The Ultimate Kubernetes Guide: Everything You Need To Know
 Darshan Atkari
Darshan Atkari
Kubernetes (K8s)
Kubernetes, often abbreviated as K8s, is an open-source platform designed for automating the deployment, scaling, and management of containerized applications. It allows you to manage your applications more efficiently and effectively, ensuring that they run consistently regardless of the environment.
What Kubernetes Can Do
Service Discovery and Load Balancing:
Kubernetes can automatically expose a container using the DNS name or its own IP address. If traffic to a container is high, Kubernetes can load balance and distribute the network traffic so that the deployment is stable.Storage Orchestration:
Kubernetes allows you to automatically mount the storage system of your choice, whether from local storage, a public cloud provider, or a shared network storage system.Local or Cloud-Based Deployments:
Kubernetes can be run in various environments, whether on-premises, in the cloud, or both. It offers a flexible and hybrid approach to managing workloads.Automated Rollouts and Rollbacks:
Kubernetes progressively rolls out changes to your application or its configuration, monitoring the health of the application and ensuring that all instances do not go down simultaneously. If something goes wrong, Kubernetes can roll back the change for you.Self-Healing:
Kubernetes automatically replaces and reschedules containers from failed nodes. It kills containers that don’t respond to user-defined health checks and doesn’t advertise them to clients until they are ready to serve.Secret and Configuration Management:
Kubernetes lets you store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys. You can deploy and update secrets and application configuration without rebuilding your image and without exposing secrets in your stack configuration.Consistent API Across Environments:
Kubernetes provides a consistent set of APIs regardless of where it is run, whether on-premises or in any cloud provider, ensuring consistency and reliability in managing workloads.
What Kubernetes Can't Do
Does Not Deploy Source Code:
Kubernetes does not handle the deployment of source code. It assumes that you have already built your application into a container image.Does Not Build Your Application:
The process of building your application is separate from Kubernetes. It does not provide tools for building your application into a container image.Does Not Provide Application-Level Services:
Kubernetes does not offer built-in application-level services such as message buses, databases, or caches. These services must be provided by third-party tools or software.
Cloud Orchestration
Kubernetes excels in cloud orchestration by managing and automating the lifecycle of containerized applications in various cloud environments. It provides a consistent platform for deploying, scaling, and operating applications in the cloud.
Use Case
To illustrate the capabilities of Kubernetes, consider a scenario where you have a microservices-based application that needs to be deployed across multiple cloud providers. Kubernetes allows you to:
Deploy the application consistently across different cloud providers using the same API and management tools.
Automatically scale up or down based on traffic loads, ensuring optimal performance and cost efficiency.
Ensure high availability and reliability with self-healing capabilities that automatically restart failed containers and reschedule them on healthy nodes.
Manage secrets and configurations securely, enabling seamless updates without exposing sensitive information.
Perform rolling updates and rollbacks to deploy new features without downtime and revert if something goes wrong.
Configuration Storage
Kubernetes configuration is stored locally on your system, which allows kubectl to connect to the Kubernetes cluster. The configuration files are typically located in:
Linux/Mac:
${HOME}/.kube/configWindows:
C:\Users\{USER}\.kube\config
Kubernetes Context
A context in Kubernetes is a group of access parameters to a Kubernetes cluster. It includes:
Kubernetes Cluster: The cluster to which you are connecting.
User: The user account that you are using to access the cluster.
Namespace: The namespace within the cluster.
The current context is the default cluster for kubectl commands.
Context Commands:
Get the Current Context:
kubectl config current-contextList All Contexts:
kubectl config get-contextsSet the Current Context:
kubectl config use-context [contextName]Delete a Context from the Config File:
kubectl config delete-context [contextName]
Quickly Switching Contexts with kubectx
kubectx is a tool for quickly switching between Kubernetes contexts.
Instead of Typing:
kubectl config use-context [contextName]Simply Type:
kubectx [contextName]
Installation:
Windows:
choco install kubectx-psmacOS:
brew install kubectxUbuntu:
sudo apt install kubectx
Architecture
When you deploy Kubernetes, you get a cluster composed of two important parts: the Master (Control Plane) and the Worker Nodes.
Nodes (Minions): Nodes are the servers, which can be physical or virtual machines.
Master Nodes: The Master Node, also known as the Control Plane, is the brain of a Kubernetes cluster. It manages the entire cluster, maintaining the desired state, and ensuring the cluster operates as expected.
Worker Nodes: Worker Nodes are the servers (physical or virtual) that run the actual applications and workloads. Each Worker Node has several critical components to execute these tasks.
The diagram below illustrates this architecture:
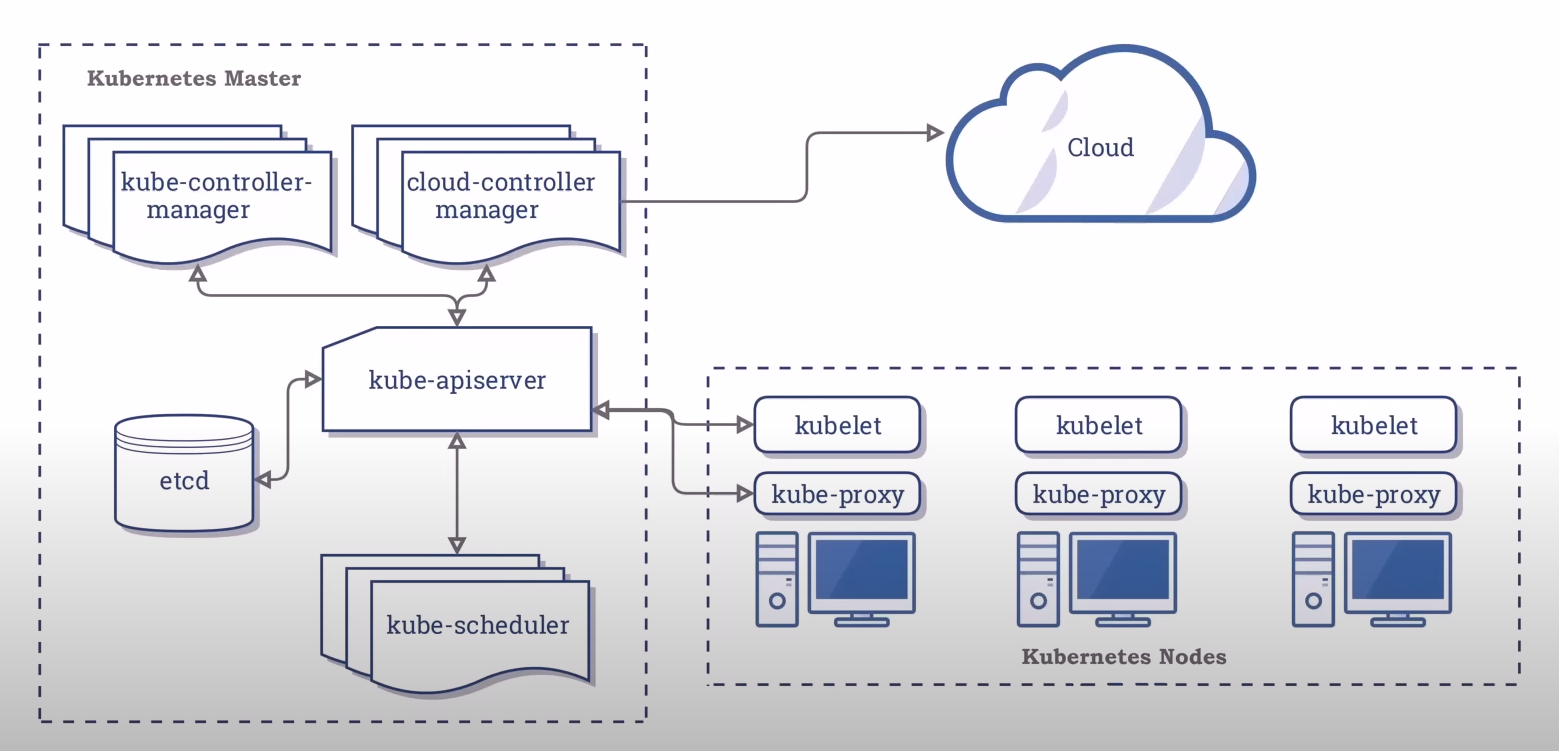
Master Node Components
API Server:
The API Server is the only component that communicates with etcd.
kube-apiserver:
Provides a REST interface.
Saves the state to the datastore (etcd).
All clients interact with it, never directly with the datastore.
etcd:
etcd acts as the cluster datastore for storing the state.
Acts as the cluster datastore for storing the state.
It is a key-value store.
It is not a database or a datastore for applications to use.
Serves as the single source of truth.
Control Manager:
The Control Manager is responsible for managing the state of the cluster.
kube-controller-manager:
The controller of controllers.
Runs various controllers, including:
Node controller.
Replication controller.
Endpoints controller.
Service account & Token controllers.
cloud-controller-manager:
Interacts with cloud provider controllers.
Node: Checks the cloud provider to determine if a node has been deleted in the cloud after it stops responding.
Route: Sets up routes in the underlying cloud infrastructure.
Service: Manages creating, updating, and deleting cloud provider load balancers.
Volume: Handles creating, attaching, and mounting volumes, and interacts with the cloud provider to orchestrate volumes.
Scheduler:
kube-scheduler:
Watches newly created pods that have no node assigned and selects a node for them to run on.
Factors taken into account for scheduling decisions include:
Individual and collective resource requirements.
Hardware/software/policy constraints.
Affinity and anti-affinity specifications.
Data locality.
Addons
Kubernetes supports various add-ons to enhance functionality:
DNS
Web UI (dashboard)
Cluster-level logging
Container resource monitoring
Worker Node Components
Kubelet:
The Kubelet is an agent that ensures containers are running in pods.
kubelet:
Manages the lifecycle of pods.
Ensures that the containers described in the Pod specs are running and healthy.
Kube-Proxy:
Kube-Proxy maintains network rules for communication with pods.
kube-proxy:
Acts as a network proxy.
Manages network rules on nodes.
Container Runtime:
The Container Runtime is a tool responsible for running containers.
Kubernetes supports several container runtimes, which must implement the Kubernetes Container Runtime Interface:
Moby
Containerd
Cri-O
Rkt
Kata
Virtlet
Node Pool:
A node pool is a group of virtual machines, all with the same size.
A cluster can have multiple node pools.
These pools can host different sizes of VMs.
Each pool can be autoscaled independently of the other pools.
Docker Desktop is limited to one node.
Get Nodes Information
Get a list of all the installed nodes. Using Docker Desktop, there should be only one:
kubectl get node
Get some info about the node:
kubectl describe node [node_name]
The Declarative Way vs. The Imperative Way
Kubernetes provides two primary methods for managing resources: imperative and declarative. Understanding the differences between these approaches is essential for effective Kubernetes management.
Imperative Method
Description:
Uses
kubectlcommands directly to perform actions on Kubernetes resources.Suitable for learning, testing, and troubleshooting purposes.
Similar to writing commands in a shell or scripting environment.
Basic Commands for Imperative Management:
# Create a Deployment imperatively kubectl create deployment [myImage] --image=[imageName] # List Deployments kubectl get deployments # Describe a specific Deployment kubectl describe deployment [deploymentName] # Delete a Deployment kubectl delete deployment [deploymentName]Example Series of Commands:
# Create a Pod kubectl run mynginx --image=nginx --port=80 # Create a Deployment kubectl create deployment mynginx --image=nginx --port=80 --replicas=3 # List Deployments kubectl get deployments # Describe a specific Pod kubectl describe pod mynginx # Describe a specific Deployment kubectl describe deployment mynginx # Delete a Deployment kubectl delete deployment mynginx
Declarative Method
Description:
Uses
kubectlwith YAML manifest files to define and manage Kubernetes resources.Promotes reproducibility and consistency across environments.
