Building a Serverless Resume API with AWS, Terraform, and GitHub Actions
 Gopi Vivek Manne
Gopi Vivek Manne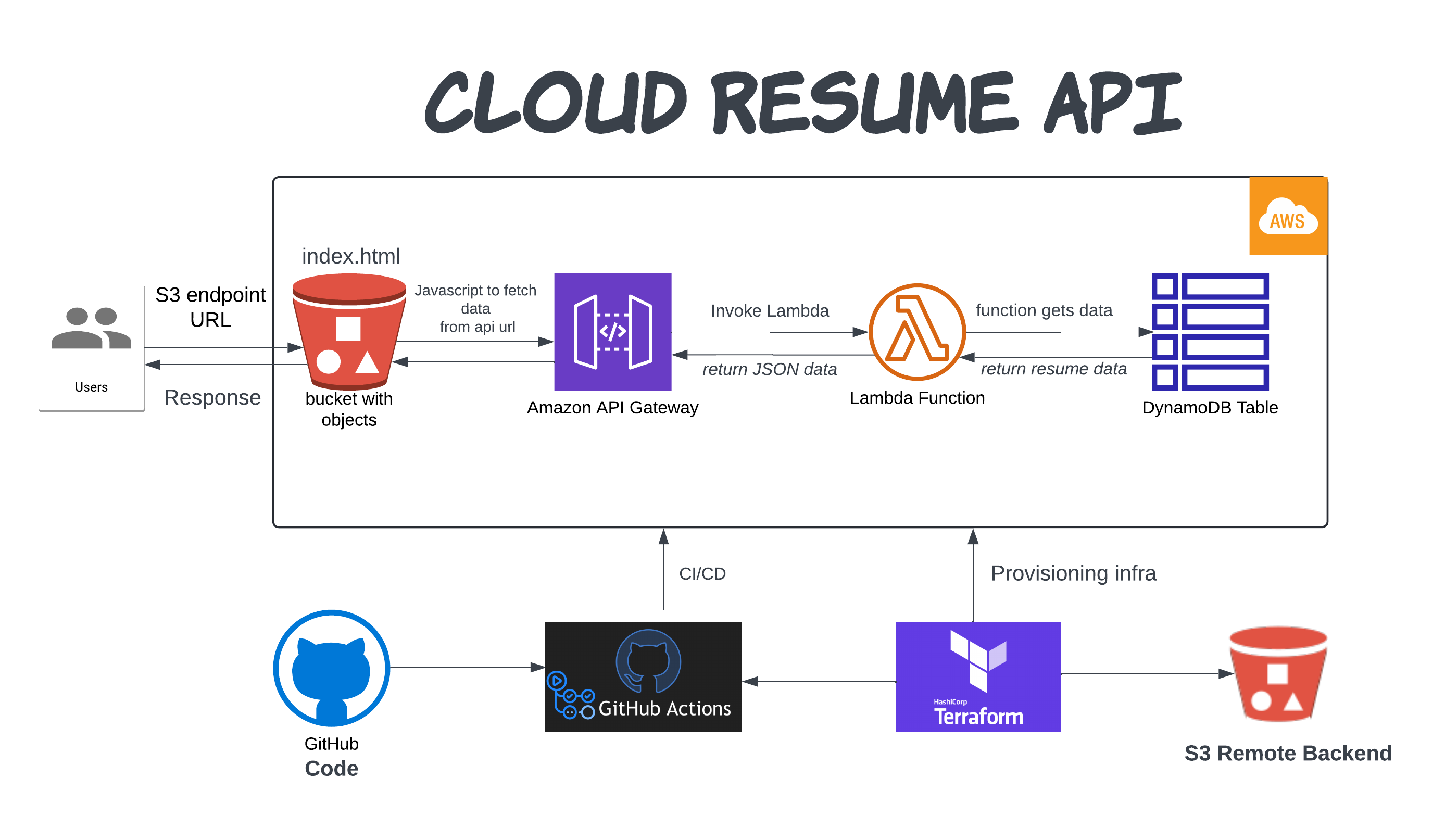
The Cloud Resume API Challenge (CRAC) provides a unique opportunity to demonstrate proficiency in building a serverless API that serves resume data dynamically. In this article, we'll walk through the steps to successfully complete the challenge using AWS services, Terraform for infrastructure provisioning, and GitHub Actions for automated deployment.
🛠️ Prerequisites
Before diving into the project, ensure you have the following:
AWS Account: You'll need an AWS account to create AWS services.
Terraform Installation: Install Terraform locally to manage infrastructure as code (IaC) for local testing purpose only.
AWS CLI Configuration: Set up the AWS CLI installed and configured locally for testing purpose only.
🌐 Project Overview
The goal is to create a serverless API that serves resume data in JSON format. When a user accesses a specific S3 endpoint URL, an index.html page hosted on an S3 bucket used JavaScript to fetch API to retrieve dynamically fetch resume data from an API Gateway endpoint, which in turn retrieves data from a DynamoDB table via Lambda function.
