Efficient API Handling in Python: Connection Pooling and Async Calls for EgyTech API Wrapper
 Abdulrahman Mustafa
Abdulrahman Mustafa
Last article, we created a simple pythonic wrapper for the EgyTech API, with basic functionality. This time we will be extending out wrapper's functionality with some interesting concepts. I've also included some diagrams to help you with these concepts.
The EgyTech API doesn't support multiple different queries natively. If you want to fetch all survey responses with a title of "backend" as well as those with a title of "frontend", you have to make two separate API calls. It is worth noting that when data is at this scale (~1700 responses at the time), the performance will be decent. However, as the data grows, you will need to have better solutions in place for handling multiple API requests.
Two of the concepts we will address in this article are offered by httpx, a powerful HTTP requests library. So let's dive right in!
Connection Pooling
Background
Making a single API request involves connecting to the API, sending the specified request, waiting for a response, receiving the response, and then disconnecting from the server, as shown by the diagram:
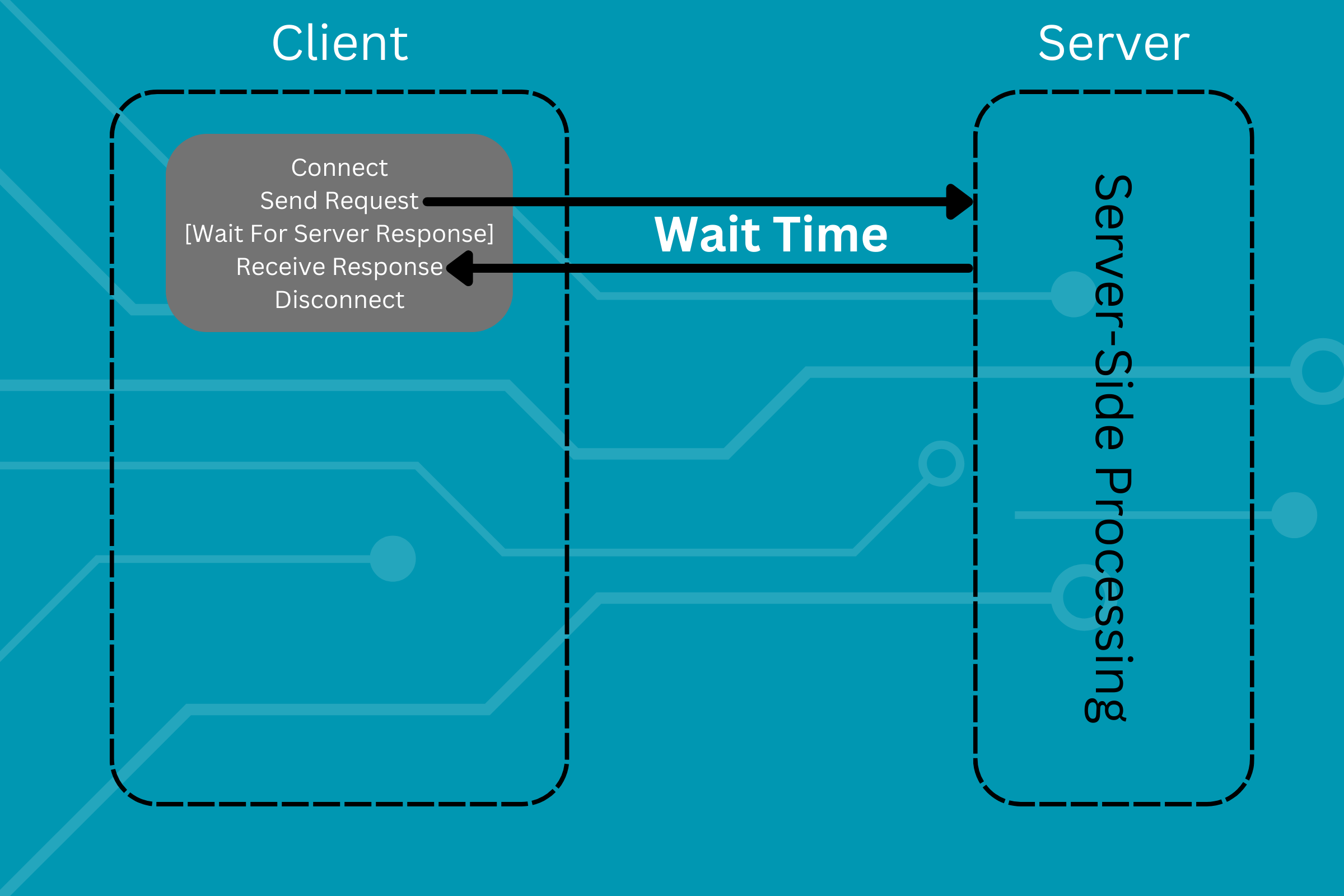
Now let's scale this. Let's make 3 API requests:
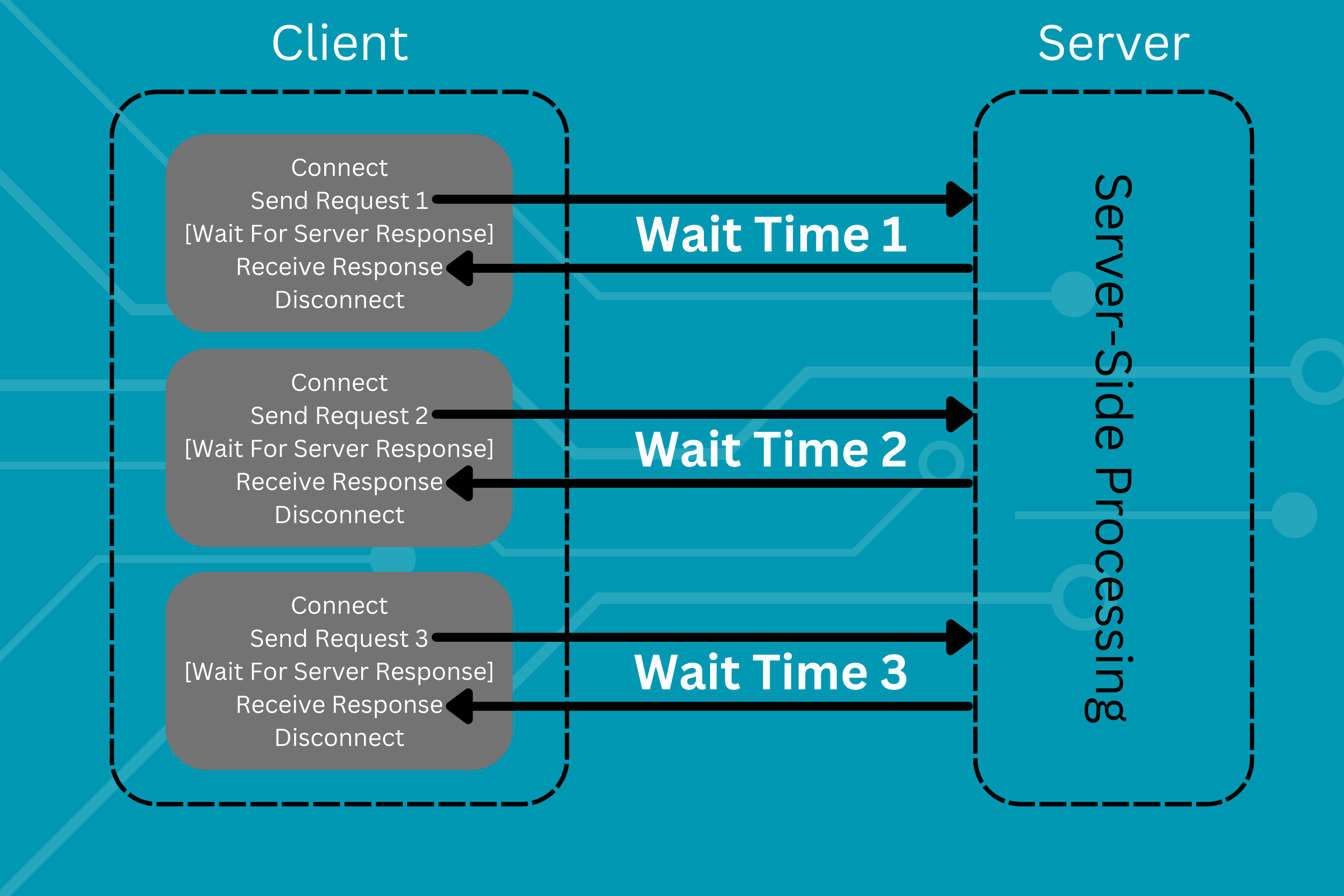
