Membuat Aplikasi Image Generation dengan Gradio
 Muhammad Ihsan
Muhammad Ihsan
Pada era sekarang, kehidupan manusia hampir tidak bisa terlepas dari teknologi. Kemajuan teknologi beriringan dengan kreativitas individu seringkali bisa menghasilkan karya yang luar biasa. Salah satu kemajuan terbaru yang cukup menarik perhatian khususnya di bidang komputer adalah kemampuan komputer untuk menghasilkan gambar hanya dari deskripsi teks. Saat ini kita bisa menggambarkan sebuah pemandangan unik, atau objek futuristik dengan menuliskan beberapa kalimat, dan sebuah model kecerdasan buatan akan menciptakan gambar yang sesuai dengan deskripsi tersebut. Teknologi ini, yang dikenal sebagai image generation, salah satu model generatif canggih yang banyak digunakan untuk melakukan image generation adalah Stable Diffusion. Pada artikel ini, kita akan mengeksplorasi bagaimana model Stable Diffusion bekerja dan bagaimana kita dapat menggunakannya untuk menghasilkan gambar dari teks dengan bantuan API dari Hugging Face dan interface interaktif Gradio.
Image Generation
Image generation adalah proses menghasilkan gambar baru dari deskripsi teks atau prompt. Proses ini melibatkan penggunaan model pembelajaran mesin yang telah dilatih pada dataset besar berupa gambar dan teks terkait. Model ini belajar mengidentifikasi dan memahami hubungan antara teks dan elemen visual dalam gambar.
Beberapa aplikasi image generation termasuk:
Generative Art: Membuat karya seni digital baru berdasarkan deskripsi artistik.
Graphic Design: Membantu desainer dengan ide-ide visual berdasarkan deskripsi proyek.
Game Development: Menghasilkan aset visual seperti karakter, latar belakang, dan objek berdasarkan deskripsi naratif.
Stable Diffusion
Stable Diffusion merupakan contoh salah satu model yang banyak digunakan untuk tugas image generation. Pada dasarnya, model difusi bekerja dengan cara membalikkan proses difusi atau penyebaran. Bayangkan bagaimana tinta menyebar di atas selembar kertas ketika tetesan tinta jatuh: proses difusi ini menyebarkan tinta dari keadaan terkonsentrasi menjadi lebih tersebar dan buram. Model difusi, termasuk Stable Diffusion, melakukan hal sebaliknya—mereka memulai dari gambar yang sangat buram (noise) dan secara bertahap "membersihkan" atau menajamkan gambar tersebut berdasarkan pola yang telah mereka pelajari selama training.Tahapan dalam model difusi antara lain:
Membuat Noise: Pada awalnya, model memulai dengan gambar yang penuh noise, yang pada dasarnya adalah gambar acak yang tidak memiliki informasi visual yang bermakna.
Pembelajaran Pola: Model kemudian belajar mengenali pola dan struktur dalam gambar yang berhubungan dengan teks yang diberikan. Selama pelatihan, model belajar dari banyak pasangan gambar dan teks, sehingga mampu mengenali objek dan konsep dari deskripsi teks.
Proses Iteratif: Melalui proses iteratif, model mulai mengurangi noise secara bertahap, menghasilkan gambar yang semakin jelas dan sesuai dengan deskripsi teks pada setiap langkah iterasi.
Guidance: Pengguna dapat mengontrol seberapa kuat pengaruh teks terhadap hasil akhir dengan menggunakan skala panduan (guidance scale). Ini memungkinkan kontrol lebih besar atas hasil yang diinginkan.
Model Stable Diffusion menggunakan arsitektur Transformer yang telah diadaptasi untuk tugas generatif ini. Arsitektur ini memungkinkan model untuk menangkap hubungan jangka panjang dalam data dan memahami konteks kompleks dalam teks deskripsi. Kelebihan dari stable difussion antara lain:
Kualitas Gambar Tinggi: Stable Diffusion mampu menghasilkan gambar dengan resolusi tinggi dan detail yang tajam, membuatnya sangat cocok untuk aplikasi kreatif dan desain.
Fleksibilitas dan Kontrol: Pengguna dapat mengontrol berbagai aspek dari proses generasi, seperti jumlah langkah inferensi dan skala panduan. Ini memungkinkan penyesuaian hasil akhir sesuai kebutuhan spesifik.
