Understanding Spark Memory Architecture: Best Practices and Tips
 Kiran Reddy
Kiran ReddySpark is an in-memory processing engine where all of the computation that a task does happens in memory. So, it is important to understand Spark Memory Management. This will help us develop Spark applications and perform performance tuning. In Apache Spark, understanding JVM (Java Virtual Machine) process memory is crucial for efficient memory management.
The JVM manages memory for executing Spark applications, and it's divided into several key regions:
Non-JVM Process (Overhead) Memory
Non-JVM overhead memory in Spark is typically calculated as the larger of either 10% of the container memory or 384 MB. This memory is reserved for non-JVM processes and is crucial for the overall stability and performance of Spark applications.
Formula: Non-JVM Overhead Memory = max(10% of Container Memory, 384 MB)
Usage of Non-JVM Overhead Memory:
Container Processes: Memory for basic container management and execution.
Shuffle Exchange: Memory used during the shuffle phase, where data is exchanged between nodes, Includes the buffer space needed for sorting and transferring data between executors.
Internal Usage: Memory required for internal Spark operations, such as maintaining Spark’s internal data structures and metadata, is also used by native libraries and frameworks integrated with Spark.
JVM Process Memory
The JVM process memory in Spark is critical for both the Driver and Executor processes. The Driver, running on the JVM, is responsible for creating the SparkContext, submitting jobs, and transforming them into tasks while coordinating task scheduling among Executors. Executors, also JVM processes, execute specific compute tasks on worker nodes, return results to the Driver, and provide storage for persisted RDDs. Adequate JVM heap memory is crucial for both processes to manage execution plans, task execution, intermediate data, and storage functionality, ensuring efficient task execution and overall application stability.
Whether it's the driver or executor, memory is categorized into two parts: JVM memory and non-JVM memory
The configuration for the driver or executor can be adjusted according to specific requirements and workload characteristics: (here 4GB and 400 MB are just for explanation purposes only)
Driver Configuration
Spark.driver.memory = 4GB
Spark.driver.memoryOverhead = 400MB
Executor Configuration
Spark.executor.memory = 8GB
Spark.executor.memoryOverhead = 800MB
Driver Memory Allocation:
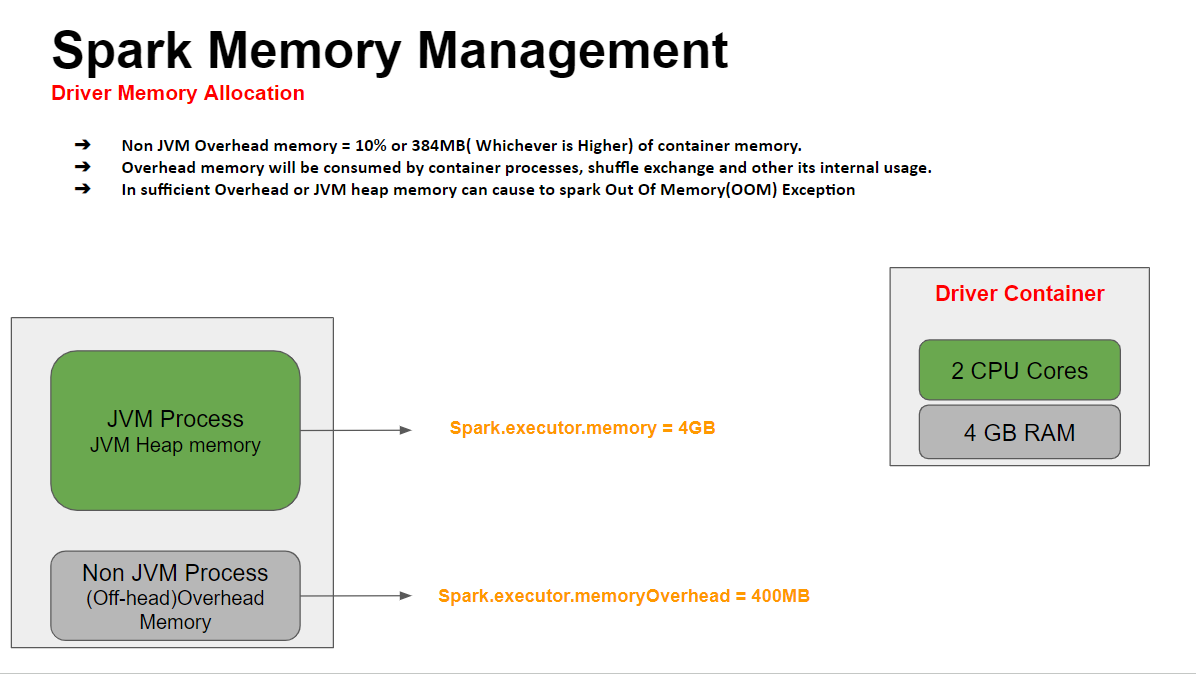
Executor Memory Allocation:
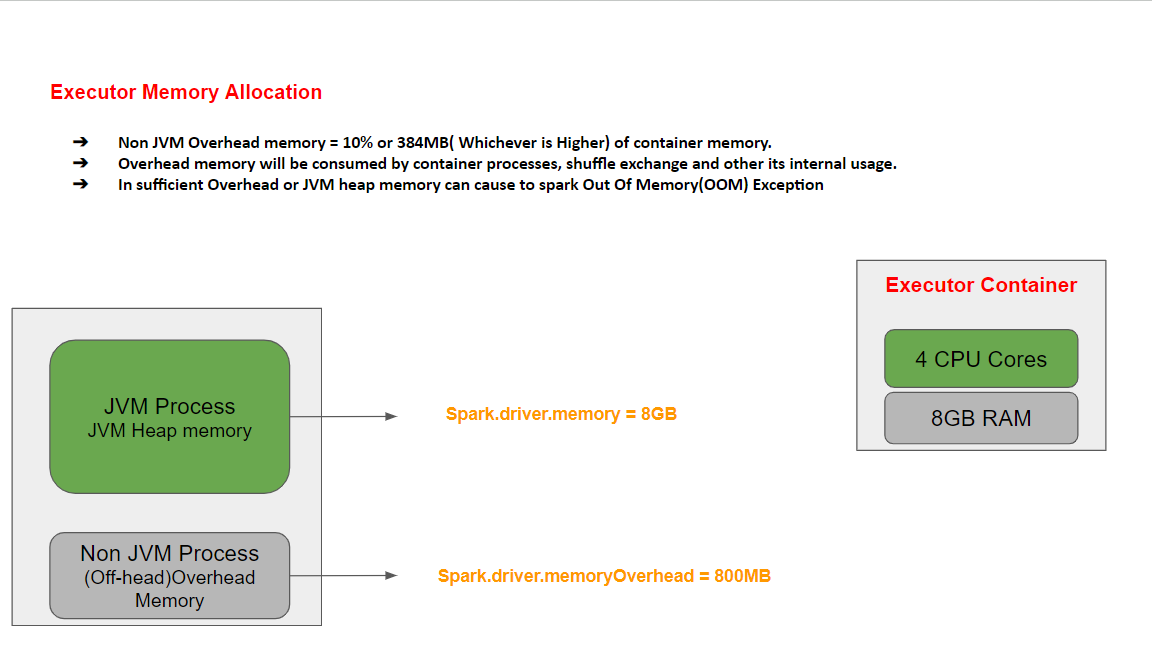
JVM Process Memory Deep Dive
In Apache Spark, JVM process memory is further divided into three main parts: reserved memory, Spark memory, and user memory. Each part plays a crucial role in managing and optimizing memory usage for executing Spark tasks efficiently.
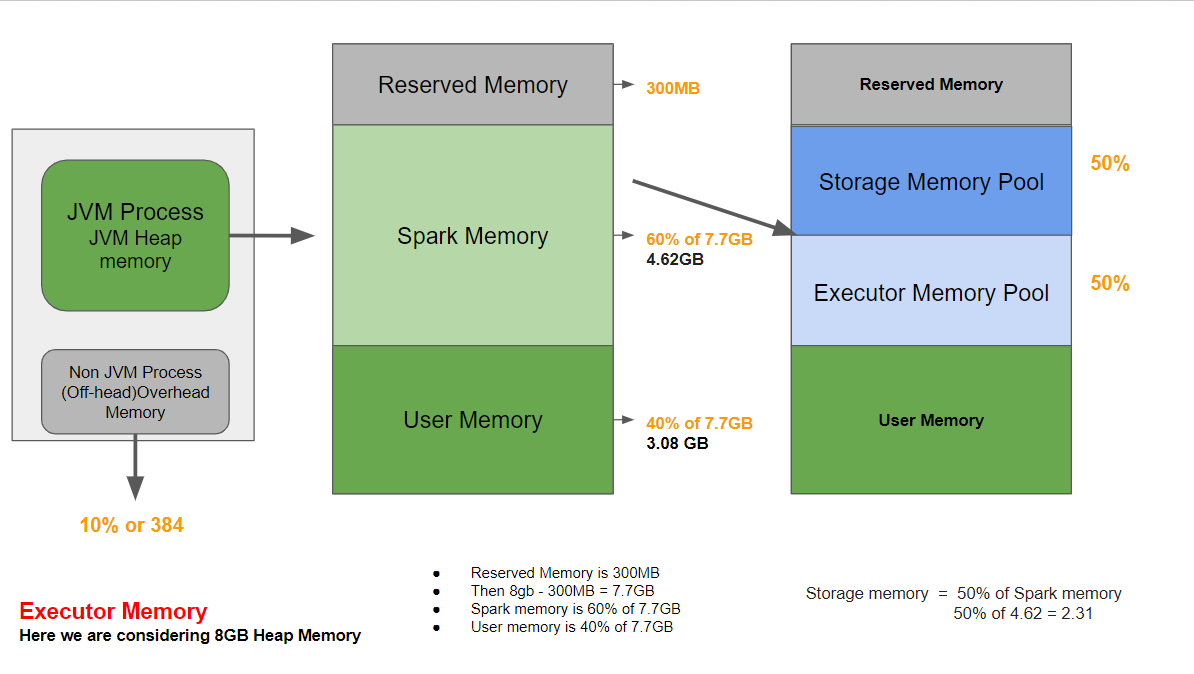
Reserved Memory
Reserved Memory in Apache Spark refers to memory allocated for storing internal Spark objects and for internal operations(Task scheduling, Internal Data Structures) Networking, and Communication).
