Real-Time Streaming Basics
 GlassFlow
GlassFlow
Real-time streaming has become critical for many businesses and applications in today's fast-paced digital era. Whether it is delivering critical financial transactions, analyzing vast amounts of data to make quick decisions, or sending social media updates, the importance of this technology is undeniably vast.
The following article briefly introduces the concept of real-time streaming, illustrating how data streams originate, their transportation mechanisms, processing methods, and the challenges faced in the domain. By the end of this article, you will gain a comprehensive understanding of the intricacies of real-time streaming.
What is Real-Time Streaming?
Real-time streaming refers to the continuous transfer and processing of data as soon as it's generated without significant delay. It enables data to be read and processed in streams.
A stream is data that is incrementally available over time. This type of data appears in many contexts like programming languages, filesystem APIs, TCP connections, audio and video streams over the internet, stdin and stdout in Linux, etc.
In a stream processing context, actions that happen within a system are called events. An event represents a compact, standalone, unchangeable record capturing the specifics of an occurrence at a particular moment.
Stream processing has the following key characteristics:
Low latency. In stream processing, the events are processed as soon as (or almost as soon as) they are available. The goal is to reduce the delay between when an event enters the streaming system and when it is processed. This latency ranges from milliseconds to seconds, hence the name real-time streaming.
Continuous data flow. In batch processing, the input data is often bounded, so the batch process knows when it has read all the input. In stream processing, data is unbounded and transmitted continuously.
Scalability. Real-time streaming systems are designed to handle varying numbers of recipients simultaneously. This is crucial for services that transmit and process huge amounts of data to many users.
Where Streams Come From
A stream can come from many sources:
User activity events, like posting a picture or liking a post.
Sensors provide periodic readings from IoT devices and wearables.
Data feeds, such as market data in finance.
How To Transport Streams?
A messaging system is required to effectively transport streams. This system has a producer that sends messages containing events, which are then pushed to consumers.
A producer can send a message to consumers directly, of course. For example, using UDP multicast, no broker messaging libraries like ZeroMQ. While these direct messaging approaches work well in some situations, the application code must be aware of the possibility of message loss; therefore, the faults they can tolerate are limited.
Using a Message Broker is typically the most robust way to send messages between producers and consumers. These brokers are special data stores optimized to handle message streams, connecting producers and consumers.

There are primarily two types of message brokers:
AMQP-style message broker. The broker distributes messages to consumers, who process the message and return an acknowledgment. Once acknowledged, messages are removed from the broker. This method is suitable when the precise sequence of message handling isn't crucial, and there is no need to go back and reread old messages after they have been processed. RabbitMQ and Apache ActiveMQ are examples of tools that implement this type of messaging system.
Log-based message broker. The broker designates every message within a partition to a consistent consumer node, ensuring the order of delivery remains unchanged. With messages stored on disk by the broker, revisiting and reading previous messages becomes feasible when required. Some well-known tools that use this approach are Apache Kafka, Amazon Kinesis Stream, and Twitter's DistributedLog.
How Streams Are Processed?
After generating streams, processing begins. These events can be stored in databases, caches, search indices, or comparable storage infrastructures, allowing other users to access and query them subsequently. Or we can push the events to users in some way (by sending email alerts or push notifications). These ways of processing streams are straightforward.
We can also process the input streams to produce one or more output streams. Streams can go through a pipeline consisting of several processing stages before they end up at an output.
There are primarily two types of message brokers:
AMQP-style message broker. The broker distributes messages to consumers, who process the message and return an acknowledgment. Once acknowledged, messages are removed from the broker. This method is suitable when the precise sequence of message handling isn't crucial, and there is no need to go back and reread old messages after they have been processed. RabbitMQ and Apache ActiveMQ are examples of tools that implement this type of messaging system.
Log-based message broker. The broker designates every message within a partition to a consistent consumer node, ensuring the order of delivery remains unchanged. With messages stored on disk by the broker, revisiting and reading previous messages becomes feasible when required. Some well-known tools that use this approach are Apache Kafka, Amazon Kinesis Stream, and Twitter's DistributedLog.
How Streams Are Processed?
