Apache Kafka for DevOps: From Confusion to Confidence - A Beginner's Tutorial
 vikash kumar
vikash kumarTable of contents
- What is Apache Kafka? Understanding Kafka for Microservices
- Why DevOps Engineers Can't Get Enough of Kafka for Real-Time Data Processing
- Rolling Up Our Sleeves: Setting Up a Kafka Cluster with Docker
- Kafka 101: The Crash Course in Kafka Streaming
- Let's Take It for a Spin: Kafka Tutorial for Beginners
- Advanced Kafka Concepts for Handling High Traffic Events
- Wrapping Up Your Apache Kafka Tutorial
- Additional Resources for Your Kafka Journey

Hey there, fellow tech enthusiasts and aspiring DevOps engineers! Pull up a chair, grab your favorite beverage, and let me tell you about my wild ride with Apache Kafka. If you're wondering how to set up Kafka for DevOps or looking for an Apache Kafka tutorial for beginners, you're in the right place. Trust me, if I can wrap my head around this distributed streaming platform, you can too!
What is Apache Kafka? Understanding Kafka for Microservices
Picture this: It's 2 AM, I'm knee-deep in error logs, and my team lead drops the K-bomb. "We need to implement Kafka for our new microservices architecture," he says, casually sipping his fifth espresso. My first thought? "Great, another tech buzzword to add to the pile." Boy, was I wrong!
Apache Kafka, as I've come to learn (and love), is like the world's most efficient post office for data. Imagine if your local post office never closed, could handle millions of packages per second, and never lost a single letter. That's Kafka in a nutshell, and it's a game-changer for Kafka microservices architecture.
Here's the gist of Kafka streaming:
It lets you send and receive streams of data (like our never-ending stream of cat videos on the internet).
It stores these streams reliably (so you never miss a cat video, even if your internet conks out).
It can process these streams as they come in (like automatically tagging those cat videos).
Technical Deep Dive: Kafka Publish-Subscribe Model Explained
For those craving more technical details, here's what's happening under the hood of Apache Kafka:
Publish-Subscribe Model: Kafka uses a publish-subscribe model where data is organized into topics. Producers write data to topics, and consumers read from topics.
Distributed System: Kafka is designed as a distributed system, allowing it to scale horizontally across multiple servers or clusters.
Log-Based Approach: At its core, Kafka treats all data as logs - append-only, totally ordered sequence of records.
Retention Policies: Kafka can be configured to retain data for a specified time period or until a certain storage limit is reached.
Exactly-Once Semantics: Kafka provides exactly-once processing semantics, ensuring data integrity in stream processing applications.
Why DevOps Engineers Can't Get Enough of Kafka for Real-Time Data Processing
Look, I'm not gonna lie – when I first started with Kafka, I was ready to pull my hair out. But once I got the hang of it, I realized why so many DevOps engineers swear by it for handling high traffic events:
It's a scaling beast: Kafka laughs in the face of millions of messages per second. I've seen it handle Black Friday traffic without breaking a sweat.
It's like a faithful puppy: Always there, always reliable. Even when servers go down, Kafka keeps your data safe and sound.
It's faster than my caffeine-fueled coding sessions: Real-time processing? Check. Low latency? Double-check.
It plays nice with others: Kafka integrates with pretty much everything. It's like that one friend who gets along with everyone at the party.
Decoupling of Data Streams: Kafka allows for complete decoupling of data streams from core applications, making it easier to evolve your system over time.
Rolling Up Our Sleeves: Setting Up a Kafka Cluster with Docker
Alright, enough chit-chat. Let's get our hands dirty and set up a Kafka cluster on your machine using Docker. Don't worry, I promise this Kafka Docker Compose setup is easier than assembling IKEA furniture.
