BeautifulSoup vs Scrapy vs Selenium
 Arpan Mahatra
Arpan Mahatra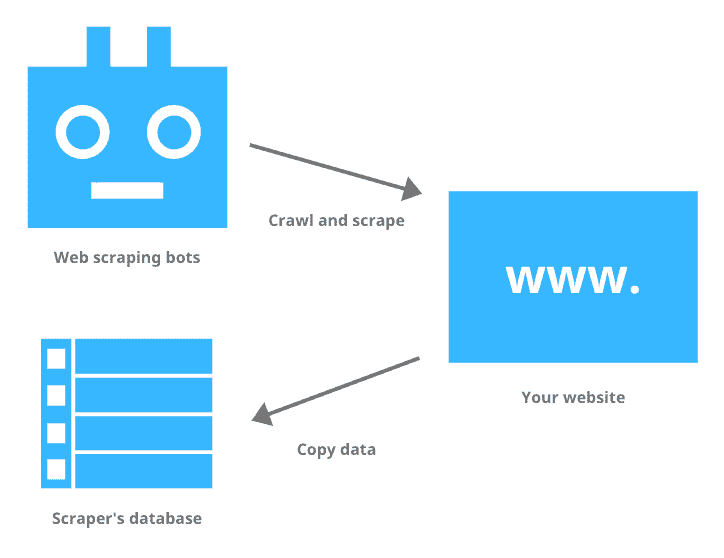
As a data analyst, the first step we always go through is data collection. When we are doing company project, we receive most data from organizational databases. However, when we do non-organizational projects, we consider web-scraping as a sole method. Webscraping involves automatic extraction of data content from websites and converting into structured format.
There are websites like Kaggle but they mostly provide fictional datasets for practice purpose.
The biggest dilemma is never the source but the tool for web scraping. There are 3 major web scraping libraries in Python: BeautifulSoup, Scrapy and Selenium. You realize this as one major query in data analyst interview: which web-scraping library should we choose and why? So, I decided to research on general information, pros and cons of all 3 libraries to help readers select one of them based on programmer and project necessities.
BeautifulSoup

This library is targeted for beginners in programming and web scraping. With great documentation and big community, it is easier for small scale projects. BeautifulSoup helps data extraction through HTML and XML files.
Though it is easier to learn, BeautifulSoup requires other modules for making requests (requests and urllib). It also doesn't support interaction with websites like clicking buttons. Parallelization in requests processing is possible but we should have better understanding of multithreading concept.
Scrapy

If you are looking for web crawling library with fast pace and low memory usage, Scrapy is the best. The architecture is well designed for middleware customization and adding own custom functionality. Scrapy can handle multiple HTTP requests together. There are no extra dependencies required for GET requests. Scrapy is productive for big projects.
But, Scrapy is not an easy tool and has no beginner friendly documentation.
Selenium

It is a webdriver and API of JS dependent pages and controls headless browser. Mostly meant for automated web testing, Selenium first loads website in browser and then scraps data. For parallelization, Selenium needs multiple browser instances. It easily interacts with website with core JS concepts (DOM) and easily handles AJAX and PJAX requests.
Since it requires multiple browser instances, it is way heavier too. Either it takes high computing power or your device will be slower.
Conclusion
After studying all 3 libraries, I realized BeautifulSoup could be selected for small scale projects due to beginner friendly documentation and large community. Scrapy can be used for large-scale projects due to fast pace, better memory usage and parallelization. Selenium is best suited for automation testing because of website interaction feature.
References
“What Is Web Scraping? | Mlytics.” Mlytics Learning Center, 2 May 2019, learning.mlytics.com/the-internet/what-is-web-scraping/.
“What Is Scraping | about Price & Web Scraping Tools | Imperva.” Learning Center, www.imperva.com/learn/application-security/web-scraping-attack/.
Melanie. “Beautiful Soup: Introduction to Web Scraping with Python.” Data Science Courses | DataScientest, 20 Jan. 2024, datascientest.com/en/beautiful-soup-introduction-to-web-scraping-with-python.
Mishra, Chetan. “Using Scrapy to Create a Generic and Scalable Crawling Framework.” Medium, Medium, 9 July 2018, medium.com/@chetaniam/using-scrapy-to-create-a-generic-and-scalable-crawling-framework-83d36732181.
Selenium. “SeleniumHQ Browser Automation.” Www.selenium.dev, 2023, www.selenium.dev/.
Subscribe to my newsletter
Read articles from Arpan Mahatra directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by