Step-by-Step Approach
1. Infrastructure Provisioning with Terraform
First, let's automate the infrastructure setup using Terraform:
Create a DynamoDB Table: Define a DynamoDB table to store resume JSON data.
Define Lambda Function: Write a Lambda function in Python to fetch data from DynamoDB and return it in JSON format.
IAM Role and Policies: Create an IAM service role for Lambda and attach policies like
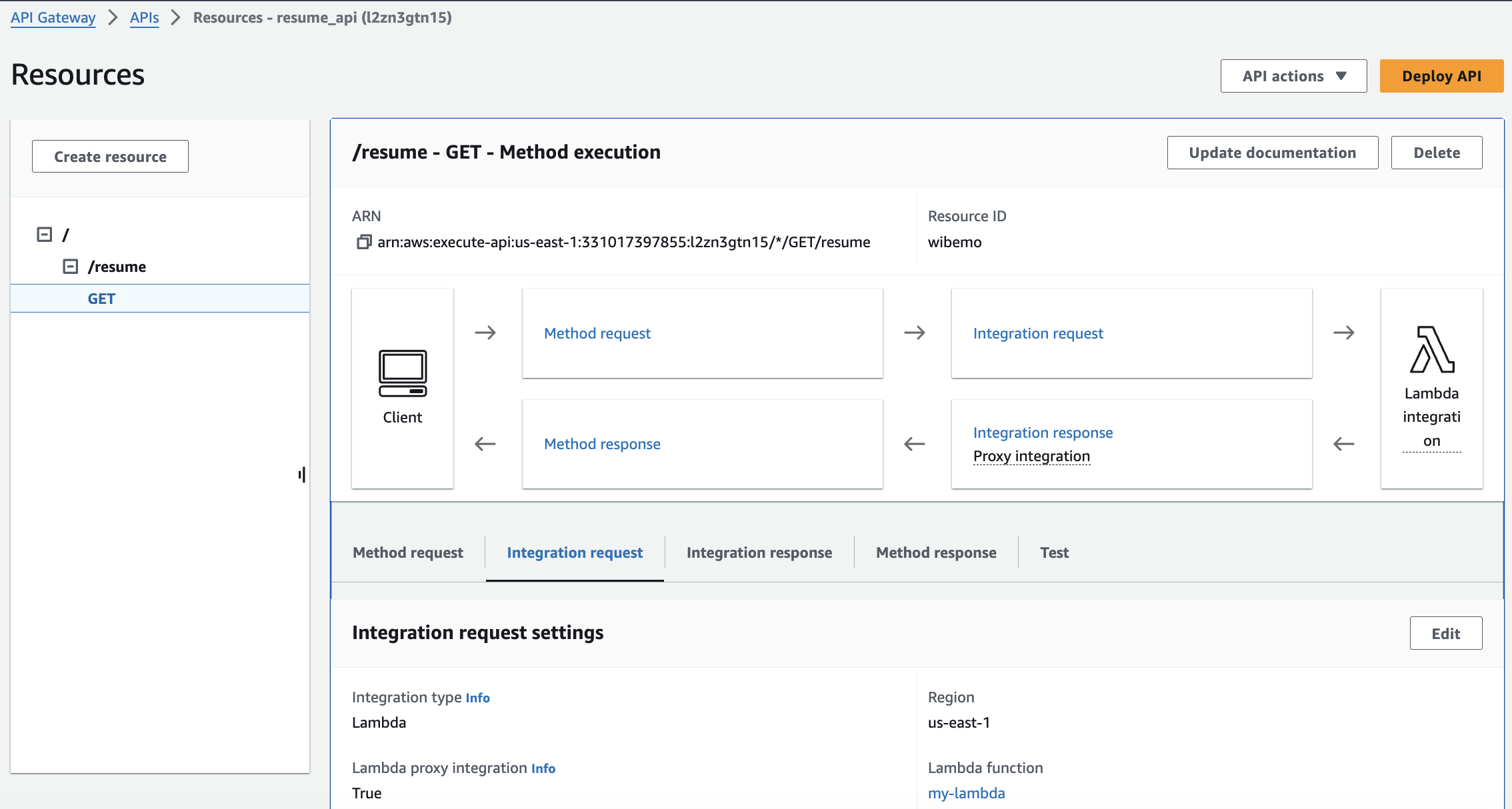
AWSLambdaBasicExecutionRoleanddynamodb_read_policyfor necessary permissions.Set Up API Gateway: configure an API Gateway REST API type, create a resource named 'resume' with a GET method for that resource
Integrate Lambda with API Gateway: Use the
AWS_PROXYintegration to connect API Gateway to the Lambda function.Permission for Lambda to be invoked by API Gateway: Explicitly set permission for lambda to be invoked by api gateway as
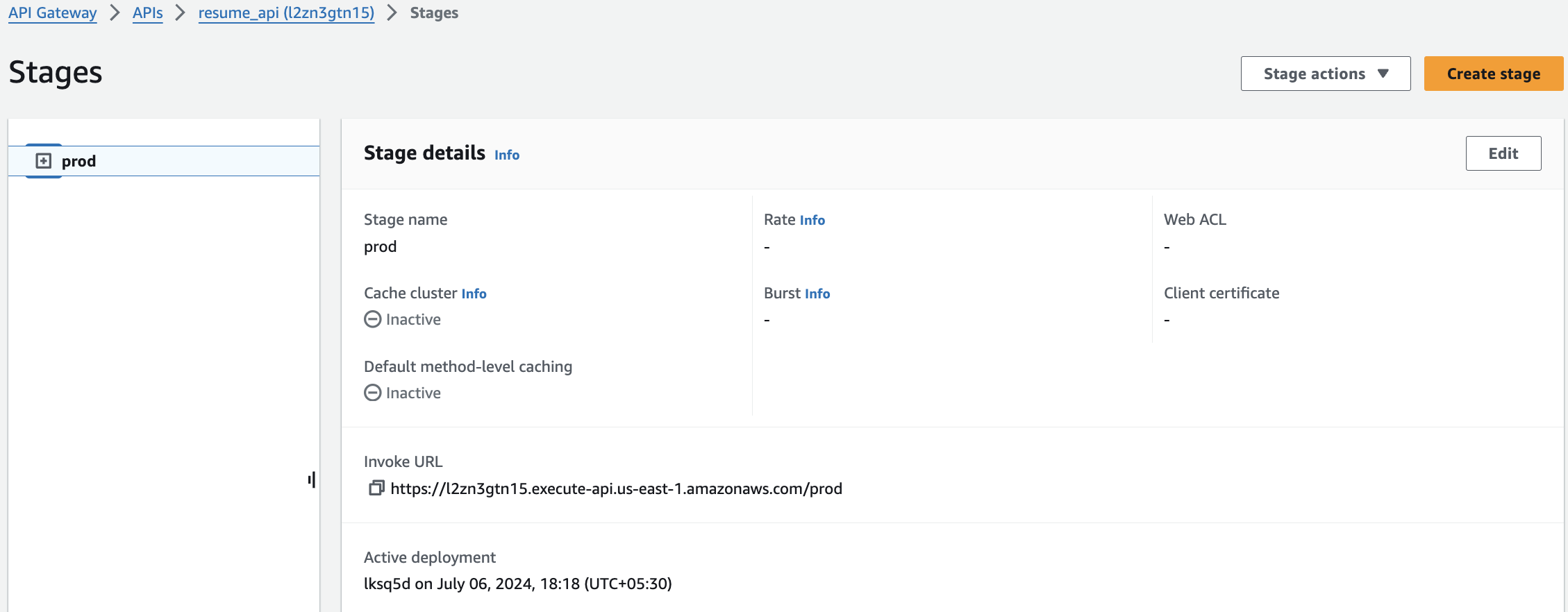
source_arnDeploy API Gateway: Deploy the API Gateway with a stage named
prodto make it accessible.
2. Configure S3 Bucket and Website Hosting
Next, Create the S3 bucket to host the index.html page and allow public access:
Create an S3 Bucket: Set up an S3 bucket and allow public access, static website hosting enabled.
Bucket Policy: Define a bucket policy to allow public access to objects (
index.html) while restricting access to theterraform.tfstatefile.
Uploadindex.html: Upload an (index.html) file that uses JavaScript to fetch data from the API Gateway endpoint dynamically.
Please refer the below attached configuration file link for better understanding: main.tf file
3. GitHub Actions for CI/CD Automation
Now, automate the deployment process using GitHub Actions:
Set Up GitHub Secrets: Store sensitive information like
AWS_ACCESS_KEY_ID,AWS_SECRET_ACCESS_KEY, andS3_BUCKET_NAMEsecurely as GitHub Secrets.Create Terraform Workflow: Write a GitHub Actions workflow (
terraform-workflow.yaml) to trigger on every push to the main branch or changes to Terraform configuration files (*.tf) insideterraformdirectory. This workflow initializes Terraform, applies changes, and manages state using an S3 backend.Deploy Resume Data: Implement a separate GitHub Actions workflow (
s3-deploy.yaml) triggered after infrastructure provisioning. This workflow updates the resume data in the S3 bucket, ensuring the latest version is always available.
NOTE: During the initial GitHub Actions workflow run for terraform-workflow.yaml, obtain the API_GATEWAY_URL. Replace its value in the index.html file. Subsequent workflow runs will proceed smoothly with this updated configuration.
