Day 15/40 Days of K8s: Node Affinity in Kubernetes !! ☸️
 Gopi Vivek Manne
Gopi Vivek Manne
❓Why the need for Node Affinity?
We've already covered Taints&Tolerations,NodeSelector and Labels as well. Let's review these concepts once again To better understand the concept and need of Node Affinity.
Taints & Toleration: It gives nodes the ability to accept certain pods to be scheduled on who have matching toleration set on them. This is node centric approach and it doesn’t guarantee pod exclusivity.
Drawback: If a pod has toleration set will be scheduled on tainted node, however it doesn’t mean that it can’t go on to any other node. It doest offer pod the ability to decide or control on which node they should be placed.
Example:
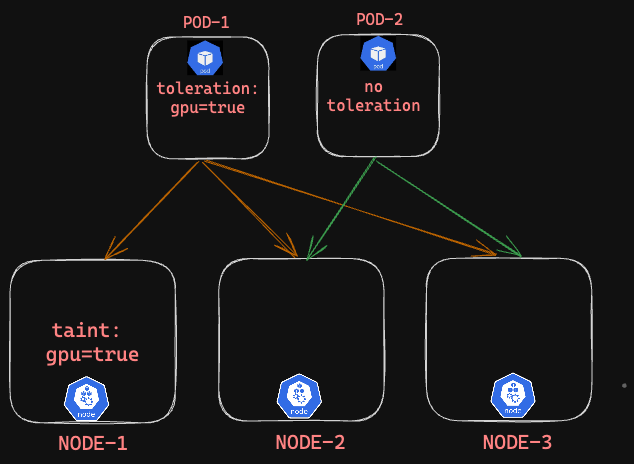
Explanations:
NODE-1: Only Pod1 can be scheduled as it can tolerate the taint.
NODE-2: Pod1,pod2 can be scheduled as both pods have no NodeSelector to restrict them.
NODE-3: pod1,pod2 can be scheduled as both have no NodeSelector to restrict them.
"'POD1 can schedule on all three nodes, not just the tainted Node1"
Nodeselector and labels: Specifically pod to decide on which node it wants to be scheduled on. To extend this capability of pod, we have NodeSelector and labels, where NodeSelctor is used at pod level with labels set and matching label at node level for scheduling on that node.This is more of pod centric approach.
Drawback:
But, the issue here is pod doesn’t have the capacity to implement operators like AND,OR and conditional like multiple nodes at a time. Just limited scope for scheduling and doesn’t offer flexibility when pods require more complex scheduling needs across multiple nodes simultaneously.
Example:
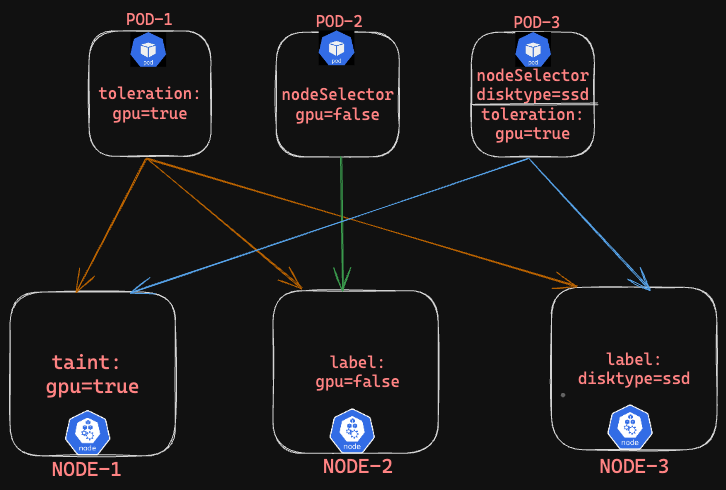
Explanation:
POD-1 : Can schedule on all three nodes,
POD-1 -----> Node-1 = It can tolerate the taint
POD-1 -----> Node-2 = No nodeSelector restriction
POD -1 -----> Node-3 = No nodeSelector restrictionPOD-2 - Can schedule on Node2 as it has nodeselector and labels set.
POD-3 - Can schedule on both Node1,Node3,
POD3 ------> Node-1 = It can tolerate the taint
POD3 ------> Node-3 = It has nodeSelector restriction
POD-2 can specifically schedule on NODE-2 using nodeSelector and labels
POD-3 can schedule on both NODE-1,NODE-2 using the combination of nodeSelector and labels,Taints&Toleration
🤷♂️ Challenge
Even using the combination of taints& tolerations, and node selectors,labels we faced issues regarding pod exclusive scheduling on a specific node. While we successfully configured the pod to schedule on the desired node using these methods, we faced a challenge as the pod continued to schedule on other nodes as well.