What You'll Need for Your Kafka Docker Setup
Docker and Docker Compose (if you don't have these, go grab 'em – I'll wait)
A basic understanding of YAML (don't worry, it's not as scary as it sounds)
A terminal/command prompt (and the courage to use it)
Step 1: The Magical Docker Compose File for Kafka
First things first, we need to create a docker-compose.yml file. This is like the recipe for our Kafka cluster. Here's what mine looks like:
version: '3.7'
services:
zookeeper:
image: zookeeper:latest
container_name: zookeeper
networks:
- kafkasinglenodecluster
environment:
ZOOKEEPER_CLIENT_PORT: 2181
ZOOKEEPER_TICK_TIME: 2000
ports:
- "2181:2181"
volumes:
- ./zookeeper-data:/var/lib/zookeeper/data
restart: always
kafka1:
image: confluentinc/cp-kafka:latest
container_name: kafka1
networks:
- kafkasinglenodecluster
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 1
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9092
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LOG_SEGMENT_BYTES: 1073741824 # 1 GB
KAFKA_LOG_RETENTION_BYTES: -1 # Unlimited retention by size
KAFKA_LOG_RETENTION_MS: 604800000 # 1 week
KAFKA_HEAP_OPTS: "-Xmx2G" # Set max heap size to 2 GB
ports:
- "9092:9092"
volumes:
- ./kafka1-data:/var/lib/kafka/data
restart: always
kafka2:
image: confluentinc/cp-kafka:latest
container_name: kafka2
networks:
- kafkasinglenodecluster
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 2
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9093
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LOG_SEGMENT_BYTES: 1073741824
KAFKA_LOG_RETENTION_BYTES: -1
KAFKA_LOG_RETENTION_MS: 604800000
KAFKA_HEAP_OPTS: "-Xmx2G"
ports:
- "9093:9093"
volumes:
- ./kafka2-data:/var/lib/kafka/data
restart: always
kafka3:
image: confluentinc/cp-kafka:latest
container_name: kafka3
networks:
- kafkasinglenodecluster
depends_on:
- zookeeper
environment:
KAFKA_BROKER_ID: 3
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9094
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://localhost:9094
KAFKA_ZOOKEEPER_CONNECT: "zookeeper:2181"
KAFKA_LOG_SEGMENT_BYTES: 1073741824
KAFKA_LOG_RETENTION_BYTES: -1
KAFKA_LOG_RETENTION_MS: 604800000
KAFKA_HEAP_OPTS: "-Xmx2G"
ports:
- "9094:9094"
volumes:
- ./kafka3-data:/var/lib/kafka/data
restart: always
kafdrop:
image: obsidiandynamics/kafdrop:latest
container_name: kafdrop
networks:
- kafkasinglenodecluster
environment:
KAFKA_BROKERCONNECT: "kafka1:9092,kafka2:9093,kafka3:9094"
ports:
- "9000:9000"
restart: always
networks:
kafkasinglenodecluster:
driver: bridge
Don't let this wall of text intimidate you. It's just telling Docker how to set up our Kafka playground.
Step 2: Understanding Kafka Brokers and Partitions
Let's break this down into bite-sized pieces:
Zookeeper: Think of this as the wise old owl of our Kafka forest. It keeps everything in check. Kafka Zookeeper configuration is crucial for maintaining cluster state.
Kafka Brokers: We're setting up three of these bad boys (kafka1, kafka2, kafka3). Why three? Because good things come in threes, and it gives us some nice redundancy. These Kafka brokers are the backbone of our cluster.
