Streams, system calls, file descriptors, and inodes. A small trip through how file access and manipulation work.
 Mohamed Moataz El Zein
Mohamed Moataz El Zein
We all know that system calls are inherently "slow". Regardless of the reasoning behind why system calls are slow, it is common practice to try and "batch" them. A great example of that is how the read() and write() system calls are "batched" or "buffered" using the Streams API in libc, which we will delve into later.
System Calls
Let's take a small step back. What are system calls? A system call in simple terms is a way for a process to "call" the operating system and request some specific functionality. Some examples are the read system call, open system call, and many others. System calls may vary from kernel to kernel, and OS to OS, but there is a somewhat standardized "approach", organized by POSIX. You can use system calls directly (assuming you can write them in assembly), or you can simply rely on system libraries, like libc, which was mentioned above. Libc exposes functions that encapsulate system calls, which contain architecture-specific assembly, and so calling them is synonymous with making system calls. System calls are everywhere, but in this article, I'd like to focus on 2 main system calls, open(), and read().
In UNIX, everything is a file. This results in a simple interface. To access any file, you first need to open() it, and then you may read() it, poll() it, write() to it, etc. So what exactly does open() do? Without getting into much detail, which we will do later, open() expects a file path that you would like to open, the flags and mode for opening, and simply returns an integer, namely, a file descriptor. This file descriptor is going to be your key when needing to do any operations on said file. An example would be read(). Read() expects a file descriptor to "read from", a buffer in user space to "read into", and then the length needed to be read. That's all it is. You can read as little as you want (1 byte), or as much as you want. An example is shown below:
//simple_read.c
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#define BUFFER_SIZE 10
// gcc simple_read.c -o simple_read &&./simple_read
int main()
{
int file_descriptor = open("in.txt", O_RDWR);
char buffer[BUFFER_SIZE + 1];
read(file_descriptor, buffer, BUFFER_SIZE + 1);
buffer[BUFFER_SIZE] = '\0';
printf("Buffer data: %s\n", buffer);
close(file_descriptor);
}
Notice the close(). And yup, you guessed it, this is also a system call. This closes the file descriptor, and if you forget to close it, all file descriptors get automatically closed when the process exits.
Default file descriptors
Before moving on, it is important to note that ALL processes are initialized with 3 file descriptors, stdin, stdout, and stderr. File descriptor 0 is stdin, 1 is stdout, and 2 is stderr. What are those? Those are how the process interacts with input, shows output, and optionally shows errors. This is the official unistd.h library in C, and below are the macros defined for those file descriptors.
//File descriptors in unistd.h
#define STDIN_FILENO 0 /* standard input file descriptor */
#define STDOUT_FILENO 1 /* standard output file descriptor */
#define STDERR_FILENO 2 /* standard error file descriptor */
Now, let's see a quick example of their usage.
#include <unistd.h>
#include <stdio.h>
#include <string.h>
#define BUFFER_SIZE 10
// gcc default_fd.c -o default_fd &&./default_fd
int main()
{
char *msg = "Hello World";
write(STDOUT_FILENO, msg, strlen(msg));
// same as write(1, msg, strlen(msg));
write(STDERR_FILENO, msg, strlen(msg));
// same as write(0, msg, strlen(msg));
char buffer[10];
read(STDIN_FILENO, buffer, 10); // read input
// same as read(0, buffer, 10)
}
As you can see, we didn't have to call open() to get those file descriptors. Rather, they are given to the process by the operating system. So file descriptors 0, 1, and 2, are usually reserved.
System Calls are generally slow
You should always keep in mind though that system calls are slow. This is in part because the process needs to trap into the kernel, which "switches the context" to the kernel, allowing the kernel to read the args to the syscall from the registers, dispatch the needed system call handler, and then return the results to the process (if there are any). So ideally, in case of read() for example, you would like to read as many bytes as you can at once, to decrease the number of read() syscalls, while making sure not to run out of memory by reading large chunks at once. You can read() 10 bytes at once, or call read() 10 times, and read a single byte each time. Finding this balance may be tricky, and may require some performance metrics on your side.