🌟 Node Affinity
Node affinity extends the capabilities of node selectors and labels by allowing pods to specify conditions, operators, and labels to determine exclusively which node they should be scheduled on.
Example:
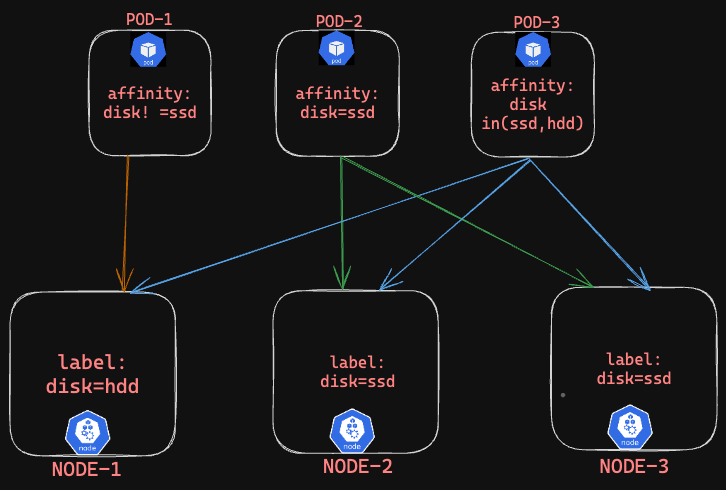
Explanation
POD-1 - Pod1 with affinity set disk !=ssd, is able to schedule on Node-1 as it has label disk=hdd.
POD-2 - Pod2 with affinity set disk=ssd, is able to schedule on Node-2,Node-3 with matching labels disk=ssd on them.
POD-3 - Pod3 with affinity set using conditional operator disk in (ssd,hdd) which means it can schedule on Node1,Node2,Node3 as matching with respective labels.
NOTE: Though the label is not matching really, but conditions of operators comes into play here while scheduling, if it meets the condition it will schedule accordingly.
Drawback:
What if the nodeaffinity label on the pod is updated or removed after it is being scheduled on the node already? Does pod get evicted like it did in taints and tolerations(noExecute)?
🌟 Properties in Node Affinity
requiredDuringSchedulingIgnoredDuringExecution
preferredDuringSchedulingIgnoredDuringExecution
Let's breakdown to understand how does these properties function.
✅ IgnoredDuringExecution: If a pod has already been scheduled, any changes on the affinity label on the pod won’t impact the existing pod, not evicted, will only impact new pods. This is common in either of these properties.
✅ requiredDuringScheduling: Make sure to schedule the pod on only matching operator node. The pod gets scheduled on the matching label of the node.
✅ preferredDuringScheduling: Prefer scheduling pods on nodes according to the specific criteria like matching affinity and conditional operators and labels matching, however if not found just go ahead and place it anywhere. It does not enforce strict placement like "requiredDuringScheduling".
TASK:
create a pod with nginx as the image and add the nodeaffinity with property
requiredDuringSchedulingIgnoredDuringExecutionand conditiondisktype = ssd#This pod with node affinity set to `requiredDuringSchedulingIgnoredDuringExecution` will only prefer nodes that match the label expression. #Then, it will still schedule the pod on the specific node that matches the labels found. apiVersion: v1 kind: Pod metadata: labels: run: nginx name: nginx spec: containers: - image: nginx name: nginx dnsPolicy: ClusterFirst restartPolicy: Always affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: In values: - ssdCheck the status of the pod and see why it is not scheduled
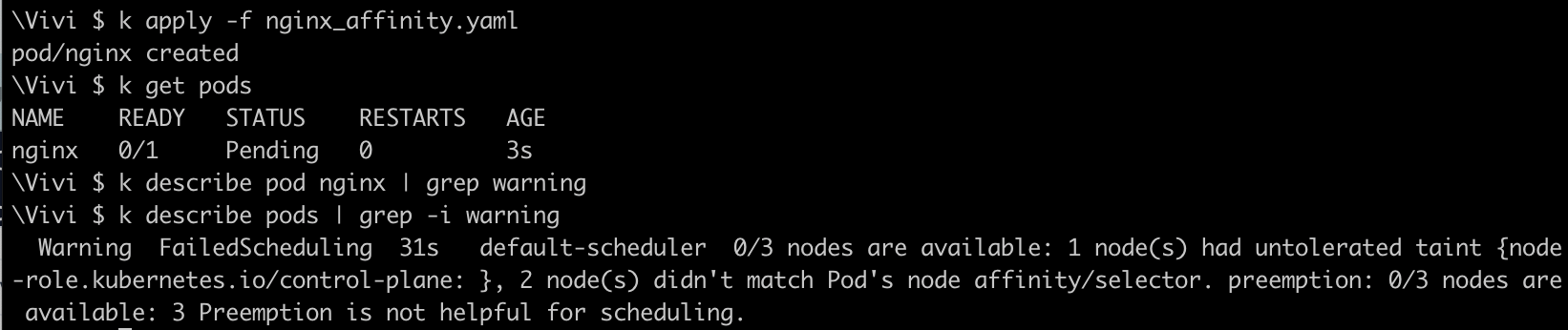
Pod scheduling failed with reason, 1 Node was tainted by control-plane to run all the master processes, 2 other nodes didn't match with pod affinity set.