YAML files can be version controlled and shared among teams.
Defines the desired state of resources, allowing Kubernetes to manage the actual state.
Example YAML File: Pod Definition
apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app: myapp type: front-end spec: containers: - name: nginx-container image: nginxBasic Commands for Declarative Management:
# Create or apply a Kubernetes object using a YAML file kubectl apply -f [YAML file] # Example: Create a Deployment declaratively kubectl apply -f deployment.yaml # Get a list of all Deployments kubectl get deployments # Describe a specific Deployment kubectl describe deployment [deploymentName] # Delete a Kubernetes object defined in a YAML file kubectl delete -f [YAML file] # Example: Delete a Deployment declaratively kubectl delete -f deployment.yaml
POD
A Pod is a single instance of a running process in a Kubernetes cluster. It can run one or more containers and share the same resources.
Atomic Unit: The smallest unit of work in Kubernetes.
Encapsulates an Application's Container: Represents a unit of deployment.
Multiple Containers: Pods can run one or multiple containers.
Shared Resources: Containers within a pod share:
IP address
Space
Mounted volumes
Communication: Containers within a pod can communicate via:
IPC
Characteristics of Pods
Ephemeral: Pods are temporary.
Atomic Deployment: Deploying a pod is an atomic operation; it either succeeds or fails.
Pod Failure: If a pod fails, it is replaced with a new one with a new IP address.
Updates: You don't update a pod; you replace it with an updated version.
Scaling: You scale by adding more pods, not more containers within a pod.
POD Life Cycle:
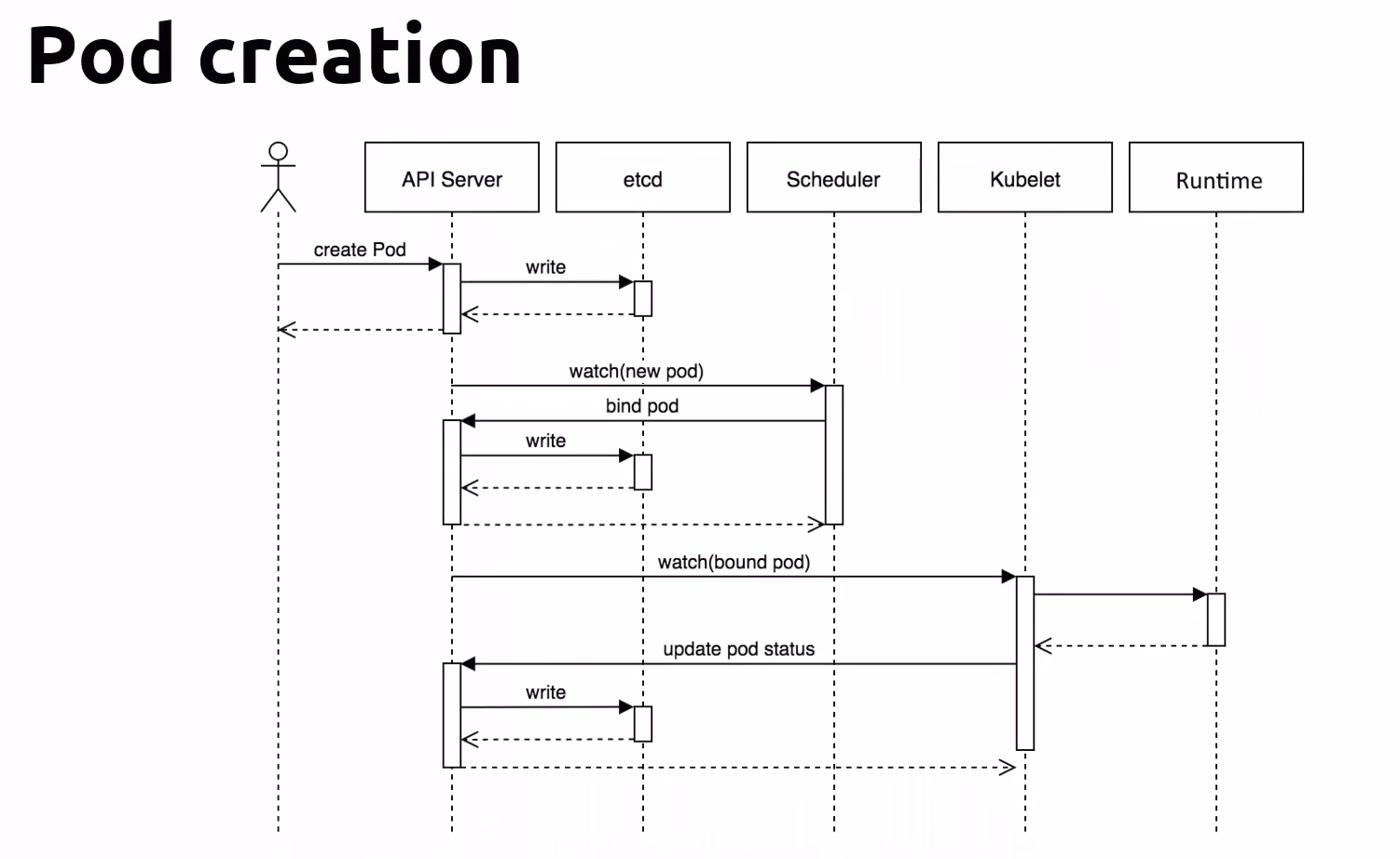
Create Pod Request
User Initiates Pod Creation
- User: Initiates the pod creation by sending a create Pod request to the API Server.
API Server Writes to etcd
- API Server: Receives the request and writes the pod specification to etcd, which is the distributed key-value store used by Kubernetes for storing all cluster data.
Scheduler Watches for New Pods
- Scheduler: Watches for new pods in etcd. When it detects a new pod that needs scheduling, it selects a node for the pod based on the current scheduling policy and available resources.
Scheduler Binds the Pod
- Scheduler: Binds the pod to a node by writing the binding information back to etcd.
Kubelet Watches for Bound Pods
- Kubelet: On the designated node, watches for pods that have been bound to it. When it detects the pod, it starts the process of setting up the pod.
Kubelet Updates Pod Status
- Kubelet: Updates the status of the pod to the API Server to reflect that it has started creating the containers defined in the pod specification.
Runtime Executes the Containers
- Runtime: The container runtime (e.g., Docker, containerd) on the node takes over, pulling the necessary images and starting the containers as specified in the pod definition.
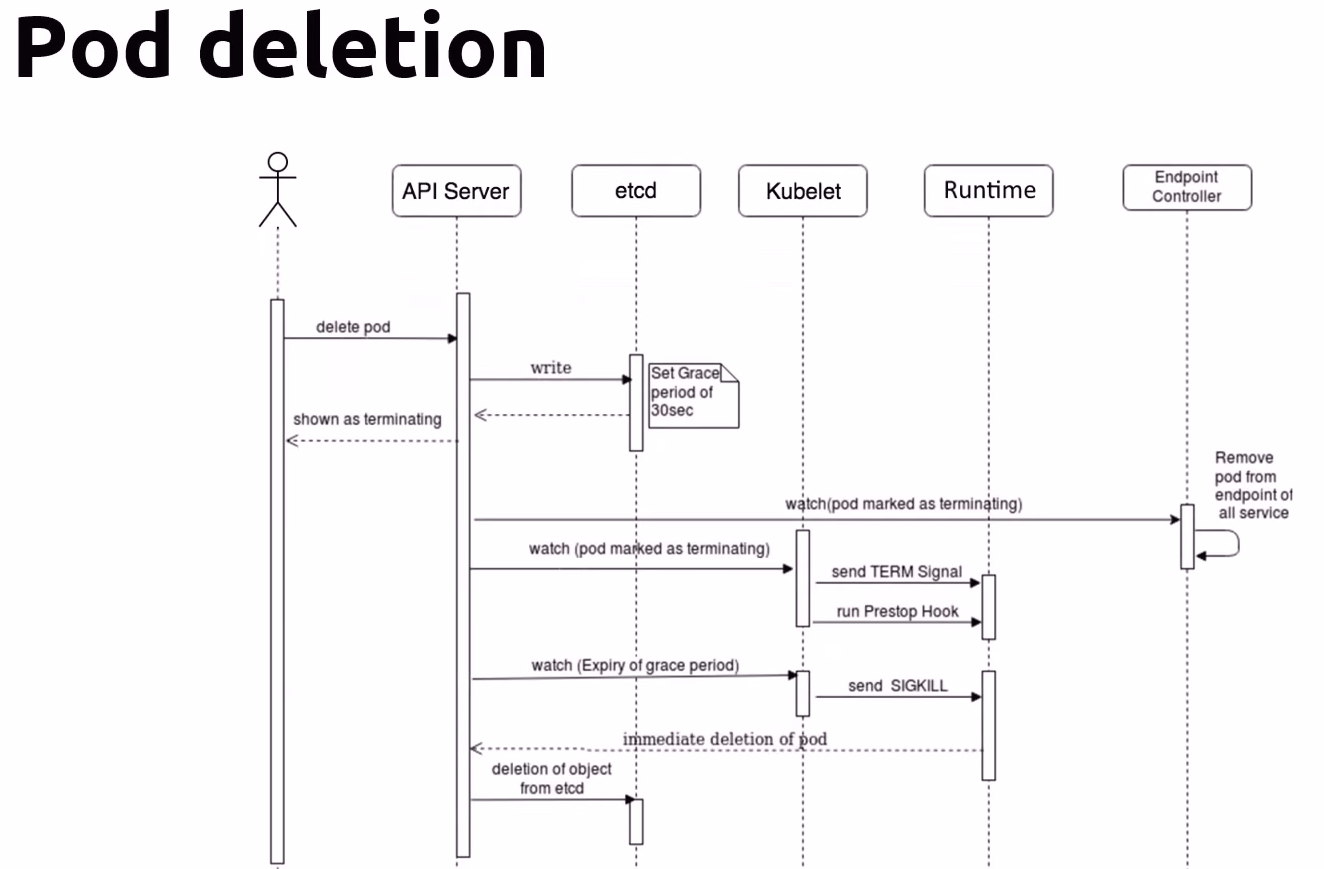
Delete Pod Request
User Initiates Pod Deletion
- User: Initiates the pod deletion by sending a delete pod request to the API Server.
API Server Marks Pod for Deletion
- API Server: Receives the delete request and marks the pod as terminating. It writes this state to etcd.
etcd Updates with Grace Period
- etcd: The API server sets a grace period (default is 30 seconds) for the pod deletion. This grace period allows the containers to gracefully shut down.
Kubelet Watches for Terminating Pods
- Kubelet: On the node where the pod is running, the kubelet watches for pods marked as terminating. When it detects such a pod, it takes action to start the termination process.
Termination Signal and PreStop Hook
- Kubelet: Sends a TERM signal to the pod’s containers to start graceful termination. If a preStop hook is defined, it executes this hook to allow any cleanup tasks to be performed.
Endpoint Controller Updates
- Endpoint Controller: Removes the pod from the endpoints of all services to which it was associated, ensuring that no new traffic is routed to the terminating pod.