Its size is fixed at 300MB by default in the codebase and cannot be directly modified, except in testing environments where it can be adjusted using the spark.testing.reservedMemory parameter.
Note:If the memory allocated to an Executor is less than 1.5 times less than reserved memory, the Executor will not be able to run. Spark will fial with “please use larger heap size” error message.
Spark Memory
Spark memory refers to the memory allocated within the JVM process for executing Spark tasks and managing data. It plays a crucial role in optimizing performance by efficiently handling data processing and caching.
configuration: spark.memory.fraction = 0.6
0.6: Represents 60% of the available memory after deducting the reserved memory. For instance, if 10GB of memory is available and 300MB is reserved, then 60% of the remaining 9.7GB (10GB - 300MB) is allocated as Storage Memory in Spark.
Spark Memory=0.6×9.7GB=5.82GB
Here are the components of Spark memory:
Execution Memory: Execution Memory is allocated in Apache Spark to handle temporary data during various computational tasks such as shuffles, joins, sorts, transformations, and aggregations. Configuration parameters spark.memory.storageFraction = 0.5 by default.
Storage Memory: Storage Memory in Apache Spark is primarily used to cache data, including RDDs, broadcast variables, and unroll data. The memory allocation is calculated based on the system's total memory and Spark configuration parameters spark.memory.storageFraction = 0.5 by default.
Default Configuration (Spark 2+): Storage Memory and Execution Memory each typically account for about 30% of the total system memory (1 * 0.6 * 0.5 = 0.3).
1: Total available memory or system's maximum capacity.
0.6: Fraction of total memory Spark uses (
spark.memory.fraction).0.5: Fraction of
spark.memory.fractionfor Storage Memory (spark.memory.storageFraction).
spark.memory.storageFraction= 0.5
- This fraction determines the portion of
spark.memory.fractionallocated to Storage Memory.
- This fraction determines the portion of
Calculate Storage Memory: Storage Memory=0.5 × 9.7GB = 4.85GB
User Memory
User memory in Apache Spark refers to the portion of memory allocated within the Spark memory space that applications can use for user-defined operations like UDFs, Broadcast Variables, and RDD conversion operations. Unlike Storage Memory and Execution Memory, which are managed by Spark for internal operations, user memory is dynamically allocated based on the application's needs and the type of operations being performed.
In Spark 2+, it defaults to 40% of the available memory (1 * (1 - 0.6) = 0.4).
spark.memory.fraction= 0.4
Simple Example
Conclusion
Effective memory management is crucial for optimizing the performance and reliability of Apache Spark applications. Throughout this article, we explored the intricacies of Spark memory management, focusing on its key components: JVM process memory, reserved memory, Storage memory, and user memory.
Understanding these components allows developers to fine-tune memory allocation based on specific workload demands and application requirements. Configurable parameters such as spark.memory.fraction and spark.memory.storageFraction enable adjustments to Storage and Execution memory, ensuring efficient data processing and minimizing resource contention.
By strategically allocating memory resources and leveraging features like caching and user-defined functions, Spark applications can achieve significant performance improvements. Properly managed memory enhances data processing efficiency, supports complex analytics tasks, and facilitates real-time data insights without compromising system stability.
In conclusion, mastering Spark memory management empowers developers to harness distributed computing capabilities effectively, delivering scalable and high-performance solutions for modern data-driven challenges.
Subscribe to my newsletter
Read articles from Kiran Reddy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kiran Reddy
Kiran Reddy
Passionate Data Engineer with a degree from Lovely Professional University. Enthusiastic about leveraging data to drive insights and solutions.