How AWS Regions and Availability Zones Work
 Nikunj Vaishnav
Nikunj VaishnavTable of contents
Introduction
Welcome to our AWS journey! Today, we’re diving into the basics of AWS’s global infrastructure: Regions and Availability Zones. Understanding these is key for creating reliable, scalable, and highly available applications on AWS. In this blog, we'll cover what Regions and Availability Zones are, how they work, and some best practices for choosing the right region for your needs. We'll also share real-world examples to help illustrate these concepts.
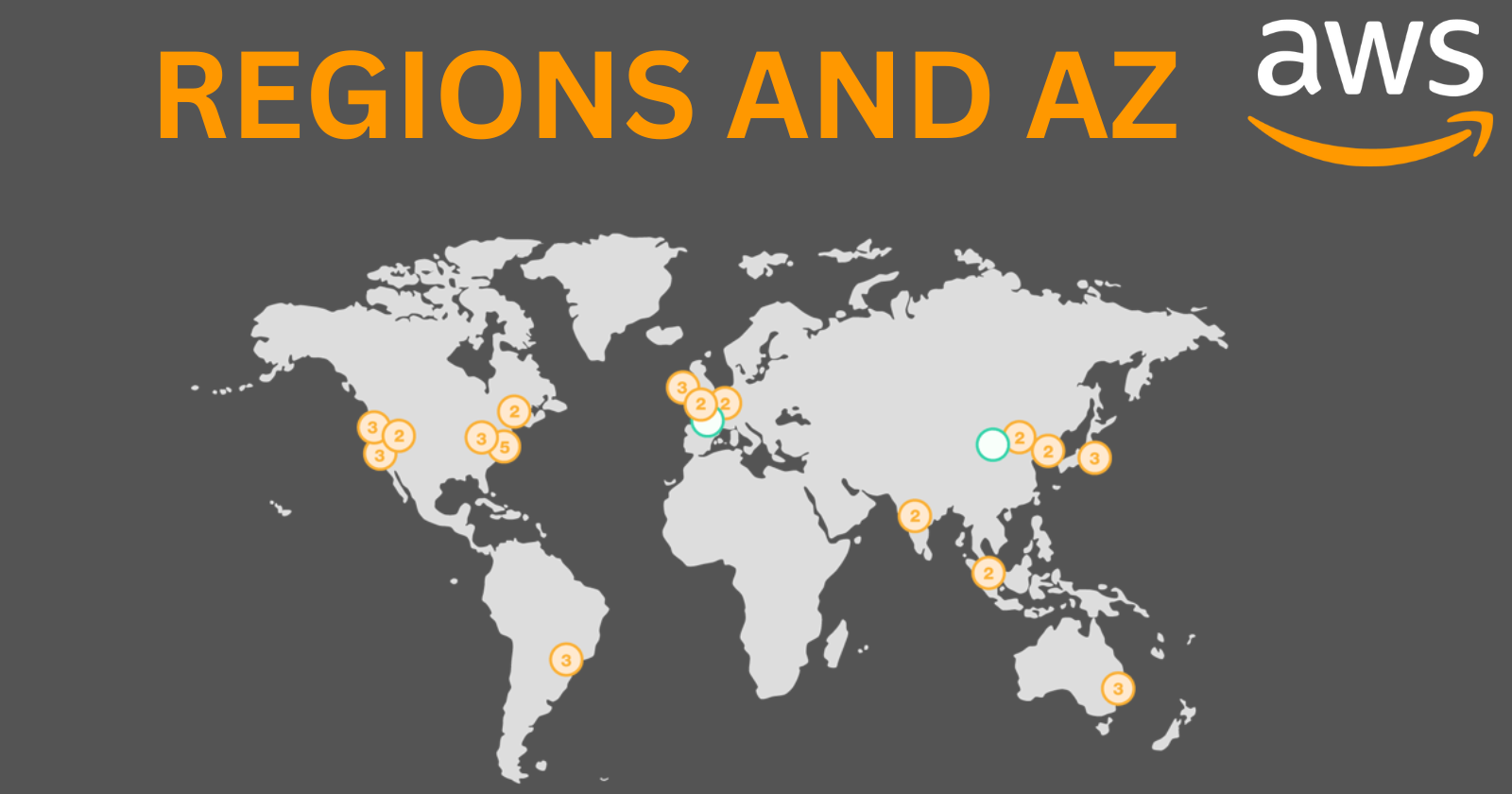
AWS Global Infrastructure Overview
AWS has one of the largest and most dependable cloud infrastructures globally, designed to be highly available, fault-tolerant, and scalable. It includes:
Regions: Geographically distinct locations where AWS clusters data centers.