One thing you may notice is that each time we make a new request, we have to establish a connection and then disconnect. This creates unnecessary overhead as you can make the requests with a single live connection rather than one for each connection. This is simply what connection pooling is. As defined in this nice article about connection pooling on Microsoft Dev Blogs (definitely a recommended read):
"Connection pooling refers to reusage of existing pre-established connections to make HTTP requests, rather than creating a new connection for each service request, be it a connection of accessing remote REST API endpoint, or a backend database instance."
Now let's compare this to making the same requests using connection pooling:
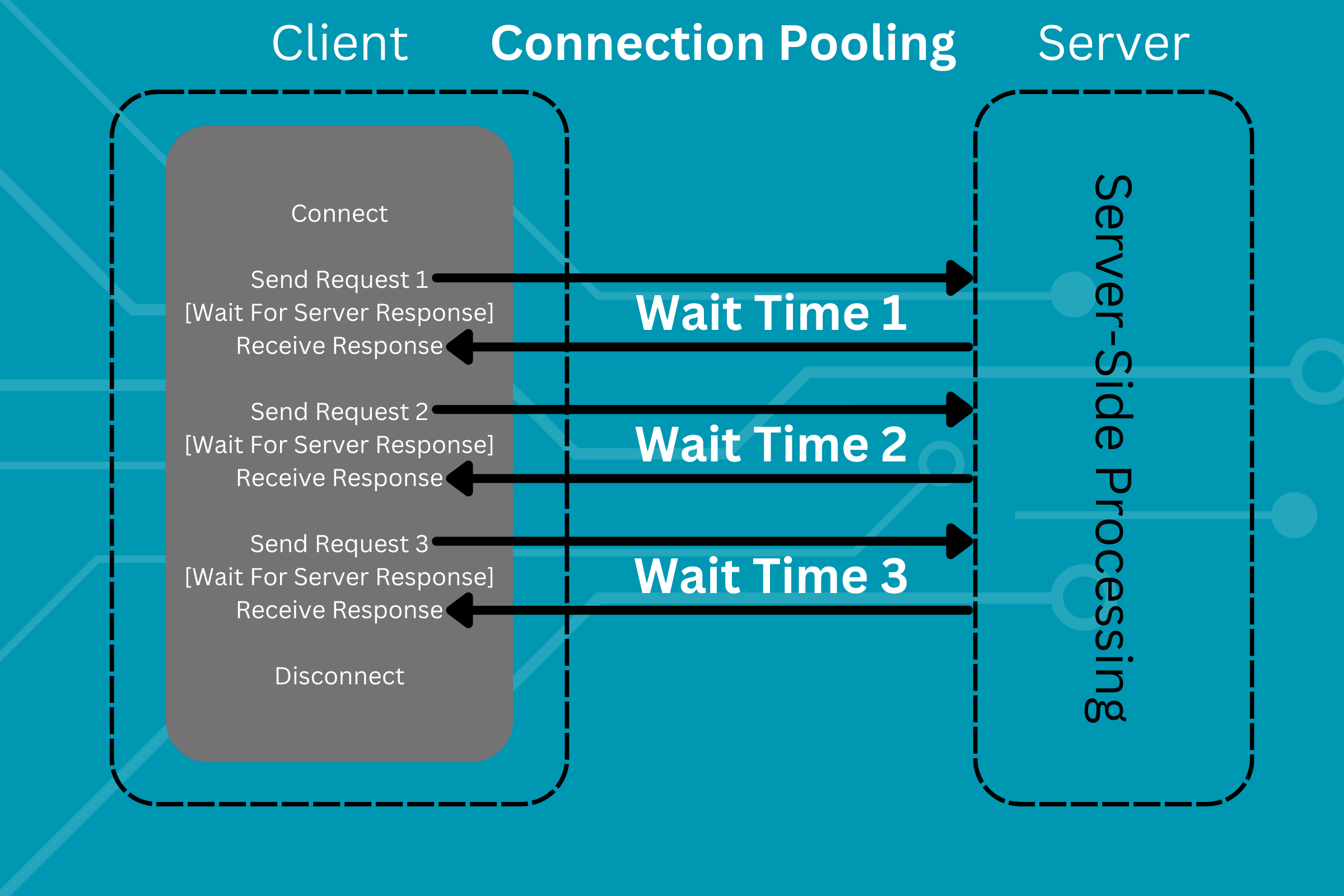
This provides a significant performance boost, as it replaces all instances of client- & server- side logic that relates to establishing and destroying a connection with only one instance of said logic. You only connect once and you only disconnect once.
Implementation In Python
Fortunately, we will not have to implement a low-level example of the above logic. HTTPX already provides an implementation of connection pooling via the httpx.Client() class. We can even eliminate the need for configuring our API call each time we make a request, as a Client instance can have consistent configuration across multiple API requests. This means that we won't have to define the headers every time we make a request, for example.