Low-Level vs High-Level API
To combat said "slowness" of system calls, some wrappers around them were created. Namely, streams. Let's start with a small comparison:
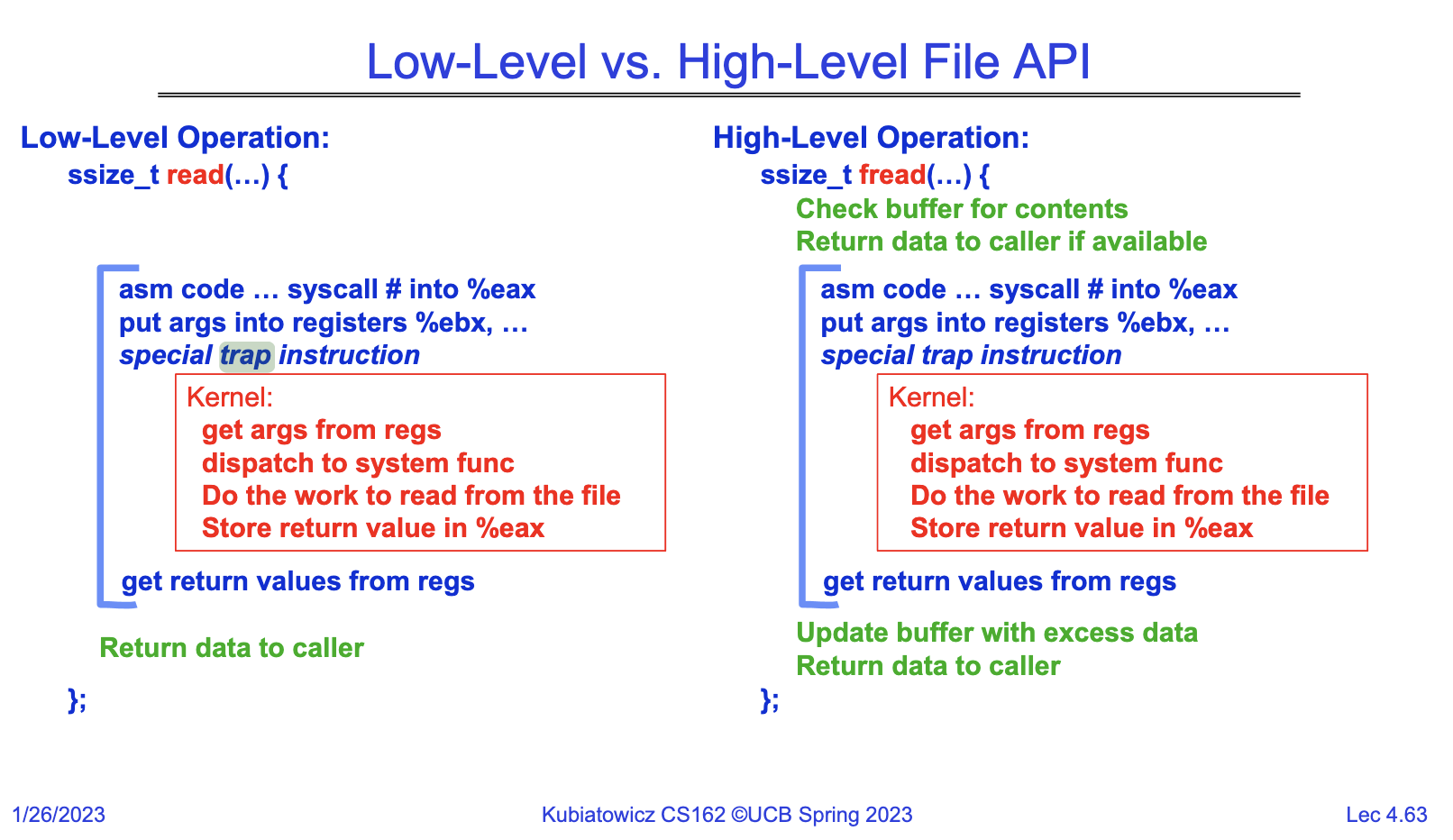
Low-level API: As mentioned above, the read() method in libc is not a system call itself, but rather, a wrapper that contains architecture-specific assembly code and trap instructions to execute the system call. There is no buffering or caching in the user space when calling read(), although that doesn't mean that there may not be caching anywhere else (kernel or disk caches). You simply give read a buffer and the number of bytes that you would like to read (usually the size of that buffer).
