How to Master Decision Trees for Machine Learning Classification
 Sujit Nirmal
Sujit Nirmal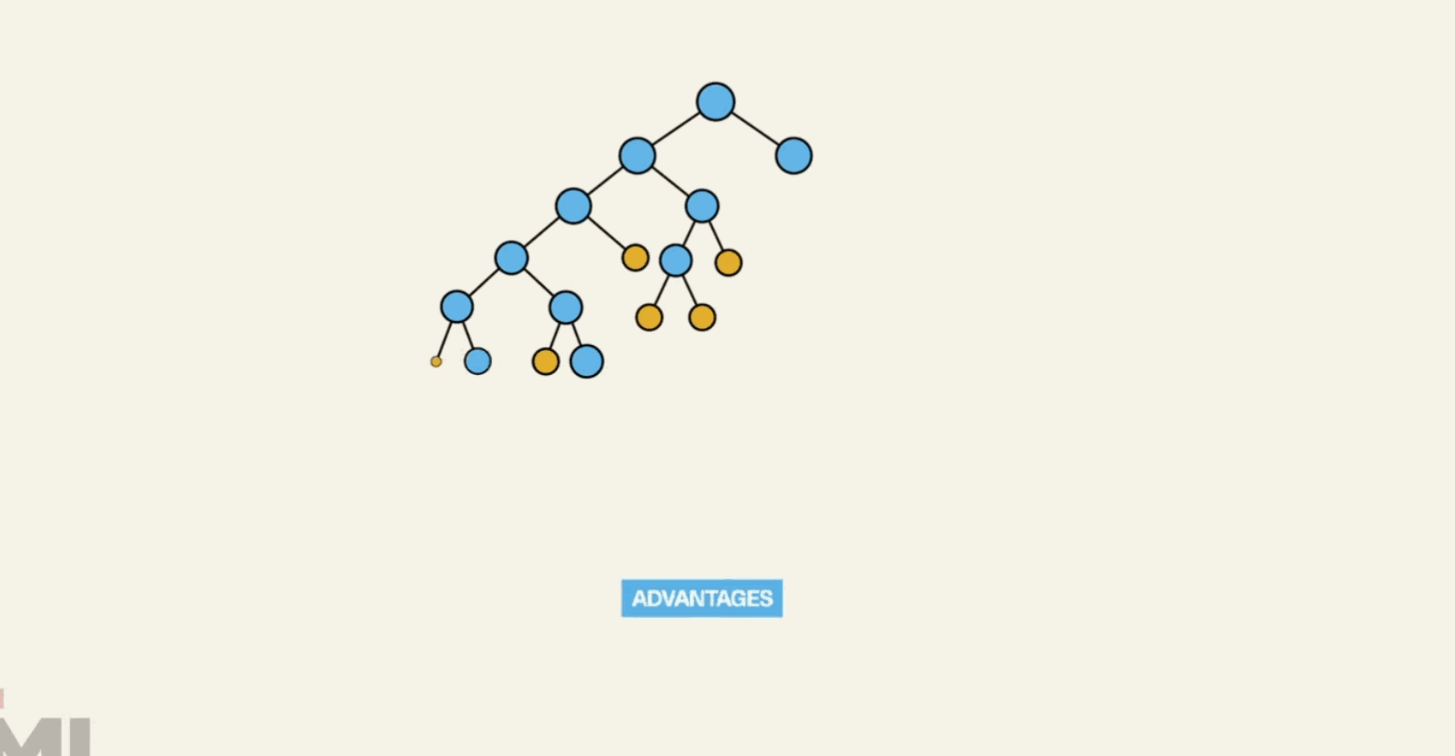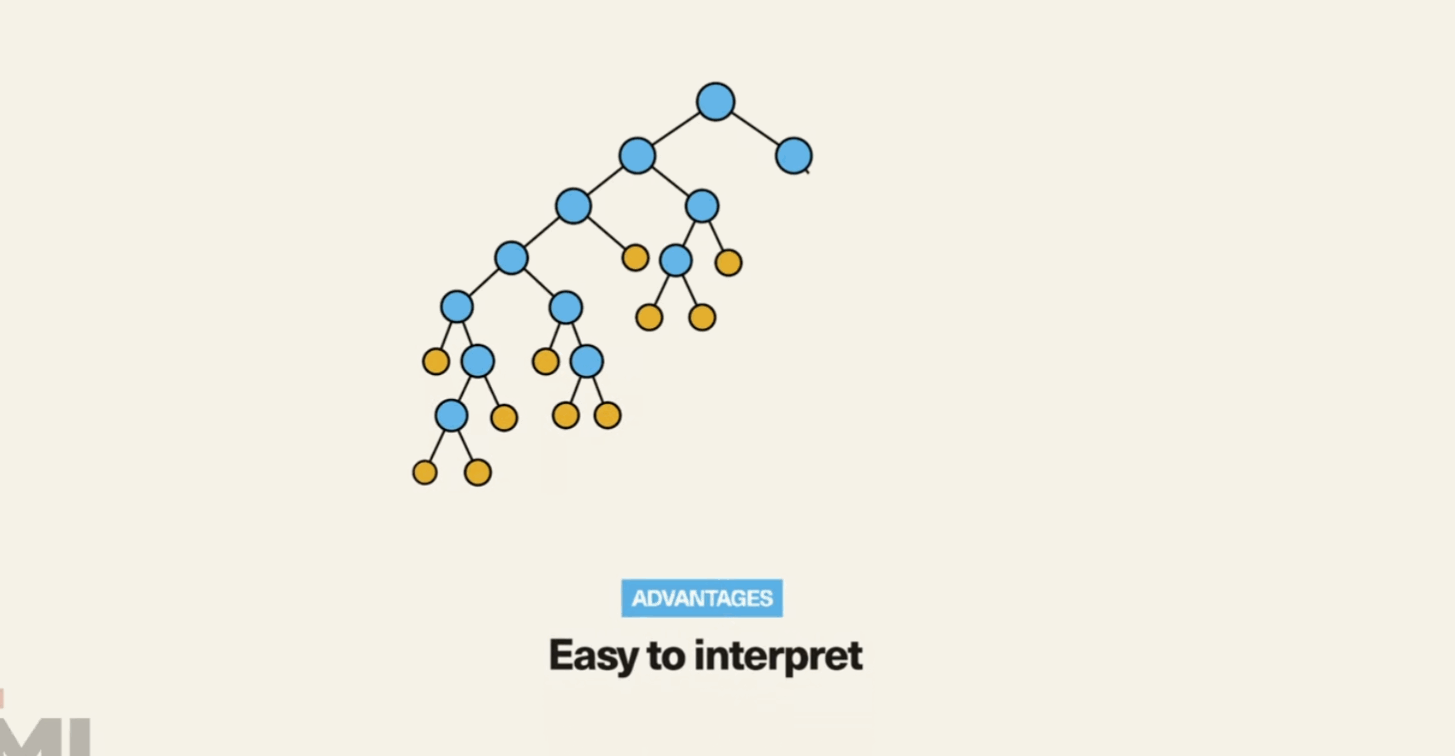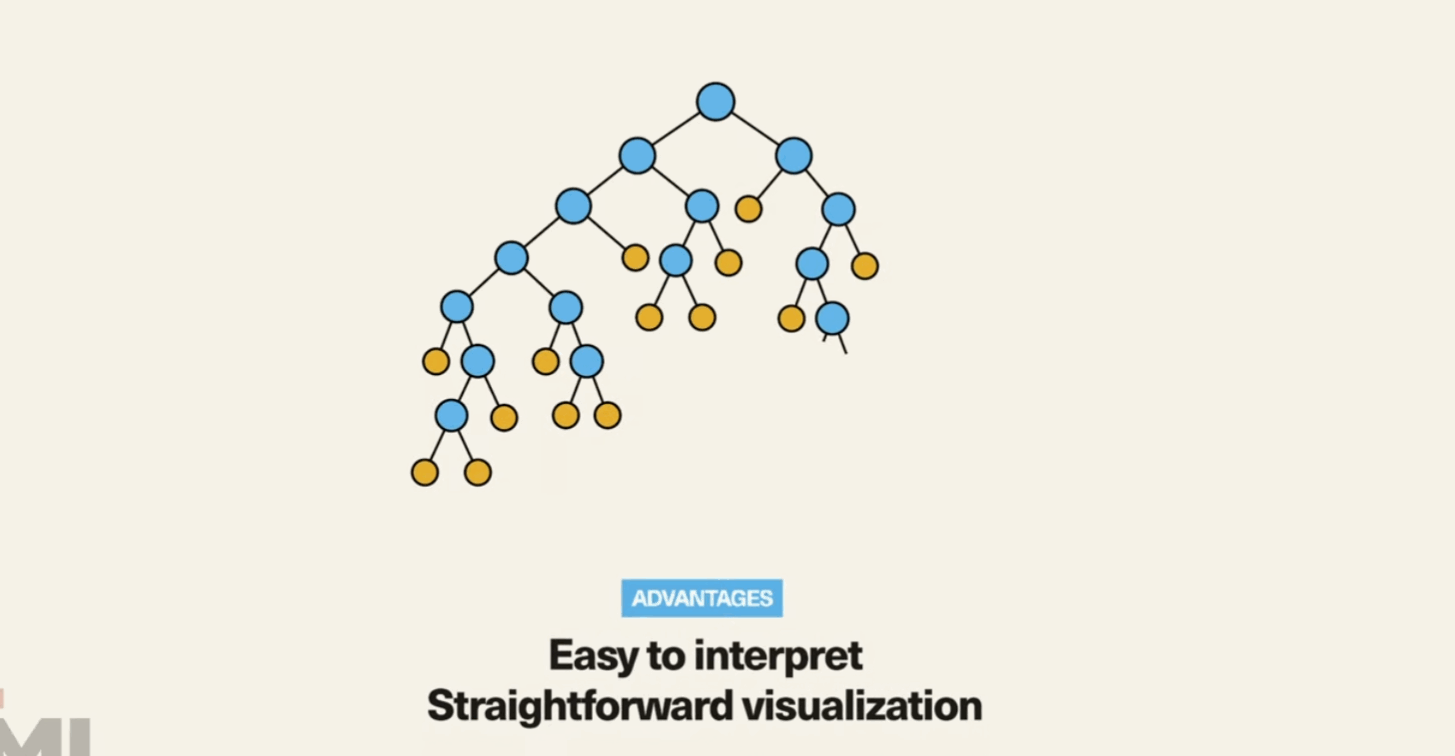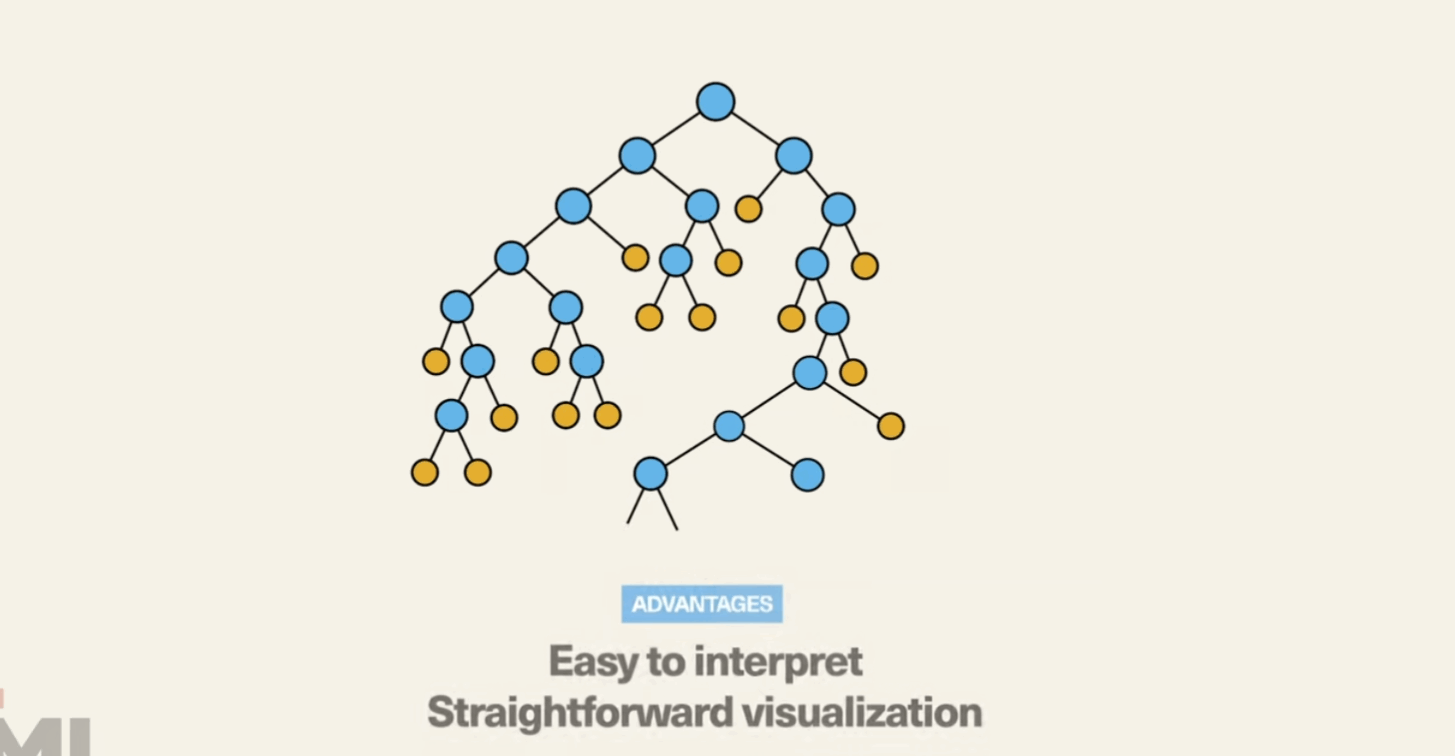
Topic: Decision Trees for Classification
Blog Content:
Introduction
Welcome back to our journey through the fascinating world of Machine Learning! In our previous blogs, we covered the basics of Machine Learning and delved into Linear Regression. Today, we will explore another fundamental
concept:
Decision Trees for Classification. This blog will provide you with a comprehensive understanding of Decision Trees, complete with code snippets, video links, and additional resources to enhance your learning experience.
What is a Decision Tree?