After generating streams, processing begins. These events can be stored in databases, caches, search indices, or comparable storage infrastructures, allowing other users to access and query them subsequently. Or we can push the events to users in some way (by sending email alerts or push notifications). These ways of processing streams are straightforward.
We can also process the input streams to produce one or more output streams. Streams can go through a pipeline consisting of several processing stages before they end up at an output.
Approaches to Processing Streams
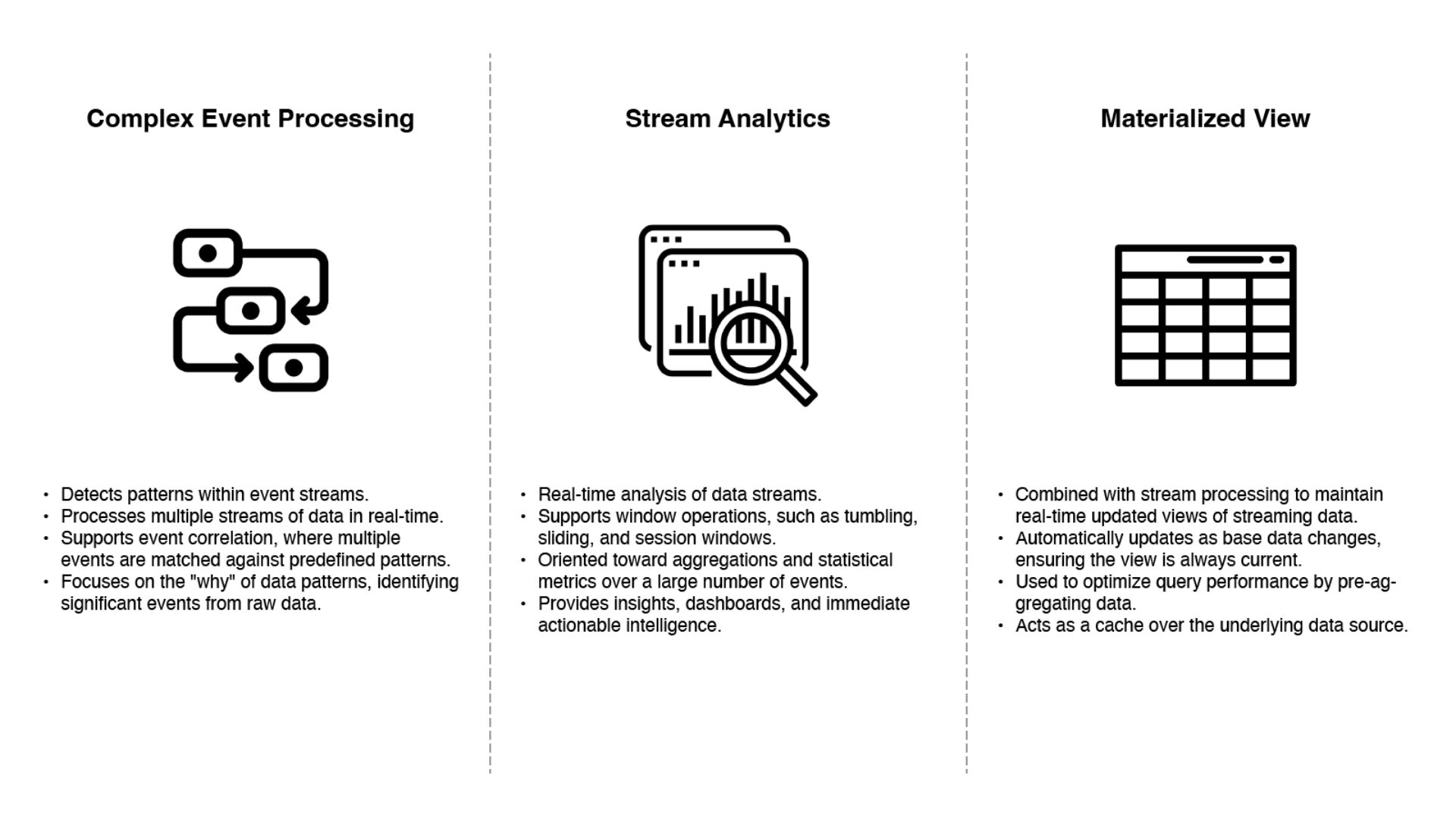
There are three common approaches when processing streams. All of them have their use cases. They are:
Complex Event Processing (CEP). Originating in the 1990s, CEP was designed to dissect event streams, especially for applications aiming to pinpoint distinct event sequences. Much like regular expressions facilitate the search for character patterns within a string; CEP offers the means to set criteria for identifying particular event patterns in a stream. This is achieved using sophisticated query languages such as SQL or a graphical interface to define the event patterns of interest. Tools that implement CEP include Esper and IBM InfoSphere Streams.