Availability Zones (AZs): Isolated locations within a region.
Edge Locations: Data centers designed to deliver content to end-users with low latency.
Key Components
Regions: Each AWS region is a separate geographic area. AWS has regions spread worldwide, enabling users to deploy applications and services closer to their customers, reducing latency and improving performance.
Availability Zones: Each region consists of multiple isolated locations known as Availability Zones, designed for high availability and fault tolerance. Each AZ has its own power, cooling, and networking infrastructure.
Edge Locations: Used by services like Amazon CloudFront and AWS Global Accelerator to cache content closer to end-users, reducing latency and improving the user experience.
Understanding AWS Regions
An AWS region is a physical location worldwide where AWS clusters data centers. Each region has multiple, isolated Availability Zones, designed to ensure high fault tolerance and stability.
Examples of AWS Regions:
US East (N. Virginia): Popular for its proximity to many businesses and government institutions.
EU (Frankfurt): Known for strong data privacy and security standards.
Asia Pacific (Mumbai): Offers low latency to users in Japan and surrounding areas.
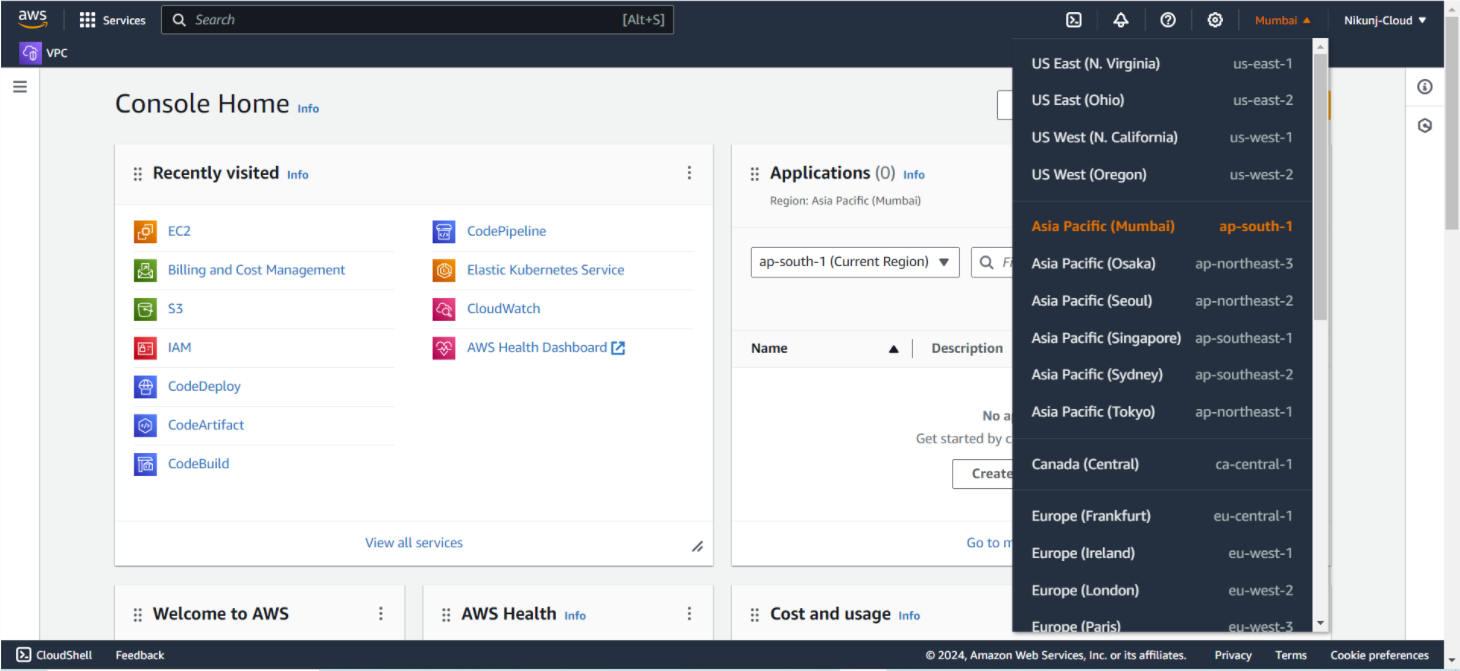
Benefits of Using Multiple Regions:
Geographic Redundancy: Ensures a regional failure doesn't impact global operations.