A Decision Tree is a powerful and intuitive model used for both classification and regression tasks. It works by splitting the data into subsets based on the value of input features, creating a tree-like structure of decisions. Each internal node represents a "decision" on an attribute, each branch represents the outcome of the decision, and each leaf node represents a class label (in classification) or a continuous value (in regression).
Why Use Decision Trees?
Simplicity and Interpretability: Decision Trees are easy to understand and interpret. They mimic human decision-making processes, making them highly intuitive.
Versatility: They can handle both numerical and categorical data.
Non-Parametric: They do not assume any underlying distribution of the data.
Building a Decision Tree Classifier
Let's dive into building a Decision Tree classifier using Python and the scikit-learn library.
Step 1: Import Libraries
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
import matplotlib.pyplot as plt
from sklearn import tree
Step 2: Load the Dataset
For this example, we will use the famous Iris dataset.
iris = load_iris()
X, y = iris.data, iris.target
Step 3: Split the Data
We split the data into training and testing sets to evaluate the model's performance.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Train the Decision Tree Classifier
clf = DecisionTreeClassifier(random_state=42)
clf.fit(X_train, y_train)
Step 5: Evaluate the Model
y_pred = clf.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
Step 6: Visualize the Decision Tree
plt.figure(figsize=(20,10))
tree.plot_tree(clf, filled=True, feature_names=iris.feature_names, class_names=iris.target_names)
plt.show()
Code Snippets and Resources
Confusion Matrix:Confusion Matrix in Python
ROC Curve:ROC Curve in Python
MinMaxScaler:MinMaxScaler in Python
Video Tutorials
Additional Reading
Conclusion
Decision Trees are a fundamental tool in the Machine Learning toolkit. They are easy to understand, interpret, and implement. By following the steps outlined in this blog, you should now have a solid understanding of how to build and evaluate a Decision Tree classifier. Stay tuned for our next blog, where we will explore more advanced topics in Machine Learning!
Happy Coding !!
Happy Learning !!
Subscribe to my newsletter
Read articles from Sujit Nirmal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sujit Nirmal
Sujit Nirmal
👋 Hi there! I'm Sujit Nirmal, a AI /ML Developer with a passion for creating intelligent, seamless ML applications. With a strong foundation in both machine learning and Deep Learning I thrive at the intersection of data and technology.