Stream Analytics. Stream analytics is often used to get aggregations and statistical metrics over many events, like measuring the rolling average of a value over some time or comparing current statistics to previous time intervals (e.g., the number of sales compared to the same time last week). Tools that provide this functionality include Apache Storm, Apache Spark Structured Streaming, Apache Flink, and Apache Kafka Streams.
Maintaining Materialized Views. A continuous flow of database updates can create a different view on a dataset, enabling more efficient querying and updating that view whenever the underlying data changes. Building the materialized view requires all events over an arbitrary period, apart from any obsolete events that may be discarded. This is a different approach to the Stream Analytics above, where we only need to consider events within some time window. Any stream processor could be used for materialized view maintenance, although the need to maintain events forever contradicts the assumptions of some analytics-oriented frameworks that mostly operate on windows of limited duration.
Challenges
While real-time streaming is an immensely powerful tool, it has its challenges. Mainly, you need to understand three challenges with this powerful technology.
Reasoning With Time
Often, stream processors grapple with time-related issues, particularly in analytics, where time windows are commonly employed. For example, how to get "the average over the last ten minutes"? The meaning of "the last ten minutes" can be quite ambiguous.
In general, when dealing with time, you need to ask the following questions:
Are you using the event time or the processing time? Mixing up events and processing times can result in inaccurate data.
Are you using the device clock or the server clock? You need to be clear about which clock you are using.
How should you determine the timestamps of an event? Things can get tricky as you can never be sure when you have received all the events for a particular window or whether some are still to come. Once you know how the timestamp should be determined, you need to decide how windows over periods should be defined. You can use tumbling, hopping, sliding, or session windows.
Joining Streams
In batch processing, joining datasets by keys forms an essential part of data pipelines. Since stream processing data pipelines are used to process continuous and unbounded datasets, there is the same need for joins on streams. However, the unpredictability of when new events might emerge in a stream complicates the whole process.
Generally, there are three types of joins:
Stream-Stream Joins (Window Joins). In this type of join, there are two input streams with activity events, and we use the join operator to search for related events within a time window. An instance might involve pairing two activities executed by an identical user in 30 minutes.
Stream-Table Joins (Stream Enrichment). One of the input streams captures activity events, whereas the other represents a database changelog. This changelog maintains a current local replica of the database. The join operator queries the database for each activity event and outputs an enriched activity event.
Table-Table Joins. The two input streams in this scenario are both database changelogs. Here, each modification from one stream is paired with the most recent version from the other. The outcome is a continuous update to the materialized view representing the connection between the two datasets.
Fault Tolerance
In batch processing, you can tolerate faults: if a job fails, it can simply be started again on another machine, and the output of the failed task is discarded. In particular, the batch approach to fault tolerance ensures that the output of the batch job is the same as if nothing had gone wrong, even if some tasks did fail. It appears every input record was processed exactly once—no records are skipped, and none are processed twice. Although restarting tasks means that records may, in fact, be processed multiple times, the visible effect in the output is as if they had only been processed once.
In stream processing, it is less straightforward. Given that stream processes are long-running and constantly generate outputs, we can't just eliminate all the results. A more nuanced recovery strategy is required, employing techniques like microbatching, checkpointing, transactional processes, or idempotent operations.
Conclusion
Real-time streaming offers unprecedented opportunities for timely insights, decision-making, and responsive actions in various fields. While the mechanics behind streams, from their origination to processing, may seem intricate, understanding them is essential for harnessing their potential fully. As industries lean more towards real-time data analysis, the importance of comprehending the nuances of streaming will only increase. Facing the challenges head-on and leveraging the power of real-time data will undoubtedly pave the way for a more informed, responsive, and data-driven future.
Subscribe to my newsletter
Read articles from GlassFlow directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by