Redis Master-Slave Cluster Explained
 Sonal Kumar
Sonal KumarWhat is Redis
Redis, which stands for Remote Dictionary Server, is an open-source, in-memory data structure store that is used as a database, cache, and message broker.Redis stores data in memory, which allows for extremely fast read and write operations compared to traditional disk-based databases.
Some benefits :
Performance:
Low Latency: Redis's in-memory nature means data can be read and written with minimal latency.
Caching:
Speed: Redis is often used as a cache to store frequently accessed data, reducing the load on primary databases and improving response times.
Ease of Use:
Redis's simple command-based interface makes it easy to use and integrate with applications. It has client libraries available for almost every programming language.
What is redis cluster
A Redis Cluster is a distributed implementation of Redis that allows data to be automatically partitioned across multiple Redis nodes, providing improved scalability, fault tolerance, and high availability. Redis Cluster is designed to meet the needs of applications that require large datasets and need to be able to scale horizontally.
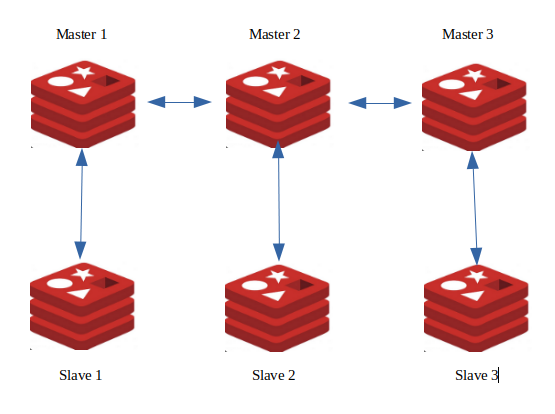
To create a sustainable master-slave setup, the master and slave should be in different servers not in the same server.
If master node is in server 1 then its slave node should be in server 2 because in case server 1 goes down then master will go down but slave will be up and it will have all master's data and will become master eventually since slave will be in different server,
but if both master and slave are in same server then both will go down and data will be lost.
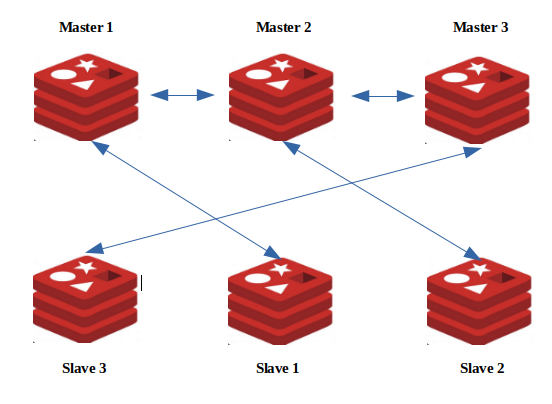
How redis master-slave setup works
In a master-slave setup, the distribution of read and write operations can be optimised to improve performance and load distribution.
Master nodes handles both read and write operations.
Slave nodes primarily exist for data redundancy and fail-over purposes.
But with redis client configuration slaves can be configured to perform read operations to distribute the load more evenly across the cluster from master node.
Slave node keeps a copy of all the keys of the master node.
If an application makes a request to a slave , if its a read query and slave has been configured to perform read operations then slave will give back the result to the application but in case its a write query slave will direct the query to its master node.
What is redis client configuration
Redis client configuration refers to the setup and customisation of how a Redis client connects to and interacts with a Redis cluster. The configuration typically includes parameters such as the Redis server addresses, connection timeouts, security settings, and specific behaviours for handling read and write operations.
Different Redis client libraries (like lettuce, Jedis, Redisson, etc.) offer various configuration options.
A Redis client is a software library or tool that allows applications to interact with a Redis database. Redis clients provide the necessary functions and abstractions to perform various operations on the Redis server, such as setting and retrieving data, managing keys.
Some advantages of redis master-slave cluster setup
Redis Cluster with a master-slave setup offers several advantages that can significantly enhance the performance, reliability, and scalability.
1. High Availability
Scenario:
You have an e-commerce application that relies heavily on Redis for caching product data and user sessions.
Advantage:
Automatic Fail-Over: If a master node fails, one of its slave nodes is automatically promoted to master, ensuring that your application continues to function without interruption.
