Deep Dive into Kubernetes API Server
 Anish Bista
Anish Bista
Deep Dive into Kubernetes API Server
The Kubernetes API server is a critical component of the Kubernetes control plane, serving as the central hub through which all interactions with the cluster occur. In this blog, we'll explore the inner workings of the API server, detailing its role in the Kubernetes ecosystem, the request flow, the various stages of request processing, and the use of mutating and validating admission controllers.
Understanding the Kubernetes API Server
The API server is responsible for handling all RESTful requests to the Kubernetes cluster, whether they come from users, administrators, or internal components such as controllers. It processes these requests, validates them, and updates the state of the cluster accordingly.
Request Flow in the API Server in Backend
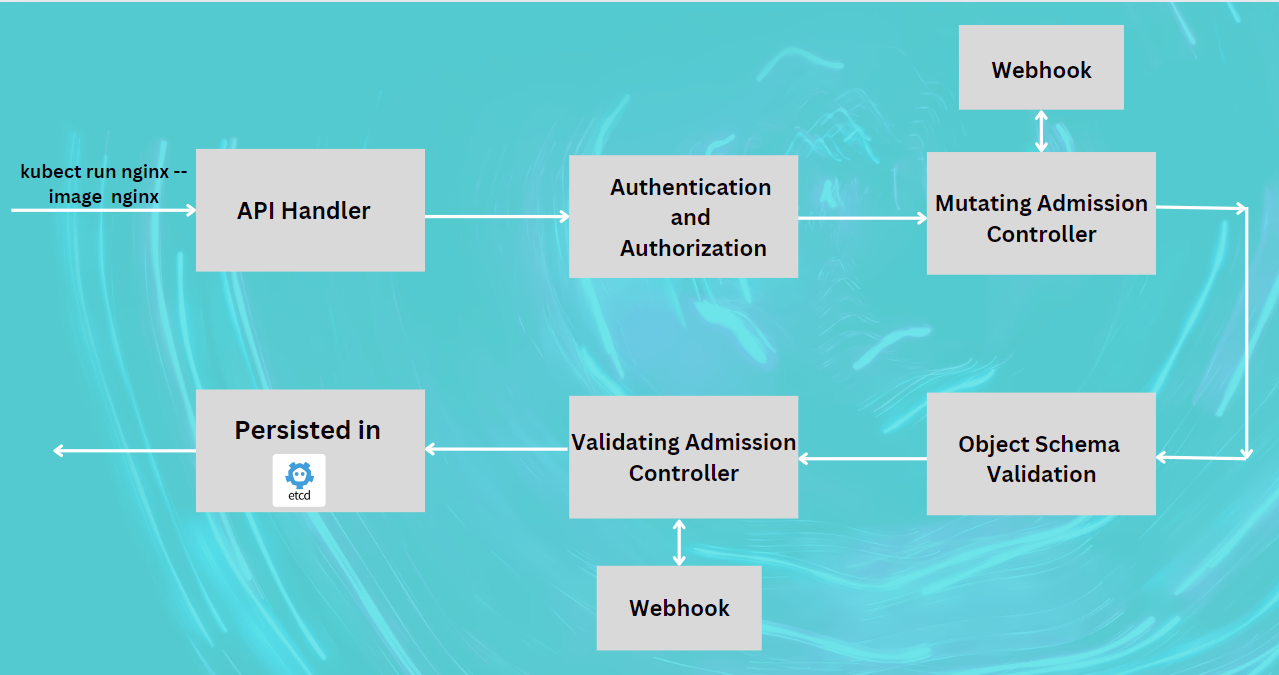
To understand the functionality of the API server, let's walk through a typical request flow using the following diagram:
API Handler:
The request, such as
kubectl run nginx --image nginx, is sent to the API server.The API handler receives the request and determines the appropriate course of action.
Authentication and Authorization:
Authentication: The API server authenticates the user or service account making the request. This can be based on various mechanisms such as:
Client Certificates: Verifying the identity of clients using TLS client certificates.
Bearer Tokens: Using JSON Web Tokens (JWT) for API authentication.
Authentication Plugins: Integrating with external authentication providers like LDAP, OIDC, or custom solutions.
Authorization: Once authenticated, the request is authorized based on the user's permissions. This involves checking the request against Kubernetes Role-Based Access Control (RBAC) policies to determine if the user has the necessary permissions to perform the requested action.
You can see what Authorization mechanism is used in your cluster by seeing the kube Apiserver manifest present at
cat /etc/kubernetes/manifests/kube-apiserver.yamlSee the
--authorization-mode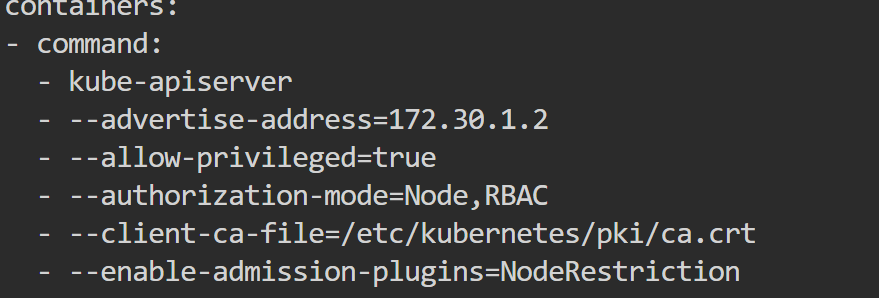
Mutating Admission Controller:
The request passes through the mutating admission controllers.
