Build your own JSON Parser in C (Day-1)
 Kaif Khan
Kaif KhanIntroduction
Welcome to our first day of building a JSON parser from scratch in the C programming language. Before we start implementing it, let's briefly go over what our JSON parser does. Generally, a JSON parser takes a JSON string and converts it into a data structure, allowing us to easily access values by providing the key.
Scope
So, what will we implement? Generally, parsing is broken into two steps:
Lexical Analysis (Lexer)
Syntactic Analysis (Parser)
We will implement both of these slowly and in simple steps.
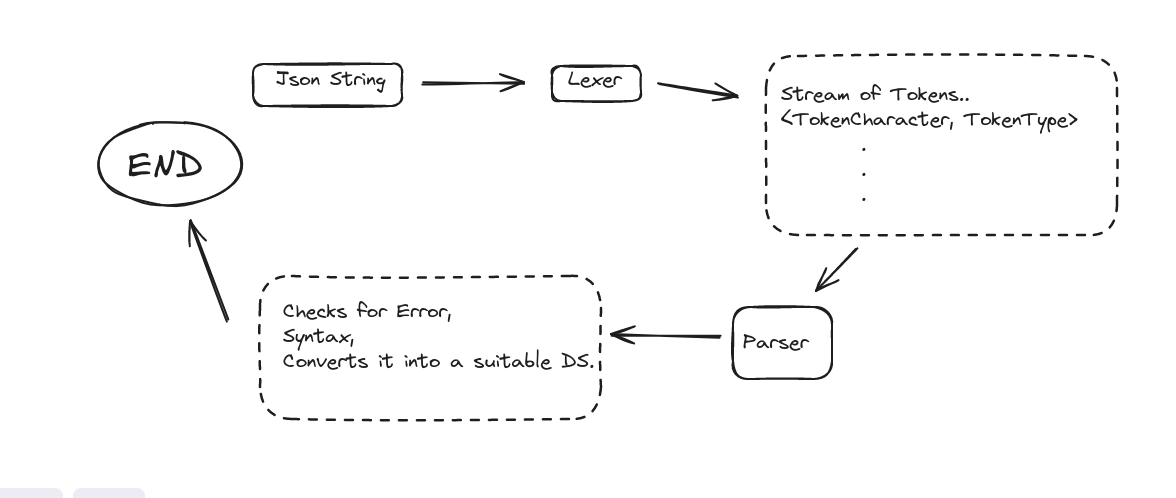
Today (Day 1), we will create a basic Lexer that recognizes { (start of an object) and } (end of an object) and a small Parser that checks for a closing }.
So, let's just dive into it and code our way through.
Implementation (Day-1)
Lexer
What is a Lexer? Well here is your answer.
First, we implement a Lexer that recognizes both of this token.
#ifndef LEXER_H
#define LEXER_H
#include<stdio.h>
#include <string.h>
#include <stdlib.h>
enum TokenType{
StartObject,
EndObject
};
typedef struct Token{
char ch;
enum TokenType t_type;
}Token;
#endif
[lexer.h]
We start by defining the enum TokenType , which currently has two values: StartObject and EndObject. Next, we define a struct named Token that will store a character value and the type of Token.
If we get a *{* as our input, we store it as
Token having value as <'{',StartObject>.
Now we define a Response structure which stores array of Tokens named token_container and the length of token_container.
typedef struct Response{
Token* token_container;
size_t length;
}Response;
Now we define our first function lexer which returns our Response struct.
struct Response lexer(char* json_string){
size_t len_json_string = strlen(json_string);
printf("%s is the string,%zu is size\n",json_string,len_json_string);
Token* token_container = (Token*) malloc(len_json_string*sizeof(Token));
What does this function do exactly? This function takes a JSON string as a parameter (we will see it called from the main function). It allocates a dynamic array on the heap using malloc. The size of our TokenContainer at most will be equal to the number of individual tokens in the string, so we allocate sizeof(Token) * length_of_json_string on the heap.
for(int i=0;i<len_json_string;++i){
consume_token(json_string[i],token_container,i);
}
//We define this later//
//debug_print(token_container,len_json_string);
Response resp;
resp.token_container = token_container;
resp.length = len_json_string;
return resp;
}//end of function
Then, for each character in the string, it calls a consume_token function (which we will define shortly). This function takes a character from the JSON string, our dynamically allocated token_container (a pointer to it), and the index i. After consuming all the tokens and populating our token_container with them, we return the response.
