Huffman Coding 101: Learn the Theory (Part 1)
 Aayush Shah
Aayush Shah
Introduction
In this blog post, we'll explore Huffman coding, a powerful algorithm used for lossless data compression. We'll delve into the theory behind Huffman trees and figure out why they work the way they do.
In the second part of this article, we will walk through a detailed implementation of a Huffman Compression tool in Golang.
What is Huffman Coding?
Huffman coding is a method of lossless data compression named after its creator, David A. Huffman. The core idea is to assign variable-length codes to characters based on their frequency of occurrence. More frequent characters get shorter codes, while less frequent characters get longer codes. This approach minimizes the overall number of bits required to represent the data.
How Variable-Length Codes Lead to Compression
To understand how variable-length codes result in compression, let's dive deeper into the concept:
Fixed-Length vs. Variable-Length Codes: In a fixed-length encoding (like ASCII), each character is represented by the same number of bits (typically 8). This is simple but inefficient for data with varying character frequencies.
Frequency-Based Encoding: Huffman coding analyzes the frequency of each character in the data. It then assigns shorter bit sequences to more frequent characters and longer sequences to less frequent ones.
Weighted Average Code Length: By assigning shorter codes to frequent characters, we reduce the total number of bits needed to represent the data. The average code length is effectively "weighted" by the frequency of each character.
Example: Consider a simple text: "AABBBCCCC"
With fixed 8-bit encoding: 9 characters * 8 bits = 72 bits
With Huffman coding:
'A' (freq: 2) -> '10' (2 bits)
'B' (freq: 3) -> '11' (2 bit)
'C' (freq: 4) -> '0' (1 bits) Total: (2***2) + (3*2) + (4*1) = 14 bits
Compression Ratio: In this simple example, we've compressed 72 bits to 14 bits, a compression ratio of about 5:1. Real-world compression ratios vary based on data characteristics but can be significant.
Adaptability to Data: The beauty of Huffman coding is that it adapts to the specific frequency distribution of the input data. Highly skewed distributions (where some characters are much more frequent than others) lead to better compression.
By leveraging the statistical properties of the data, Huffman coding achieves compression without losing any information. This makes it a fundamental technique in data compression, serving as a building block for more advanced algorithms and finding applications in various file formats and communication protocols.
The Theory Behind Huffman Trees
Huffman coding relies on a special binary tree data structure called a Huffman Tree. As discussed earlier, Huffman coding assigns codes to characters based on their frequency. The Huffman Code for each character is derived from the Huffman Tree.
Each leaf of the Huffman Tree corresponds to a character, and we can define the weight of each leaf node to be the frequency of that character. The goal is to build a tree with the minimum external path weight.
Define the weighted path length of a leaf to be its weight times its depth. The binary tree with the smallest external path weight is the one where the total of all the weighted path lengths for the given leaves is the least. A letter with high weight should have low depth, so that it will count the least against the total path length. As a result, another letter might be pushed deeper in the tree if it has less weight.
Build a Huffman Tree
The process of building a Huffman Tree is simpler than you'd expect.
Construct a set of n Huffman trees, each with a single leaf node containing one of the characters.
Insert the n trees into a priority queue organized by their weights (frequency).
Remove the first two trees from the queue (the ones with the lowest weights).
Join these two together to create a new tree whose root has the two trees as children, and whose weight is the sum of the weights of the two trees.
Put this new tree back into the queue.
Repeat steps 3-6 until only one tree remains in the queue, and there you will find the treasure you sought!
Let's visualize this process with an extensive example. Consider that we have the following character-frequency map for some file that we need to compress.
