Prediksi Kualitas Wine dengan Support Vector Machine
 Muhammad Ihsan
Muhammad Ihsan
Ketika kita mulai belajar machine learning, kita tentu tidak akan asing dengan istilah Support Vector Machine (SVM). SVM merupakan algoritma machine learning yang banyak digunakan untuk klasifikasi dan regresi. Pada artikel ini, kita akan belajar tentang SVM dan mencoba mengimplementasikannya untuk menentukan kualitas dari suatu wine.
Support Vector Machine
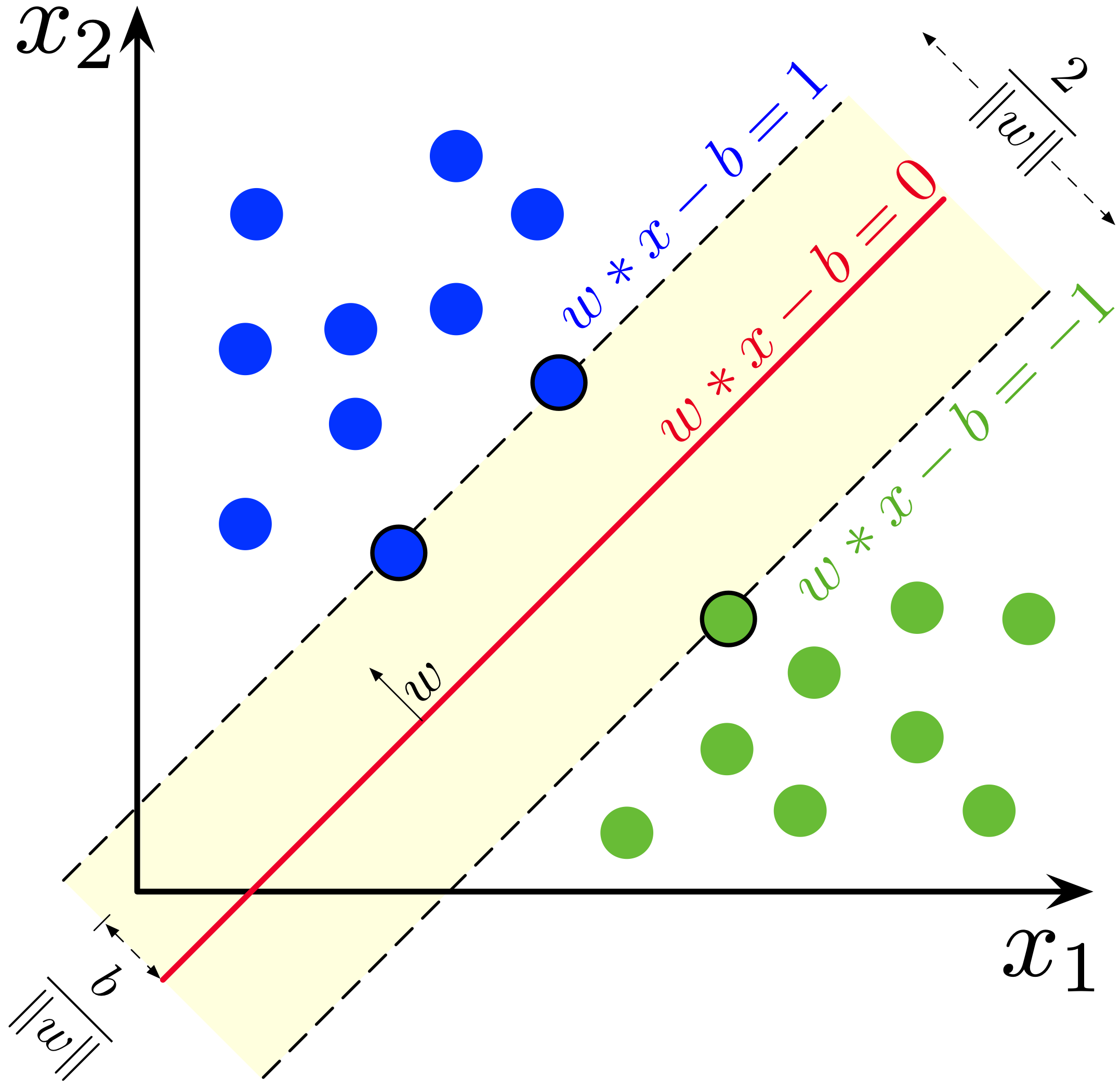
Support Vector Machine merupakan algoritma machine learning yang bekerja dengan cara mencari hyperplane optimal untuk memisahkan data ke dalam kelas-kelas berbeda. Dalam kasus data dua dimensi, hyperplane ini adalah garis lurus yang memisahkan data. Di ruang tiga dimensi, hyperplane menjadi bidang, dan di dimensi lebih tinggi, hyperplane tetap disebut hyperplane. Tujuan SVM adalah menemukan hyperplane yang memaksimalkan margin antara dua kelas, yang dikenal sebagai margin maximization.