Minimal Downtime: This automatic promotion minimises downtime and maintains the availability of your cached data.
2. Scalability
Scenario:
Your social media application is experiencing rapid growth, and the volume of data stored in Redis is increasing.
Advantage:
Horizontal Scalability: By adding more master nodes, you can distribute the data across multiple nodes.
Load Distribution: Read operations can be distributed across both master and slave nodes, reducing the load on individual nodes and improving performance.
3. Data Redundancy and Backup
Scenario:
A financial application uses Redis to store real-time transaction data, and data integrity is crucial.
Advantage:
Data Redundancy: Each master node has one or more slave nodes that replicate its data. This redundancy ensures that data is not lost if a master node fails.
Backup Strategy: Slave nodes can be used to create backups of the data without affecting the performance of the master nodes.
4. Maintenance and Upgrades
Scenario:
Your application needs to perform routine maintenance or upgrades on the Redis infrastructure without causing downtime.
Advantage:
- Rolling Upgrades: With a master-slave setup, you can perform rolling upgrades and maintenance. You can upgrade or restart nodes one at a time, ensuring that there are always nodes available to handle requests.
How is data inserted into redis cluster
Redis Cluster automatically handles the distribution of keys among multiple nodes. This is achieved through a concept called "hash slots".
Hash Slot Calculation:
Redis Cluster divides the key space into 16,384 hash slots.
When a key is written to the cluster, a hash function (CRC16) is applied to the key to determine its hash slot. The result of the hash function gives the hash slot.
Slot Assignment:
Each node in the cluster is responsible for a subset of these slots.
For instance, if you have 3 nodes, the slots might be divided as:
Node 1: Slots 0-5460
Node 2: Slots 5461-10922
Node 3: Slots 10923-16383
Note : Slots do not get assigned to the slave nodes, they are assigned among the master nodes itself.
Writing the Key
Client Command: SET user:1001 "John Doe"
The client sends this command to any node in the cluster.
The node receiving the command calculates the hash slot for "user:1001".
Calculation is done by redis internally something like below -
CRC16("user:1001") % 16384 = 7000The node determines that slot 7000 is managed by Node 2 and forwards the command to Node 2.
Node 2 stores the key "user:1001" with the value "John Doe".

How is data fetched from redis cluster
Reading a Key:
Key: "user:1001"
When you query for "user:1001", Redis calculates the hash slot again and determines it falls into slot 7000.
Redis knows that slot 7000 is managed by Node 2 and will fetch the key from Node 2.
What info we need to provide an application which interacts with redis ?
When an application needs to interact with a Redis cluster, it typically needs the following information:
Cluster Nodes Information:
IP Addresses and Ports: The application should have the IP addresses and ports of one or more nodes in the Redis cluster. It does not need the IP addresses and ports of all nodes, but having multiple nodes can help with fault tolerance if one node is down.
In case of a springboot application, how will the application access redis if passed with cluster information as a variable like :-
REDIS_CLUSTER_NODES=13.232.152.199:6379,13.232.152.199:6380
In a Spring Boot application, when you pass multiple Redis cluster nodes in the configuration, the behaviour depends on the Redis client library you are using.
Let's assume you are using lettuce, a popular Redis client for Java.
Lettuce Client Behavior
Initial Connection:
- The client will attempt to connect to the nodes in the order they are listed. It will try the first node (13.232.152.199:6379). If the first node is unreachable, it will then try the second node (13.232.152.199:6380).
Cluster Discovery:
- Once connected to a node, the client will issue a CLUSTER NODES command to retrieve the cluster topology. This includes information about all nodes in the cluster, including which nodes are masters, which are replicas, and which hash slots each node is responsible for.
In a Spring Boot application, the Redis client library used typically depends on the dependencies you have included in your pom.xml (for Maven) or build.gradle (for Gradle) file. Here's how you can determine which Redis client library your application is using:
Checking Maven Dependencies
Open yourpom.xml file:
Look for dependencies related to Redis. These dependencies typically include a specific Redis client library.
The spring-boot-starter-data-redis dependency includes the lettuce Redis client by default unless specified otherwise.
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
These are some of the points which I came across while reading about redis master-slave cluster, its advantages, its functioning on high level and a bit more understanding in detail.
Hope you find this useful.
Subscribe to my newsletter
Read articles from Sonal Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by