This tutorial is more concerned with applying the connection pooling concept than applying client-side advanced deserialization logic. Thus, we will only support the /participants endpoint in our connection pooling-enabled model, as the logic involved in processing multiple /stats is a bit more complex, and beyond the purpose of this article series.
Now, we will ask our users to construct a list of ParticipantsQueryParams, as we still want our request parameters to be correct. This can be done with the model we built for validation only (doesn't include API calling or data conversion). Let's define a pydantic model that receives a list of ParticipantsQueryParams, and returns data the same way we deserialized it last time.
from typing import Optional
import httpx
import pandas as pd
from pydantic import BaseModel, ConfigDict
class PoolingClient(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True, extra="forbid")
query_list: list[ParticipantsQueryParams] = Field(exclude=True)
_dataframe: Optional[pd.DataFrame] = None
# define a model_post_init() and a make_calls()
def model_post_init(self, __context: Any):
self.make_calls()
def make_calls(self):
url = "https://api.egytech.fyi"
headers = {"accept": "application/json"}
# create a client instance to make a series of API calls
with httpx.Client(base_url=url, headers=headers) as client:
# create a responses list to hold the deserialized response values
responses = []
for query in self.query_list:
response = client.get(
"/participants",
params=query.model_dump(
mode="json", exclude_none=True
),
)
# Cancel initialization if unsuccessful API call
if response.status_code != 200:
raise Exception("Unsuccessful API Call")
# Deserialize the received response
deser_response = response.json()
# Retrieve the last value from the deser_response dict
# and extend the responses list from it
responses.extend(list(deser_response.values())[-1])
# Construct a DataFrame from the compiled responses
self._dataframe = pd.DataFrame.from_records(responses)
# define a method get_dataframe() to retrieve the constructed df
def get_df(self):
return self._dataframe
Right now, our users can construct a list of ParticipantsQueryParams, pass it to the PoolingClient, and receive a DataFrame of the compiled participant survey data as follows:
from our_amazing_wrapper import ParticipantsQueryParams, PoolingClient
query1 = ParticipantsQueryParams(title = "backend", cs_degree = True)
query2 = ParticipantsQueryParams(title = "frontend", cs_degree = True)
queryn = ParticipantsQueryParams(title = "fullstack", cs_degree = True)
query_list = [query1, query2, queryn]
compiled_df = PoolingClient(query_list=query_list).get_df()
# Do amazing things with the DataFrame
Asynchronous API Calling
Background
Python is a language that support asynchronous programming very well. While this article is not dedicated to this concept, I recommend that you check out the RealPython primer article about it if you're not familiar with the concept.