Support Vectors
Support vectors adalah titik data yang paling dekat dengan hyperplane. Titik-titik ini sangat penting karena mereka menentukan posisi dan orientasi hyperplane. Jika support vectors diubah, hyperplane yang memisahkan kelas juga akan berubah. Oleh karena itu, SVM hanya bergantung pada beberapa titik data penting ini, menjadikannya efisien dalam hal penggunaan memori.
Margin Maximization
Margin adalah jarak antara hyperplane dan titik data terdekat dari setiap kelas. SVM berusaha untuk menemukan hyperplane yang memaksimalkan margin ini. Hyperplane dengan margin terbesar dipilih karena diharapkan dapat memberikan generalisasi yang lebih baik pada data baru. Margin yang lebih besar mengurangi risiko overfitting, yang terjadi ketika model terlalu menyesuaikan data pelatihan dan tidak bekerja dengan baik pada data yang tidak terlihat.
Kernel Trick
Dalam banyak kasus, data tidak dapat dipisahkan secara linear di ruang fitur asli. Untuk mengatasi ini, SVM menggunakan kernel trick, yang memetakan data ke ruang dimensi lebih tinggi di mana data dapat dipisahkan secara linear. Kernel yang umum digunakan termasuk kernel linear, polynomial, dan radial basis function (RBF). Dengan kernel trick, SVM dapat menangani data yang sangat kompleks dan tidak dapat dipisahkan secara linear.
Fungsi Kernel
Linear Kernel: Digunakan untuk data yang dapat dipisahkan secara linear.
Polynomial Kernel: Memetakan data ke ruang polinomial.
Radial Basis Function (RBF) Kernel: Memetakan data ke ruang dimensi tak hingga.
SVM dengan kernel trick memungkinkan model untuk menemukan hyperplane optimal di ruang fitur yang lebih tinggi tanpa perlu menghitung koordinat data dalam ruang tersebut secara eksplisit.
Studi Kasus: Klasifikasi kualitas Wine
Pada bagian ini, kita akan mengimplementasikan algoritma Support Vector Machine (SVM) menggunakan dataset Wine Quality.
Mengimpor Library dan Dataset
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
import matplotlib.pyplot as plt
import seaborn as sns
import numpy as np
import warnings
warnings.filterwarnings('ignore')
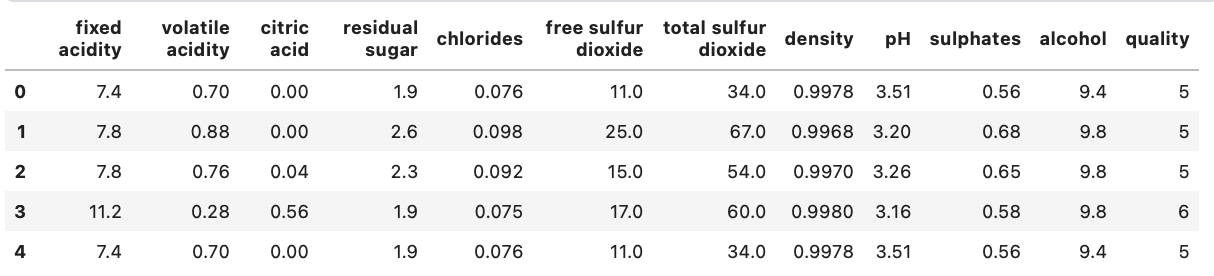
wine_data = pd.read_csv('/kaggle/input/red-wine-quality-cortez-et-al-2009/winequality-red.csv')
wine_data.head()
Pada langkah ini, kita mengimpor library-library yanng diperlukan dan membaca dataset Wine Quality dari file CSV yang tersedia di Kaggle.