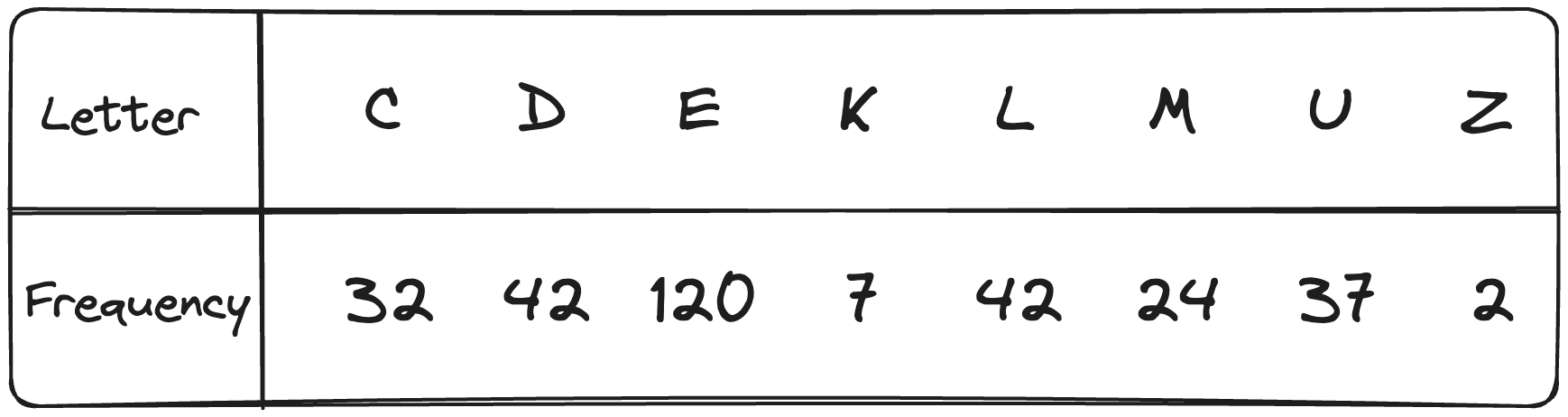
Let's construct n Huffman trees, one for each character.

As you can see, each node's weight is equal to the corresponding character's frequency.
Insert all the trees into a priority queue, sorted by their weights.