Making API calls asynchronously yields a significant performance boost to your application. It utilizes the serve wait times to do other things in your code or even make more API requests. This significantly speeds up your code.
HTTPX also supports asynchronous API calls with its httpx.AsyncClient() class. It can also leverage connection pooling if all your API calls are being made to the same base URL, which is the case for our wrapper.
Using an AsyncClient in our wrapper would change the diagram shown above as follows:
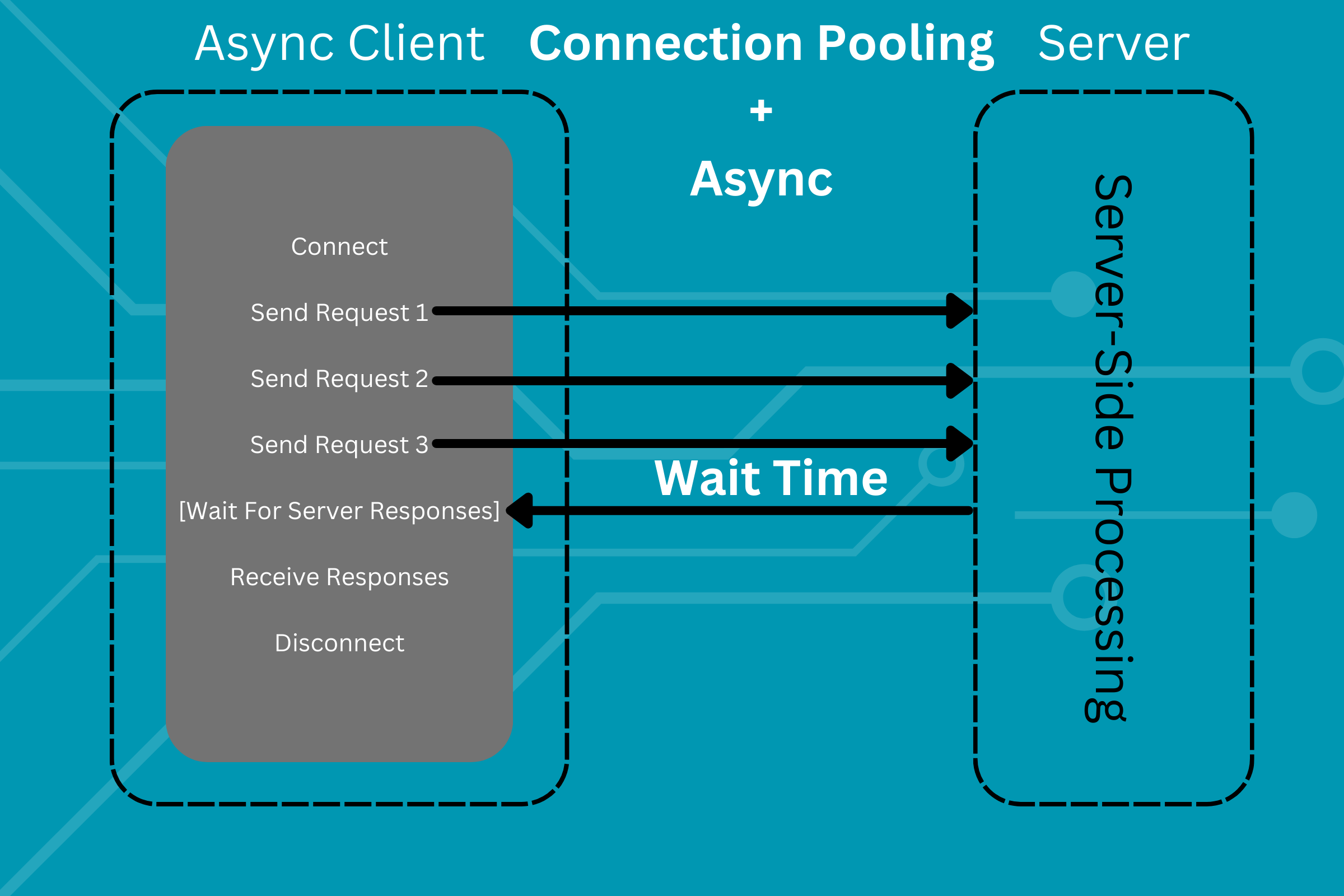
Granted, the wait time here is expected to be more than the aforementioned wait times, as the server processes more data. However, the overall performance of the code will be significantly higher. As mentioned before, these features are a bit of an overkill for an API of this scale, but it's useful to learn these basic concepts that significantly speed up your code.
import asyncio
import itertools
from typing import Optional
import httpx
import pandas as pd
from pydantic import BaseModel, ConfigDict
class AsyncPoolingClient(BaseModel):
model_config = ConfigDict(arbitrary_types_allowed=True, extra="forbid")
query_list: list[ParticipantsQueryParams] = Field(exclude=True)
_dataframe: Optional[pd.DataFrame] = None
def model_post_init(self, __context: Any):
asyncio.run(self.make_calls())
async def make_calls(self):
async def make_single_call(
query: ParticipantsQueryParams, c: httpx.AsyncClient
):
response = await c.get(
params=query.model_dump(mode="json", exclude_none=True),
)
if response.status_code != 200:
raise Exception("Unsuccessful API Call")
return response.json()["results"]
headers = {"accept": "application/json"}
client = httpx.AsyncClient(
base_url="https://api.egytech.fyi/participants", headers=headers
)
responses = await asyncio.gather(
*map(make_single_call, self.queries, itertools.repeat(client))
)
results = itertools.chain(*responses)