Eksplorasi dan Pembersihan Data
Pertama-tama kita memeriksa informasi tentang dataset, termasuk jumlah baris dan kolom, serta tipe data setiap kolom.
wine_data.info()
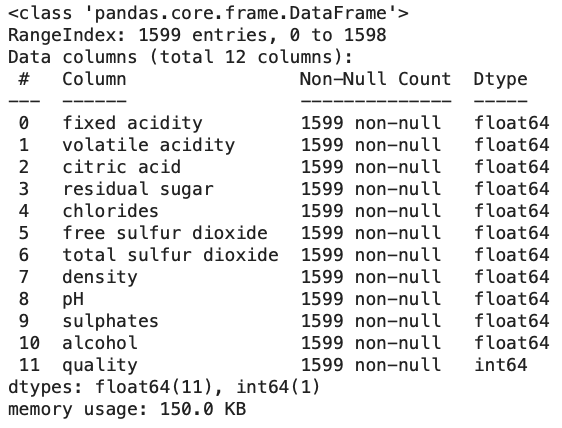
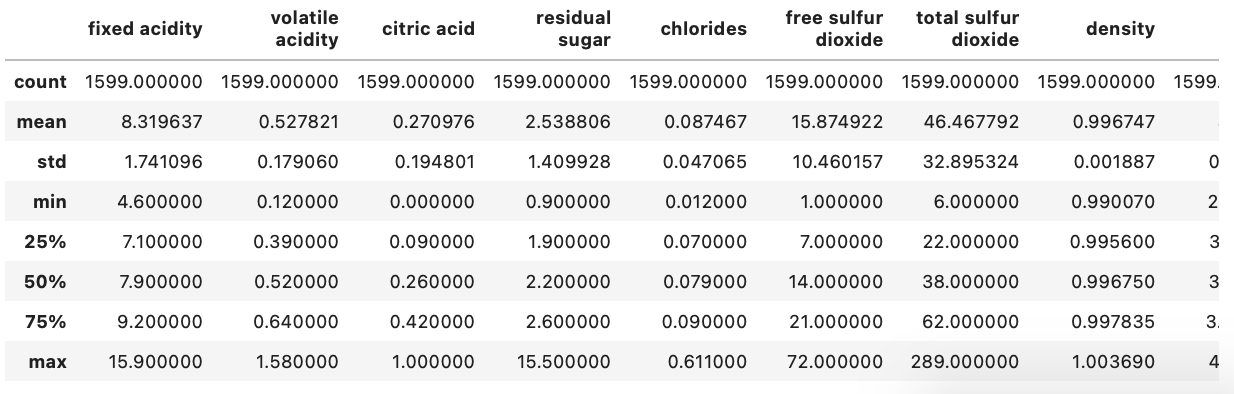
Dari informasi di atas dapat diketahui bahwa keseluruhan data memiliki tipe data numerik. Selanjutnya adalah memeriksa statistik deskriptif dari dataset seperti mean, standard deviation, minimum, dan maximum value untuk setiap fitur.
wine_data.describe()
Kemudian kita juga perlu memeriksa apakah ada missing values dalam dataset.