High-Level API: Since we would ideally like to buffer system calls, file streams were created. Streams are simply wrappersor structs that contain a buffer and a lock internally. They wrap the low-level system calls, like read(). So when requesting some bytes from a stream, it first checks if the data is present in the internal stream buffer. If it is, it avoids making a new system call, and rather serves the data from memory, while moving the position in the buffer. If the data that is needed isn't already in the buffer, then it simply attempts another syscall, buffers it, and returns the required data to the caller. In simple terms, when using streams, you may request 10 bytes at a time, but internally, the stream reads 1024 bytes, to avoid making syscalls in the future. Instead of read(), for streams, we use fread(), and instead of open(), we use fopen(). This happens for both reads and writes. You may be wondering, does fopen() return a file descriptor like open(), and does fread() expect this file descriptor, just like read()? The answer is no. fopen() returns a FILE* , and fread expects this FILE*. No, let's show you and example of streams buffering writes.
//streams_write_buffering.c
#include <stdio.h>
#include <unistd.h>
// RUN: gcc streams_write_buffering.c -o streams_write_buffering && ./streams_write_buffering
int main()
{
printf("Hello ");
sleep(5);
printf("World\n");
//Will the above print Hello, sleep, then print World?
//Or will Hello World suddenly get printed together?
write(STDOUT_FILENO, "Hello ", 6);
sleep(5);
write(STDOUT_FILENO, "World\n", 6);
//What about here?
}
If you were not aware, printf("") is a method that writes to the stdoutstream (not the file descriptor). Just like there are 3 default file descriptors, there are also 3 default streams! printf writes to the stdout stream, which means that the writes, in theory, should be buffered, and they are. They are buffered until the buffer gets full, in which case the output gets printed to the screen, or a "\n" is encountered. So in this first case, the output isn't "Hello" (sleep for 5 seconds) "World", but rather, we see that the program sleeps for 5 seconds, then prints out all the contents (streaminternallycalls write() syscall) of the buffer at once, which are "Hello World\n". In the second case though, we immediately write(), which triggers a syscall to write "Hello" to stdout file descriptor, after which the program sleeps, and then it completes and prints "World" to the stdout. That's a pretty neat experiment to try and I encourage you to give it a go. Try to comment out each case individually and see what happens. Below are the default streams.
streams in stdio.h
#define stdin __stdinp
#define stdout __stdoutp
#define stderr __stderrp
__BEGIN_DECLS
extern FILE *__stdinp;
extern FILE *__stdoutp;
extern FILE *__stderrp;
__END_DECLS
So now let's see read buffering using Streams in action in C. Let's assume we have a file in.txt that has the text "Sample test file". We want to read this file and write the output to out.txt. The following code proves that fread() reads 100 bytes into the internal stream buffer at first, even though we only request 5 bytes at a time.
#include <stdio.h>
#define READ_BUFFER_SIZE 5
#define STREAM_INTERNAL_BUFFER_SIZE 100
// gcc main.c - o main &&./ main
int main()
{
FILE *input = fopen("in.txt", "r"); //input stream
FILE *output = fopen("out.txt", "w"); //output stream
setvbuf(input, NULL, _IOFBF, STREAM_INTERNAL_BUFFER_SIZE); //resize the internal stream buffer to STREAM_INTERNAL_BUFFER_SIZE
printf("Stream internal buffer size: %d\n\n", input->_bf._size);
char buffer[READ_BUFFER_SIZE + 1]; // additional char for str termination
size_t len; //number of bytes read by fread into buffer
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
while (len > 0)
{
buffer[READ_BUFFER_SIZE] = '\0';
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
printf("Internal buffer data: '%s'\n", input->_bf._base);
printf("Internal buffer pos: %ld\n", ftell(input)); //next index to read from in the internal buffer
printf("\n");
fwrite(buffer, len, sizeof(char), output);
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
}
fclose(input);
fclose(output);
}
Let's see how we can go about this in C using the streams API, step by step.
