How to scrape Weather.com for Weather Information using BeautifulSoup
 Buzzpy
Buzzpy
Are you planning to go out for this summer? Picking a date for the perfect summer day out would be difficult but running a simple data analysis of the weather of upcoming dates may save you the hustle. In this tutorial, we will scrape and extract data from the famous weather forecasting website weather.com using Python and Beautifulsoup library, and deploy it to the Apify Platform.
What is Apify?
Apify is a web scraping platform that provides SDKs and pre-built templates for common web scraping tasks. It also provides convenient storage functions, making it easy to handle scraped data.
Prerequisites
Python 3.9+
Basic knowledge of web scraping.
Setting Up
Even though we can write our web scraper from scratch using Apify SDK, Apify has a few pre-built templates for an easier start. They include every file we need to scrape a web page and are very easy to customize, which helps us save time and prevent headaches.
These templates also include the Actor Life-style management feature, which helps us to focus on the core logic of the scraper, without much concern on the setup and teardown processes. We can also use the template’s pre-built Input schema file to define and easily validate a schema for our Actor’s input.
So here, we’ll be using the Apify Python starter template which uses BeautifulSoup to scrape a single page with the input URL.
Start with Python - Template · Apify
While we can use the Apify console itself to edit, build, and run the code, it would be more convenient for us to write the program locally and then deploy it to Apify.
To use the template locally, first install the Apify CLI and create a new actor using the template as below:
$ npm -g install apify-cli
Running this command will build a virtual environment for the Actor and install the required dependencies.
When it’s all set up, we can see 2 Python scripts main.py and main.py. The functions of these 2 scripts are as follows:
main.py: This file contains the main function for the Apify actor. It’s where the web scraping task is defined and executed._main_.py: This file is the entry point for executing the Apify Actor. It sets up necessary settings and runs the main function in the main.py script asynchronously.
What is an Actor?
Just like a human actor, apify actors accept input, perform their job, and generate output, according to the script.
Understanding the code
Let’s take a closer look at the scripts of our newly created actor.
Main.py
# Beautiful Soup - library for pulling data out of HTML and XML files, read more at
# https://www.crummy.com/software/BeautifulSoup/bs4/doc
from bs4 import BeautifulSoup
# HTTPX - library for making asynchronous HTTP requests in Python, read more at https://www.python-httpx.org/
from httpx import AsyncClient
# Apify SDK - toolkit for building Apify Actors, read more at https://docs.apify.com/sdk/python
from apify import Actor
async def main() -> None:
async with Actor:
# Structure of input is defined in input_schema.json
actor_input = await Actor.get_input() or {}
url = actor_input.get('url')
# Create an asynchronous HTTPX client
async with AsyncClient() as client:
# Fetch the HTML content of the page.
response = await client.get(url, follow_redirects=True)
# Parse the HTML content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract all headings from the page (tag name and text)
headings = []
for heading in soup.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6']):
heading_object = {'level': heading.name, 'text': heading.text}
Actor.log.info(f'Extracted heading: {heading_object}')
headings.append(heading_object)
# Save headings to Dataset - a table-like storage
await Actor.push_data(headings)
This script uses the following libraries:
BeautifulSoup: A popular Python web scraping library that can be used to extract data in a hierarchical and more readable manner.
Httpx: Httpx is a http client built for Python 3, that provides sync and async APIs. AsyncClient is used for making asynchronous HTTP requests in Python, which means a batch of requests doesn’t wait for each request to finish before making the next.
Apify library
The sample main() function fetches the HTML content from the input URL, parses it using BeautifulSoup, and then extracts the web page headings, finally storing it in datasets.
The storage function raises an important concern about deploying these web scrapers in Apify. When run locally, the output of the web scraper is stored as separate lines in individual JSON files, which means if there are 20 outputs, there would be 20 JSON Files. This makes it difficult to acquire data for data analysis.
But when the web scraper is deployed and run on Apify, the dataset is stored in the cloud and can be accessed and downloaded through the Apify app or its API. The data can be downloaded in different formats such as CSV, JSON, Excel, and even as an RSS feed, whichever fits our requirements. Therefore, once we finish creating the program, we will be deploying it to Apify.
_main_.py
import asyncio
import logging
from apify.log import ActorLogFormatter
from .main import main
# Configure loggers
handler = logging.StreamHandler()
handler.setFormatter(ActorLogFormatter())
apify_client_logger = logging.getLogger('apify_client')
apify_client_logger.setLevel(logging.INFO)
apify_client_logger.addHandler(handler)
apify_logger = logging.getLogger('apify')
apify_logger.setLevel(logging.DEBUG)
apify_logger.addHandler(handler)
# Execute the Actor's main coroutine
asyncio.run(main())
This script uses basic libraries such as async and logging to run asynchronous functions and to configure logging settings for apify actor respectively.