wine_data.isnull().sum()

Hasil menunjukkan bahwa tidak ada missing values. Selanjutnya kita akan menampilkan sejumlah visualisasi dari data yang kita gunakan
plt.figure(figsize=(8, 6))
sns.countplot(data=wine_data, x='quality', palette='viridis')
plt.title('Wine Quality Distribution')
plt.xlabel('Quality')
plt.ylabel('Count')
plt.show()
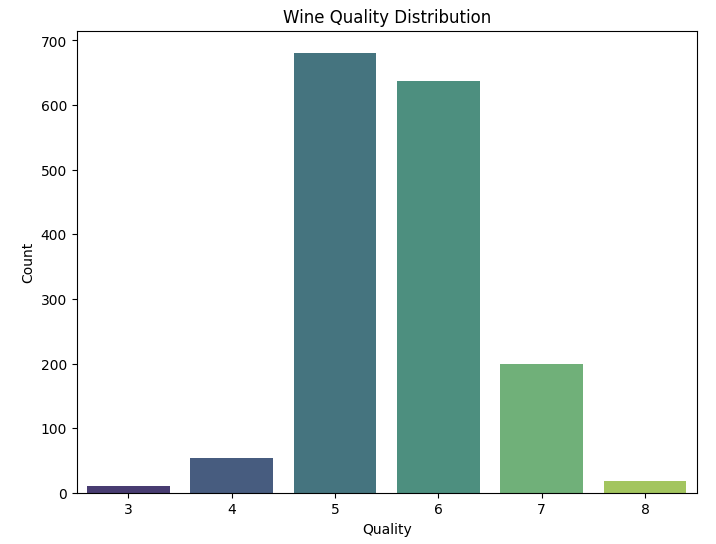
Plot ini menunjukkan sebaran jumlah sampel anggur untuk setiap nilai kualitas. Ini membantu kita memahami berapa banyak anggur yang masuk dalam setiap kategori kualitas.
plt.figure(figsize=(12, 8))
sns.heatmap(wine_data.corr(), annot=True, cmap='coolwarm')
plt.title('Feature Correlation Heatmap')
plt.show()
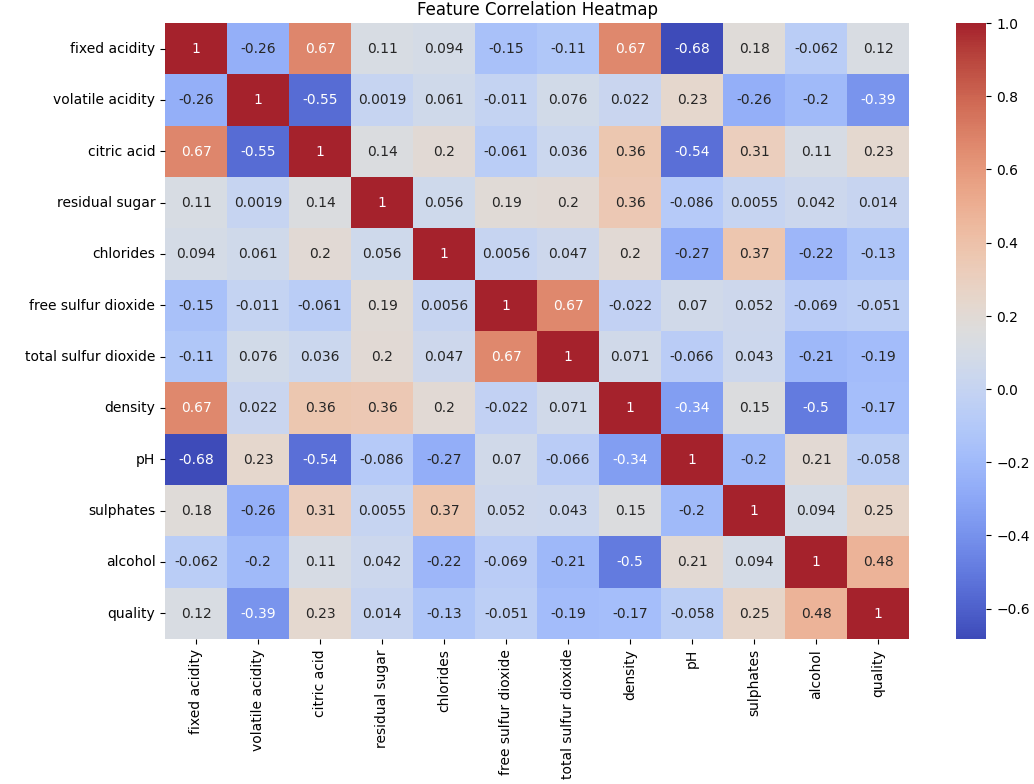
Plot ini menunjukkan korelasi antar fitur dalam dataset. Nilai korelasi berkisar dari -1 hingga 1. Nilai positif menunjukkan korelasi positif, sementara nilai negatif menunjukkan korelasi negatif. Ini membantu kita memahami hubungan antar fitur.
