Kafka 토픽 발행으로 Mysql 부하 줄이기
 HKH
HKH
🤯 문제 발생
회사 광고팀에서 사용하던 mysql이 터졌다
정확히는 connection pool이 너무 많이 늘어나면서 요청을 다 처리하지 못하고 뻗어버렸다
유력 범인 후보로는 내가 관리하는 추천 API 서버가 지목이 되었다
문제를 해결해보자 😌
🤔 원인이 무엇이었을까?
우선적으로 광고 유효 업체 api 구조를 살펴보자
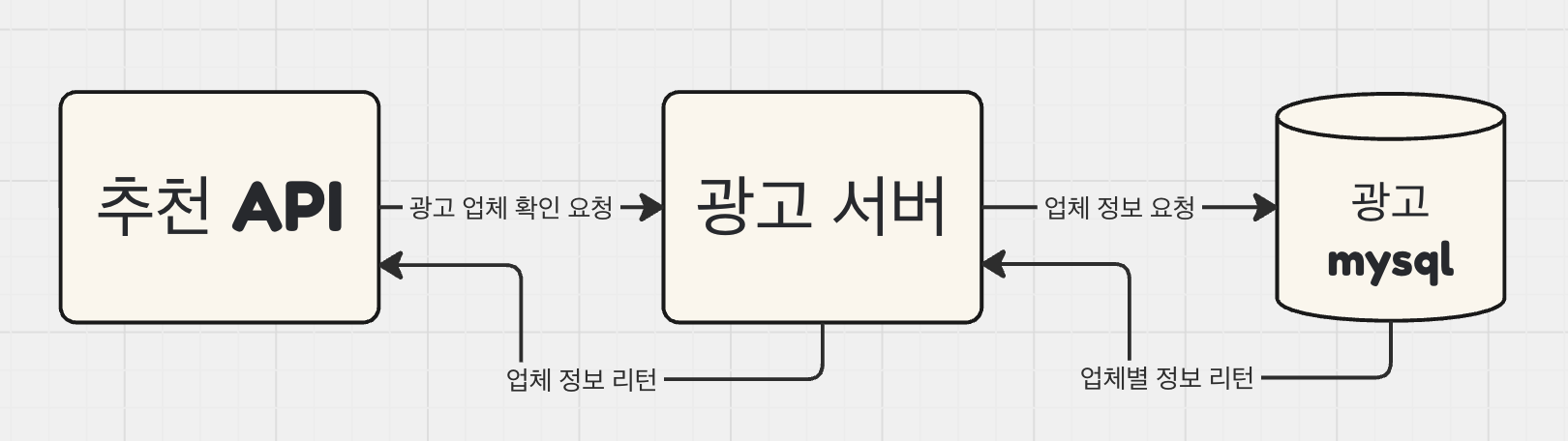
추천 api를 통해 광고 업체들의 유효성 판별 요청을 광고 서버에 보낸다
해당 광고 서버는 정보가 담긴 mysql db를 뒤져서 해당 업체의 정보를 들고온다
리턴
이라는 아주 간단한 구조이다!
