The Art of Consistent Hashing
 Aditya Gupta
Aditya Gupta
While reading the paper "Scaling Memcached at Facebook", I came across Consistent Hashing. What started as a quick read became an hour-long obsession with this topic! My journey to understanding consistent hashing was a long one. This blog is here to ensure yours isn't! I'll try to keep this blog simple and cover its applications (in subsequent blogs) so that it's easy to understand. So buckle up, we are launching in 3..2..1🚀
Introduction
I assume most of you know what Hashing is, but just to ensure everyone is on the same page, Hashing refers to the process of generating a fixed-size output from an input of variable size using the mathematical formulas known as hash functions. We'll discuss more about hash functions later.
Web Caching
Web caching, in basic terms, refers to storing a copy of a web application, for example, a website, in the cache (local or remote). Imagine a browser attempting to access google.com. Before retrieving the data directly from the server, the browser checks if a cached version of google.com is available. If it finds a copy in the cache, it uses that cached version to serve the user. If the data isn't in the cache, the browser then fetches it from the original server.
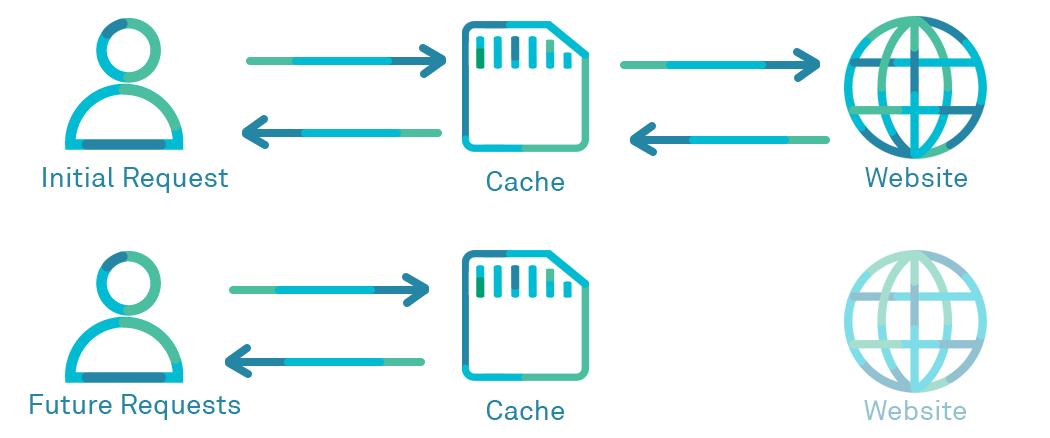
Caching is beneficial as it reduces latency and internet traffic. Now, the question arises: where should we store the cache? One suggestion is to allocate a dedicated cache for each user. We already implement a local cache in many of our applications, utilizing tools such as Redis and Memcached, which are specifically designed for caching. Moreover, we can extend the benefits of caching by deploying a Web cache that serves multiple users concurrently.
Imagine if one of your neighbors recently accessed google.com and it's stored in their local cache. Now, when your browser attempts to access google.com, wouldn't it be quicker to retrieve the data from your neighbor's cache instead of fetching it from the source? So the goal is straightforward: we aim to share the cache among multiple users, creating an all-to-all communication pattern.
Sharing cache among multiple users might sound straightforward, but it's actually quite challenging. For instance, maintaining records of which cache stores which data could require significant storage and be inefficient. Another approach, such as searching each cache individually to check for data, is inefficient. A straightforward solution to this problem involves using Hashing.
So what we want to implement is, given a URL, we somehow automatically know which cache to check among all the caches. This is where Hash Functions come into the picture.
By using hash functions, we can solve the problem of mapping a URL to a cache. For instance, consider a scenario with n cache servers. We essentially apply a modulo n operation to the output of the hash function:
$$h(x)modn$$
In this method, the result of the formula will always fall between 0 and n−1. Consequently, we assign the URL to the i-th cache server, where i is the output of the above formula.
Sounds clever, doesn’t it? However, there’s a significant drawback to this approach. Currently, the number of cache servers, n, is fixed and not dynamic. For example, if we add another cache server in the future, the value of n changes. Consequently, the output for each previously mapped URL would likely be different when recalculated with the new n value. This implies that whenever n changes, we would need to reassign all previously stored URLs to different cache servers. This process is inefficient and impractical.
Consistent Hashing
Consistent Hashing tries to solve the problem listed earlier. The main concept here is to hash not only the names of all objects (URLs), as we did previously, but also the names of all cache servers.
To start with, consider a very long 1-D array where we have already hashed all the cache server names. When given an object x (URL) that hashes to the bucket h(x), we start scanning the buckets to the right of h(x). We continue this scan until we encounter a bucket h(s), where s is the name of a cache server that hashes to this bucket.

We can also visualize this 1-D array on a circle:
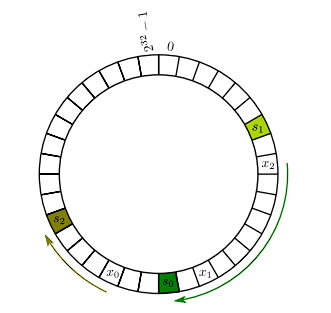
Here, instead of going right, we go clockwise or anti-clockwise direction. This straightforward concept offers several valuable benefits. Firstly, assuming we use well-designed hash functions, the load on each of the n cache servers is evenly distributed, with each server handling approximately 1/n of the objects.
Secondly, and more crucially, consider what happens when a new cache server, denoted by s, is added. Only the objects that would be assigned to s based on the hash function need to move. This means that, on average, adding an nth cache server results in only 1/n of the objects being relocated.
Consistent hashing is widely used in various systems and services, including Akamai, BitTorrent, and DynamoDB, among others. This blog is getting a bit lengthy. Let's take a break here, and I'll create another blog soon discussing implementations of Consistent Hashing.
Until then, adios!
References used for creating this blog:
Subscribe to my newsletter
Read articles from Aditya Gupta directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Aditya Gupta
Aditya Gupta
Hey there, I’m Aditya, a Software Developer at Fidelity Investments. I’m really into all things tech and love geeking out about it. My memory isn’t the greatest, so I use this blog to keep track of everything I learn. Think of it as my personal journal—if you enjoy it, hit that follow button to keep me inspired to write more!