Step-by-Step Guide to Evaluating RAG with Azure AI Search, Azure OpenAI, LlamaIndex, and Tonic AI
 Farzad Sunavala
Farzad Sunavala
In this blog, we will explore how to use Azure AI Search in conjunction with Azure OpenAI, LlamaIndex, and Tonic AI Validate to build a robust Retrieval-Augmented Generation (RAG) evaluation system. This tutorial is inspired by the blog "RAG Evaluation Series: Validating the RAG performance of Amazon Titan vs Cohere using Amazon Bedrock" by Joe Ferrara, PhD, Tonic AI.
Overview
Retrieval-Augmented Generation (RAG) has become a standard architecture for equipping Large Language Models (LLMs) with context, thereby reducing the occurrence of hallucinations. However, even RAG apps can experience hallucinations when the retrieval fails to provide sufficient or relevant context.
To address this, we use Tonic AI Validate for evaluating the quality of both retrieval and generation in the RAG architecture. The key evaluation metrics used are:
Overall Score: Average of normalized metric scores.
Answer Similarity: Measures how well the answer matches the reference answer on a 0-5 scale.
Answer Consistency: Measures how much of the answer is consistent with the retrieved context.
Augmentation Precision: Measures how well the relevant context is used in the answer.
By achieving satisfactory evaluations on these metrics, we can ensure the correctness of our application and minimize hallucinations within the limits of its knowledge base.
Initial Setup
For this blog, we will reuse the exact same steps from our "contoso-hr-docs" index we built using llama-index with Azure AI Search as our vector store and Azure OpenAI as our embedding and language models. Please refer to the blog Evaluating RAG with Azure AI Search, LlamaIndex, and TruLens (hashnode.dev) on how to configure your search index as a pre-req or follow the instructions listed in the full notebook: azure-ai-search-python-playground/azure-ai-search-rag-eval-tonic-ai.ipynb at main · farzad528/azure-ai-search-python-playground (github.com)
Once you have created your search index, you can now proceed to the following steps to run RAG Evaluations using Tonic Validate.
Evaluate RAG with Tonic AI
Let's now set up and run evaluations using Tonic Validate. In this code, we are creating a function for each LlamaIndex query engine (keyword, hybrid, and semantic_hybrid retrieval modes in Azure AI Search).
# Modifies the function to leverage the keyword engine
def get_llama_response_with_query_engine(prompt, engine_type='keyword'):
if engine_type == 'keyword':
query_engine = keyword_query_engine
elif engine_type == 'hybrid':
query_engine = hybrid_query_engine
elif engine_type == 'semantic_hybrid':
query_engine = semantic_hybrid_query_engine
else:
raise ValueError("Invalid engine type specified")
response = query_engine.query(prompt)
context = [x.text for x in response.source_nodes]
return {
"llm_answer": response.response,
"llm_context_list": context
}
Set Benchmark Ground-Truth Values
In this code block, we pre-generated a list of question-answer pairs as required by Tonic Validate and set this as our benchmark ground-truth set, eval_tonic.json. I used ChatGPT to generate 100 question-answer pairs with the following prompt. See https://farzzy.hashnode.dev/evaluating-azure-ai-search-with-llamaindex-and-trulens#heading-query-types-and-definitions.
import json
from tonic_validate import Benchmark
qa_pairs = []
with open("eval/eval_tonic.json", "r") as qa_file:
qa_pairs = json.load(qa_file)
question_list = [qa_pair['question'] for qa_pair in qa_pairs]
answer_list = [qa_pair['answer'] for qa_pair in qa_pairs]
benchmark = Benchmark(questions=question_list, answers=answer_list)
Here an example of the one of the qna pairs:
{
"question": "Why is PerksPlus considered a comprehensive health and wellness program?",
"answer": "PerksPlus is considered comprehensive because it offers reimbursement for a wide range of fitness activities including gym memberships, personal training, yoga and Pilates classes, fitness equipment purchases, and more.",
"reference_article": "PerksPlus"
},
Evaluating Query Engines with Tonic Validate
This section demonstrates how to evaluate different query engines (keyword, hybrid, and semantic_hybrid) using the Tonic Validate framework. For each query engine type, we score the responses based on a benchmark and upload the results separately to the Tonic Validate API. This process allows for a comparative analysis of the performance of each query engine type under the same evaluation conditions.