features = ['fixed acidity', 'volatile acidity', 'citric acid', 'residual sugar', 'chlorides', 'free sulfur dioxide', 'total sulfur dioxide', 'density', 'pH', 'sulphates', 'alcohol']
plt.figure(figsize=(20, 15))
for i, feature in enumerate(features):
plt.subplot(4, 3, i+1)
sns.histplot(wine_data[feature], kde=True, bins=30, color='blue')
plt.title(f'Distribusi {feature}')
plt.tight_layout()
plt.show()
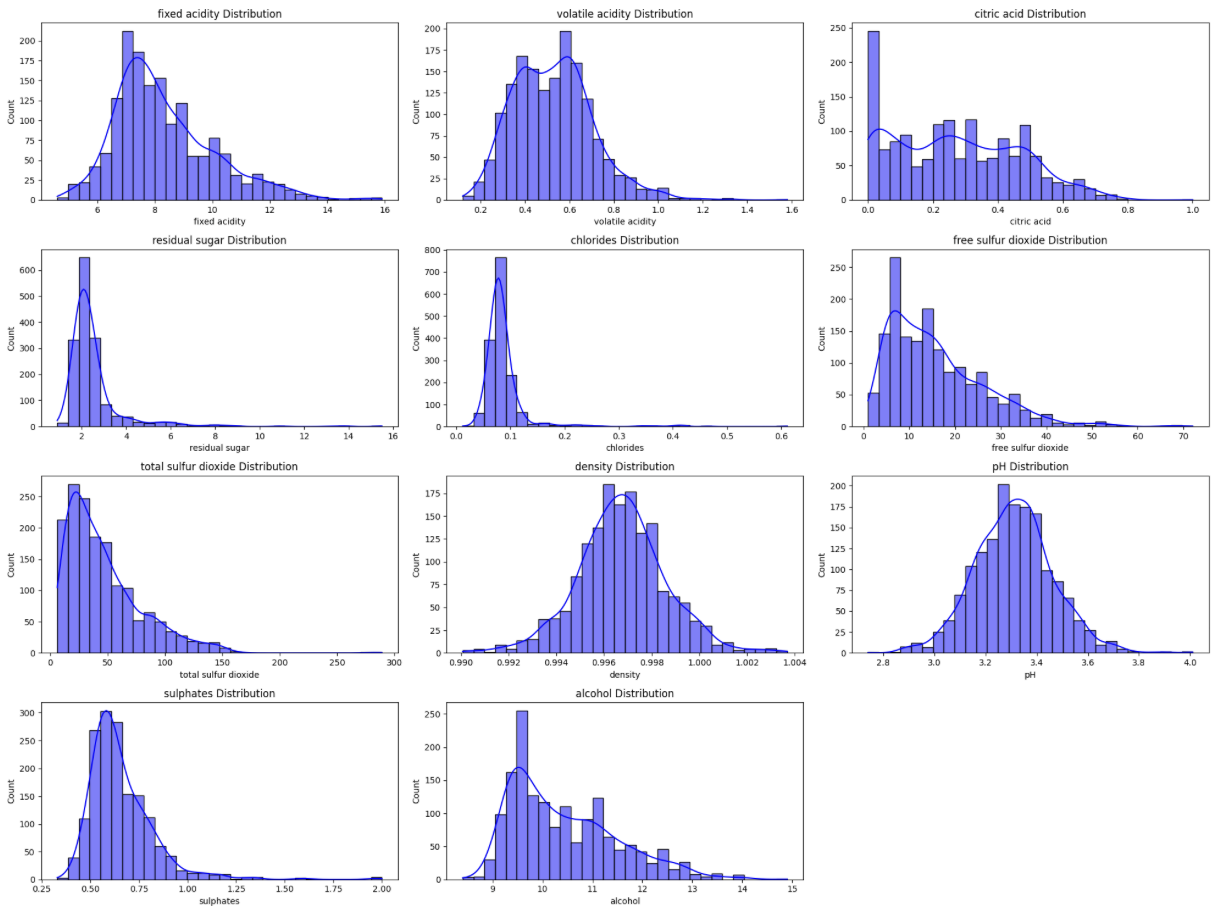
Plot ini menunjukkan distribusi nilai dari setiap fitur utama dalam dataset. Ini membantu kita memahami sebaran data dan mendeteksi adanya outlier.