Kecepatan dan Efisiensi: Dibandingkan dengan beberapa model generatif lainnya, Stable Diffusion menawarkan kecepatan dan efisiensi yang lebih baik dalam menghasilkan gambar berkualitas tinggi.
Implementasi
Pada artikel ini, kita akan membuat aplikasi image generation menggunakan model Stable Diffusion yang tersedia di Hugging Face. Kita akan menggunakan API inference dari Hugging Face dan Gradio untuk membuat antarmuka interaktif yang memungkinkan pengguna untuk menghasilkan gambar dari deskripsi teks.
Mengatur Kunci API
Pertama, kita perlu mengatur dan memuat kunci API dari Hugging Face untuk dapat mengakses layanan inference mereka. Kunci API ini biasanya disimpan dalam file .env untuk keamanan.
import io
import requests
import gradio as gr
from PIL import Image
import os
import requests
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv()) # read local .env file
hf_api_key = os.environ['HF_API_KEY']
Pada kode di atas, kita menggunakan library dotenv untuk memuat kunci API dari file .env. Pastikan kita telah menambahkan kunci API kita di file .env dengan format HF_API_KEY=your_hugging_face_api_key.
Membuat Fungsi untuk Mengakses API
Selanjutnya, kita akan membuat fungsi query yang akan mengirimkan deskripsi teks ke API Hugging Face dan menerima hasil gambar yang dihasilkan dari deskripsi tersebut.
API_URL = "https://api-inference.huggingface.co/models/runwayml/stable-diffusion-v1-5"
headers = {"Authorization": f"Bearer {hf_api_key}"}
def query(payload):
response = requests.post(API_URL, headers=headers, json=payload)
return response.content
Fungsi query menggunakan modul requests untuk mengirimkan deskripsi teks ke API Hugging Face. Hasil dari API akan dikembalikan dalam bentuk gambar dalam format byte.
Membuat Fungsi Generate
Kita kemudian membuat fungsi generate yang akan memanggil fungsi query dan mengembalikan gambar yang dihasilkan dari deskripsi teks.
def generate(prompt, steps, guidance, width, height):
image_bytes = query({
"inputs": prompt,
"parameters": {
"steps": steps,
"guidance_scale": guidance,
"width": width,
"height": height
}
})
image = Image.open(io.BytesIO(image_bytes))
return image
Fungsi ini menerima parameter seperti deskripsi teks (prompt), jumlah langkah inferensi (steps), skala panduan (guidance), lebar (width), dan tinggi (height). Hasil dari API kemudian diubah menjadi format gambar yang dapat ditampilkan.
Membuat Antarmuka Gradio
Terakhir, kita akan membuat interface menggunakan Gradio.
demo = gr.Interface(
fn=generate,
inputs=[
gr.Textbox(label="Your prompt"),
gr.Slider(label="Inference Steps", minimum=1, maximum=100, value=25, info="In how many steps will the denoiser denoise the image?"),
gr.Slider(label="Guidance Scale", minimum=1, maximum=20, value=7, info="Controls how much the text prompt influences the result"),
gr.Slider(label="Width", minimum=64, maximum=512, step=64, value=512),
gr.Slider(label="Height", minimum=64, maximum=512, step=64, value=512),
],
outputs=[gr.Image(label="Result")],
title="Image Generation with Stable Diffusion",
description="Generate any image with Stable Diffusion",
allow_flagging="never"
)
demo.launch()
demo.close()
Interface ini memungkinkan pengguna untuk memasukkan deskripsi teks dan menyesuaikan parameter generasi gambar. Dengan Gradio, kita dapat dengan mudah menampilkan aplikasi ini di browser.