These controllers can modify the request object to enforce certain policies (e.g., adding default values).
for this you can see
--enable-admission-plugins
Object Schema Validation:
The request object is validated against the Kubernetes schema to ensure it adheres to the required structure.
This step prevents malformed requests from being processed.
Validating Admission Controller:
The request is then processed by validating admission controllers.
These controllers perform additional checks and can deny requests that do not comply with specified policies.
for this you can see
--enable-admission-plugins
Persisting in etcd:
If the request passes all previous steps, it is persisted in
etcd, the key-value store used by Kubernetes.This ensures the desired state of the cluster is recorded.
Webhooks in Admission Controllers
Admission controllers can use webhooks to extend their functionality. Webhooks allow external services to participate in the admission process by making HTTP callbacks. There are two types of webhooks:
Mutating Webhook: Modifies the request object before it is persisted.
Validating Webhook: Validates the request object and can deny it if necessary.
Production Use Cases for Admission Controllers
Mutating Admission Controllers
Injecting Sidecars:
Use Case: Automatically inject sidecar containers (e.g., logging agents, monitoring agents, service meshes like Istio) into pods.
Example: When a new pod is created, the mutating admission controller injects a sidecar container that runs a logging agent to ensure all logs are collected without requiring developers to modify their pod specifications.
Setting Default Values:
Use Case: Apply default configurations to resources that do not specify certain values.
Example: Automatically add default resource limits and requests for CPU and memory to pods that do not have these values specified, ensuring resource constraints are applied consistently.
Label and Annotation Injection:
Use Case: Add mandatory labels or annotations to Kubernetes resources for monitoring, logging, or policy enforcement.
Example: Inject a specific label to all pods created in the cluster for environment identification (e.g.,
environment=production) to facilitate filtering and management.
Automated Configuration Management:
Use Case: Ensure specific configuration parameters are always present in resource definitions.
Example: Automatically add network policies to new namespaces to ensure they adhere to security standards without requiring manual intervention.
Validating Admission Controllers
Security Policy Enforcement:
Use Case: Ensure all resources adhere to the organization's security policies.
Example: Validate that all containers use approved base images, preventing the deployment of containers with untrusted or vulnerable images.
Resource Quota Enforcement:
Use Case: Ensure that resource requests and limits conform to predefined quotas.
Example: Reject deployments that request more CPU or memory resources than allowed by the namespace's quota, preventing resource exhaustion.
Compliance Checks:
Use Case: Enforce regulatory compliance by validating resource configurations.
Example: Validate that all pods running in a specific namespace have encryption enabled for sensitive data, ensuring compliance with data protection regulations.
Pod Security Policies:
Use Case: Enforce security contexts and capabilities for pods.
Example: Validate that all pods adhere to the defined pod security policies, such as running as a non-root user, disabling privilege escalation, and using read-only root filesystems.
Challenges and Disadvantages of Mutating Webhooks
While mutating webhooks can be powerful, they come with certain challenges and disadvantages:
Complexity:
- Disadvantage: Implementing and maintaining mutating webhooks adds significant complexity to the Kubernetes cluster, making the system harder to understand, troubleshoot, and manage.
Debugging Challenges:
- Disadvantage: Mutating webhooks can make it difficult to understand what changes are being applied to resource definitions, leading to challenges in debugging and troubleshooting.
Order of Execution:
- Disadvantage: When multiple mutating webhooks are configured, the order of execution is not guaranteed, which can lead to unpredictable results if multiple webhooks modify the same resource attributes.
Performance Overhead:
- Disadvantage: The additional processing time for each request can lead to increased latency and reduced performance, particularly in large or heavily utilized clusters.
Security Risks:
- Disadvantage: Improperly configured mutating webhooks can introduce security vulnerabilities if they inadvertently allow unauthorized modifications or weaken security controls.
Lack of Transparency:
- Disadvantage: Mutations applied by webhooks may not be immediately apparent to users or developers, leading to confusion and difficulties in understanding the true state of resources within the cluster.
Conclusion
The Kubernetes API server is a vital component that orchestrates all interactions within a Kubernetes cluster. By understanding its request flow and the roles of its various components, you can gain deeper insights into how Kubernetes maintains its desired state and enforces policies. Mutating and validating admission controllers are powerful tools for automating and enforcing policies, but they come with their own set of challenges and considerations.
Subscribe to my newsletter
Read articles from Anish Bista directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Anish Bista
Anish Bista
Anish Bista is a passionate student deeply involved in cloud-native, DevOps, and open-source software, particularly focusing on Kubernetes ☸. He actively contributes to CNCF projects, including KubeVirt and Kanisterio. Anish is also engaged in community work and is a member of DevOpsCloudJunction. He also serve as a Co-Organizer at CNCF Kathmandu. His interest and Expertise lies on K8s and Golang.