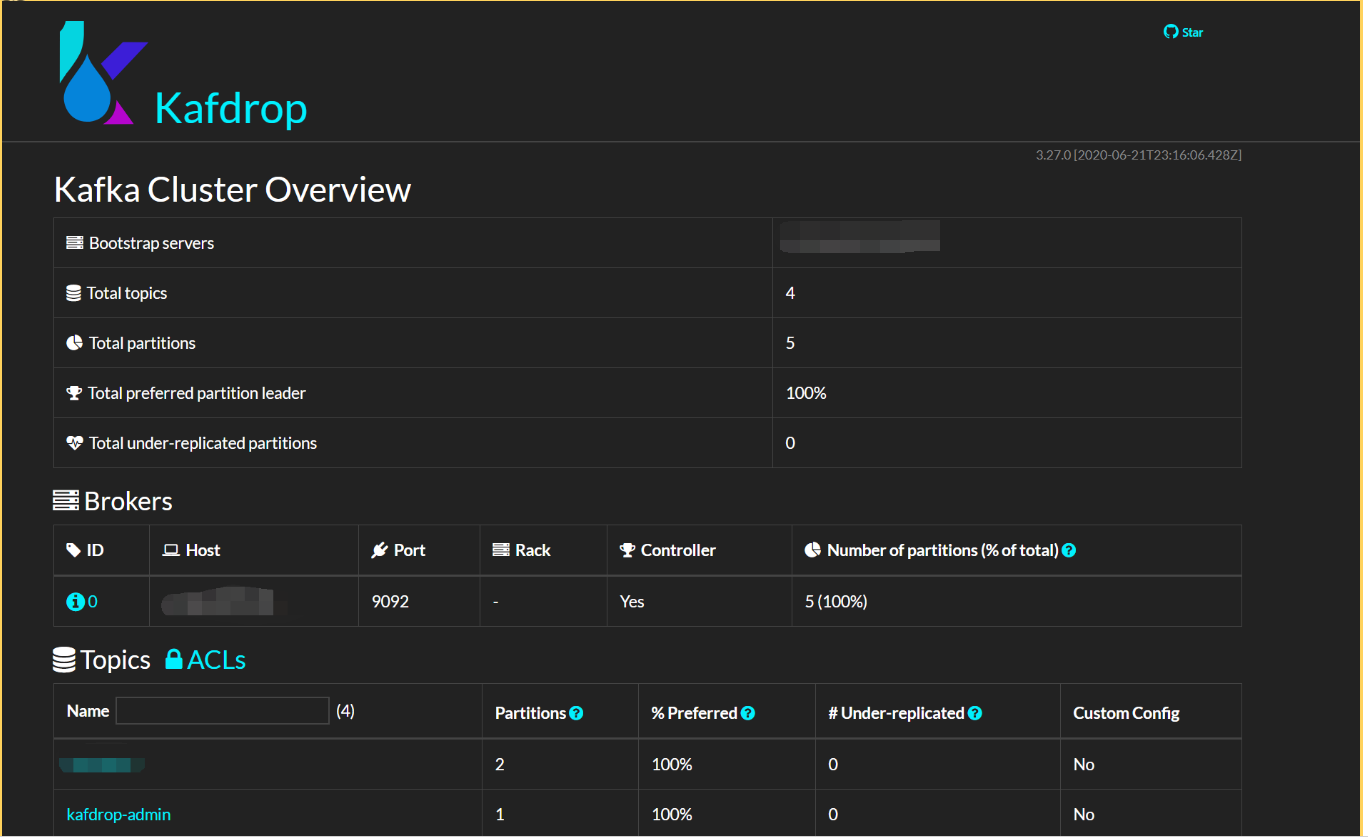
Kafdrop: This is our window into the Kafka world. It's a web UI that lets us peek at what's going on inside our cluster.
Networking: We're putting all these containers in the same sandbox so they can play nicely together.
Volumes: This is where we store our data. Think of it as Kafka's journal – it keeps track of everything, even if we turn it off and on again.
Step 3: Bringing Our Kafka Cluster to Life
Open up your terminal (don't be scared, it doesn't bite), navigate to where you saved that docker-compose.yml file, and type:
docker-compose up -d
Now sit back and watch the magic happen. This command is basically telling Docker, "Hey, build me this Kafka thing I described, and do it in the background so I can keep using my terminal."
Step 4: Verifying Your Kafka Setup
Let's make sure everything's up and running:
Check on our containers:
docker-compose psYou should see all our services chillin' in the "Up" state.
Let's peek at Kafdrop: Fire up your browser and go to
http://localhost:9000. If you see a page with a bunch of Kafka info, congratulations! You're now a Kafka wrangler!
Kafka 101: The Crash Course in Kafka Streaming
Now that we've got our Kafka cluster purring like a kitten, let's talk about what makes it tick:
Topics: These are like channels on your TV. You tune into the ones you want.
