Understanding semantic search
 Sammith S Bharadwaj
Sammith S Bharadwaj
Introduction
During my college days, one of the electives I had chosen was algorithms for information retrieval, it was a pretty fun course, learnt about how webpages are ranked while retrieving, cold start problem and how companies like netflix tackle. It was the only course where I had actually read the textbook prescribed for the course, if only I had done that for the other ones but anyway, recently I have gone back to my ML craze days and want to explore stuff, today I want to see what is up with semantic search and what is that all about.
Semantic search
Traditionally retrieving webpages relied upon keyword matching which does not fully leverage the query as it misses the context, with semantic search we want to take that into account as well, for instance when we type apple, it can mean the fruit or the company, based on context that changes, so using semantic search we can tackle that is what is expected. So using NLP techniques, we understand the query and retrieve relevant results.
How does it work?
Natural Language Processing (NLP) and entity recognition
Semantic search uses NLP to analyse structure of the language. We parse and try to understand structure of the sentence, identifying entities, and what is the relationship between the different entities.
Contextual Understanding
Semantic search engines takes into account the context of words and phrases. It also had to take into account synonyms, related concepts and sometimes even spelling mistakes, like we see in google search sometimes.
Vector Space Models and Embeddings
Words, phrases, and entire documents are transformed into high-dimensional vectors through techniques like word embeddings. Models such as Word2Vec, GloVe, and BERT capture the semantic relationships between words by placing similar words closer together in the vector space. This allows the search engine to find documents that are contextually similar to the query, even if they don’t contain the exact keywords.
Coding timeeeeee
Install Required Libraries
First, ensure you have the necessary libraries installed.
!pip install sentence-transformers scikit-learn
Download and Preprocess Dataset
We'll use the fetch_20newsgroups function from scikit-learn to download the dataset.
from sklearn.datasets import fetch_20newsgroups