⭐ Workflow-1: terraform-workflow.yaml
# This workflow will be triggered for every change inside the terraform directory, on every push to the main branch.
# The pipeline executes Terraform apply to provision infrastructure changes.
name: 'Terraform CI/CD'
on:
push:
branches:
- main
paths:
- 'terraform/**'
- '.github/workflows/terraform-workflow.yaml'
jobs:
terraform:
name: 'Terraform'
runs-on: ubuntu-latest
environment: dev
defaults:
run:
working-directory: ./terraform
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-east-1
- name: Setup Terraform
uses: hashicorp/setup-terraform@v1
with:
terraform_version: 1.8.0
- name: Create S3 bucket for Terraform state
run: |
aws s3api create-bucket --bucket viviterraformstatebucket --region us-east-1
continue-on-error: true
- name: Terraform Init
run: terraform init
- name: Terraform Plan
run: terraform plan -out=tfplan
#- name: Terraform apply
# run: terraform apply -auto-approve
- name: Terraform destroy
run: terraform destroy -auto-approve
⭐ Workflow-2: s3-deploy.yaml
# This workflow will be triggered for every change inside the src directory, on every push to the main branch.
# This workflow will also be auto triggered upon execution of Terraform CI/CD workflow.
# This pipeline will deploy all changes to files to s3 bucket.
name: 'S3 Deployment'
on:
push:
branches:
- main
paths:
- 'src/**'
- '.github/workflows/s3-deploy.yaml'
workflow_run:
workflows: ["Terraform CI/CD"]
types:
- completed
jobs:
deploy:
name: 'Deploy to S3'
runs-on: ubuntu-latest
environment: dev
steps:
- name: Checkout
uses: actions/checkout@v2
- name: Configure AWS Credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: us-east-1
- name: Deploy to S3
run: |
aws s3 sync src/ s3://${{ secrets.S3_BUCKET_NAME }}
💁 What this setup achieves
Clear separation between infrastructure provisioning and application deployment.
Terraform state stored in S3 backend.