Grace Period Expiry
- Kubelet: Watches for the expiry of the grace period. If the containers have not terminated within the grace period, it proceeds to forcefully terminate them.
Forced Termination
- Kubelet: Sends a SIGKILL signal to the containers if they have not terminated after the grace period expires, ensuring they are forcibly stopped.
Pod Deletion from etcd
- etcd: The pod object is immediately deleted from etcd, removing all traces of the pod from the cluster's state.
Pod State
Pending
- Accepted but not yet created.
Running
- Bound to a node.
Succeeded
- Exited with status 0.
Failed
- All containers exited, and at least one exited with a non-zero status.
Unknown
- Communication issues with the pod.
CrashLoopBackOff
- Started, crashed, started again, and then crashed again.
Defining and Running Pods
YAML File
apiVersion: v1
kind: Pod # ---> Pod
metadata:
name: myapp-pod
labels:
app: myapp
type: front-end
spec:
containers:
- name: nginx-container
image: nginx
ports:
- containerPort: 80
name: http
protocol: TCP
env:
- name: DBCON
value: connectionstring
command: ["/bin/sh", "-c"]
args: ["echo ${DBCON}"]
kubectl - Pod Cheat Sheet
Create a pod (Declarative Way)
kubectl create -f [pod-definition.yml]Run a pod (Imperative Way)
kubectl run my-nginx --image=nginxRun a pod and open a session inside the running pod
kubectl run [podname] --image=busybox -- /bin/sh -c "sleep 3600"kubectl run [podname] --image=busybox -it -- /bin/sh # exit // to exit the sessionResume the session
kubectl attach [podname] -c [podname] -i -tInteractive mode, open a session to a currently running pod
kubectl exec -it [podname] -- shList the running pods
kubectl get podsList the running pods with more information
kubectl get pods -o wideShow pod information
kubectl describe pod [podname]Extract the pod definition in YAML and save it to a file
kubectl get pod [podname] -o yaml > file.yamlDelete a pod using the pod definition file
kubectl delete -f [pod-definition.yml]Delete a pod using the pod's name
kubectl delete pod [podname]To delete the pod immediately
kubectl delete pod [podname] --wait=falsekubectl delete pod [podname] --grace-period=0 --force
Init Containers
Init containers initialize the pod before the application container runs. Inside the pod, the init container runs first to check whether all required services are up and running. Once all init containers succeed, the pod drops the init container and starts the main application container. This helps keep infrastructure code out of the main logic.
Always run to completion.
Each init container must be completed successfully before the next one starts.
If an init container fails, the kubelet repeatedly restarts it until it succeeds, unless its restartPolicy is set to Never.
Probes (livenessProbe, readinessProbe, startupProbe) are not supported.
Example YAML File
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
labels:
app: myapp
spec:
containers:
- name: myapp-container
image: busybox
initContainers:
- name: init-myservice
image: busybox:1.28
command: ['sh', '-c', "until nslookup mysvc.namespace.svc.cluster.local; do echo waiting for myservice; sleep 2; done"]
- name: init-mydb
image: busybox:1.28
command: ['sh', '-c', "until nslookup mysvc.namespace.svc.cluster.local; do echo waiting for mydb; sleep 2; done"]
Selectors:
Labels in Kubernetes are key-value pairs used to identify, describe, and group related sets of objects or resources.
Selectors utilize labels to filter or select objects.
In the image below we are telling Kubernetes to run the pod on a node that has the label "disktype: superfast"
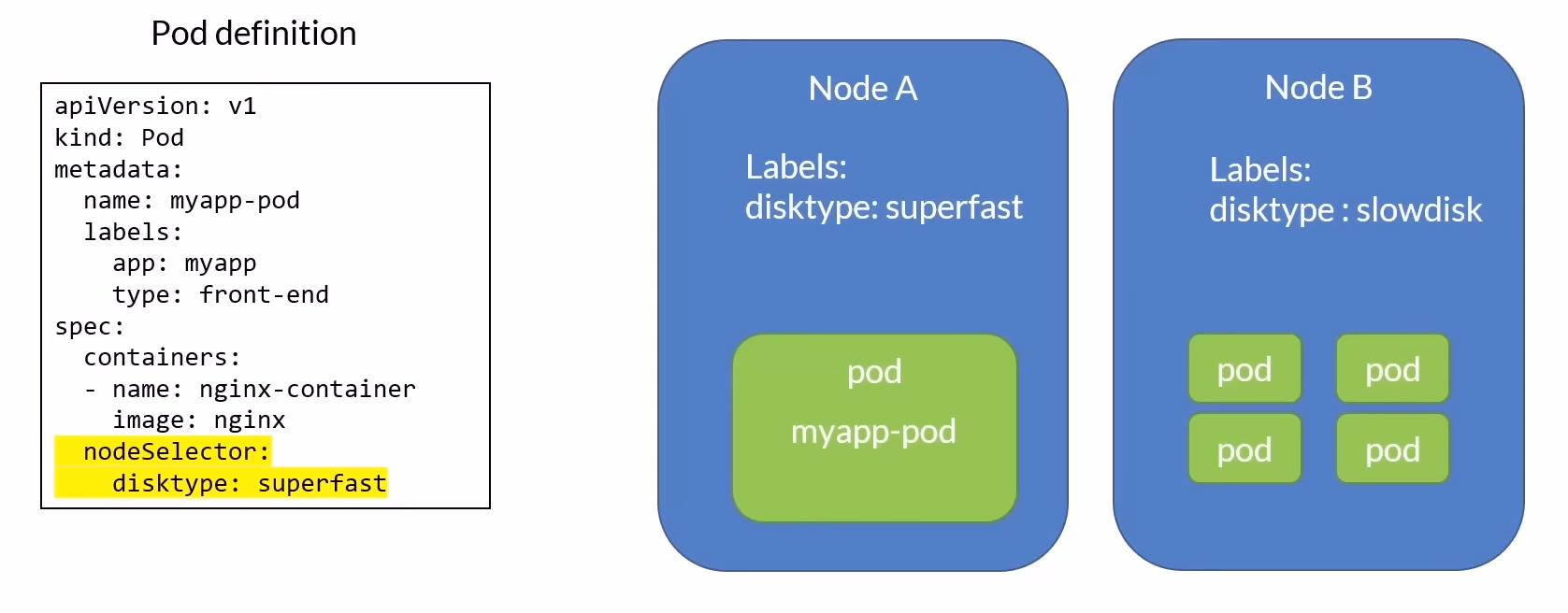
Example: Running a Pod on a Node with a Specific Label
To instruct Kubernetes to run a pod on a node labeled "disktype: superfast":
Check Pod IP Address:
kubectl get po -o wideVerify Service Endpoint: If the service is connected to the pod, the endpoint will point to the pod's IP address. To confirm:
kubectl get ep myserviceEnsure that the IP address listed here matches the one obtained from
kubectl get po.Port Forwarding to the Service: To forward ports from the service
myservice(assuming it listens on port 80) to localhost port 8080:kubectl port-forward service/myservice 8080:80
This setup allows you to access the service running inside Kubernetes locally on your machine.
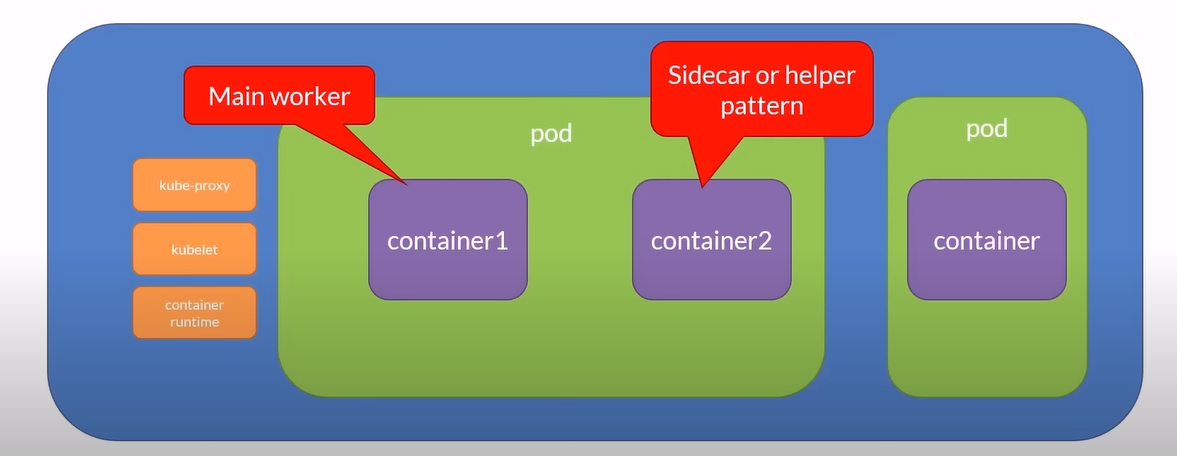
Multi-container Pods
Multi-container pods in Kubernetes are a powerful concept where a single pod can host multiple containers that are tightly coupled and share resources. This setup is particularly useful for scenarios requiring collaboration between different processes or services within the same application context.
Typical Scenarios
The most common use case for multi-container pods involves helper processes that support the main application container. Here’s an overview of typical patterns:
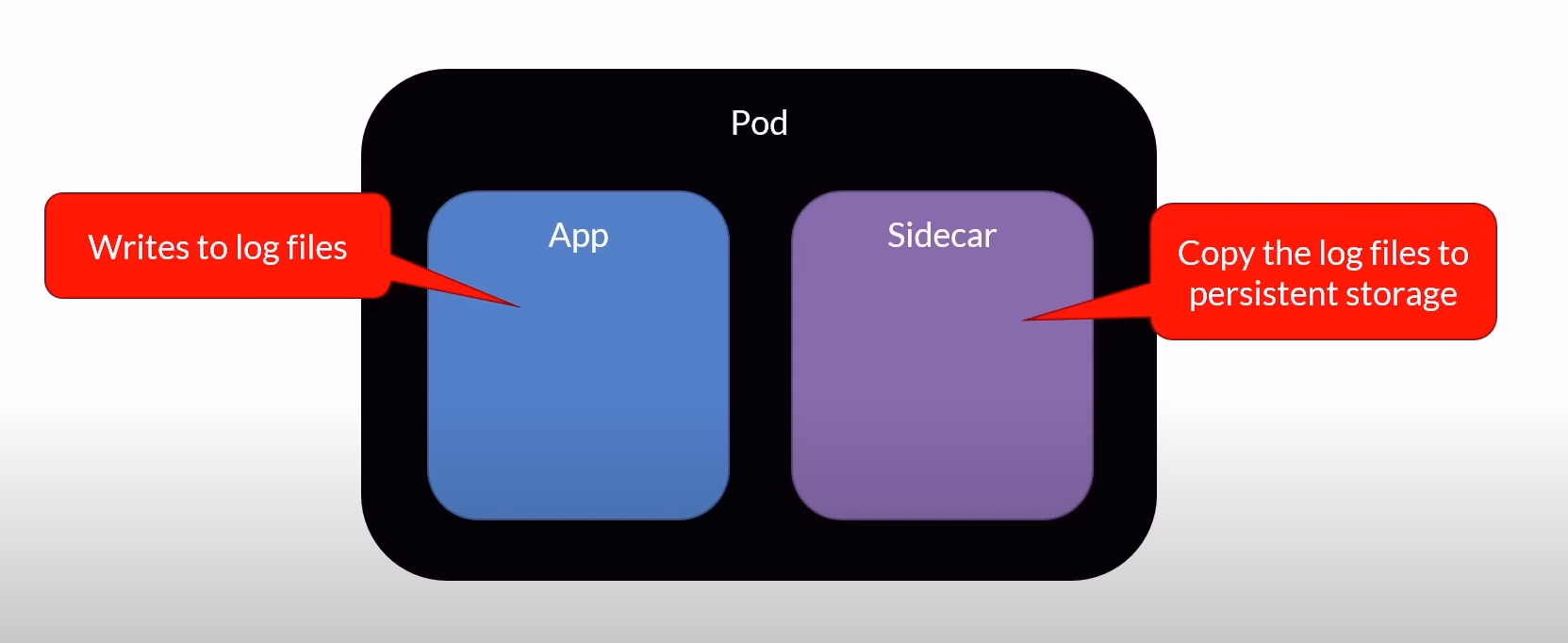
Sidecar Pattern
Description: The sidecar container extends or enhances the functionality of the main application container. It runs alongside the main container and is designed to support its operations.