from tonic_validate import ValidateScorer, ValidateApi
# Score the responses for each query engine type and upload the runs separately
scorer = ValidateScorer(model_evaluator=AZURE_OPENAI_CHAT_COMPLETION_DEPLOYED_MODEL_NAME)
# Keyword engine
run_keyword = scorer.score(
benchmark,
lambda prompt: get_llama_response_with_query_engine(prompt, engine_type="keyword"),
scoring_parallelism=2,
callback_parallelism=2,
)
validate_api.upload_run("YOUR-KEYWORD-RUN-ID", run_keyword) # keyword
# Hybrid engine
run_hybrid = scorer.score(
benchmark,
lambda prompt: get_llama_response_with_query_engine(prompt, engine_type="hybrid"),
scoring_parallelism=2,
callback_parallelism=2,
)
validate_api.upload_run("YOUR-HYBRID-RUN-ID", run_hybrid) # hybrid
# Semantic Hybrid engine
run_semantic_hybrid = scorer.score(
benchmark,
lambda prompt: get_llama_response_with_query_engine(prompt, engine_type="semantic_hybrid"),
scoring_parallelism=2,
callback_parallelism=2,
)
validate_api.upload_run("YOUR-SEMANTIC-HYBRID-RUN-ID", run_semantic_hybrid) # semantic_hybrid
scoring_parallelism and callback_parallelism properties.Deep Dive into Results
Let's dive into the results.
Evaluate Baseline Results
The Baseline RAG solution has an overall score of 0.48 out of 1, with a significant issue in answer consistency, scoring only 0.28 out of 1.
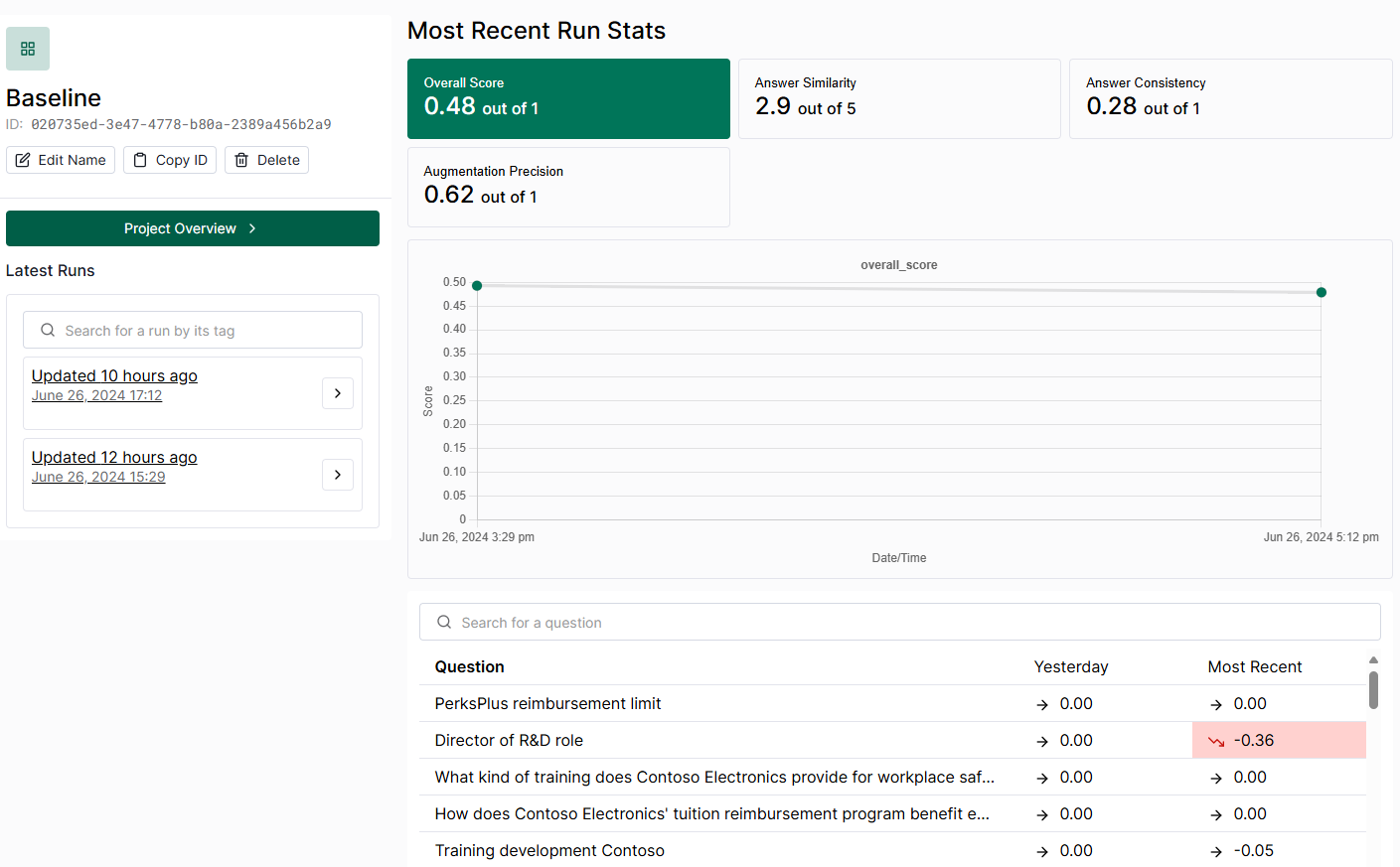
By clicking the "scores" tab, we can see which queries performed the best and worst by sorting by overall_score.
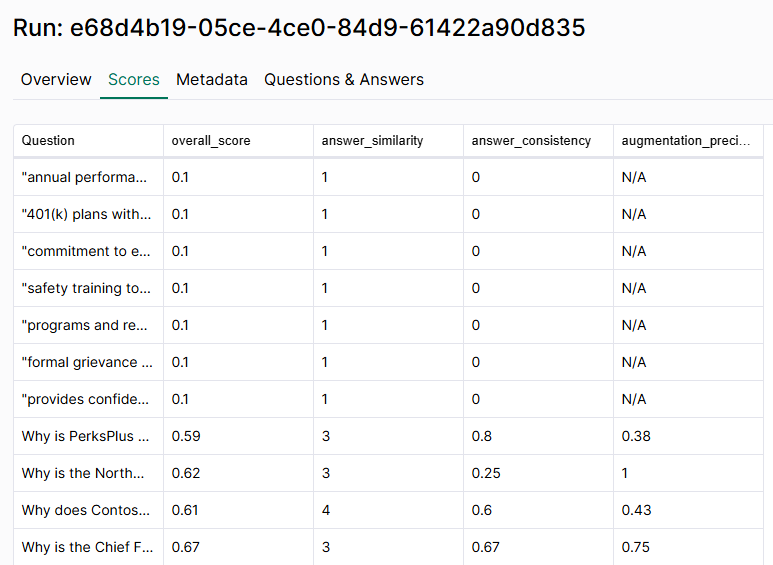
Let's take a look at the query on the "Questions & Answers" tab, "Why is PerksPlus considered a comprehensive health and wellness program?".