Add the label to your
kind-cluster-1-worker2node asdisktype=ssdand then check the status of the pod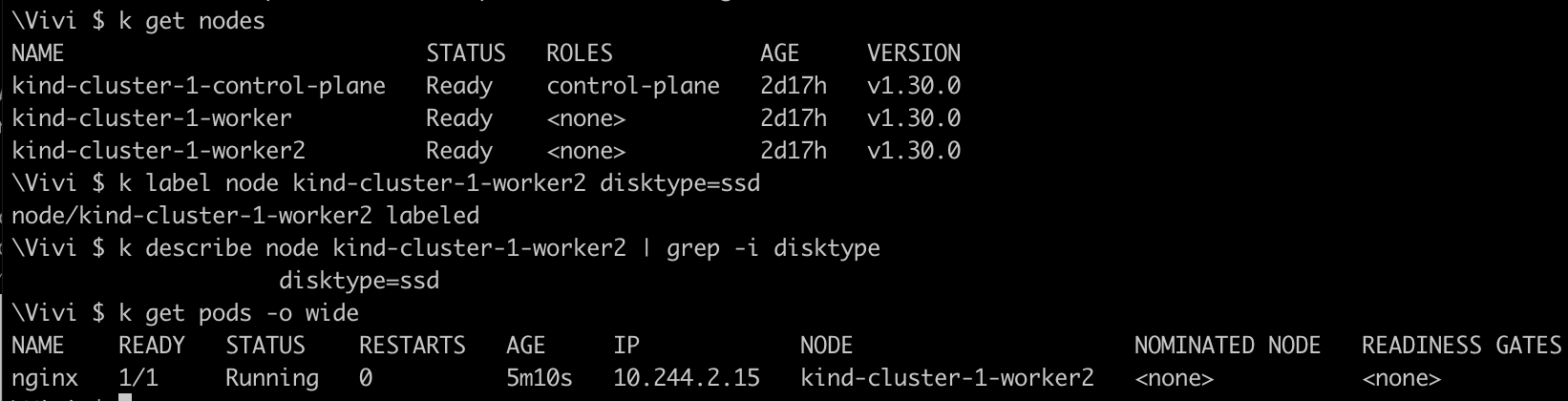
The
nginxpod is now scheduled onkind-cluster-1-worker2node once we added label to the node.create a new pod with redis as the image and add the nodeaffinity with property
requiredDuringSchedulingIgnoredDuringExecutionand conditiondisktypewith no value# This pod with node affinity set to `requiredDuringSchedulingIgnoredDuringExecution` will select nodes that match the `disktype` label expression. # The pod will be scheduled on a node that meets this criterion using the `Exists` operator. apiVersion: v1 kind: Pod metadata: labels: run: redis name: redis spec: containers: - image: redis name: redis dnsPolicy: ClusterFirst restartPolicy: Always affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: disktype operator: Exists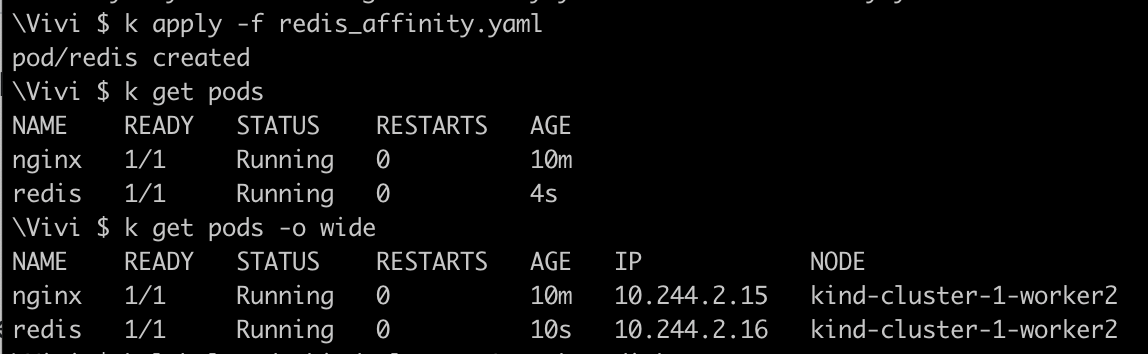
As you can see, once redis is created it was scheduled on
kind-cluster-1-worker2where we setdisktype=ssd. Our pod will pick any nodes which has gotdisktypelabel irrespective of the value assigned to it.Now, lets add the label of