plt.figure(figsize=(20, 15))
for i, feature in enumerate(features):
plt.subplot(4, 3, i+1)
sns.boxplot(y=wine_data[feature], color='blue')
plt.title(f'Boxplot {feature}')
plt.tight_layout()
plt.show()
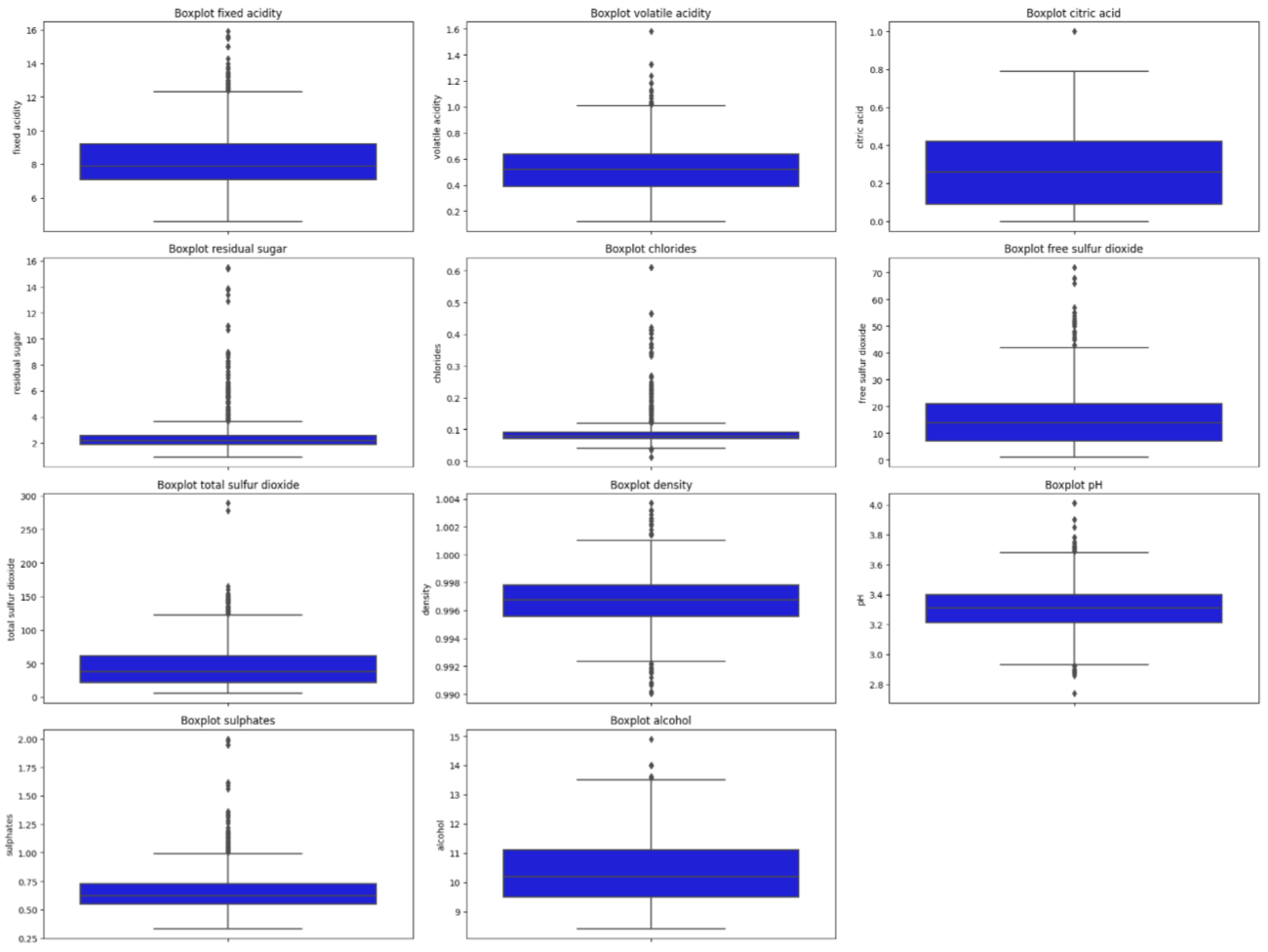
Plot ini menunjukkan boxplot dari setiap fitur utama dalam dataset. Boxplot memberikan informasi tentang distribusi data, median, kuartil, dan potensi outlier. Ini membantu kita memahami karakteristik distribusi setiap fitur lebih detail.
Preprocessing Data
Selanjutnya adalah melakukan prapemrosesan pada data. Tahap ini bertujuan agar data siap dimasukkan ke dalam model machine learning.
X = wine_data.drop('quality', axis=1)
y = wine_data['quality']
y = (y > 5).astype(int)
Pertama, kita memisahkan fitur (X) dan target (y). Kita mengubah kolom quality menjadi variabel binary di mana nilai 0 menunjukkan kualitas <= 5 dan nilai 1 menunjukkan kualitas > 5.
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
Selanjutnya, kita melakukan scaling pada fitur menggunakan StandardScaler untuk memastikan semua fitur memiliki skala yang sama.