Now we repeat steps 3-6 until we obtain the final Huffman Tree!

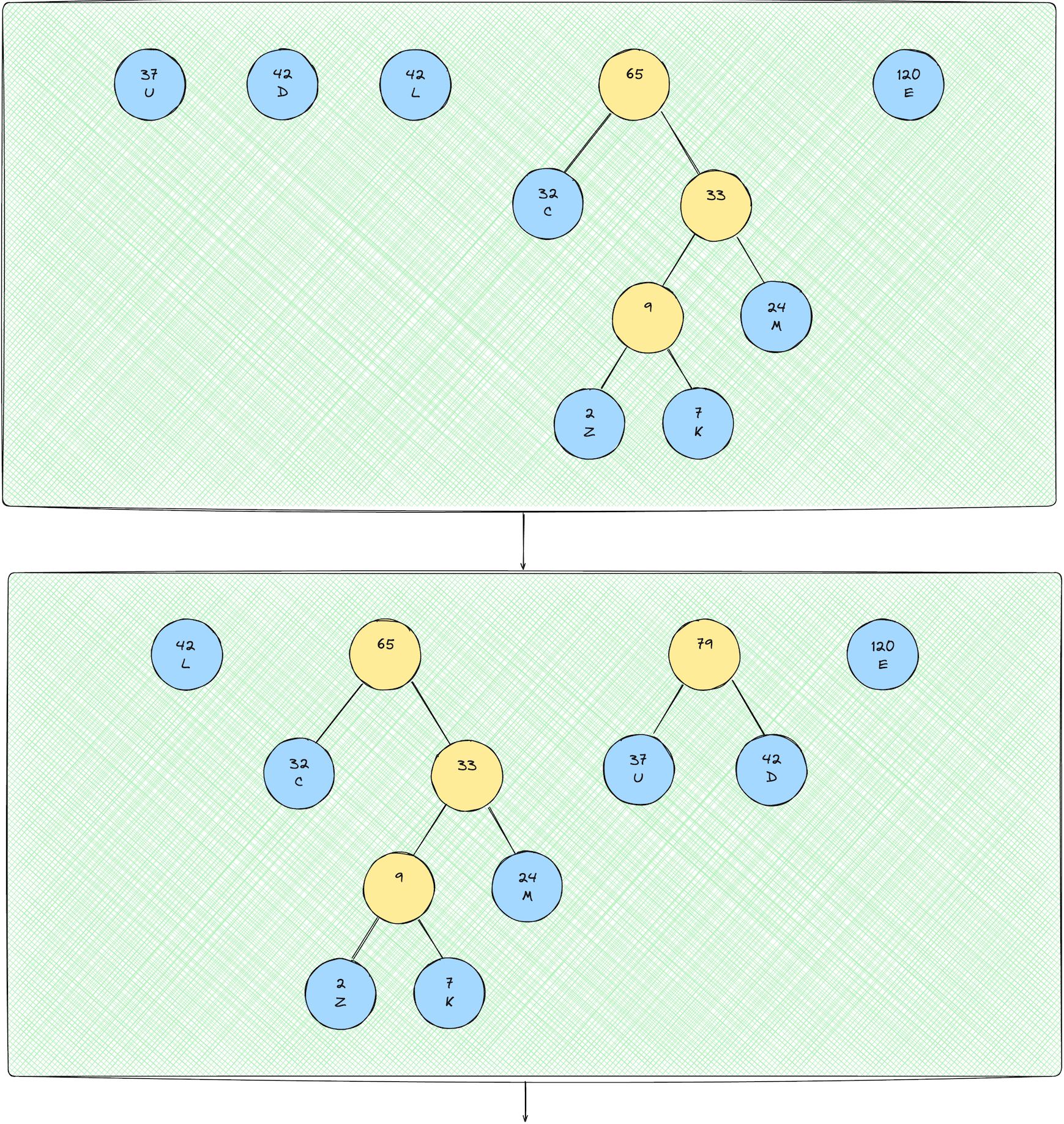
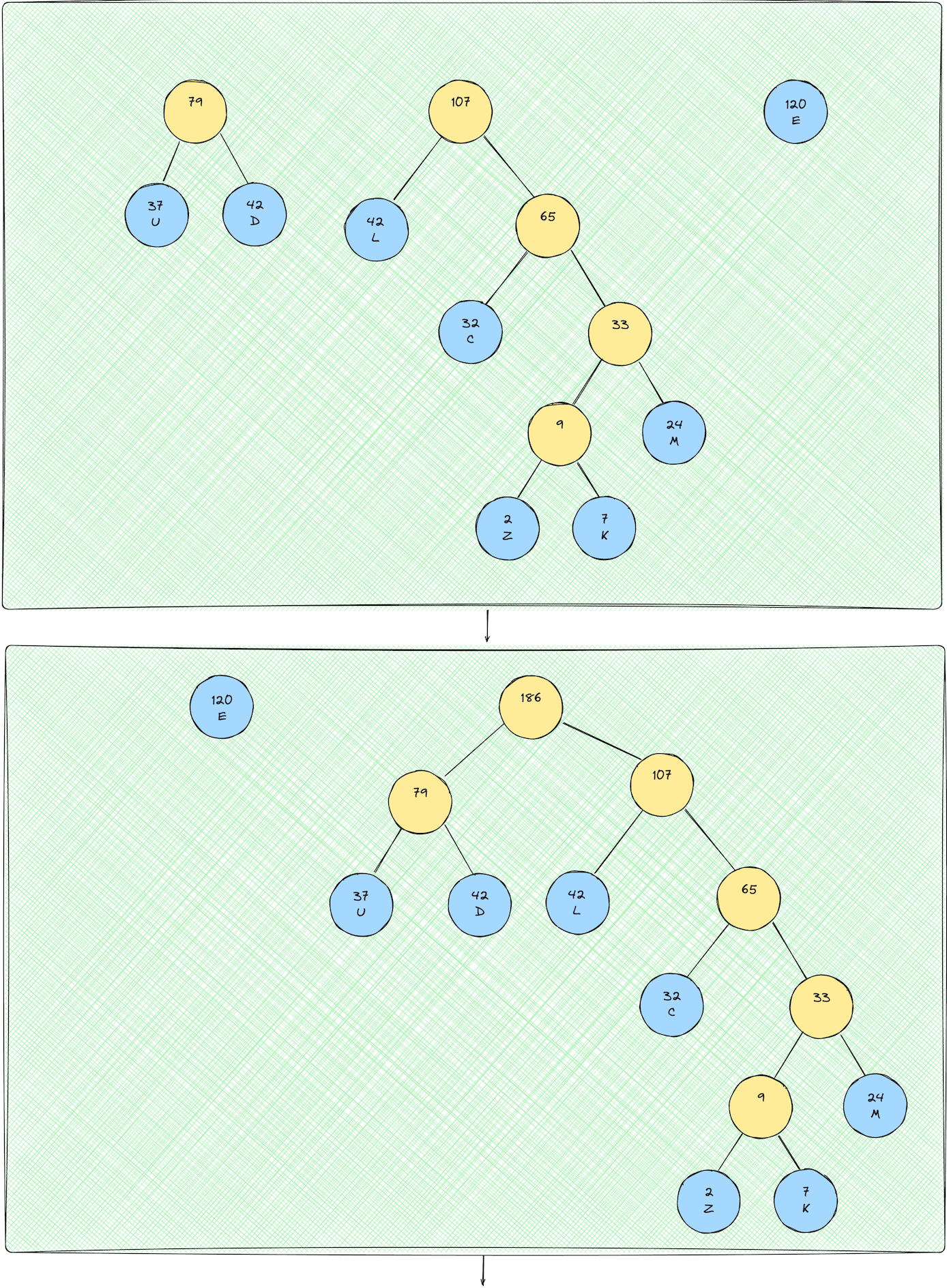
I'd suggest you work through this tree-building process with pen and paper to really get a good grasp on the intuition.