Now comes the main part of our Lexer, consume_token function. Let's define it and then we explain what does it do.
void consume_token(char token,Token* token_container,int i){
Token t;
switch (token)
{
case '{':
/* code */
t.ch = token;
t.t_type = StartObject;
break;
case '}':
t.ch = token;
t.t_type = EndObject;
break;
default:
printf("%c not valid",token);
exit(EXIT_FAILURE);
break;
}
token_container[i] = t;
}
It's pretty simple, right? For now, we will handle just { and }. If it's either of these, we label it and store it in our token_container. If we encounter anything else, it will throw a lexer error and exit.
Well that's it for lexer. But for the sake of debugging we define two more helper functions.
char* enum_to_string(enum TokenType t_type){
switch (t_type)
{
case StartObject:
/* code */
return "StartObject";
case EndObject:
return "EndObject";
default:
return "Invalid";
break;
}
}
void debug_print(Token* token_container,int len){
for(int i=0;i<len;i++){
printf("<%c,%s>\n",token_container[i].ch,enum_to_string(token_container[i].t_type));
}
}
enum_to_string just converts our enum type to string in order to print it.
Now we jump into Parser.
Parser
What is a Parser? Well, here is your answer.
For now it's pretty simple and straight forward but before we begin writing our parser header file, we must implement our stack to check if our { and } appears in the correct order. So, let's just do it.
#ifndef STACK_H
#define STACK_H
#include <stdio.h>
#include <limits.h>
#include <stdlib.h>
struct Stack {
int top;
unsigned capacity;
char* array;
};
// function to create a stack of given capacity. It initializes size of
// stack as 0
struct Stack* createStack(unsigned capacity)
{
struct Stack* stack = (struct Stack*)malloc(sizeof(struct Stack));
stack->capacity = capacity;
stack->top = -1;
stack->array = (char*)malloc(stack->capacity * sizeof(char));
return stack;
}
// Stack is full when top is equal to the last index
int isFull(struct Stack* stack)
{
return stack->top == stack->capacity - 1;
}
// Stack is empty when top is equal to -1
int isEmpty(struct Stack* stack)
{
return stack->top == -1;
}
// Function to add an item to stack. It increases top by 1
void push(struct Stack* stack, char item)
{
if (isFull(stack))
return;
stack->array[++stack->top] = item;
// printf("%c pushed to stack\n", item);
}
// Function to remove an item from stack. It decreases top by 1
char pop(struct Stack* stack)
{
if (isEmpty(stack))
return INT_MIN;
return stack->array[stack->top--];
}
// Function to return the top from stack without removing it
int peek(struct Stack* stack)
{
if (isEmpty(stack))
return INT_MIN;
return stack->array[stack->top];
}
#endif
[stack.h]
Now, this is our stack which stores characters. Let's move onto our main parser header file.
As I mentioned earlier our Parser takes input our token_container and based on the token take it's action. Let's define it.
#ifndef PARSER_H
#define PARSER_H
#include "lexer.h"
#include "stack.h"
void parser(Token* token_container,int len){
// printf("working");
struct Stack* stack = createStack(len);
for(int i=0;i<len;i++){
if(token_container[i].ch=='{'){
push(stack,token_container[i].ch);
}
else if(token_container[i].ch=='}'){
if(isEmpty(stack)==1 || pop(stack)!='{'){
printf("Parser Error : Invalid Syntax\nOperation Aborted\n");
free(stack);
exit(EXIT_FAILURE);
}
}
}
printf("Succesfully Parsed\n");
free(stack);
}
#endif
[parser.h]
Our parser function takes the token_container and its length, iterates over it, and if it finds {, it pushes it onto the stack. If it finds }, it checks if the stack is empty or if the top of the stack is not {, ensuring that each closing tag } has a corresponding opening tag {. If there is an error, we free the stack and exit the program, indicating failure. If everything goes well, we also free the stack and exit the function.
Main Function
#include "lexer.h"
#include "parser.h"
int main(){
Response res_lexer;
res_lexer = lexer("{}");
parser(res_lexer.token_container,res_lexer.length);
free(res_lexer.token_container);
}
We include our lexer.h and parser.h header files, take the Response returned from the lexer, pass it to our parser function, and finally free our token_container since it was allocated on the heap.
Now, if you run the program, it will print *Successfully Parsed* on the console and terminates.
Wrapping Up
That's it for today. In this article, we walk through the basics of creating a JSON parser in C, starting with a Lexer to recognize { and } tokens, followed by a Parser that ensures these tokens are correctly matched. We implement a simple stack to help the Parser verify that every opening brace { has a corresponding closing brace }. The end result is a program that reads a JSON string, tokenizes it, and checks for correct syntax, demonstrating fundamental concepts in lexical and syntactic analysis. See you on Day 2. :-)
Subscribe to my newsletter
Read articles from Kaif Khan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Kaif Khan
Kaif Khan
CS enthusiast.