditor which aims at analysing code behaviours at every git push.flow.py: Traverses full project graph to generate explanations for each entry point upfront
knowledge_graph.py: Loads Postgres data into a vector database and provides method to query it.
tools.py: Defines Langchain tools to fetch code, Pydantic definitions, query the knowledge graph. These tools will be used by code generation agents to gather pointed context.
Flow for Generating Complete Code Context
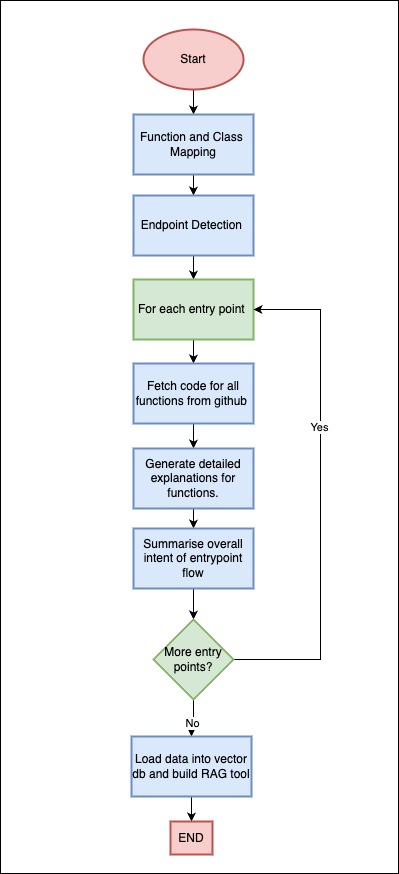
In a processing step, flow.py is triggered for the entire project codebase right after parsing and endpoint detection is completed.
It captures all the functions, classes, entry points defined in the system.
For each entry point:
It fetches the code for all functions in the flow from GitHub (we do not want to store code in our db.)
It generates detailed natural language explanations of each function in the flow, capturing input, response, business logic, exceptions.
It summarizes the overall intent of the endpoint from the function explanations. This is a single line statement of purpose of each API.
The endpoint paths, inferred intents, function explanations, and Pydantic models are loaded into the vector DB. We are using Weaviate as our vector DB of choice.
To load this data into Weaviate and query it, ideally, we would chunk, embed, set overlap, define query algorithm etc but for simplicity, here we use Embedchain to build the RAG tool.
When a user requests code generation for a specific entry point:
The ReAct agent uses tools to:
Directly fetch relevant code and Pydantic definitions for that entry point
Query the vector DB with natural language to retrieve explanations and metadata for that endpoint and its functions
Equipped with granular code and high-level intent, the agent generates the requested code.
Benefits
Providing explanations for the full codebase upfront allows rapidly serving context for any entry point.
Vector search enables dynamically retrieving only the most relevant explanations for the entry point of interest
Having context of other flows helps generate better results. Questions like "How can I create a document" can be answered with a reference to the POST /document/ API and file where it is present. This kind of queries asked by agents can help in tasks like writing a test for a DELETE /document/{id} endpoint that might need to insert a document first.
Conclusion
Mapping full codebases through a lens of entry points in vector databases provides a powerful tool for AI code generation agents
This approach equips language models with broad yet accessible context to generate code that respects the structure and intent of the full system
Techniques like this will be key to enabling agents to program by understanding entire codebases rather than just snippets in isolation
Subscribe to my newsletter
Read articles from Dhiren Mathur directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by