그러면 어디에 부하가 심하게 걸렸던 것일까?
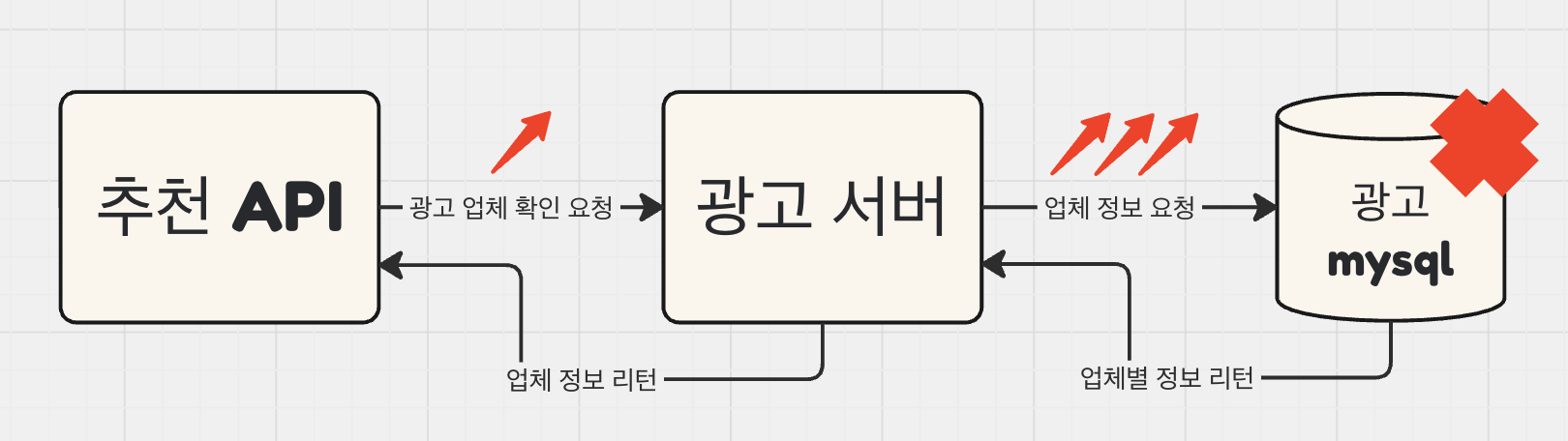
요청량 증가: 광고 구좌가 늘어나면서 업체 체크 api를 활용하는 영역이 많아졌다
동기 처리: 많은 요청량을 mysql에서 동기식으로 처리하다보니 결과를 뱉기 전까지 connection pool에 쌓이기 시작
별도의 업체 관리 테이블 없음: 업체 잔여 금액이 로그 형식으로 집계가 되며 해당 업체의 유효성을 판별하기 위해서는 테이블 총 3개 스캔이 필요함
🛠️ 해결 방안 모색
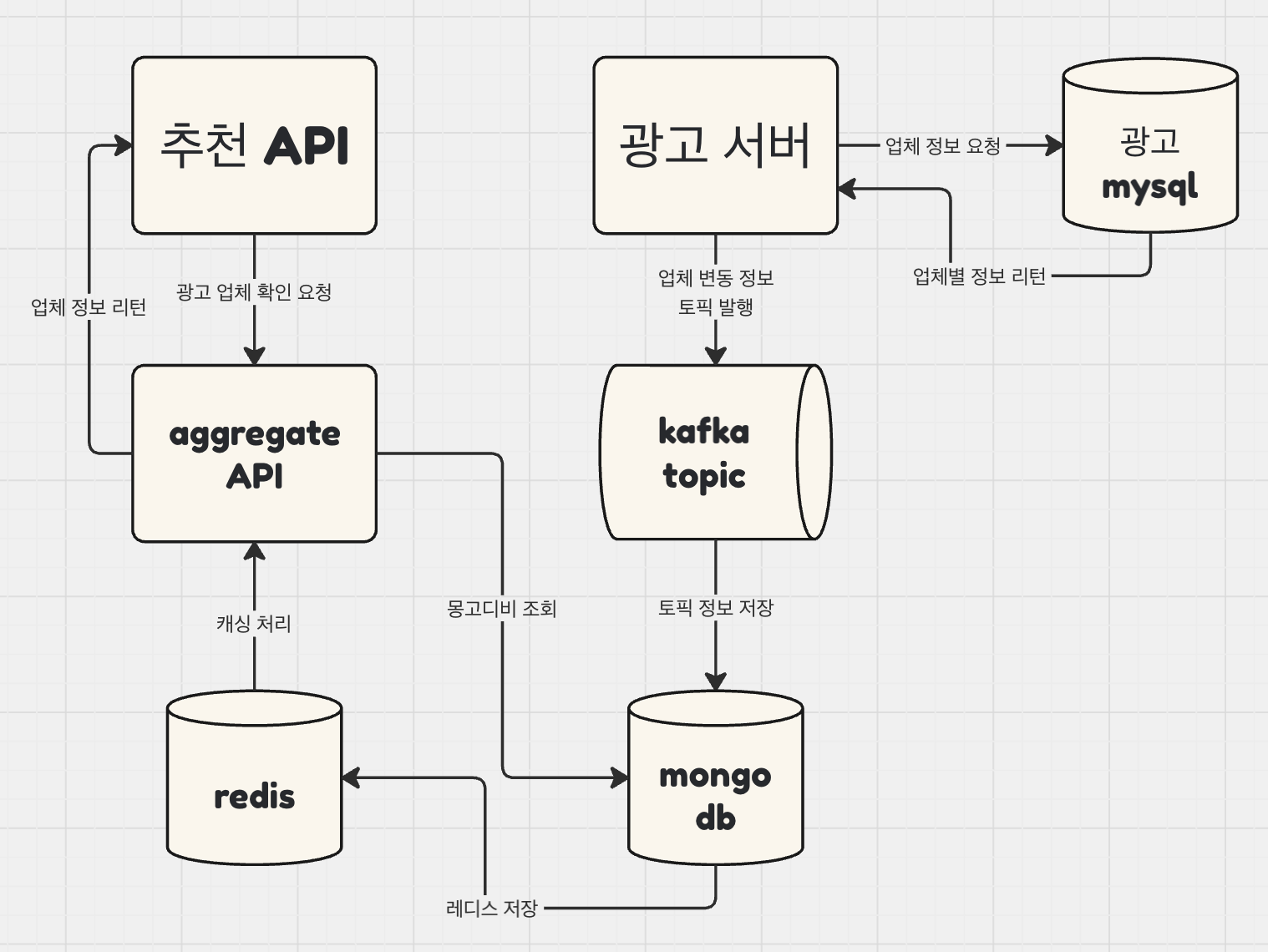
직접적으로 광고서버에 대한 요청을 줄여서 mysql 데이터베이스와의 의존성을 줄여보자!