# Download the dataset
newsgroups_data = fetch_20newsgroups(subset='all', remove=('headers', 'footers', 'quotes'))
# Print the dataset information
print(f"Number of documents: {len(newsgroups_data.data)}")
print(f"Number of categories: {len(newsgroups_data.target_names)}")
Compute Embeddings
We use the sentence-transformers library to load a pre-trained model and compute embeddings for each document.
from sentence_transformers import SentenceTransformer
# Load pre-trained model
model = SentenceTransformer('paraphrase-MiniLM-L6-v2')
# Compute embeddings for the documents
doc_embeddings = model.encode(newsgroups_data.data, show_progress_bar=True)
Perform Semantic Search
We define a function to perform semantic search by computing the embedding of a query and finding the most similar documents using cosine similarity.
from sklearn.metrics.pairwise import cosine_similarity
import numpy as np
def semantic_search(query, documents, doc_embeddings, top_n=3):
# Compute embedding for the query
query_embedding = model.encode([query])
# Compute cosine similarity between query and documents
similarities = cosine_similarity(query_embedding, doc_embeddings).flatten()
# Get the top_n most similar documents
top_indices = similarities.argsort()[-top_n:][::-1]
# Print the top_n most similar documents
print(f"Query: {query}\n")
for idx in top_indices:
print(f"Document: {documents[idx][:200]}...") # Print only the first 200 characters for brevity
print(f"Similarity: {similarities[idx]:.4f}\n")
# Example query
query = "Baseball is fun"
semantic_search(query, newsgroups_data.data, doc_embeddings, top_n=3)
Results
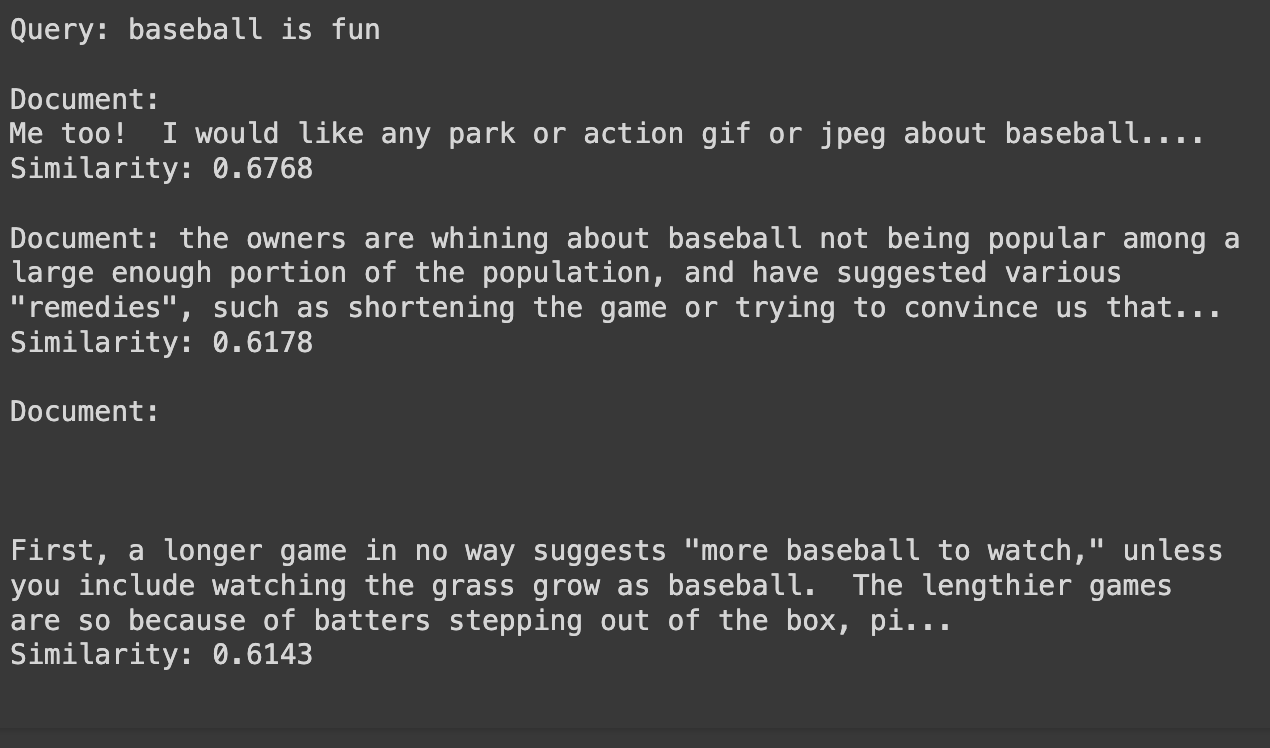

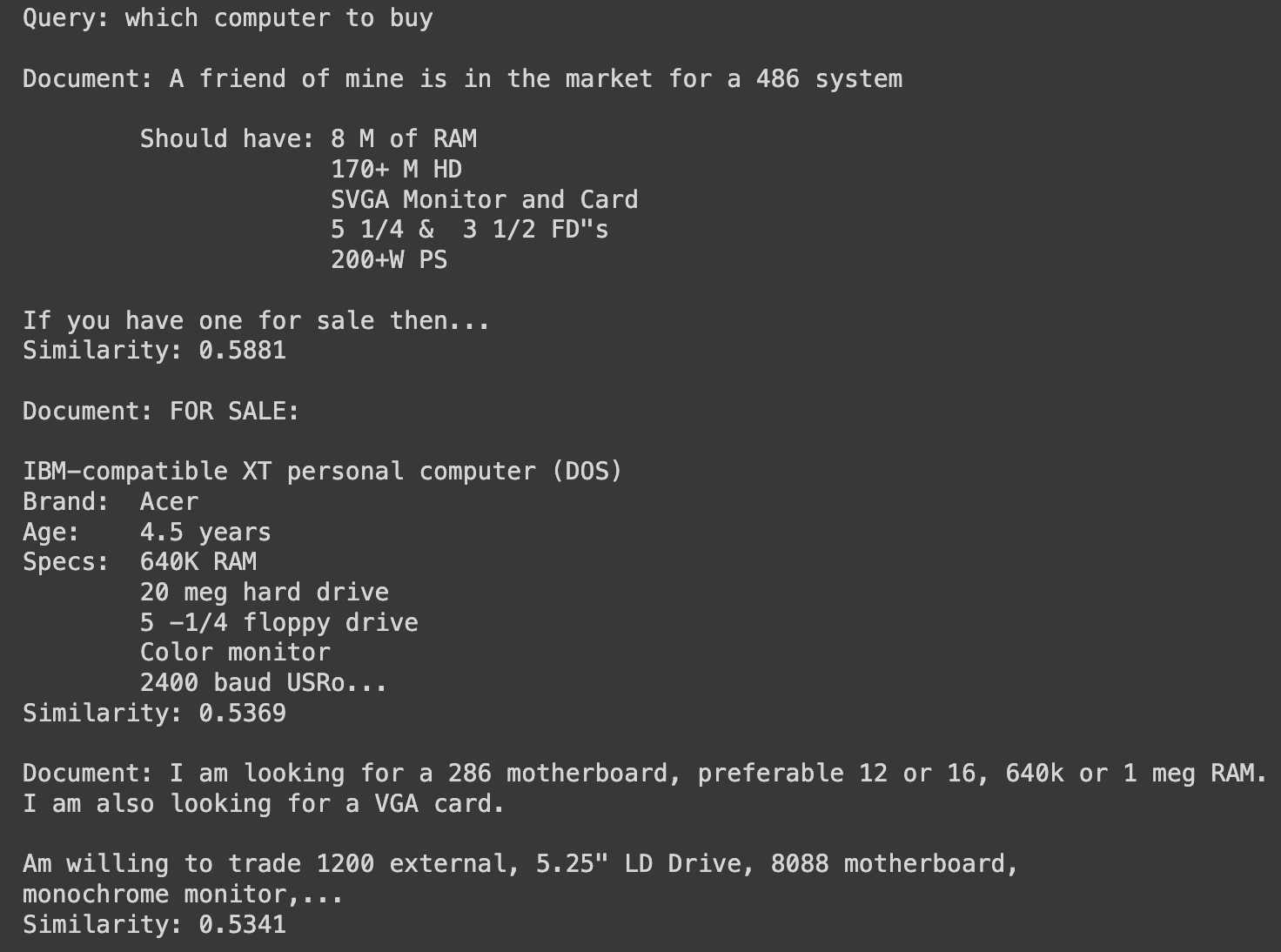
As we can see the results are okayish at best, but are still kinda relevant, i would say the last one quite good. To be fair, it not that big of a dataset to have all knowledge in the world to give correct answer, but it does get the context right, using bigger datasets, better transformers and all will ensure we get good results and in fact that is what is happening in the real world currently, we have search engines, e-commerce sites, content recommendation platforms and even chatbots integrate semantic search to serve their customers better.
Subscribe to my newsletter
Read articles from Sammith S Bharadwaj directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by