#define READ_BUFFER_SIZE 5
#define STREAM_INTERNAL_BUFFER_SIZE 100
FILE *input = fopen("in.txt", "r"); //input stream
FILE *output = fopen("out.txt", "w"); //output stream
setvbuf(input, NULL, _IOFBF, STREAM_INTERNAL_BUFFER_SIZE); //resize the internal stream buffer to STREAM_INTERNAL_BUFFER_SIZE
printf("Stream internal buffer size: %d\n\n", input->_bf._size);
//Output: Stream internal buffer size: 100
First off, we start by declaring 2 new file streams, 1 for input, with the mode set to read, and 1 for output, with the mode set to write. As we agreed above, each stream contains a buffer. We would like to see the input streams buffer and re-size it, and we do it using the setvbuf method. This method takes the stream, a buffer pointer if present, the buffering mode, and the needed size of the buffer. We are only interested in the first and last parameters, and in this case, we resize the buffer of the input stream to be STREAM_INTERNAL_BUFFER_SIZE (100) bytes. To ensure that the stream buffer has indeed been resized, we printf the size, and we get the expected output.
char buffer[READ_BUFFER_SIZE + 1]; // additional char for str termination
size_t len; //number of bytes read by fread into buffer
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
while (len > 0)
{
buffer[READ_BUFFER_SIZE] = '\0';
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
printf("Internal buffer data: '%s'\n", input->_bf._base);
printf("Internal buffer pos: %ld\n", ftell(input)); //next index to read from in the internal buffer
printf("\n");
fwrite(buffer, len, sizeof(char), output);
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
}
Now we get to the meat and potatoes. First off, we initialize a buffer for reading from the file. We will read only 5 bytes at a time, plus keep only 1 byte for string termination. Then we start reading from the stream. We call fread() with the buffer to fill, along with its size, and pass the input stream. As a return value, we get the number of bytes actually read (max 5) in the len variable. We then add the string termination character to be able to print out the bytes read in the buffer.
Now let's talk about some numbers. The stream's internal buffer is 100 bytes. Our allocated buffer size is 5. The total number of bytes in the file is 16. So how do we expect the program to behave?
First fread() call should start a syscall that tries to read 100 bytes (to fill the internal buffer), but given that the file is only 16 bytes, it reads those 16 bytes and places them in the internal buffer. After this system call is successful, it then fills out the 5-byte char buffer we created with the first 5 bytes, and thus the returned len is 5. It then moves the internal buffer position to 5 (for the next read). Here is the output for the first loop.
Read bytes len: 5 -- Read bytes: 'Sampl'
Internal buffer data: 'Sample test file'
Internal buffer pos: 5
As we can see, the internal buffer data contains the whole file, and that's because as we agreed, all 16 bytes are now loaded into memory, but we are only getting served 5 bytes with each fread(). Each subsequent fread() reads 5 bytes, until the buffer is finally empty. Afterwards, we close the file streams, and the program exits. This way, rather than executing a read() syscall every 5 bytes, we execute it only once in the beginning. Here is the full program output.
Stream internal buffer size: 100
Read bytes len: 5 -- Read bytes: 'Sampl'
Internal buffer data: 'Sample test file'
Internal buffer pos: 5
Read bytes len: 5 -- Read bytes: 'e tes'
Internal buffer data: 'Sample test file'
Internal buffer pos: 10
Read bytes len: 5 -- Read bytes: 't fil'
Internal buffer data: 'Sample test file'
Internal buffer pos: 15
Read bytes len: 1 -- Read bytes: 'e'
Internal buffer data: 'Sample test file'
Internal buffer pos: 16
Although I didn't mention it above in this sample program, don't forget that writes to fwrite() are also buffered! That means that if you call fwrite() on a file without explicitly flushing the internal buffer afterward, the changes may or may not have been written to disk, so this is something to keep in mind when dealing with streams. Now that was fun! Let's move on to another super interesting topic, file descriptors, open file descriptions, and inodes!