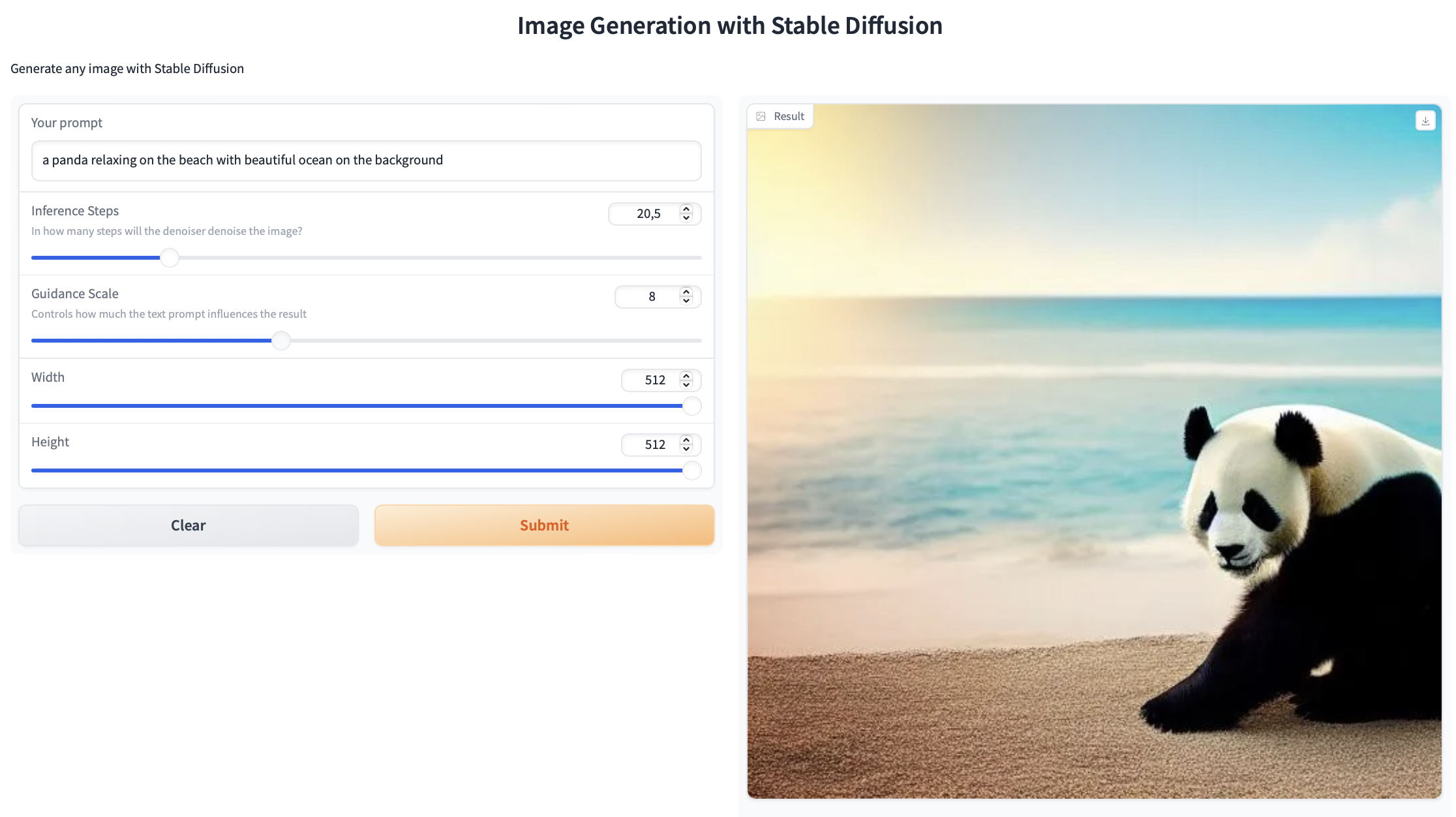
Kesimpulan
Pada artikel ini, kita telah belajar cara menggunakan model Stable Diffusion dari Hugging Face untuk melakukan image generation. Kita juga telah membuat antarmuka interaktif menggunakan Gradio yang memungkinkan pengguna untuk menghasilkan gambar dari deskripsi teks dengan mudah. Teknologi ini membuka peluang besar dalam berbagai aplikasi kreatif dan desain. Terimakasih sudah membaca artikel ini, selamat belajar!
Source Code: Link to GitHub Repository
Subscribe to my newsletter
Read articles from Muhammad Ihsan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Muhammad Ihsan
Muhammad Ihsan
AI, ML and DL Enthusiast. https://www.upwork.com/freelancers/emhaihsan https://github.com/emhaihsan https://linkedin.com/in/emhaihsan