Use Cases:
Logging or monitoring agents that collect logs and metrics from the main container.
Proxies for managing outbound traffic, such as service mesh sidecars.
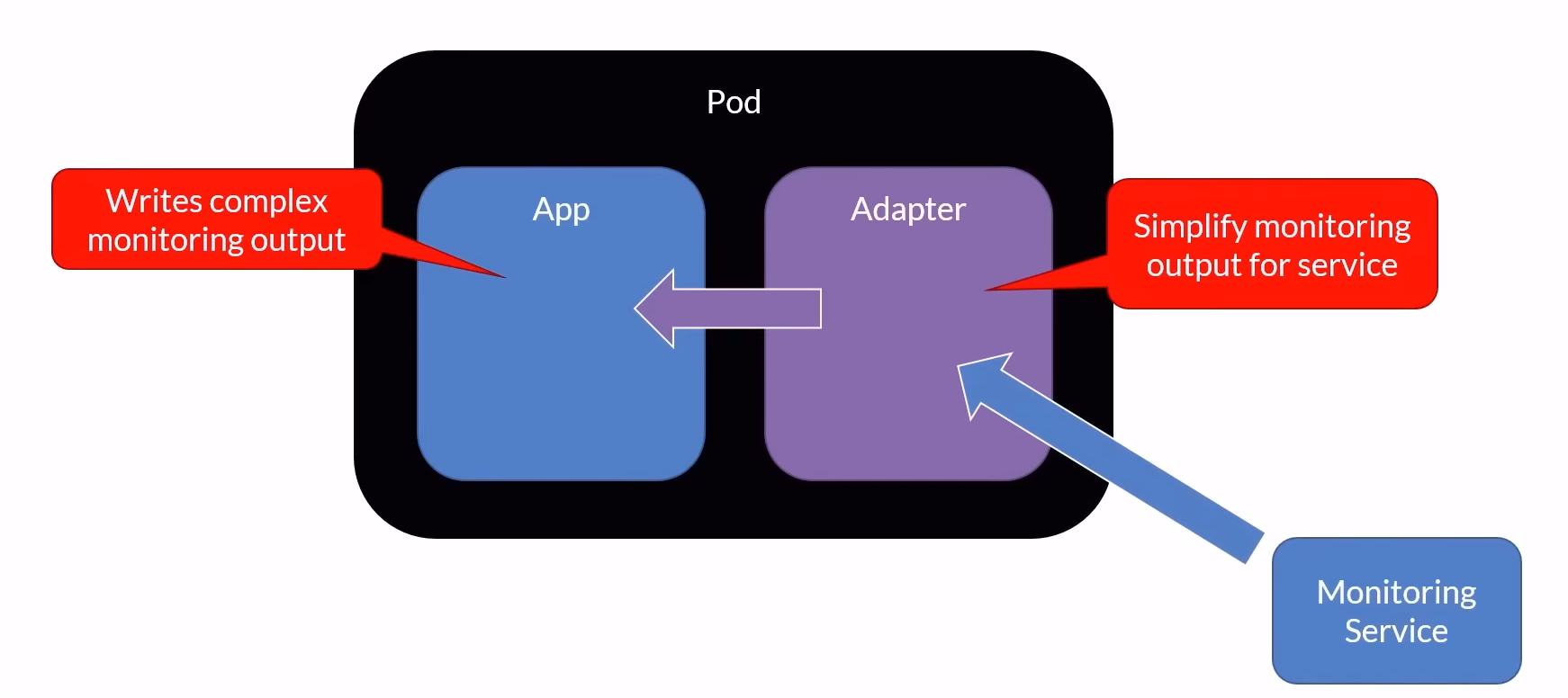
Adapter Pattern
Description: An adapter container standardizes the output of the main application container. It transforms the output into a format that can be easily consumed by other systems or components.
Use Cases:
Converting logs into a specific format.
Transforming data from one format to another for compatibility.
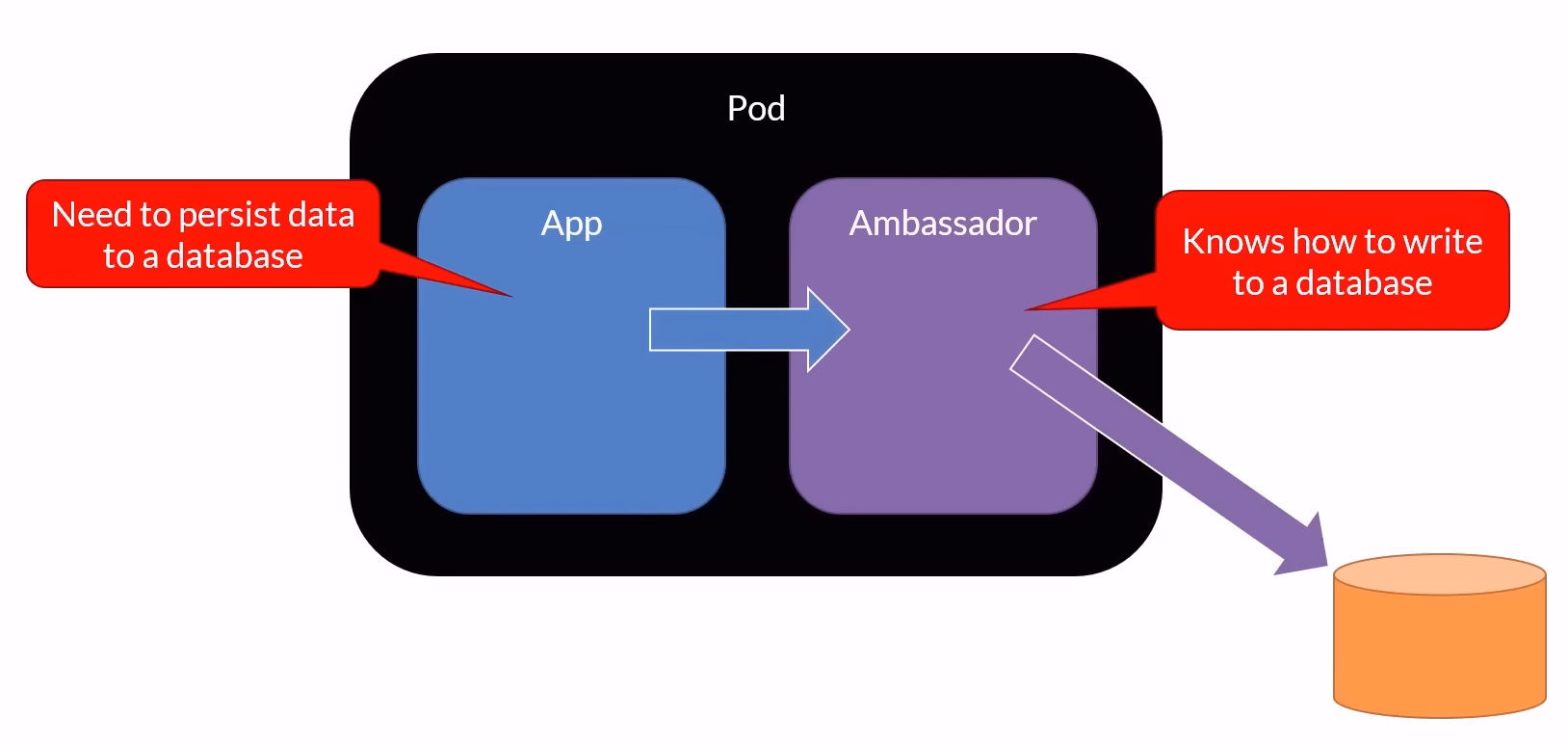
Ambassador Pattern
Description: The ambassador container acts as a proxy facilitating communication between other containers within the pod and the external world. It typically handles network-related tasks.
Use Cases:
Managing outbound connections and routing.
Handling network configurations and policies.
Pod Definition Example
Here's an example of a multi-container pod definition in YAML format:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Always
containers:
- name: mynginx
image: nginx
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
ports:
- containerPort: 80
- name: mybox
image: busybox
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
ports:
- containerPort: 81
command:
- sleep
- "3600"
Commands for Multi-container Pods
Create a Pod:
kubectl create -f [pod-definition.yml]This command creates a pod based on the YAML definition provided.
Execute a Command in a Container:
kubectl exec -it [podname] -c [containername] -- shUse this command to execute an interactive shell (
sh) within a specific container (-c) of a pod ([podname]).Retrieve Container Logs:
kubectl logs [podname] -c [containername]This command retrieves logs from a specific container (
-c) within a pod ([podname]).
In Short
Multi-container pods in Kubernetes offer flexibility and efficiency by allowing containers to work closely together within a shared context. Whether implementing sidecars for enhanced functionality, adapters for data transformation, or ambassadors for network management, leveraging multi-container pods can streamline application architectures and operational workflows in Kubernetes environments.
Networking Concepts in Kubernetes
Key Networking Principles
Pod-to-Pod Communication:
All containers within a pod can communicate with each other using localhost and respective port numbers.
Pods are assigned ephemeral (temporary) IP addresses for internal communication within the cluster.
Inter-Pod Communication:
Pods across the cluster can communicate with each other using their unique IP addresses.
Direct communication between containers in different pods using localhost is not possible; communication requires network routing via services.
Node-to-Pod Communication:
- All nodes in the Kubernetes cluster can communicate with all pods running within the cluster.
Pod Networking:
- Pods are the smallest deployable units in Kubernetes, containing one or more containers that share the same network namespace.