File descriptors and Open file descriptions
So I briefly talked about read() above, and mentioned that you need to pass a file descriptor to it, which is received via a call to open(). So what exactly is a file descriptor, and what does it stand for? And what happens when a process opens the same file multiple times? Does it get the same file descriptor every time?
Open() creates an open file description entry in a system-wide table of open files in the kernel. This open file description object in the kernel represents an open file. Open() returns a file descriptor, which is an index to an entry in the process's table of open file descriptors. For each process, the kernel maintains a mapping from the returned file descriptor to the created open file description. So during calls to methods like read(), the kernel looks up the created open file description using the provided file descriptor. So there are currently 2 tables, the process's local table of open file descriptors, and the system-wide open file description table maintained by the kernel. Tldr, just imagine that each process has an array of file descriptors local to it. And the kernel has another array, of all the open file descriptions in the system.
// https://lxr.linux.no/#linux+v3.19/include/linux/file.h#L29
//File descriptor struct in linux
struct fd {
struct file *file;
unsigned int flags;
};
As we can see, each integer (file descriptor) returned from open() maps to the above fd struct. So what does each fd struct contain? It contains a pointer to the file struct, and as you may have guessed, this file struct is the open file description.
So to recap, you call open(), and you receive an integer (file descriptor). This integer is an index that maps to a struct fd. This struct fd then contains a pointer to the open file description. There can be multiple file descriptors pointing to the same open file description. The open file description contains information about the way the file is open, including the mode (read-only vs read-write, append, etc.), the position in the file, etc.
The Open File Description Struct (named file in linux)
// https://lxr.linux.no/#linux+v3.19/include/linux/fs.h#L804
// File description struct in linux
struct file {
union {
struct llist_node fu_llist;
struct rcu_head fu_rcuhead;
} f_u;
struct path f_path;
struct inode *f_inode; /* cached value */
const struct file_operations *f_op;
/*
* Protects f_ep_links, f_flags.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
struct mutex f_pos_lock;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void *f_security;
#endif
/* needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file */
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif /* #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
} __attribute__((aligned(4))); /* lest something weird decides that 2 is OK */
The fields that we might be interested in are
struct inode *f_inode; /* cached value */
loff_t f_pos;
The above struct is the open file description. The inode is a pointer to where to find the file data on disk along with metadata, and the loff_t f_pos tells us the current position in the file. Why is this needed? Well, think about this. When we execute a read() on this file descriptor, which points to this open file description, and we want to read() of 100 bytes, and then we execute a follow-up read(), how does the kernel know where to start from in the next read? Well, this is where the f_pos field comes in. It is incremented whenever a read() is issued to the kernel to keep track of the current position in the file to start reading from.
Fork() syscall
Another super interesting case is what happens when fork() is called? Well, fork() is also another syscall that creates another copy of the process, where the address space is duplicated, as well as the TCBs, as well as the file descriptor table! Don't worry, we will look at fork in more detail in the next article. Fork returns an integer on completion, which signifies whether the current process is the parent or the child. Essentially, fork() just spawns a completely new process. This subsequently means that either of the new processes can read from the same open file description and if one reads before the other, then when the other process starts reading, it will read from the following offset. Let's have a look with a simple program
#include <stdio.h>
#include <unistd.h>
#define READ_BUFFER_SIZE 5
#define STREAM_INTERNAL_BUFFER_SIZE 100
// gcc shared_open_file_description.c -o shared_open_file_description && ./shared_open_file_description
int main()
{
FILE *input = fopen("in.txt", "r");
setvbuf(input, NULL, _IOFBF, STREAM_INTERNAL_BUFFER_SIZE);
printf("Stream internal buffer size: %d\n\n", input->_bf._size);
char buffer[READ_BUFFER_SIZE + 1]; // additional char for str termination
size_t len;
pid_t p = fork();
if (p < 0)
{
perror("fork failed");
return -1;
}
if (p == 0)
{
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
printf("This is the child\n");
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
}
else
{
len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
printf("This is the parent\n");
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
}
fclose(input);
}
In this program, we run fork(), and keep in mind that when forking, there is no shared memory. Those aren't threads, but rather completely different processes. So the buffer isn't shared, rather, each process has its own copy. The "in.txt" file contains "Sample test file", and the output here is they both indeed read from the same open file description. This is proven since after the parent reads "Sampl", the child doesn't start over, but rather reads "e te".