disktypewith no value tokind-cluster-1-workernode and redeploy redis pod to ensure that it should be scheduled onkind-cluster-1-worker
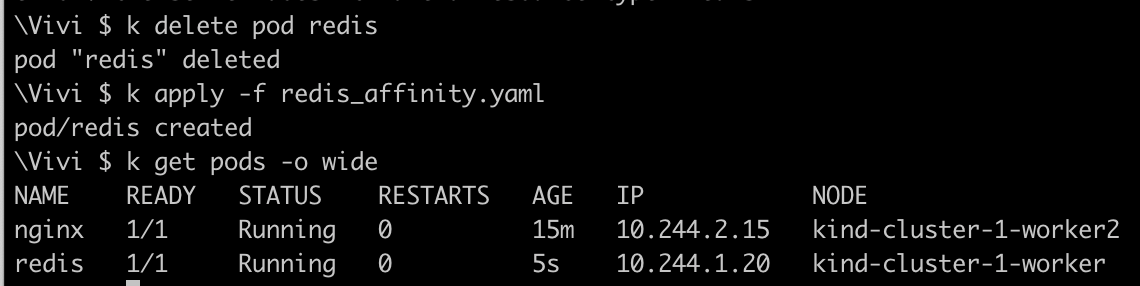
Now, the
redispod is deployed on kind-cluster-1-worker node as it matches withdisktypeoperator.create a new pod with redis as the image and add the nodeaffinity with property
preferedDuringSchedulingIgnoredDuringExecutionand conditiondisktype=hddapiVersion: v1 kind: Pod metadata: labels: run: redis-2 name: redis-2 spec: containers: - image: redis-2 name: redis-2 dnsPolicy: ClusterFirst restartPolicy: Always affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: disktype operator: In values: - hdd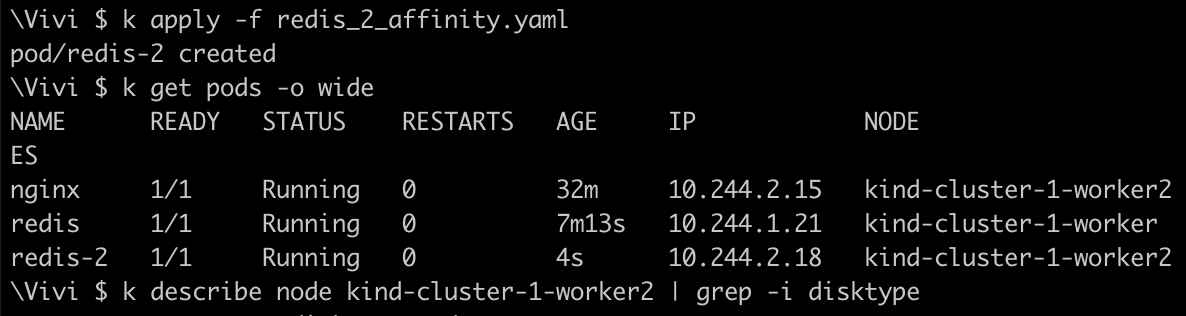
We used node affinity with
preferredDuringSchedulingIgnoredDuringExecutionand the conditiondisktype=hdd. However, the pod was scheduled onkind-cluster-worker2with the labeldisktype=ssd, indicating the pod prefers but does not require nodes with thedisktype=hddlabel explicitly.