Pod Structure and Networking
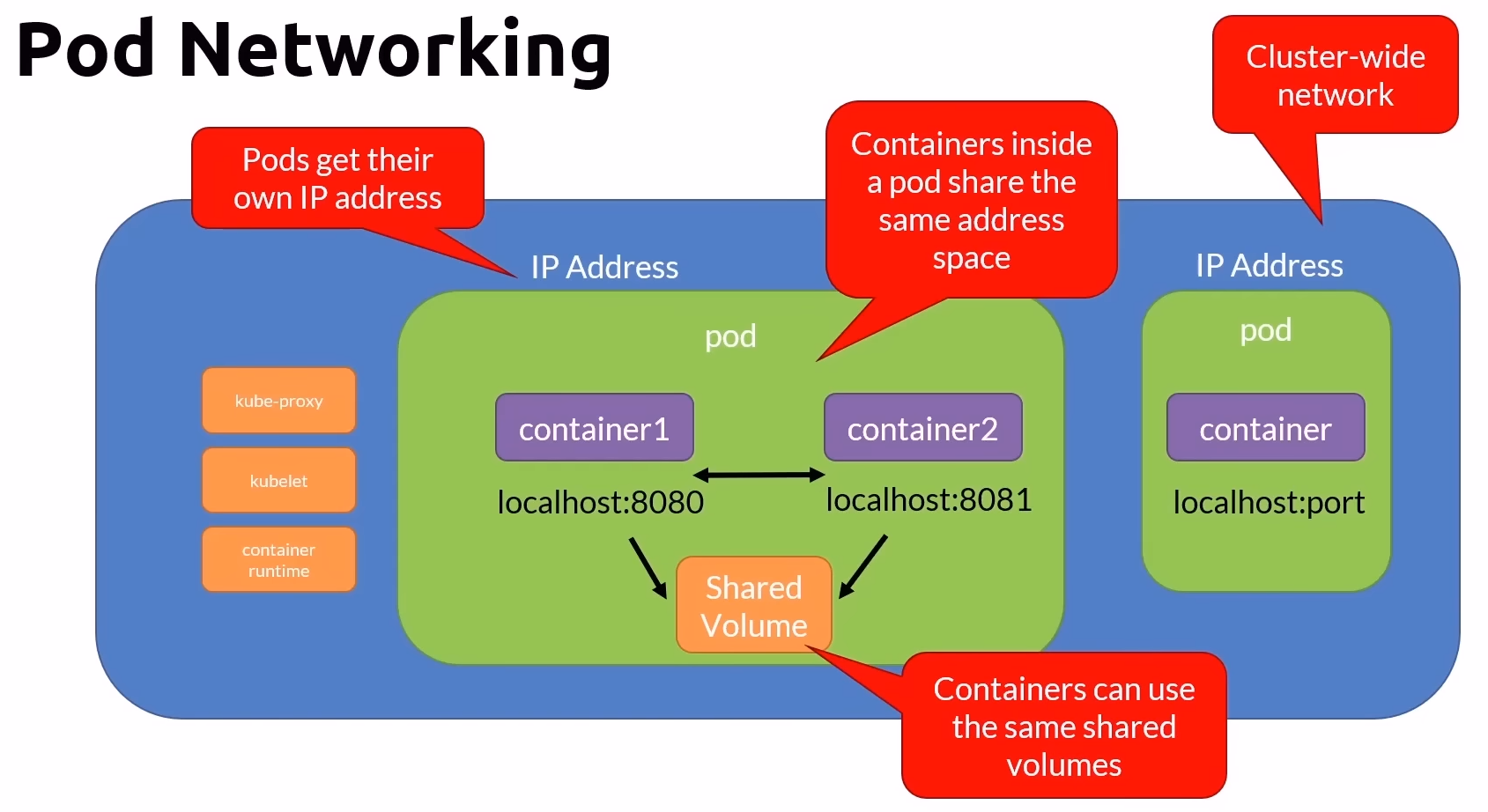
Pod Structure:
Each pod can host multiple containers that share the same IP address and network namespace.
Example: Pod 1 contains container1 and container2, which can communicate with each other using localhost and respective port numbers.
Kubernetes Networking Components
kube-proxy:
- Manages network rules and routing on each node in the Kubernetes cluster.
kubelet:
- Node agent responsible for managing pods and containers on the node, ensuring their health and proper execution.
Container Runtime:
- Software responsible for running containers within pods, such as Docker or containerd.
Inter-Pod Communication
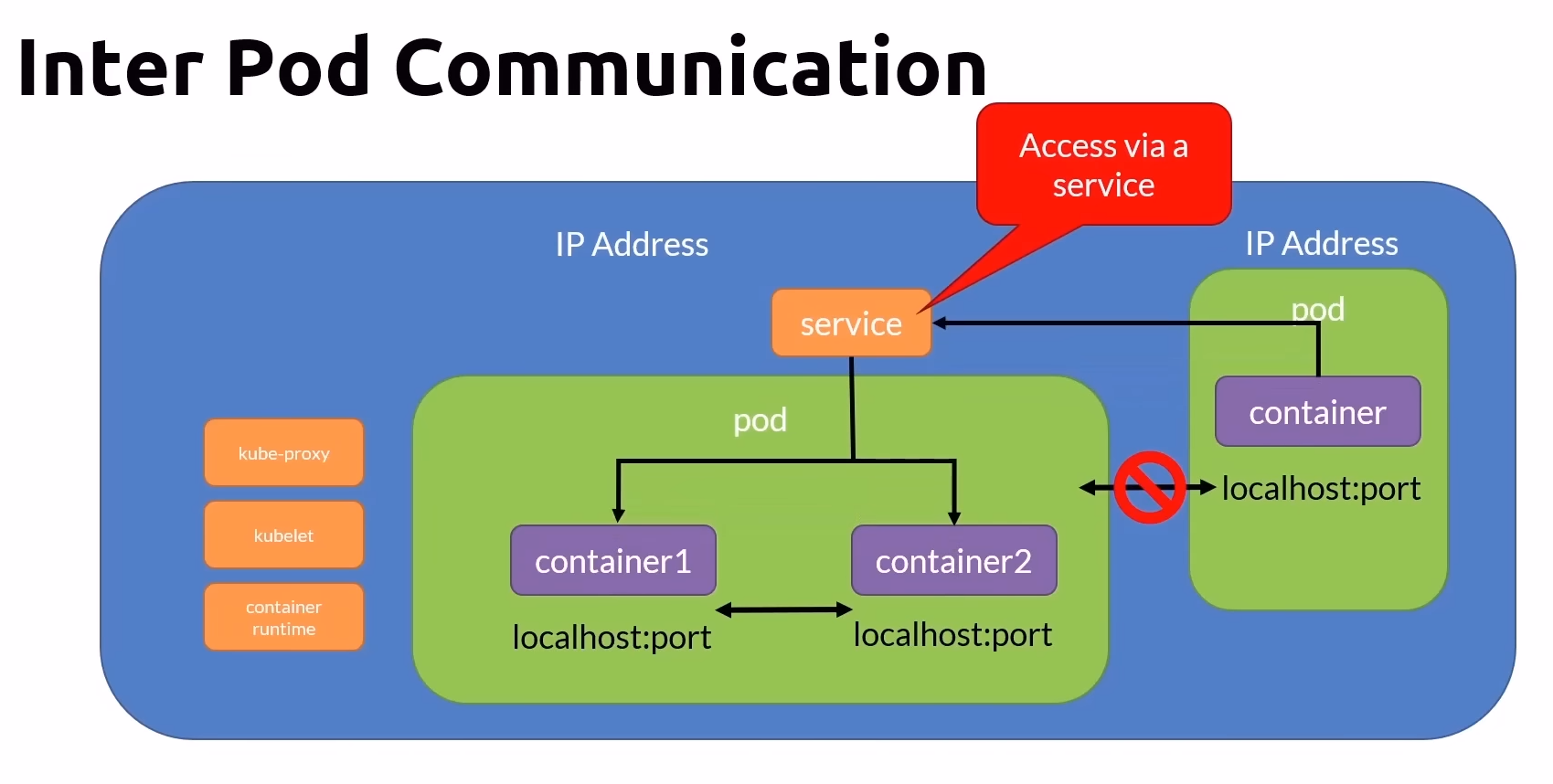
Within a Pod:
- Containers within the same pod communicate directly using localhost and port numbers.
Between Pods:
Direct communication between containers in different pods via localhost is not possible.
Communication between pods is facilitated by Kubernetes services, which assign persistent IP addresses and route traffic to the appropriate pods.
External Access
External Access:
Services in Kubernetes enable external access to applications running inside pods.
Services are assigned persistent IP addresses and manage routing of external traffic to pods based on labels.
Namespaces
Namespaces in Kubernetes provide a way to organize and isolate resources within a cluster.
Grouping Resources:
- Allows logical grouping of resources such as environments (Dev, Test, Prod).
Default Namespace:
- Kubernetes creates a default workspace named
defaultfor resources not assigned to any specific namespace.
- Kubernetes creates a default workspace named
Cross-Namespace Access:
- Objects in one namespace can access objects in another using the format
objectname.namespace.svc.cluster.local.
- Objects in one namespace can access objects in another using the format
Namespace Deletion:
- Deleting a namespace will remove all resources (pods, services, etc.) associated with it.
Namespace Definition
apiVersion: v1
kind: Namespace
metadata:
name: prod # Defines a namespace named 'prod'
Pod Definition in a Namespace
apiVersion: v1
kind: Pod
metadata:
name: myapp-pod
namespace: prod # Specifies that the pod will reside in the 'prod' namespace
spec:
containers:
- name: nginx-container
image: nginx
NetworkPolicy Definition in a Namespace
apiVersion: networking.k8s.io/v1
kind: NetworkPolicy
metadata:
namespace: clientb
name: deny-from-other-namespaces
spec:
podSelector:
matchLabels:
ingress:
- from:
- podSelector:
ResourceQuota Definition in a Namespace
apiVersion: v1
kind: ResourceQuota
metadata:
name: compute-quota
namespace: prod
spec:
hard:
pods: "10"
limits.cpu: "5"
limits.memory: 10Gi
kubectl Namespace Cheat Sheet
List all namespaces
kubectl get namespace
Apply the namespace
kubectl apply -f [file.yml]
Shortcut for listing namespaces
kubectl get ns
Set the current context to use a specific namespace
kubectl config set-context --current --namespace=[namespaceName]
Create a new namespace
kubectl create ns [namespaceName]
Delete a namespace
kubectl delete ns [namespaceName]
List all pods across all namespaces
kubectl get pods --all-namespaces
Example Commands
To list pods from a specific namespace:
kubectl get pods --namespace=kube-system
kubectl get pods -n kube-system
Workloads
A workload in Kubernetes refers to an application or a set of applications running on the cluster. Kubernetes provides several controllers to manage different types of workloads:
Pod:
- Represents a set of running containers on Kubernetes.
ReplicaSet:
- Ensures a specified number of identical pods are running at all times.
Deployment:
- Manages ReplicaSets and provides declarative updates to applications.
StatefulSet:
- Manages stateful applications and ensures stable, unique network identifiers and persistent storage.
DaemonSet:
- Ensures that all (or some) nodes run a copy of a pod.
Jobs:
- Runs a pod to perform a specific task and then terminates.
CronJob:
- Runs a job on a schedule specified by the cron format.
ReplicaSet
Purpose:
The primary method of managing pod replicas is to provide fault tolerance and scaling.
Ensures a specified number of pod replicas are running.
Recommended Usage:
- While you can create ReplicaSets directly, it's recommended to manage them using Deployments for easier management and additional features.