Assigning and Using Huffman Codes
We have our Huffman Tree ready to go. But how do we get the actual variable-length Huffman codes that we've been talking about since forever? Lucky for us, it is trivial.
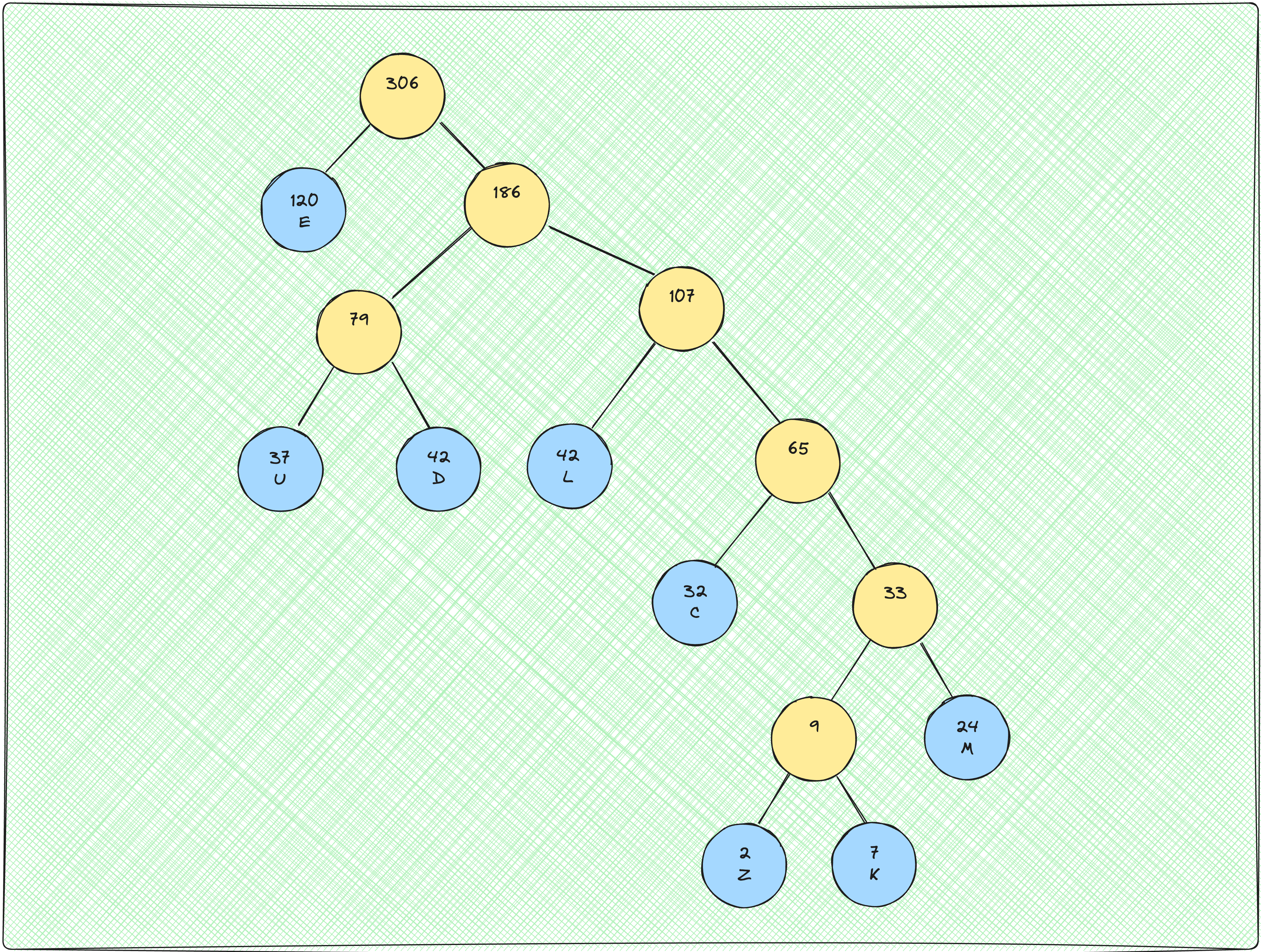
Beginning at the root, we assign either a 0 or a 1 to each edge in the tree. All the edges connecting a node to its left child get a 0 and the ones connecting a node to its right child get a 1. Applying this to the Huffman Tree we have already constructed, we get the following representation:
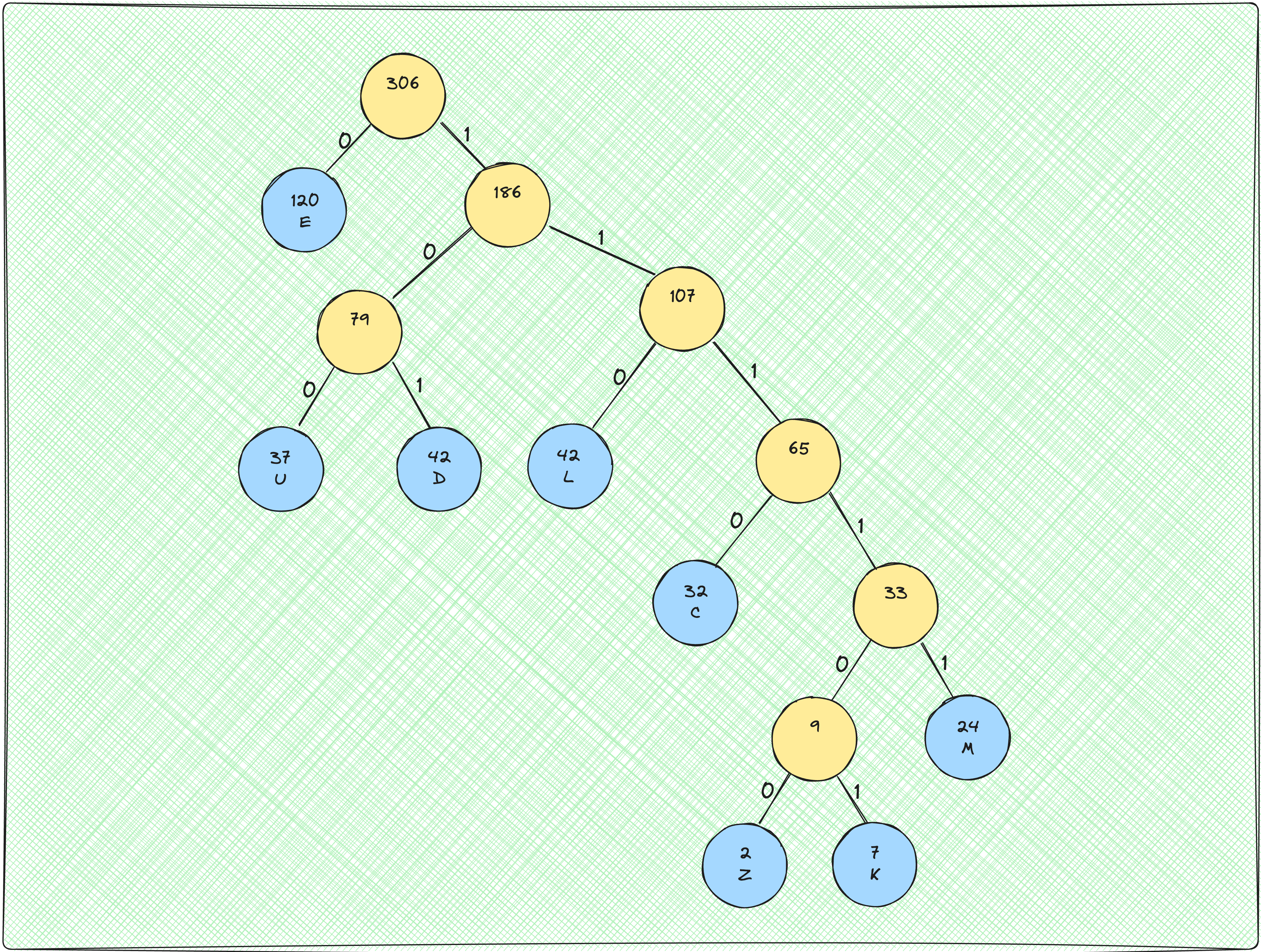
Getting the individual codes for each letter is now only a matter of traversing the tree and concatenating the weight assigned to each edge! For instance, the code assigned to the letter L will be 110.
The final codes obtained after following this process are:
| Letter | Huffman Code |
| E | 0 |
| U | 100 |
| D | 101 |
| L | 110 |
| C | 1110 |
| M | 11111 |
| Z | 111100 |
| K | 111101 |
Now we have everything we need to compress our file using our hot-and-fresh Huffman codes. Every character in the original text file will be represented using these variable length codes instead of a fixed 8-bit code, thus compressing the file size to a great extent!
Now, you should have a good enough understanding of how Huffman coding works to try and implement a solution yourself. You can find a complete solution in Golang and its explanation in Part 2 of this article.
Keep learning!
Subscribe to my newsletter
Read articles from Aayush Shah directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by