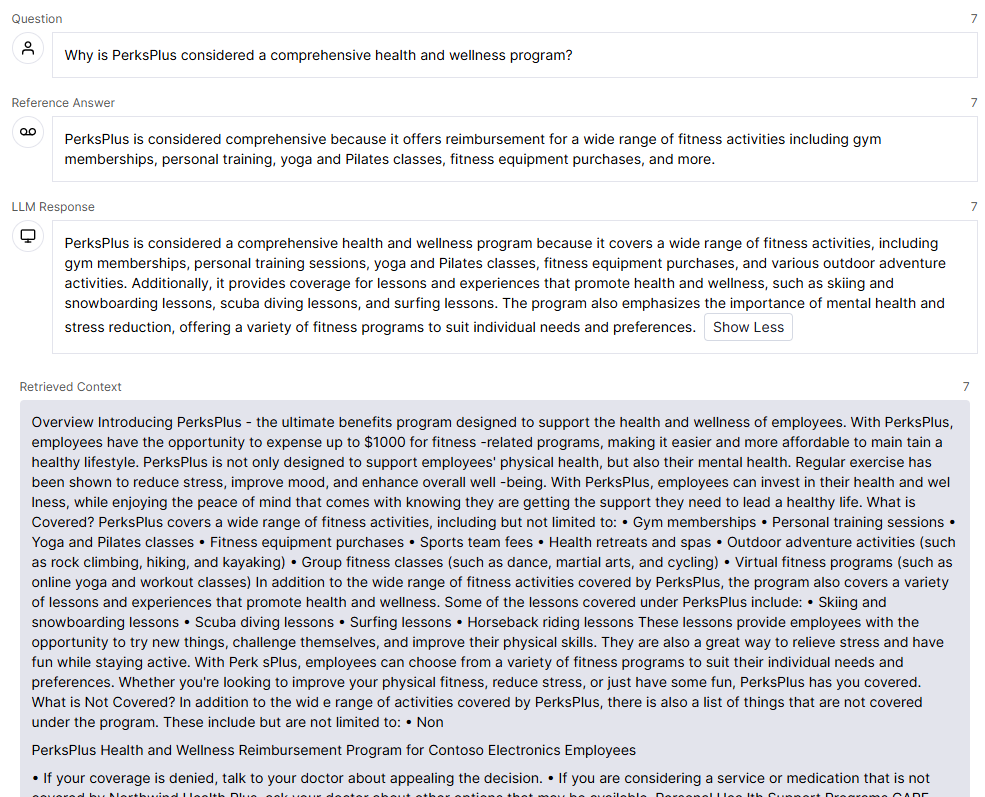
You can see that the image contains the query, the response, and the LLM response (aka 'critic') resulting in the following scores:
| Score Category | Score | Description |
| Overall Score | 0.5917 | Average of normalized metric scores. |
| Answer Similarity | 3.0000 | Measures how well the answer matches the reference answer on a 0-5 scale. |
| Answer Consistency | 0.8000 | Measures how much of the answer is consistent with the retrieved context. |
| Augmentation Precision | 0.3750 | Measures how well the relevant context is used in the answer. |
You can add more RAG metrics as you desire. Please visit Tonic Validate RAG Metrics for the full list of supported metrics.

Based on the above screenshots, for my ground-truth set, hybrid retrieval mode outperformed the others but there is still lots of room for improvement to increase these metrics.
Conclusion
Through detailed analysis of the metrics and trace details, we've identified potential areas for improvement in both the retrieval and response generation processes.
To further improve these evaluation metrics, we can experiment with advanced RAG strategies such as:
Adjusting the Chunk Size
Modifying the Overlap Window
Using a different
top_kvalueImplementing a Sentence Window Retrieval
Utilizing an Auto-Merging Retrieval
Applying Query Rewriting techniques
Experimenting with Different Embedding Models
Testing Different Large Language Models (LLMs)
For additional information on query categorization and performance metrics, please refer to the Azure AI Search blog post.
References
Subscribe to my newsletter
Read articles from Farzad Sunavala directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Farzad Sunavala
Farzad Sunavala
I am a Principal Product Manager at Microsoft, leading RAG and Vector Database capabilities in Azure AI Search. My passion lies in Information Retrieval, Generative AI, and everything in between—from RAG and Embedding Models to LLMs and SLMs. Follow my journey for a deep dive into the coolest AI/ML innovations, where I demystify complex concepts and share the latest breakthroughs. Whether you're here to geek out on technology or find practical AI solutions, you've found your tribe.