광고파트에서 업체별로 변동 정보를 체크하고서 각 변동분을 카프카 토픽으로 내려준다
해당 토픽을 컨슈밍해서 업체의 상태값만 별도 테이블에 저장을 한다
현재 유효한 업체 리스트를 캐싱하여 빠르게 판별할 수 있는 독립적인 API를 구축한다
추천 API에서 해당 API를 호출한다
구조를 정리하면 아래와 같다
🚀 개발 및 도입
1. Kafka Consumer
해당 토픽을 컨슈밍하는 Listener 코드 개발!
광고 유효성을 판별하여 AiadValidVen에 저장
@KafkaListener(topics = TOPIC_NAME, groupId = GROUP_ID)
public void consume(ConsumerRecord<String, String> record) throws Exception {
try {
ObjectMapper objectMapper = originalObjectMapper.copy();
objectMapper.setPropertyNamingStrategy(PropertyNamingStrategies.LOWER_CAMEL_CASE);
String message = record.value();
AiadVenDispStatMessageDto msg = objectMapper.readValue(message, AiadVenDispStatMessageDto.class);
LocalDateTime messageTimestamp = LocalDateTime.ofInstant(Instant.ofEpochMilli(record.timestamp()),
ZoneId.systemDefault());
boolean isUseYn = isValidVen(msg);
AiadVenStat stat = ...;
aiadVenStatRepository.save(stat);
AiadValidVen validVen = AiadValidVen.builder()
._id(msg.getKey())
.build();
if (isUseYn) {
aiadValidVenRepository.save(validVen);
} else {
aiadValidVenRepository.delete(validVen);
}
} catch (Exception e) {
log.error("AiadVenDispStatMessageDto Exception : {}", record);
throw e;
}
boolean isValidVen(AiadVenDispStatMessageDto msg) {
return ...;
}
}
2. Aggregate API
WebFlux을 이용하여 보다 빠르게 해당 몽고 레파지토리를 접근
Redis에 저장하여 DB I/O 최소화
private Mono<String> findAiadVenStatus(String venId) {
return reactiveRedisOperations.opsForValue().get(setRedisKey(venId))
.switchIfEmpty(Mono.defer(() ->
aiadValidVenStatRepository.existsById(venId)
.flatMap(exists -> exists ? Mono.just(venId) : Mono.empty())
.doOnNext(this::cacheAiadVenStat)
));
}
private void cacheAiadVenStat(String venId) {
String key = AIAD_VEN_REDIS_KEY_PREFIX.concat(venId);
reactiveRedisOperations.opsForValue()
.setIfAbsent(key, venId, Duration.ofMinutes(1))
.subscribe();
}
3. Recommend API
FeignClient를 활용하여 보다 간편하게 위에 개발한 API를 호출
유효한 업체인지 정보를 들고 올 수 있다
@Primary
@FeignClient(value = "AGGREGATE-API",
path = "/aggregate",
configuration = AggregateApiFeignConfiguration.class,
fallback = AggregateApiClient.AggregateApiClientFallback.class)
public interface AggregateApiClient {
@PostMapping(value = "/aiad/check")
Set<String> validVenIds(@RequestBody Set<String> venIds);
default Set<String> getValidVenIds(@RequestBody Set<String> venIds) {
return Optional.ofNullable(validVenIds(venIds)).orElse(Collections.emptySet());
}
default Set<String> getVenIdSetY(Set<String> venIdList) {
Set<String> validVenList = getValidVenIds(venIdList);
return venIdList.stream()
.filter(validVenList::contains)
.collect(Collectors.toSet());
}
}
🎉 결론
이전에는 업체별로 이력관리도 불가하고 오로지 광고팀에서 내려주는 정보를 가지고 유효 업체 여부를 판별할 수 밖에 없었다. 하지만 이제는 토픽으로 발행해주면서 각 업체의 상태값 트래킹도 가능하고 우리팀 내부적으로도 해당 데이터를 이용하여 정합성을 판별할 수 있게 되었다. mysql 의존성을 줄인것도 덤!
Subscribe to my newsletter
Read articles from HKH directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by