Stream internal buffer size: 100
This is the parent
Read bytes len: 5 -- Read bytes: 'Sampl'
This is the child
Read bytes len: 5 -- Read bytes: 'e tes'
When we close() the file descriptor, well, the file descriptor struct is cleared, along with the open file description entry, assuming of course that this was the only file descriptor entry pointing to it. One thing to note is what happens if one of the forked processes closes its own file descriptor, maybe the parent. The open file description is certainly not cleared, because remember that another process, the child, is still pointing to it.
Now, what happens if we change the open() call to be after the fork() syscall and so the file descriptor is not shared? Each would have a separate file descriptor, pointing to a separate open file description, and both will start reading from the beginning of the file. Here is an example
pid_t p = fork();
if (p < 0)
{
perror("fork failed");
return -1;
}
if (p == 0)
{
FILE *input = fopen("in.txt", "r");
setvbuf(input, NULL, _IOFBF, STREAM_INTERNAL_BUFFER_SIZE);
printf("Stream internal buffer size: %d\n\n", input->_bf._size);
char buffer[READ_BUFFER_SIZE + 1]; // additional char for str termination
size_t len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
printf("This is the child\n");
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
}
else
{
FILE *input = fopen("in.txt", "r");
setvbuf(input, NULL, _IOFBF, STREAM_INTERNAL_BUFFER_SIZE);
printf("Stream internal buffer size: %d\n\n", input->_bf._size);
char buffer[READ_BUFFER_SIZE + 1]; // additional char for str termination
size_t len = fread(buffer, sizeof(char), READ_BUFFER_SIZE, input);
printf("This is the parent\n");
printf("Read bytes len: %zu -- Read bytes: '%s'\n", len, buffer);
}
//Output:
//Stream internal buffer size: 100
//This is the parent
//Read bytes len: 5 -- Read bytes: 'Sampl'
//Stream internal buffer size: 100
//This is the child
//Read bytes len: 5 -- Read bytes: 'Sampl'
This behavior is the same when opening the same file multiple times from our process. In this case, you get a new file descriptor for each file, as well as a new open file description entry. Below is some code to drive this point home.
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#define BUFFER_SIZE 10
// gcc multi_simple_read.c -o multi_simple_read &&./multi_simple_read
int open_and_read()
{
int file_descriptor = open("in.txt", O_RDWR);
printf("File descriptor: %d\n", file_descriptor);
char buffer[BUFFER_SIZE + 1];
read(file_descriptor, buffer, BUFFER_SIZE + 1);
buffer[BUFFER_SIZE] = '\0';
printf("Buffer data: %s\n", buffer);
return file_descriptor;
}
int main()
{
int fd1 = open_and_read();
int fd2 = open_and_read();
close(fd1);
close(fd2);
}
//Output:
//File descriptor: 3
//Buffer data: Sample tes
//File descriptor: 4
//Buffer data: Sample tes
Why is fork() behavior interesting? Because this is how the shell "usually works". When running "cat in.txt" for example, the shell forks a new process. This process has a copy of the file descriptors of the original process, so it shares the STDIN, STDOUT, and STDERR file descriptors, and thus the same open file description. This means that when a child process starts to write to its STDOUT, it is actually writing to the STDOUT of the shell as well, so they both write to the terminal, and we can see the output of "cat" on the same terminal as the shell that forked it.