Example ReplicaSet Definition
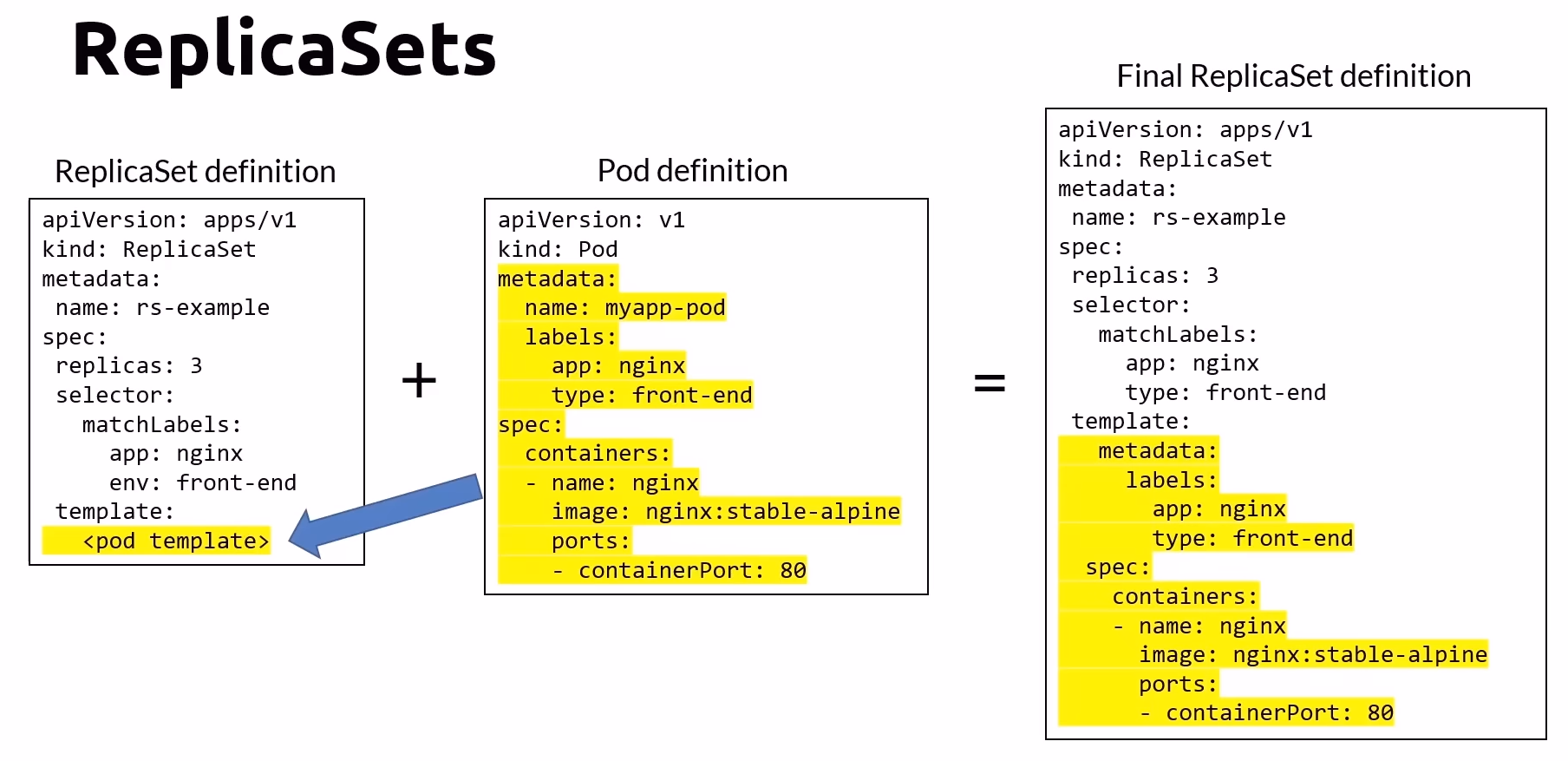
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: rs-example
spec:
replicas: 3 # Desired number of pod instances
selector:
matchLabels:
app: nginx
type: front-end
template:
metadata:
labels:
app: nginx
type: front-end
spec:
containers:
- name: nginx
image: nginx:stable-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
ports:
- containerPort: 80
Commands
Create a ReplicaSet:
kubectl apply -f [definition.yaml]List Pods:
kubectl get pods -o wideList ReplicaSets:
kubectl get rsDescribe ReplicaSet:
kubectl describe rs [rsName]Delete a ReplicaSet (using YAML file):
kubectl delete -f [definition.yaml]Delete a ReplicaSet (using ReplicaSet name):
kubectl delete rs [rsName]
Deployment
Pods vs Deployment
Pods:
- Do not self-heal, scale, update, or rollback on their own.
Deployments:
- Manage a single pod template and provide self-healing, scaling, updates, and rollback capabilities.
Microservices with Deployments
Create a deployment for each microservice:
front-end
back-end
image-processor
creditcard-processor
Deployments Overview
Deployments create ReplicaSets in the background.
Interact with deployments, not directly with ReplicaSets.
Deployment Definition
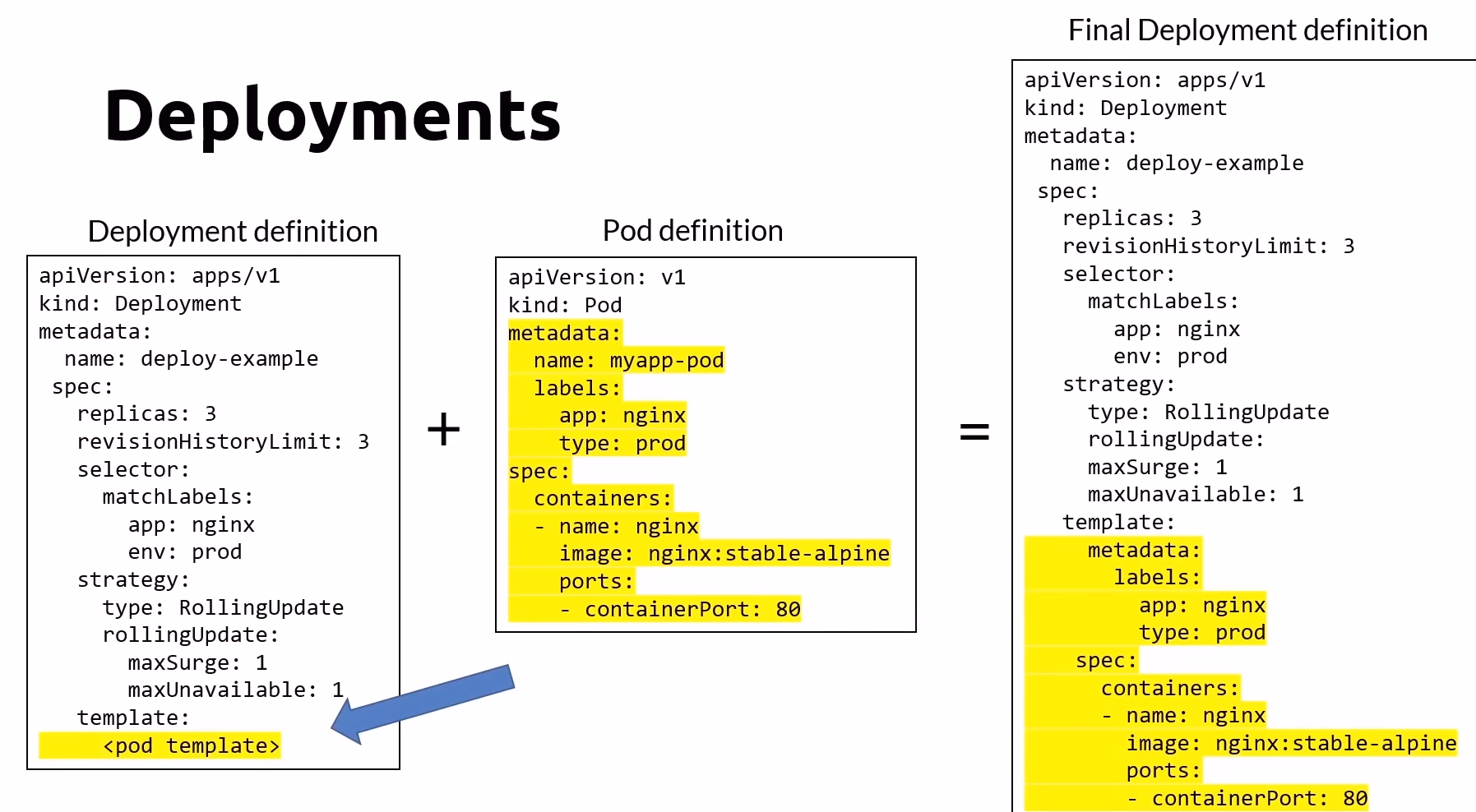
apiVersion: apps/v1
kind: Deployment
metadata:
name: deploy-example
spec:
replicas: 3
revisionHistoryLimit: 3
selector:
matchLabels:
app: nginx
env: prod
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 1
maxUnavailable: 1
template:
spec:
containers:
- name: nginx
image: nginx:stable-alpine
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 250m
memory: 256Mi
ports:
- containerPort: 80
Deployment Commands
Imperative Deployment:
kubectl create deploy [deploymentName] --image=busybox --replicas=3 --port=80Create a Deployment (using YAML file):
kubectl apply -f [definition.yaml]List Deployments:
kubectl get deployDescribe Deployment:
kubectl describe deploy [deploymentName]List ReplicaSets:
kubectl get rsDelete a Deployment (using YAML file):
kubectl delete -f [definition.yaml]Delete a Deployment (using Deployment name):
kubectl delete deploy [deploymentName]
Here's the formatted and corrected content for the DaemonSet section in Kubernetes:
DaemonSet
Purpose:
Ensures all nodes (or a subset) run an instance of a pod.
Managed by the daemon controller and scheduled by the scheduler controller.
Automatically adds pods to nodes as they are added to the cluster.
Typical Uses:
Running a cluster storage daemon.
Running a logs collection daemon on every node.
Running a node monitoring daemon on every node.
DaemonSet Definition
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: daemonset-example
labels:
app: daemonset-example
spec:
selector:
matchLabels:
app: daemonset-example
template:
metadata:
labels:
app: daemonset-example
spec:
tolerations:
- key: node-role.kubernetes.io/master
effect: NoSchedule
containers:
- name: busybox
image: busybox
args:
- sleep
- "3600"
Tolerations Explanation
By setting tolerations, we specify that the DaemonSet should not schedule pods on master nodes (node-role.kubernetes.io/master).
DaemonSet Commands
Create a DaemonSet (using YAML file):
kubectl apply -f [definition.yaml]List DaemonSets:
kubectl get dsDescribe DaemonSet:
kubectl describe ds [dsName]Delete a DaemonSet (using YAML file):
kubectl delete -f [definition.yaml]Delete a DaemonSet (using DaemonSet name):
kubectl delete ds [dsName]
StatefulSet
Purpose:
Designed for pods that require stable, unique identifiers and persistent storage.
Maintains a sticky identity for each pod, replacing pods using the same identifier if they fail.
Pods are created sequentially from 0 to X and deleted sequentially from X to 0.
Typical Uses:
Stable network identifiers.
Databases requiring persistent storage.