As a summary, this script configures the 2 loggers— apify-logger and apify-client-logger — and runs the main.py script asynchronously, which allows the script to perform multiple tasks simultaneously.
Customizing the Code
Now that we have a basic understanding of the code in the template, we can customize it according to our needs.
As mentioned in the first part of the tutorial, we will be scraping data from weather.com to extract weather information for the next 10-13 days. To do so, we should first edit the input URL of the input_schema.json file to the URL of the 10-Day weather Page of weather.com.
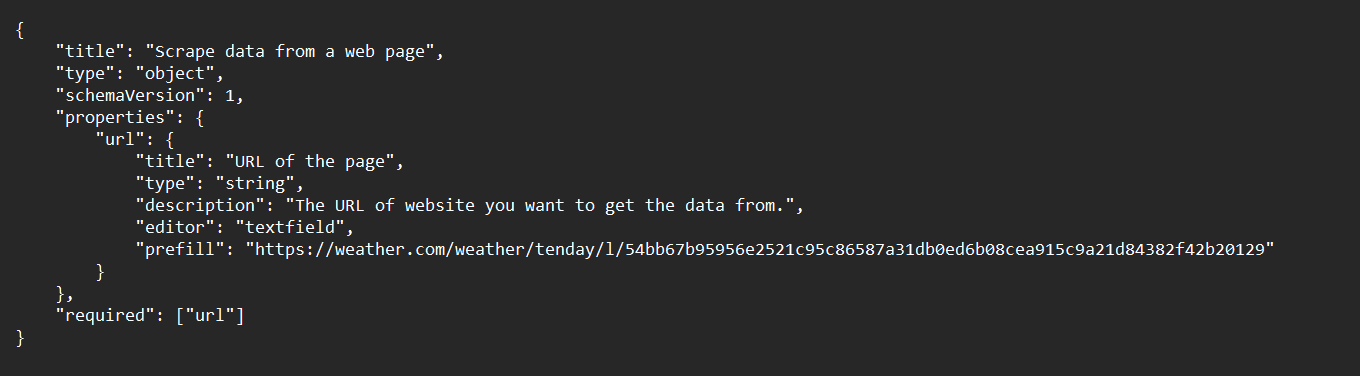
(To find the URL, go to weather.com > 10-Day weather. The URL depends on the location of the IP address. If you want to extract weather information for a specific place, enter the zip code on the website and proceed.
Then we should edit our main.py file to extract data with relevant classes. For this tutorial, we will extract the data about the weather and the temperature.
If you take a close look at the main.py file in the template, we can observe how headings are extracted through HTML tags. But since we are looking out for specific information, we can’t use HTML tags; Instead, we should use class names assigned to those elements.
Here’s how customized code that fits our requirements would look like:
from bs4 import BeautifulSoup
from httpx import AsyncClient
from apify import Actor
async def main() -> None:
async with Actor:
actor_input = await Actor.get_input() or {}
url = actor_input.get('url')
async with AsyncClient() as client:
response = await client.get(url, follow_redirects=True)
soup = BeautifulSoup(response.content, 'html.parser')
# Extract weather data for 10 days
weather_data = []
for day in soup.find_all('div', class_='Disclosure--SummaryDefault--2XBO9'):
day_data = {}
# Extract day name
day_name = day.find(attrs={"data-testid": "daypartName"}) day_data['day_name'] = day_name.text if day_name else "N/A"
# Extract weather, temperature, wind speed, and UV index
weather = day.find('span', class_='DetailsSummary--extendedData--307Ax')
day_data['weather'] = weather.text if weather else "N/A"
#Extract temperature
temperature = day.find('span', class_='DetailsSummary--highTempValue--3PjlX')
day_data['temperature'] = temperature.text if temperature else "N/A"
Actor.log.info(f'Extracted weather data: {day_data}')
weather_data.append(day_data)
# Save weather data to Dataset
await Actor.push_data(weather_data)
Modifications done to the template:
Data is extracted via class names, and stored in the list
weather_dataDatasets will have 3 columns: The Day, Weather, and the temperature. If needed, you can extract data about wind speed, UV index, humidity, etc. in the same manner.
If certain information doesn’t exist, that data field is filled with “N/A”, to prevent potential errors and for an easier data cleaning process in the data analysis.
Now our program is complete. We can move to the next step by deploying it to Apify.
Deploying the code to Apify
To deploy and execute this code on Apify, you should create an Apify account first and get your default API token for logging in.
Go to apify.com > sign up and create a free account.
In the Apify console, go to settings > Integrations and copy your default API token.
- Copy the API token
Once you have the token, type apify login on the terminal, and then paste your token.