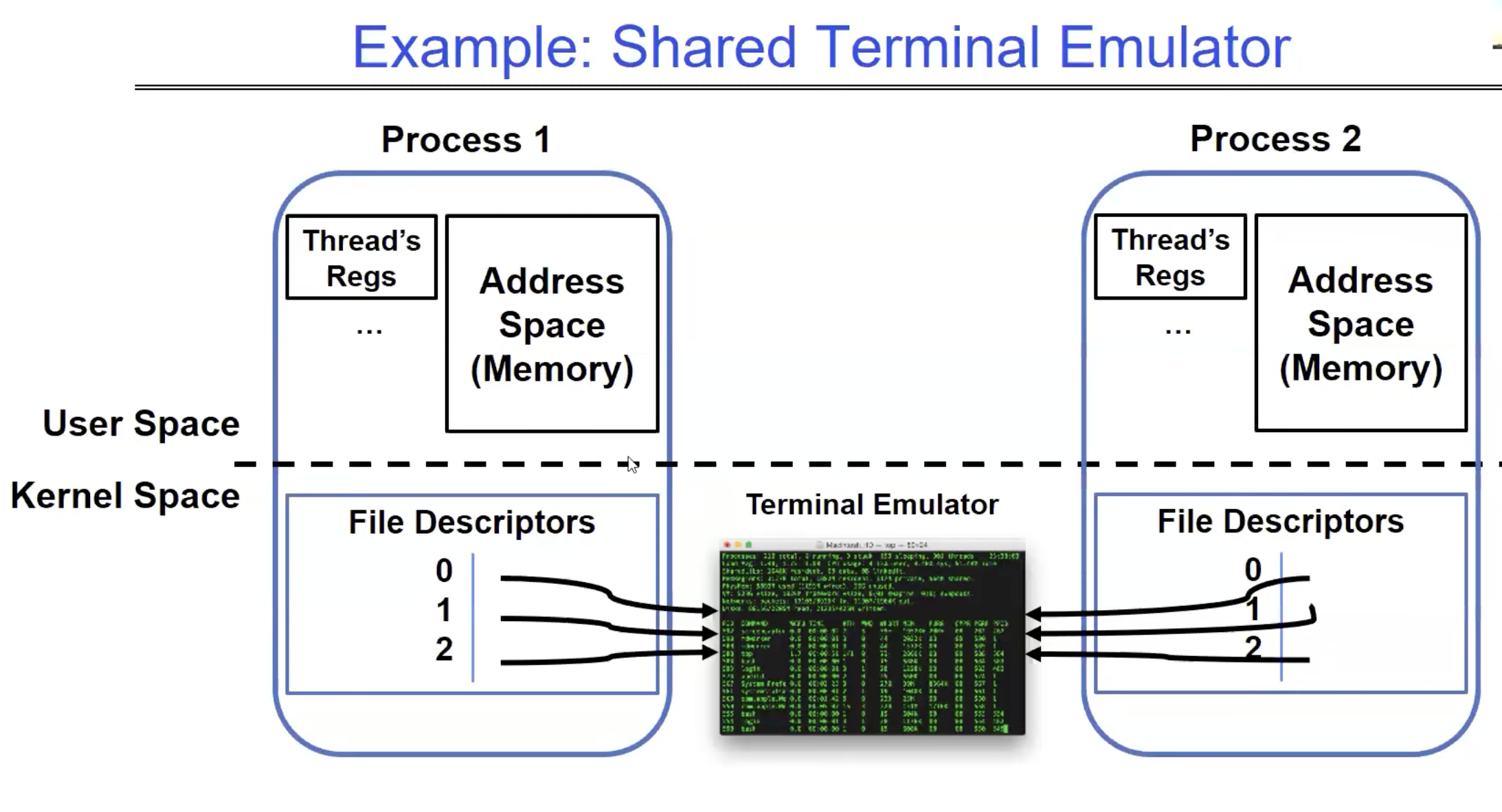
Well, I hope that was as fun for you as it was for me!
References:
Berkley CS162 Lecture 4 https://www.youtube.com/watch?v=WHmmT_syaG8
Linux Man Pages
And a lot of other stuff :)
Subscribe to my newsletter
Read articles from Mohamed Moataz El Zein directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by