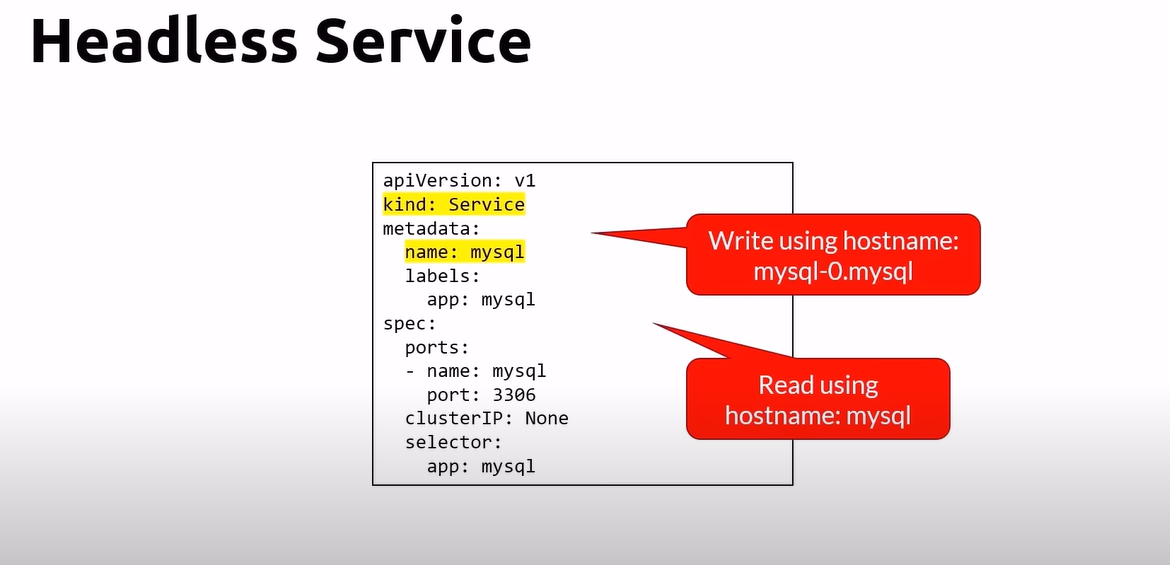
# Service
apiVersion: v1
kind: Service
metadata:
name: nginx
spec:
selector:
app: nginx
ports:
- port: 80
targetPort: 80
clusterIP: None
--
# StatefulState
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: example-statefulset
spec:
serviceName: "nginx"
replicas: 3
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
volumeClaimTemplates:
- metadata:
name: www
spec:
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
Considerations:
Containers are stateless by default; StatefulSets address stateful scenarios.
Consider using cloud provider database services for managed solutions.
Deleting a StatefulSet does not delete PersistentVolumes (PVCs); manual deletion is required.
StatefulSet Commands
Create a StatefulSet (using YAML file):
kubectl apply -f [definition.yaml]List StatefulSets:
kubectl get stsDescribe StatefulSet:
kubectl describe sts [stsName]Delete a StatefulSet (using YAML file):
kubectl delete -f [definition.yaml]Delete a StatefulSet (using StatefulSet name):
kubectl delete sts [stsName]
Jobs
Purpose:
Executes short-lived tasks and tracks successful completions.
Creates and manages pods until a specified number of successful completions is reached.

apiVersion: batch/v1
kind: Job
metadata:
name: example-job
spec:
template:
spec:
containers:
- name: pi
image: perl
command: ["perl", "-Mbignum=bpi", "-wle", "print bpi(2000)"]
restartPolicy: Never
backoffLimit: 4 # number of retries befor job fails
Jobs Commands
Create a Job (using imperative way):
kubectl create job [jobName] --image=busyboxCreate a Job (using YAML file):
kubectl apply -f [definition.yaml]List Jobs:
kubectl get jobsDescribe Job:
kubectl describe job [jobName]Delete a Job (using YAML file):
kubectl delete -f [definition.yaml]Delete a Job (using Job name):
kubectl delete job [jobName]
CronJob
Purpose:
Executes jobs on a scheduled basis, similar to cron jobs.
Runs jobs based on a specified schedule in UTC.
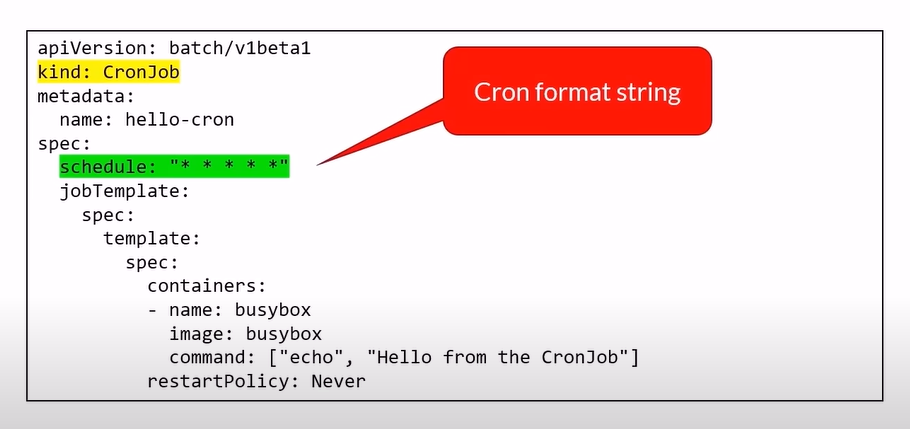
apiVersion: batch/v1
kind: CronJob
metadata:
name: example-cronjob
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: hello
image: busybox
command: ["echo", "Hello from the Kubernetes cluster!!"]
restartPolicy: OnFailure
History:
Stores the last 3 successful jobs and the last failed job.
Set
successfulJobsHistoryLimit: 0to store no successful jobs.
CronJob Commands
Create a CronJob (using imperative way):
kubectl create cronjob [jobName] --image=busybox --schedule="*/1 * * * *" -- bin/sh -c "date;"Create a CronJob (using YAML file):
kubectl apply -f [definition.yaml]List CronJobs:
kubectl get cjDescribe CronJob:
kubectl describe cj [jobName]Delete a CronJob (using YAML file):
kubectl delete -f [definition.yaml]Delete a CronJob (using CronJob name):
kubectl delete cj [jobName]
Rolling Updates
Rolling updates allow you to update your Kubernetes applications without downtime by gradually replacing the old versions of Pods with new ones. This ensures continuous availability during the update process.
Key Parameters for Rolling Updates:
maxSurge
Definition: The maximum number of Pods that can be created over the desired number of Pods during the update process.
Value Type: Can be specified as a number or a percentage.
Example: If the desired number of Pods is 10 and
maxSurgeis set to 2, the update process can create up to 12 Pods temporarily.
maxUnavailable
Definition: The maximum number of Pods that can be unavailable during the update process.
Value Type: Can be specified as a number or a percentage.
Default Values: Both
maxSurgeandmaxUnavailableare set to 1 by default.
Commands for Managing Rollouts:
Update a Deployment:
kubectl apply -f [definition.yaml]- Apply the changes specified in the YAML file to update the deployment.