✳ Node Affinity vs Taints &Tolerations
When we use Nodeaffinity or Taints&Tolerations separately,
Example:
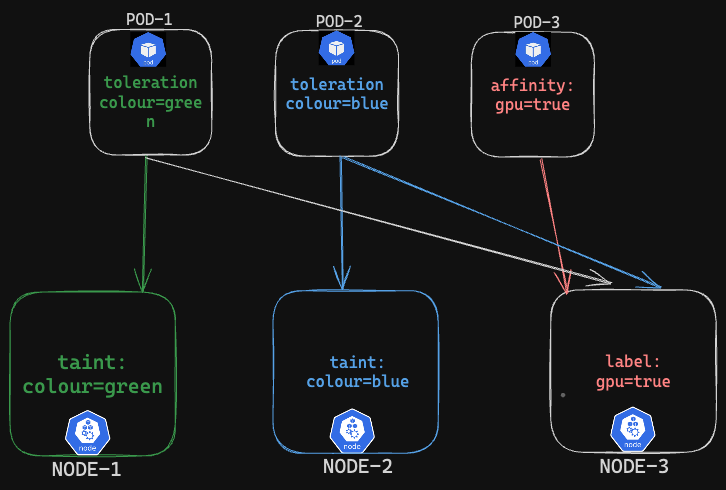
Pod-1,Pod-2 can be scheduled on Node-1 and Node-2 respectively as they can tolerate the taints, Both of them can also be scheduled on Node-3 since no
nodeSelectorornodeAffinityrestrictions.
🎯 Challenge:we want to restrict the pod scheduling SOLELY on specific targeted node
✳ Node Affinity and Taints &Tolerations
With the combination of Nodeaffinity and Taints &Tolerations we can restrict the pod to be able to scheduled on ONLY specific targeted node.
Example:
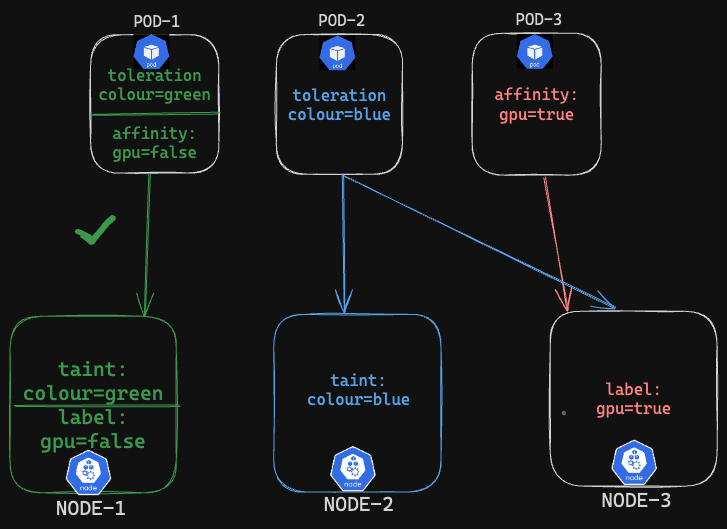
Explanation
POD-1 : Can only schedule on Node-1 as it can tolerate the taint and also match the label
gpu=falseon the node using pod's nodeaffinity.POD-2: can schedule on Node-2 as it can tolerate the taint set,Node-3 as no
nodeSelectorornodeaffinityrestrictions.POD-3: can only schedule on Node-3 as it matches with the label
gpu=trueon the node using pod's nodeaffinity
NOTE: Assuming the above example in case when we use nodeaffinity property set to
requiredDuringSchedulingIgnoredDuringExecution
🌟 Key Observations:
Taints & Tolerations: Nodes decide which pods to accept based on tolerations. No pod exclusivity.
Node Selector & Labels: Pods decide which node to use but lack flexibility for complex scheduling or exclusivity.
Node Affinity: Extends node selection with complex scheduling using operators. Can't ensure pod scheduling on specific nodes exclusively.
Updating or removing node labels post-scheduling doesn't evict pods due to node affinity(properties). Removing taint evicts toleration-set pods immediately.
Using Node Affinity + Taints & Tolerations: Ensures specific node usage. Use either or both for our custom scheduling needs.
#Kubernetes #Taints&Tolerations #NodeSelector #NodeAffinity #40DaysofKubernetes #CKASeries
Subscribe to my newsletter
Read articles from Gopi Vivek Manne directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gopi Vivek Manne
Gopi Vivek Manne
I'm Gopi Vivek Manne, a passionate DevOps Cloud Engineer with a strong focus on AWS cloud migrations. I have expertise in a range of technologies, including AWS, Linux, Jenkins, Bitbucket, GitHub Actions, Terraform, Docker, Kubernetes, Ansible, SonarQube, JUnit, AppScan, Prometheus, Grafana, Zabbix, and container orchestration. I'm constantly learning and exploring new ways to optimize and automate workflows, and I enjoy sharing my experiences and knowledge with others in the tech community. Follow me for insights, tips, and best practices on all things DevOps and cloud engineering!