await client.aclose()
self._dataframe = pd.DataFrame.from_records(results)
def get_df(self):
return self._dataframe
Explaining The Code
We created an AsyncPoolingClient model, that functions almost exactly as the PoolingClient, but is very different under-the-hood.
First, we define a simple async function that receives an instance of httpx.AsyncClient and a instance of ParticipantsQueryParams, and makes the API call using these.
Then inside our make_calls function, we initialize an httpx.AsyncClient instance. We configure this instance with our common API call configuration.
We construct a series of tasks using a mapper that maps our query object (list of ParticipantsQueryParams) to the function that makes exactly one API call for an instance of ParticipantsQueryParams. We also ask the mapper to keep using the same client for all the tasks we have at hand, to prevent our wrapper from disconnecting and reconnecting, thus eliminating the unnecessary overhead. We extract the list of mapped function calls that the mapper produces. We call asyncio.gather() on this list of function calls. This executes our series of asynchronous API calls.
Finally, we flatten the list of responses we receive from our tasks. This flattened list of responses is then used to construct our DataFrame as we did before.
Note: our
AsyncPoolingClientmodel is not a truly asynchronous model, meaning that you wouldn't await aget_df()call on an instance of it. Instead, our model simply uses asynchronous API calls to make the specified series of API calls. There is no need to make a truly asynchronous implementation of our model, as most of it is not I/O-related procedures.
You can check the full source code for this article here. This code is licensed under the MIT license, which is very permissive. You can reuse it however you want.
Subscribe to my newsletter
Read articles from Abdulrahman Mustafa directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by