C:\Users\user\my-actor>apify login
After signing in, enter apify push on the terminal and we’re good to go!
Success: you are logged in to Apify as buzzpy!
C:\Users\nethm\my-actor>apify push
To view and run our deployed code, go to console.apify.com > Actors. You can view your deployed actor there. To run, click the “Start” button and let Apify do the rest.
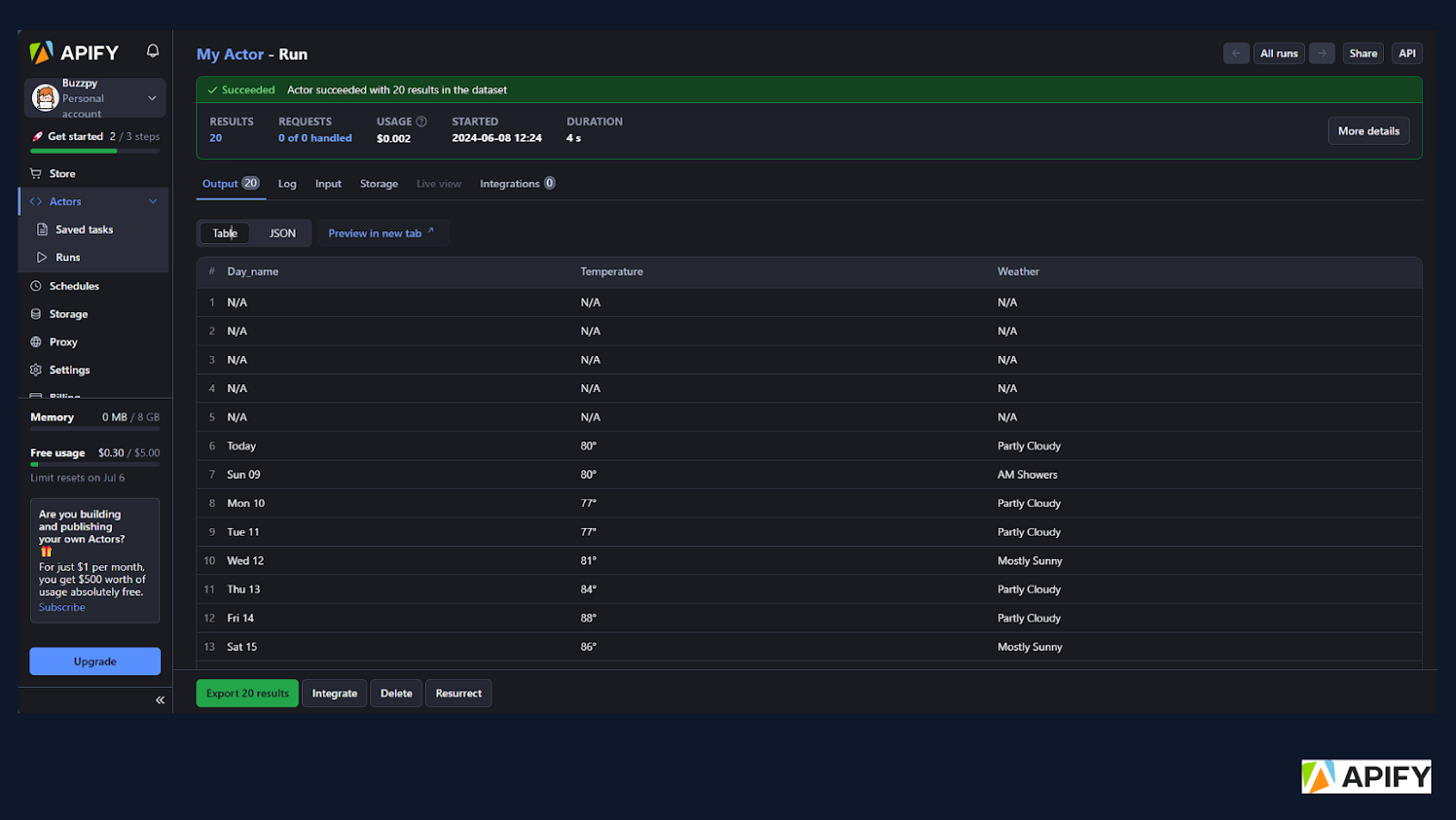
Image: Output of the actor
Now you can easily download the output data, clean the N/A values, and analyze.
Next Steps
And that’s all about it. Read Apify Python SDK Documentation to expand your knowledge on Python web scraping with Apify and if you want to try out more, read this tutorial on scraping LinkedIn on Apify Blog.
Subscribe to my newsletter
Read articles from Buzzpy directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Buzzpy
Buzzpy
A Buzzy Pythoneer, who enjoys Coding + Reading 🐳