Secure handling of AWS credentials using GitHub Secrets.
Automated infrastructure updates when changes are pushed to main branch.
Automated deployment of website content when changes are pushed to s3 branch.
🚧 Challenges faced:
JSON Formatting for DynamoDB: To populate JSON data into a DynamoDB table using Terraform, it's crucial to format the JSON according to DynamoDB's attribute map structure. This approach ensures compatibility with Terraform's insertion process without needing additional encoding or decoding steps(pass the raw updated JSON file).
Secrets specific to the dev environment, missed referencing the environment dev in the workflow.
GitHub Actions Integration: Set up access keys and permissions correctly to allow GitHub Actions workflows to interact with AWS services securely. I missed creating access keys for applications running outside AWS - as GitHub actions needs to run workflows
Overlooked API Gateway-Lambda function permissions explicit invocation needed despite integration was made to api-gateway.
Initially, I tried using same S3 bucket for both hosting
index.htmland storing Terraform state, with restrictive access policies. Eventually, I decided on a dedicated bucket for Terraform state to enhance management and security.
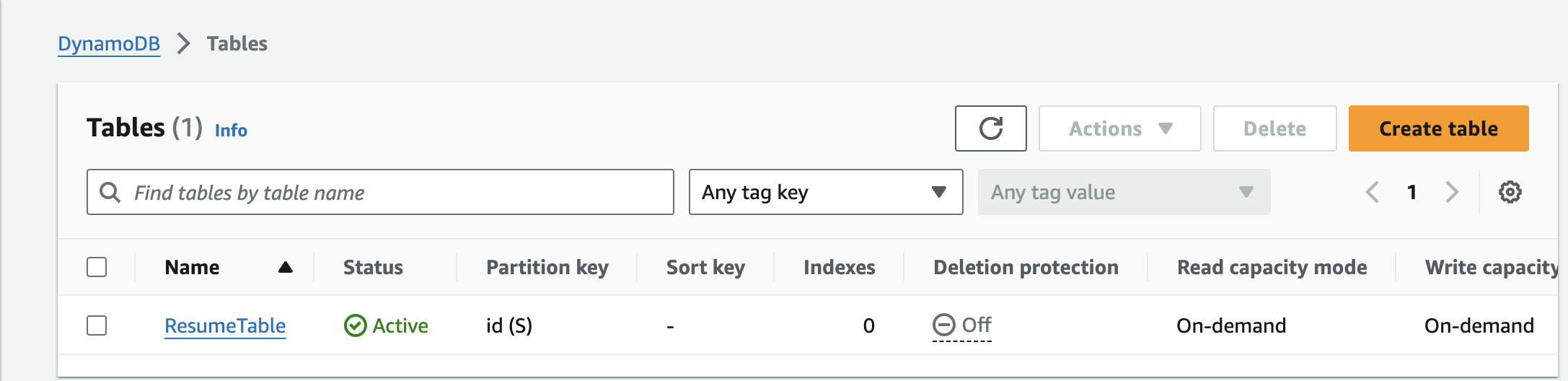
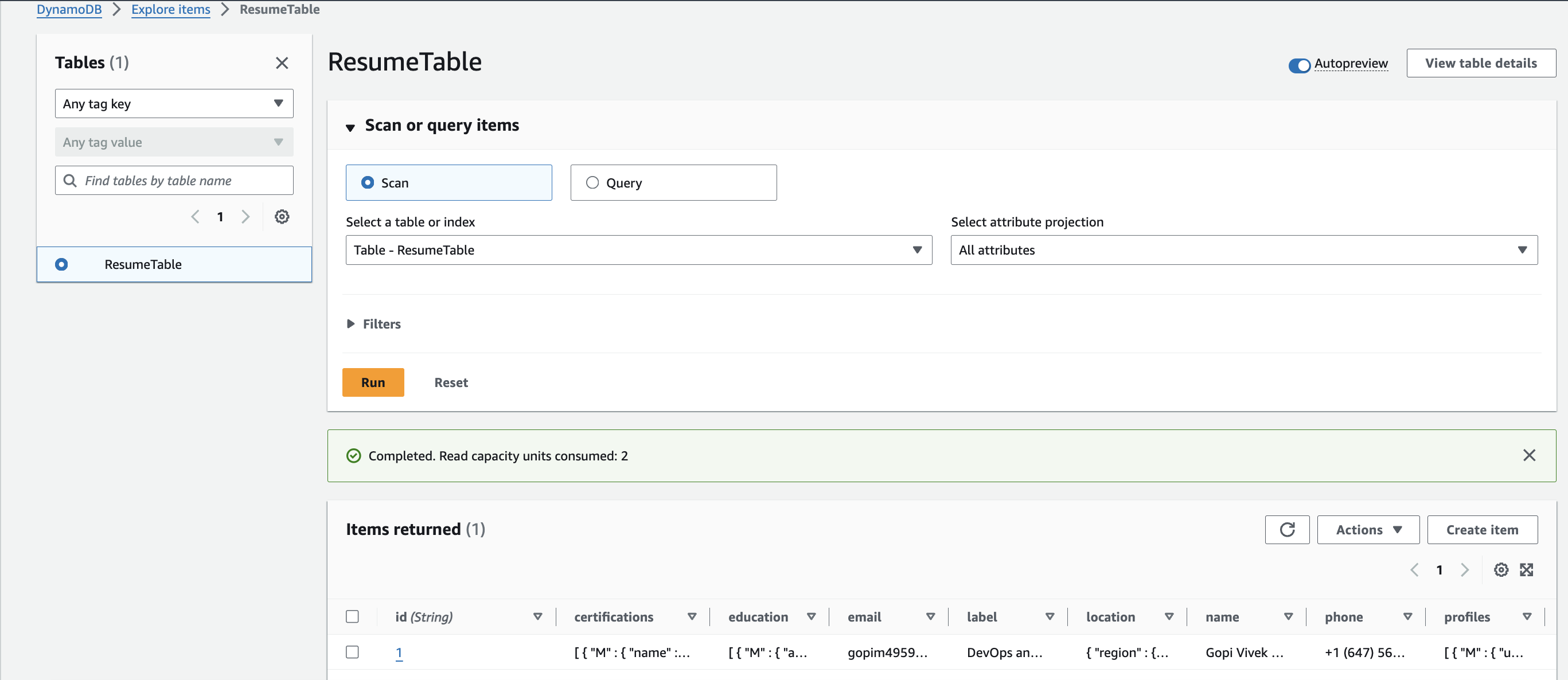
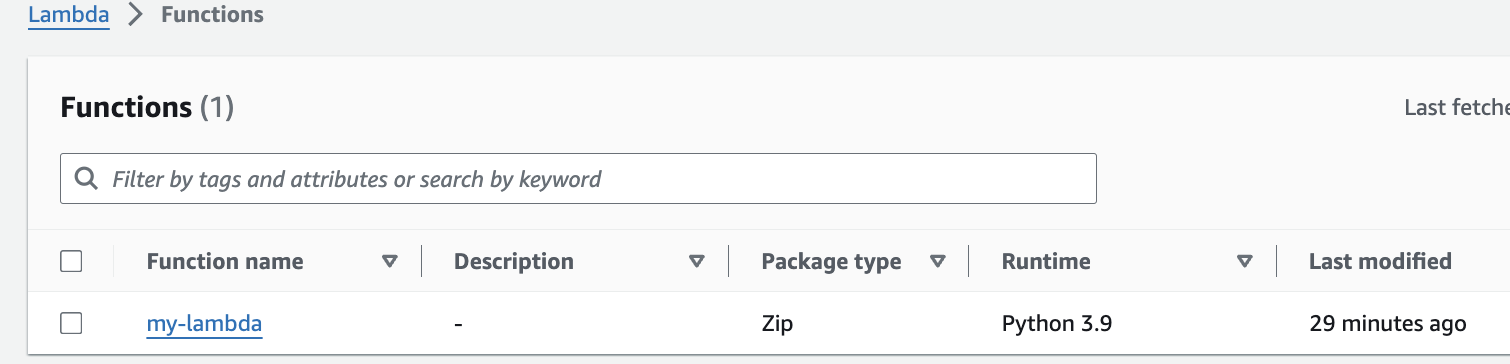
Attached Screenshots of the resources for your reference:
- DynamoDB Table
- Lambda Function
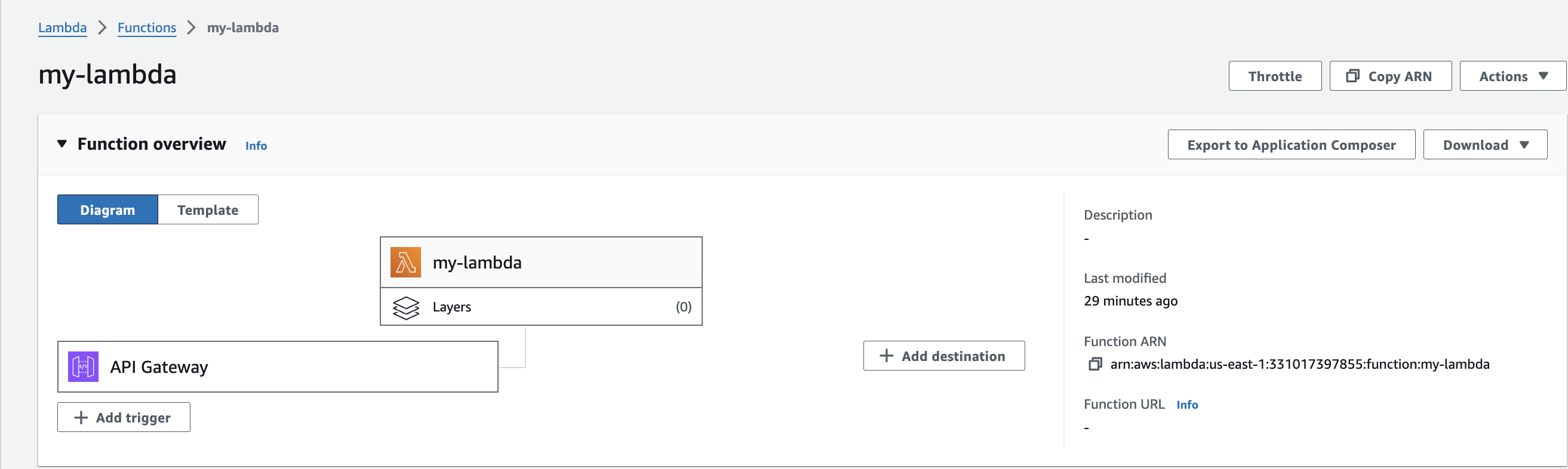
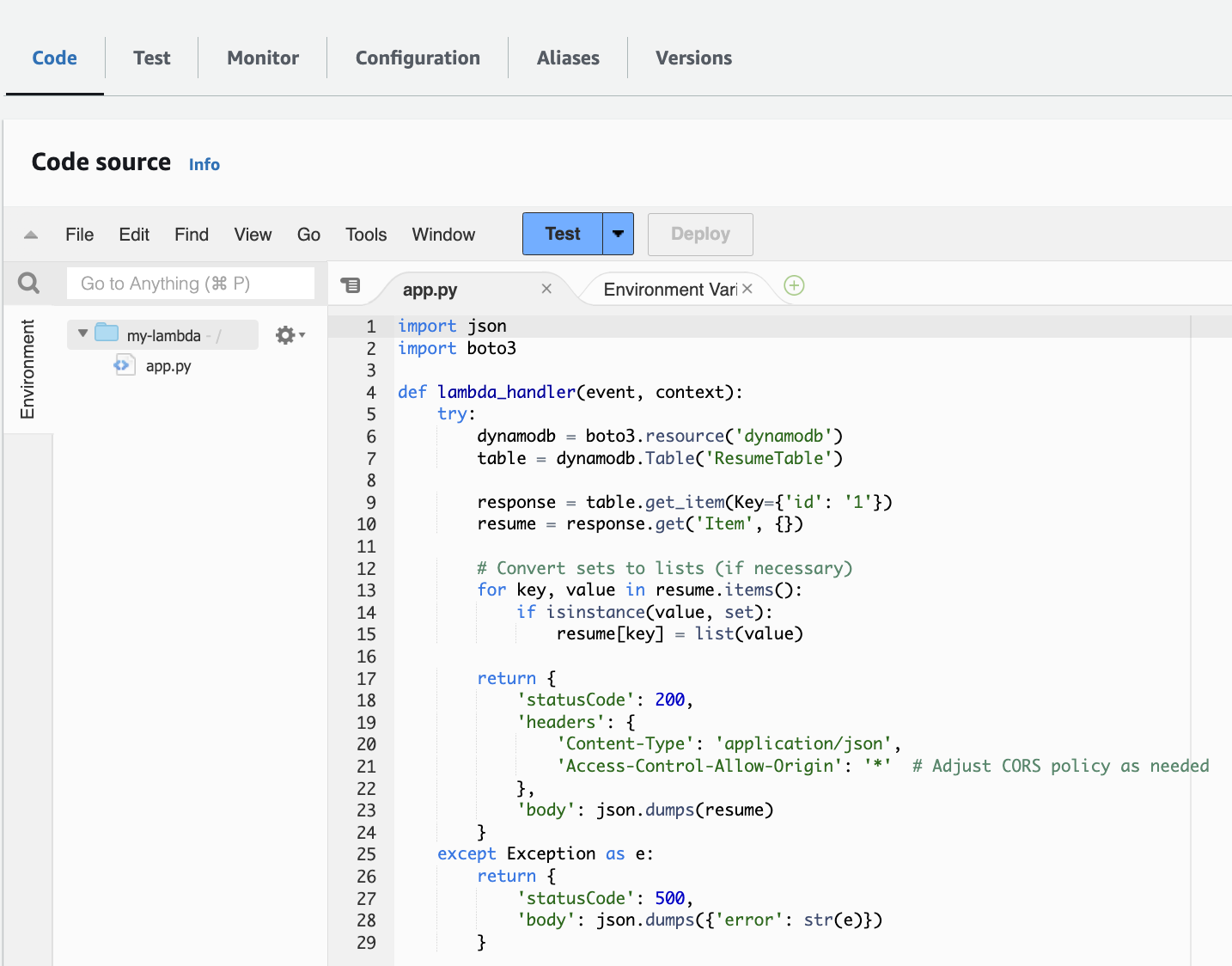
- API Gateway
- S3 Buckets

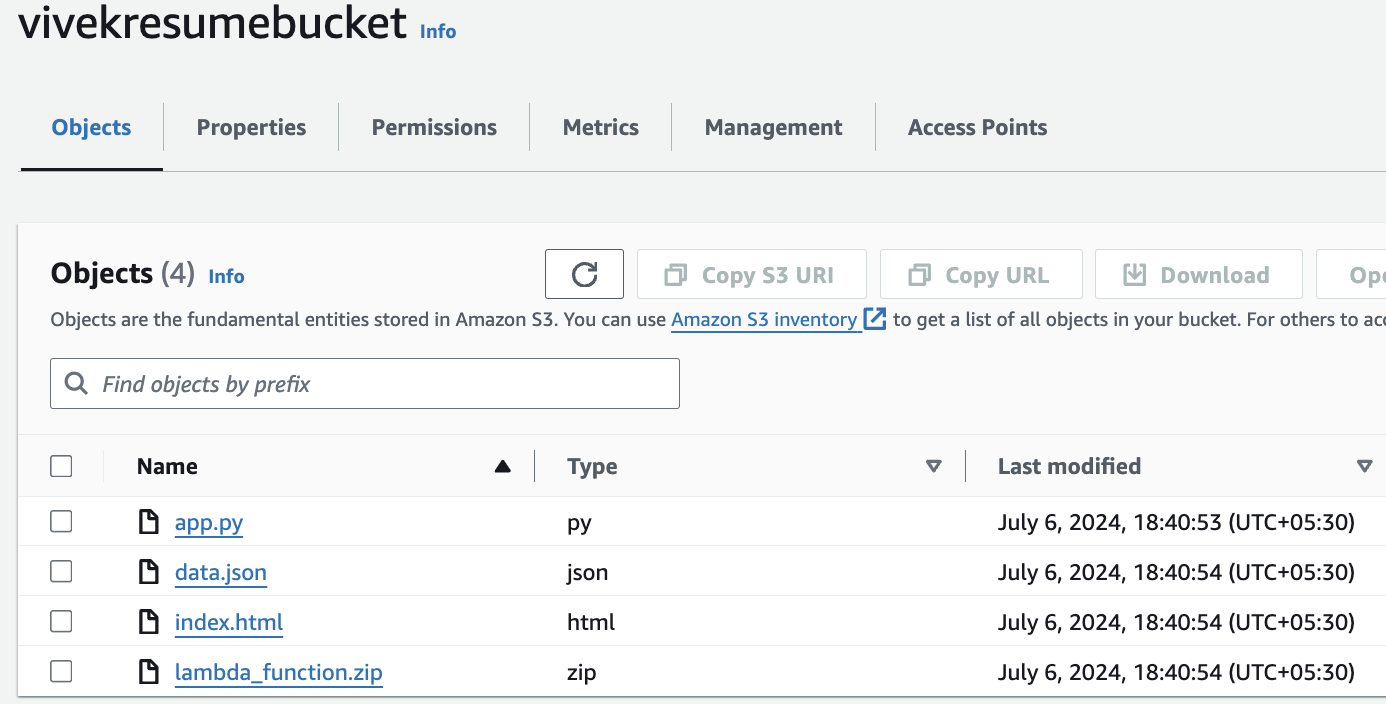
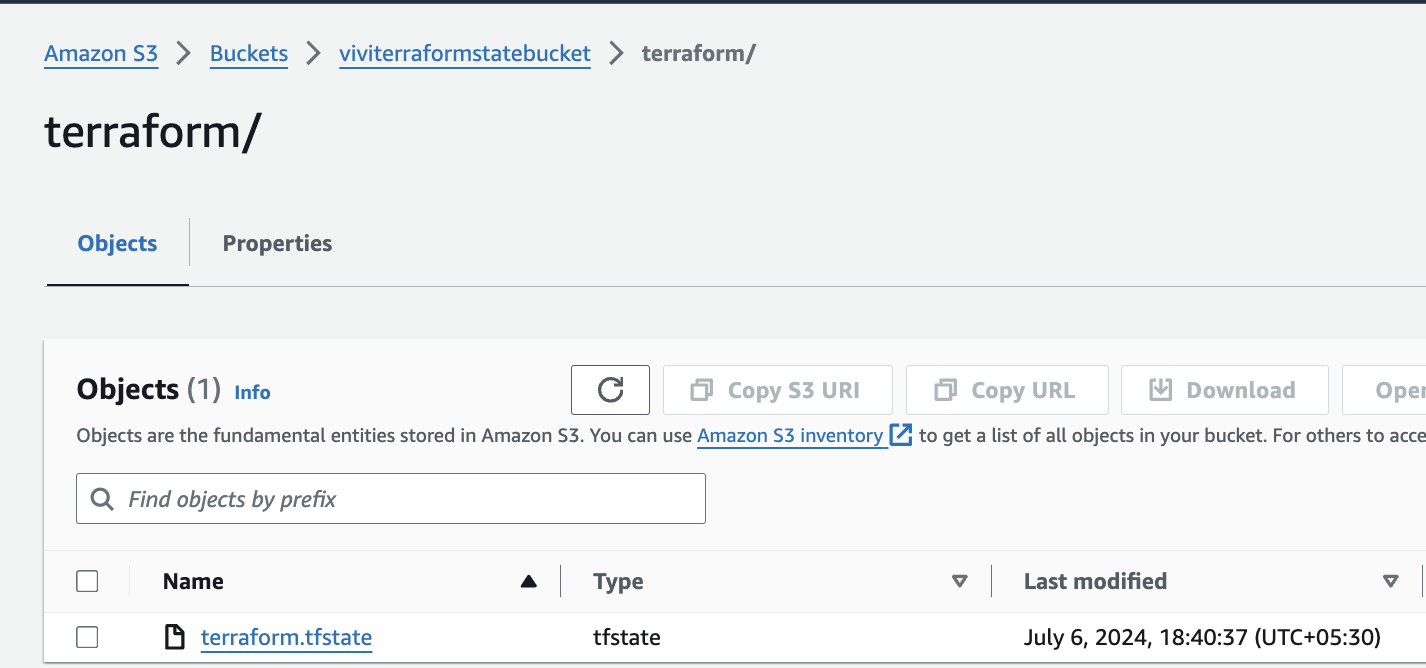
- Workflows Deployment
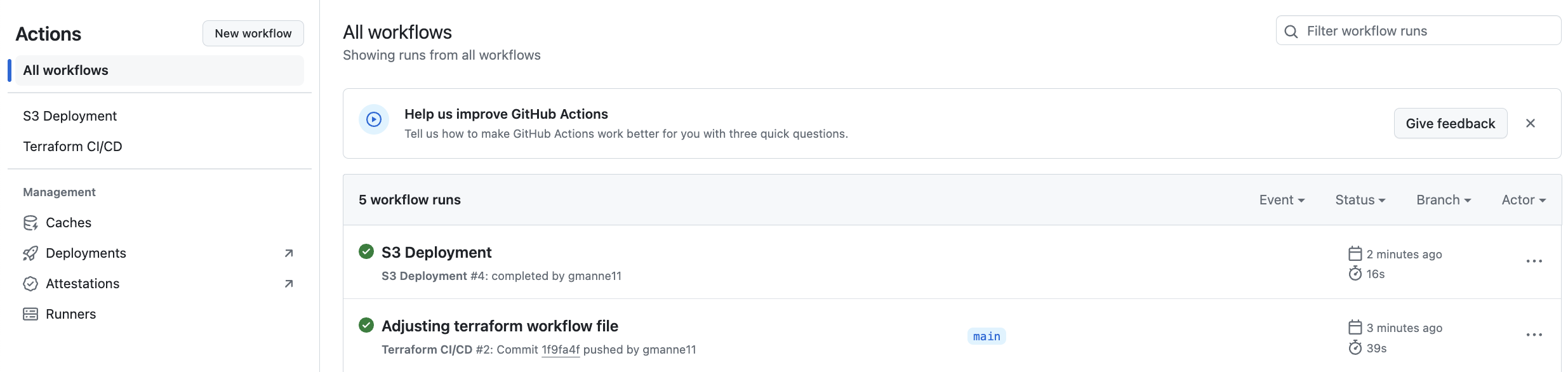
By following these steps, I have a fully automated deployment pipeline that fetches resume data from DynamoDB via a Lambda function and API Gateway, and serves a static website from an S3 bucket, all managed by GitHub Actions.
Please checkout the Git repository for your reference: https://github.com/gmanne11/CloudResumeAPI
Subscribe to my newsletter
Read articles from Gopi Vivek Manne directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gopi Vivek Manne
Gopi Vivek Manne
I'm Gopi Vivek Manne, a passionate DevOps Cloud Engineer with a strong focus on AWS cloud migrations. I have expertise in a range of technologies, including AWS, Linux, Jenkins, Bitbucket, GitHub Actions, Terraform, Docker, Kubernetes, Ansible, SonarQube, JUnit, AppScan, Prometheus, Grafana, Zabbix, and container orchestration. I'm constantly learning and exploring new ways to optimize and automate workflows, and I enjoy sharing my experiences and knowledge with others in the tech community. Follow me for insights, tips, and best practices on all things DevOps and cloud engineering!