What the heck is Vector Database?
 Nayan Radadiya
Nayan RadadiyaThis article won't make you a wizard in vector databases but it will give you an overview of vector databases and how it works. So let's begin.
What do you mean by vector database?
If you are familiar with traditional databases then you might know that databases are just way to manage your data. That data can be represented as tabular format, document format, key-value pair or graph based. Similarly in vector databases you can store vector embedding in the database specifically designed to store vector embeddings in vector space.
Vector databases store similar embeddings closer to each other.
Wait! what are these vector embeddings?
Cool, Now you know about what we store in the database so let me tell you what vector embeddings are. You can understand vector embeddings as numerical representations of objects (such as words, sentences, images, or other data types) in a continuous vector space. For programmers like me, you can think of it as an array with bunch of numbers which somehow represents an object.
But how can you represent picture of my dog in numbers?
Conversion of your dog's picture to vector embedding can be done through deep learning. There are neural networks and pre-trained ML models like VGG-16 or RestNet50 available for conversion to vector embeddings. Here is the fun part. You can generate embeddings for audio, images, words, sentences or even documents. I know it looks like magic (Maybe it is for non machine learning person).
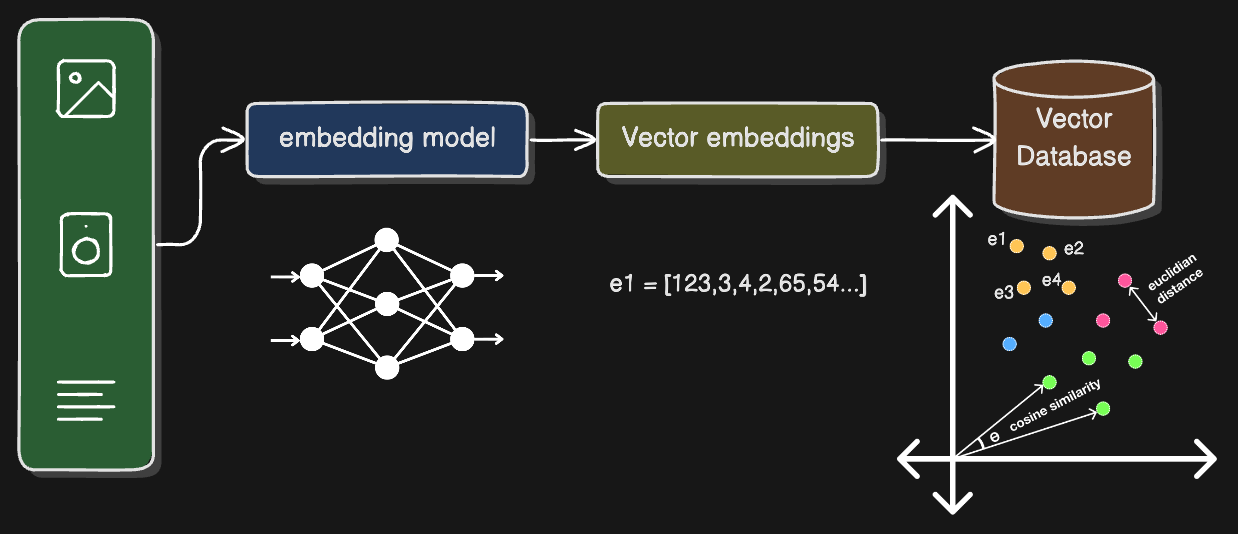
How do I retrieve my data?
Good question. There is no select * from .... in vector databases, instead you will retrieve data the way you stored. Yes, you heard it right. You have to create embedding for the data you want to search and vector db will give embeddings similar to your query and that's how you implement semantic search with vector databases.
And how do you find similar embeddings?
Now, this is a whole new topic on how similarity search and indexing work in vector databases, but I'll keep it short for now. If you know a bit of math, you might have heard about the Cartesian 2D plane. When storing new data, similar objects are placed closer to each other based on their embeddings. So, when you search for a new object, it fetches embeddings that are close to the new object's embeddings. This closeness can be measured using Euclidean distance or cosine similarity. This is how you can implement similar image searches or auto-correct words using vector databases.
Many so called AI startups are just good at handling vector database underneath
I know it might be overwhelming for you to understand this gigantic topic in one article without practical things so I might write next article on Vector database in action.
Subscribe to my newsletter
Read articles from Nayan Radadiya directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by