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.2, random_state=42)
Kita membagi data menjadi training set dan test set dengan proporsi 80% training dan 20% testing.
Membuat Model SVM
svm_model = SVC(kernel='linear')
svm_model.fit(X_train, y_train)
y_pred = svm_model.predict(X_test)
Pada bagian ini, kita membangun model SVM menggunakan kernel linear dan melatihnya dengan data training. Kemudian, kita melakukan prediksi pada data test.
Model Evaluation
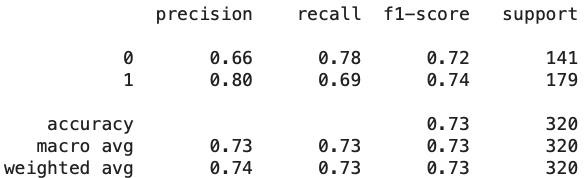
print(classification_report(y_test, y_pred))
Kita mengevaluasi performa model menggunakan classification_report yang memberikan metrik seperti precision, recall, dan f1-score untuk setiap kelas.
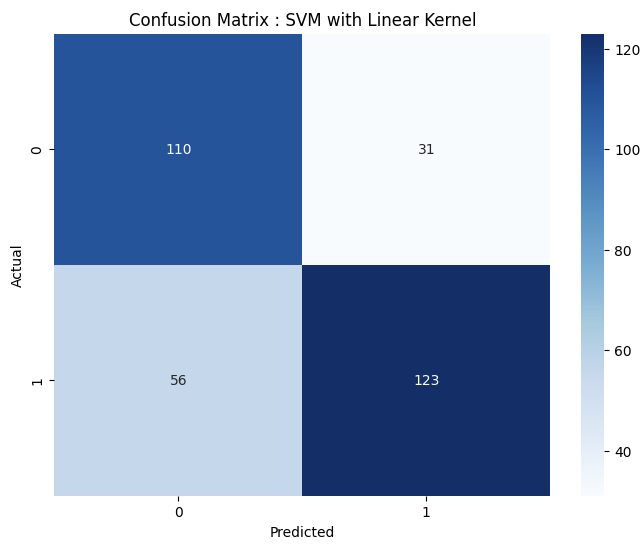
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix(y_test, y_pred), annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
Kita juga menampilkan confusion matrix untuk melihat jumlah prediksi benar dan salah untuk setiap kelas.