Improved Latency: Resources closer to end-users reduce latency.
Regulatory Compliance: Meets local data sovereignty laws.
Understanding Availability Zones (AZs)
Definition: An Availability Zone is an isolated location within an AWS region, each with independent power, cooling, and physical security. AZs are connected with low-latency, high-throughput, and highly redundant networking.
Importance of AZs: AZs provide high availability and fault tolerance by isolating failures. Deploying applications across multiple AZs ensures they remain available even if one AZ goes down.
Examples of Using AZs:
Multi-AZ Deployment for High Availability:
Load Balancer: Use an Elastic Load Balancer (ELB) to distribute traffic across multiple EC2 instances in different AZs.
Database Replication: Set up Amazon RDS with Multi-AZ deployment for automatic data replication and seamless failover.
Disaster Recovery:
Cross-AZ Backup: Regularly back up data using AWS Backup or Amazon S3.
Failover Strategy: Configure failover mechanisms using AWS Route 53 and Elastic IPs to redirect traffic to healthy AZs during an outage.
Best Practices for Choosing the Right AWS Region
Latency and Proximity to End Users:
- Deploy close to your primary user base to reduce latency. For example, if most users are in Europe, use the EU (Frankfurt) or EU (Ireland) region.
Regulatory Compliance and Data Residency:
- Ensure your chosen region complies with local regulations. For instance, a healthcare provider in Germany might use the EU (Frankfurt) region for GDPR compliance.
Service Availability:
- Verify that your needed services are available in your chosen region. For example, check if AWS Outposts are available in your region of choice.
Cost Considerations:
- Compare pricing across regions to find the most cost-effective option for your workloads.
High Availability and Fault Tolerance:
- Deploy across multiple regions and AZs for critical applications to ensure high availability.
Disaster Recovery Planning:
- Choose a secondary region that fits your disaster recovery strategy. For instance, a financial firm might select US West (Oregon) for disaster recovery.
Real-World Examples and Case Studies
Netflix: Uses multiple AWS regions for low-latency streaming and high availability, deploying services in regions like US East, US West, and in Europe and Asia-Pacific.
Airbnb: Deploys its services across multiple AZs for scalability and resilience, ensuring high traffic handling and availability during AZ outages.
Samsung: Hosts its SmartThings platform on AWS, choosing regions for compliance with local data protection regulations and performance optimization.
Conclusion
Understanding AWS Regions and Availability Zones is essential for designing robust and scalable cloud architectures. By leveraging AWS’s global infrastructure, you can deploy highly available, fault-tolerant, and performant applications. When selecting an AWS region, consider latency, compliance, service availability, cost, and disaster recovery needs.
In this blog, we explored AWS’s global infrastructure, defined Regions and Availability Zones, and discussed best practices for selecting the right region. Real-world examples highlighted these concepts. Follow these best practices to optimize your AWS deployments and meet your users’ needs.
Stay tuned for more insights and best practices in my upcoming blog posts.
Connect and Follow Me On Socials :
Like👍 | Share📲 | Comment💭
Subscribe to my newsletter
Read articles from Nikunj Vaishnav directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Nikunj Vaishnav
Nikunj Vaishnav
👋 Hi there! I'm Nikunj Vaishnav, a passionate QA engineer Cloud, and DevOps. I thrive on exploring new technologies and sharing my journey through code. From designing cloud infrastructures to ensuring software quality, I'm deeply involved in CI/CD pipelines, automated testing, and containerization with Docker. I'm always eager to grow in the ever-evolving fields of Software Testing, Cloud and DevOps. My goal is to simplify complex concepts, offer practical tips on automation and testing, and inspire others in the tech community. Let's connect, learn, and build high-quality software together! 📝 Check out my blog for tutorials and insights on cloud infrastructure, QA best practices, and DevOps. Feel free to reach out – I’m always open to discussions, collaborations, and feedback!