Partitions: Imagine slicing a pizza. Topics are divided into partitions so many people can grab a slice at once.
Producers: These are the chefs making the pizza (or in our case, creating the data).
Consumers: These are the hungry folks eating the pizza (reading the data).
Brokers: Our three Kafka containers. They're like the pizza delivery guys, making sure the pizza gets where it needs to go.
Zookeeper: The restaurant manager, keeping everything running smoothly.
Here's a simple diagram to visualize how these components interact in Kafka streaming:
[Producer] -> [Topic (Partition 1, Partition 2, ...)] -> [Consumer]
^
|
[Broker 1, Broker 2, Broker 3]
^
|
[Zookeeper]
Let's Take It for a Spin: Kafka Tutorial for Beginners
Time for the fun part – actually using our Kafka cluster for real-time data processing!
Create a Topic:
docker-compose exec kafka1 kafka-topics --create --topic my-awesome-topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 2We just created a topic called "my-awesome-topic". Feel free to name it whatever you want – "cat-videos", "lunch-orders", you name it!
See What Topics We Have:
docker-compose exec kafka1 kafka-topics --list --bootstrap-server localhost:9092This should show your newly created topic.
Send Some Messages:
docker-compose exec kafka1 kafka-console-producer --topic my-awesome-topic --bootstrap-server localhost:9092Start typing messages and hit Enter after each one. This is you being a producer!
Receive Those Messages: Open a new terminal window and run:
docker-compose exec kafka1 kafka-console-consumer --topic my-awesome-topic --from-beginning --bootstrap-server localhost:9092You should see the messages you sent earlier. You're now a consumer!
Advanced Kafka Concepts for Handling High Traffic Events
For those ready to dive deeper into Kafka for microservices, here are some advanced concepts to explore:
Consumer Groups: Allow you to parallelize consumption of messages from topics.
Partitioning Strategies: Determine how data is distributed across partitions.
Compacted Topics: Special topics that only keep the latest value for each key.
Kafka Connect: A tool for scalably and reliably streaming data between Kafka and other systems.
Kafka Streams: A client library for building applications and microservices that process and analyze data stored in Kafka.
Wrapping Up Your Apache Kafka Tutorial
And there you have it, folks! You've just set up and used your very own Kafka cluster. Pat yourself on the back – you've taken your first step into the larger world of distributed systems and event streaming with Apache Kafka.
Remember, Kafka is like a good cup of coffee – it takes time to appreciate its full flavor. Keep experimenting, keep learning, and before you know it, you'll be the Kafka guru in your office, handling high traffic events like a pro.
Until next time, happy streaming! And remember, when in doubt, just kafka-bout it! (Sorry, couldn't resist the pun.)
Additional Resources for Your Kafka Journey
To continue your Kafka adventure, check out these resources:
Kafka: The Definitive Guide by Neha Narkhede, Gwen Shapira, and Todd Palino
Happy Kafkaing, and may your streams always flow smoothly!
Subscribe to my newsletter
Read articles from vikash kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
vikash kumar
vikash kumar
Hey folks! 👋 I'm Vikash Kumar, a seasoned DevOps Engineer navigating the thrilling landscapes of DevOps and Cloud ☁️. My passion? Simplifying and automating processes to enhance our tech experiences. By day, I'm a Terraform wizard; by night, a Kubernetes aficionado crafting ingenious solutions with the latest DevOps methodologies 🚀. From troubleshooting deployment snags to orchestrating seamless CI/CD pipelines, I've got your back. Fluent in scripts and infrastructure as code. With AWS ☁️ expertise, I'm your go-to guide in the cloud. And when it comes to monitoring and observability 📊, Prometheus and Grafana are my trusty allies. In the realm of source code management, I'm at ease with GitLab, Bitbucket, and Git. Eager to stay ahead of the curve 📚, I'm committed to exploring the ever-evolving domains of DevOps and Cloud. Let's connect and embark on this journey together! Drop me a line at thenameisvikash@gmail.com.