Tambahan : Menggunakan Kernel RBF
Jika pada percobaan sebelumnya kita menggunakan kernel linear, sekarang mari kita coba membuat model svm menggunakan kernel rbf. gamma='auto' berarti bahwa parameter gamma akan diatur ke nilai default.
svm_model_rbf = SVC(kernel='rbf', gamma='auto')
svm_model_rbf.fit(X_train, y_train)
y_pred_rbf = svm_model_rbf.predict(X_test)
# Evaluasi performa model RBF
print(classification_report(y_test, y_pred_rbf))
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix(y_test, y_pred_rbf), annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
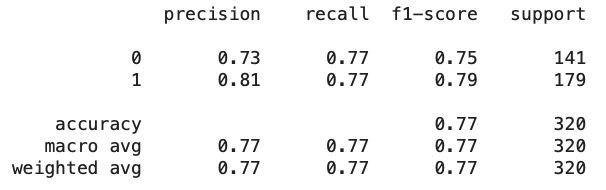
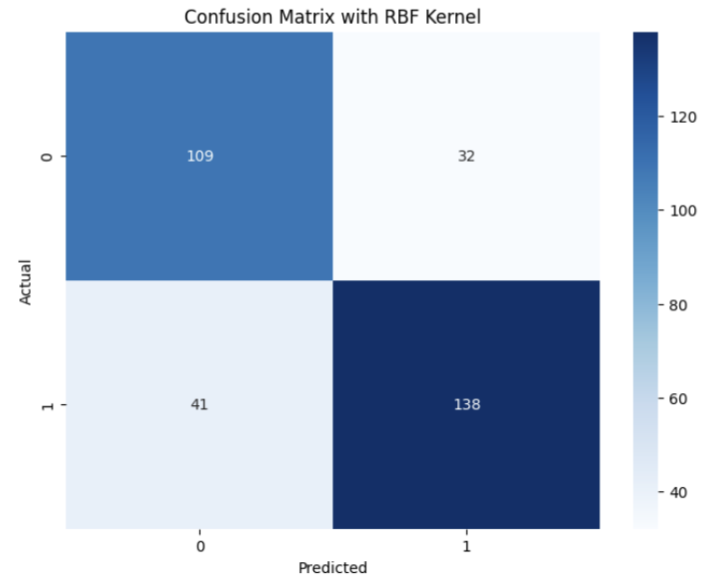
Dari hasli yang didapatkan dapat dilihat bahwa hasil klasifikasi yang menggunakan kernel RBF mendapatkan hasil yang lebih baik dibandingkan dengan menggunakan kernel Linear.
Kesimpulan
Dalam artikel ini, kita membahas konsep dasar Support Vector Machine (SVM) dan mengimplementasikannya pada dataset Wine Quality untuk klasifikasi kualitas anggur. Hasil evaluasi menunjukkan bahwa SVM dengan kernel RBF memberikan performa lebih baik dengan akurasi 77% dibandingkan kernel linear dengan akurasi 73%. Visualisasi seperti distribusi kualitas anggur, heatmap korelasi fitur, dan boxplot distribusi fitur utama membantu memahami karakteristik data. Secara keseluruhan, SVM adalah algoritma yang kuat untuk tugas klasifikasi, terutama saat data tidak dapat dipisahkan secara linear. Selain itu, perbedaan hasil antara model yang menggunakan kernel RBF dengan linear menggambarkan pentingnya untuk melakukan tuning terhadap parameter-parameter yang ada di dalam model. Terima kasih sudah membaca artikel ini. Semoga bermanfaat dan selamat belajar!
Source Code : Kaggle
Subscribe to my newsletter
Read articles from Muhammad Ihsan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Muhammad Ihsan
Muhammad Ihsan
AI, ML and DL Enthusiast. https://www.upwork.com/freelancers/emhaihsan https://github.com/emhaihsan https://linkedin.com/in/emhaihsan