Get the Progress of the Update:
kubectl rollout status deployment/[deploymentname]- Check the status of the ongoing rollout to monitor its progress.
Get the History of the Deployment:
kubectl rollout history deployment [deploymentname]- Retrieve the history of rollouts for a specific deployment to see previous versions.
Rollback a Deployment:
kubectl rollout undo deployment/[deploymentname]example :
kubectl rollout undo deployment/example-dep — to-revision 1Rollback the deployment to the previous stable version.
Rollback to a Specific Revision Number:
kubectl rollout undo deployment/[deploymentname] --to-revision=[revision X]- Rollback the deployment to a specific revision.
Example YAML File for a Deployment with Rolling Updates
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deployment
spec:
replicas: 5
selector:
matchLabels:
app: example
template:
metadata:
labels:
app: example
spec:
containers:
- name: example-container
image: nginx:1.14.2
ports:
- containerPort: 80
strategy:
type: RollingUpdate
rollingUpdate:
maxSurge: 2
maxUnavailable: 1
Blue-Green Deployment
Blue-Green Deployment is a strategy that reduces downtime and risk by running two identical production environments, referred to as Blue and Green. Here’s how it works:
Two Environments: You have two identical production environments, Blue and Green. At any given time, only one of these environments serves live production traffic.
Deploying a New Version:
- When you need to deploy a new version of your application, you deploy it to the idle environment (e.g., Green).
Testing:
- Once the deployment is successful, you thoroughly test the new version in the Green environment to ensure everything works correctly.
Switch Traffic:
- After successful testing, you switch the live production traffic from the old environment (e.g., Blue) to the new one (Green). This switch can be performed quickly and seamlessly.
Quick Rollback:
- If something goes wrong with the new version, you can quickly rollback by switching the live traffic back to the old environment (Blue).
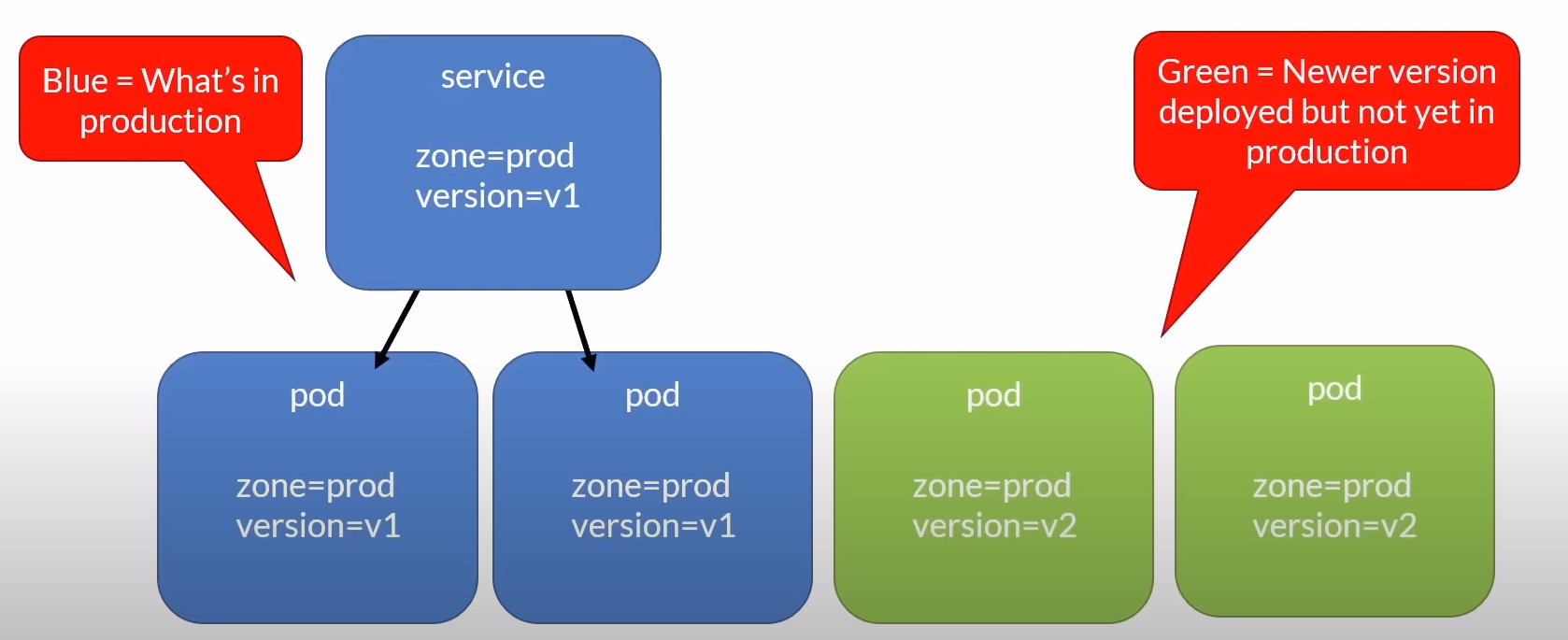
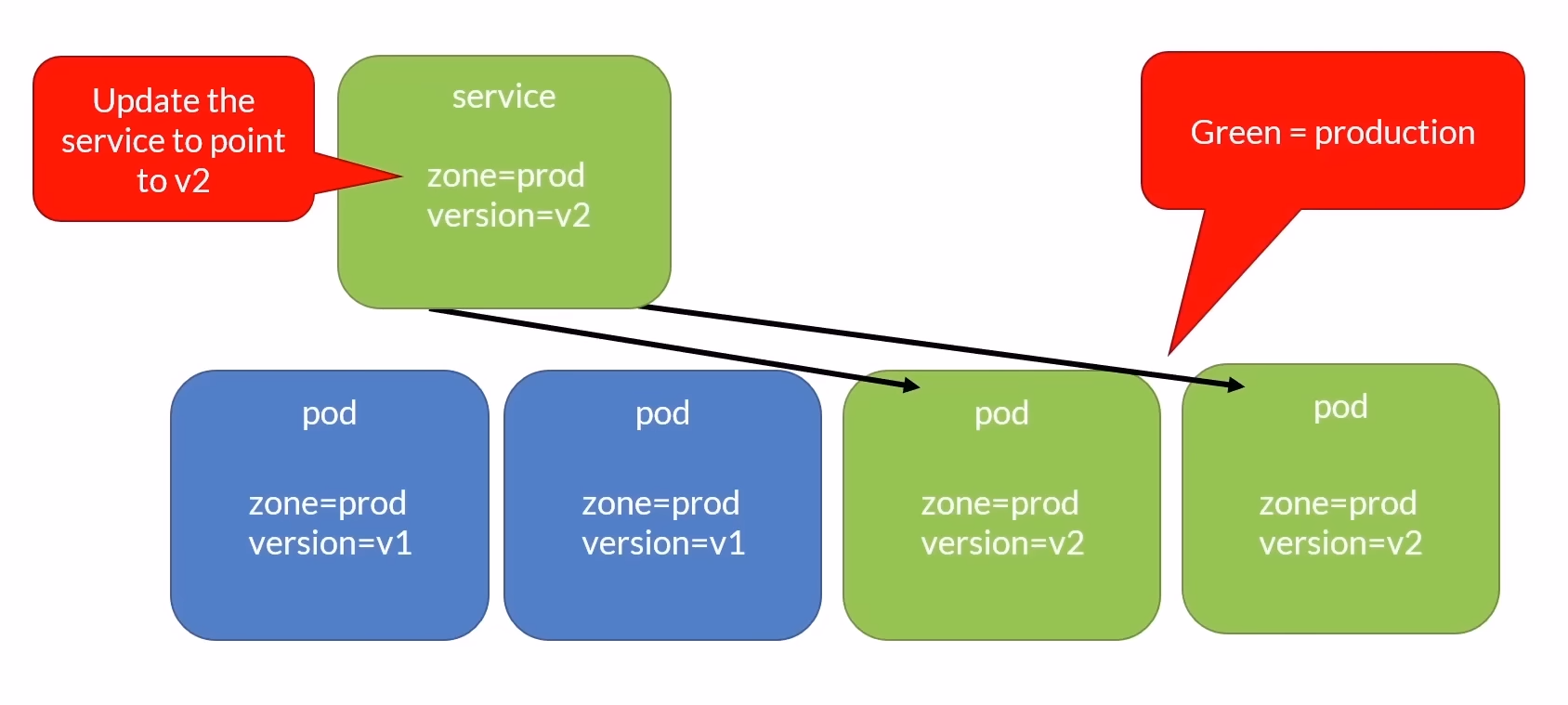
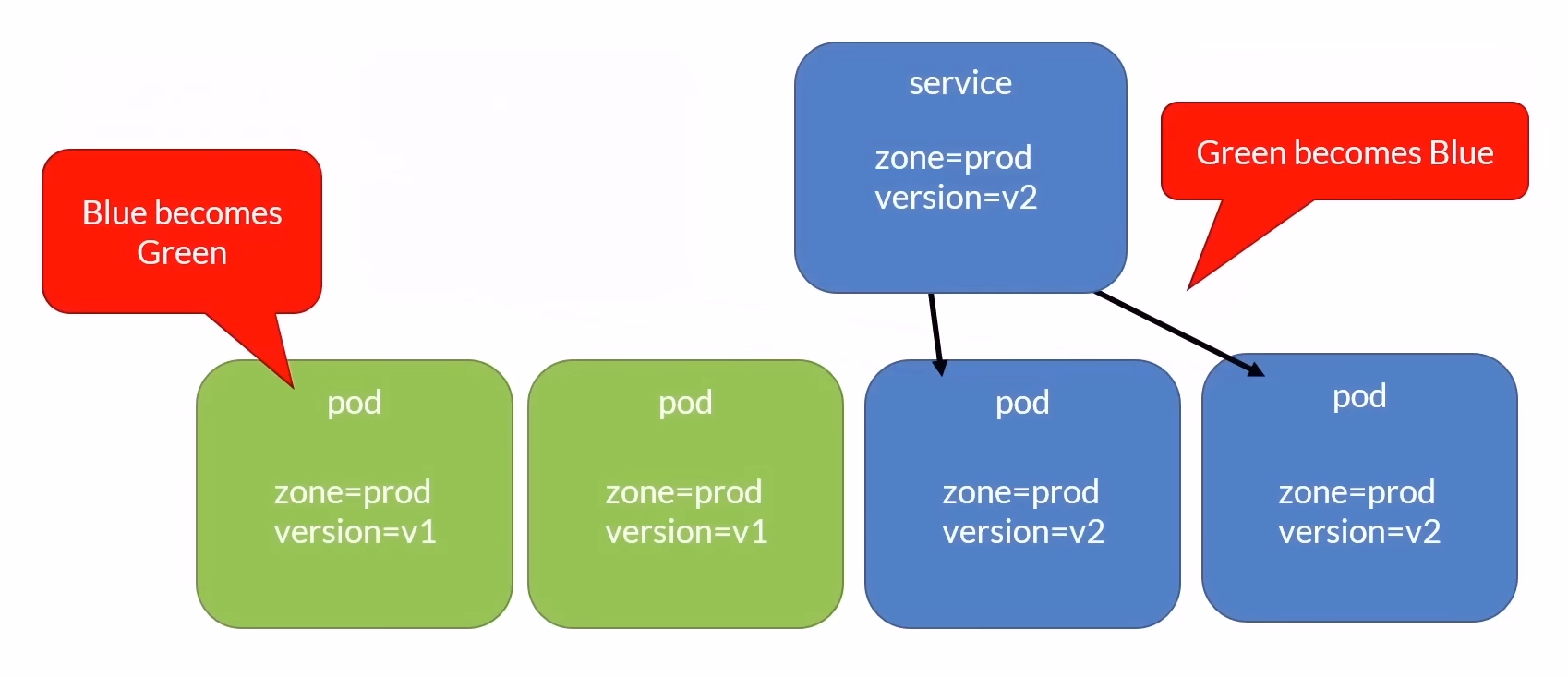
Benefits of Blue-Green Deployment:
Zero Downtime: Traffic can be switched almost instantly with minimal downtime.
Quick Rollback: If the new version fails, traffic can be switched back to the previous version quickly.
Simplified Testing: The new version can be tested in a production-like environment before switching traffic.
Considerations:
Over Provisioning: Requires enough resources to run two full environments simultaneously, which means over-provisioning the cluster size.
Database Schema Changes: Need careful handling of database schema changes to ensure compatibility between versions.
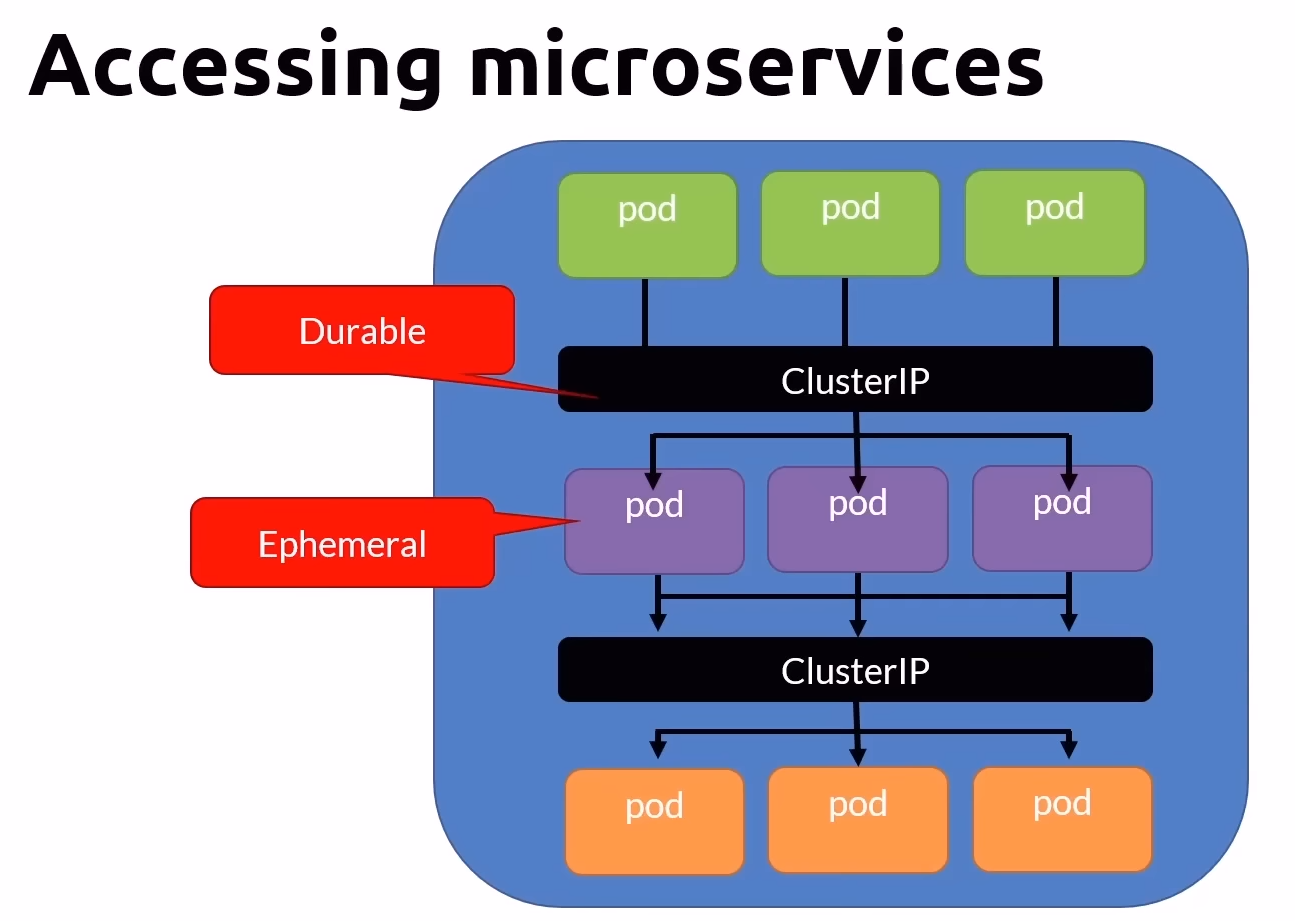
Kubernetes Services
Kubernetes Services are a crucial component designed to solve several key issues related to accessing and managing Pods. Here’s an overview of the problems they solve and how they work.
Problems Services Solve:
Pod IPs Are Unreliable:
- Pods are ephemeral; they can be created and destroyed frequently, leading to changes in their IP addresses. Services provide stable IPs to access these Pods.
Durability:
- Unlike Pods, Services are durable and provide a consistent endpoint for accessing applications running within Pods.
Static IP and DNS:
Services offer a static IP address and a DNS name, ensuring reliable connectivity.
DNS format:
[servicename].[namespace].svc.cluster.local.
Accessing Pods:
- Services allow you to target and access Pods using selectors, facilitating communication within the cluster.
Types of Services
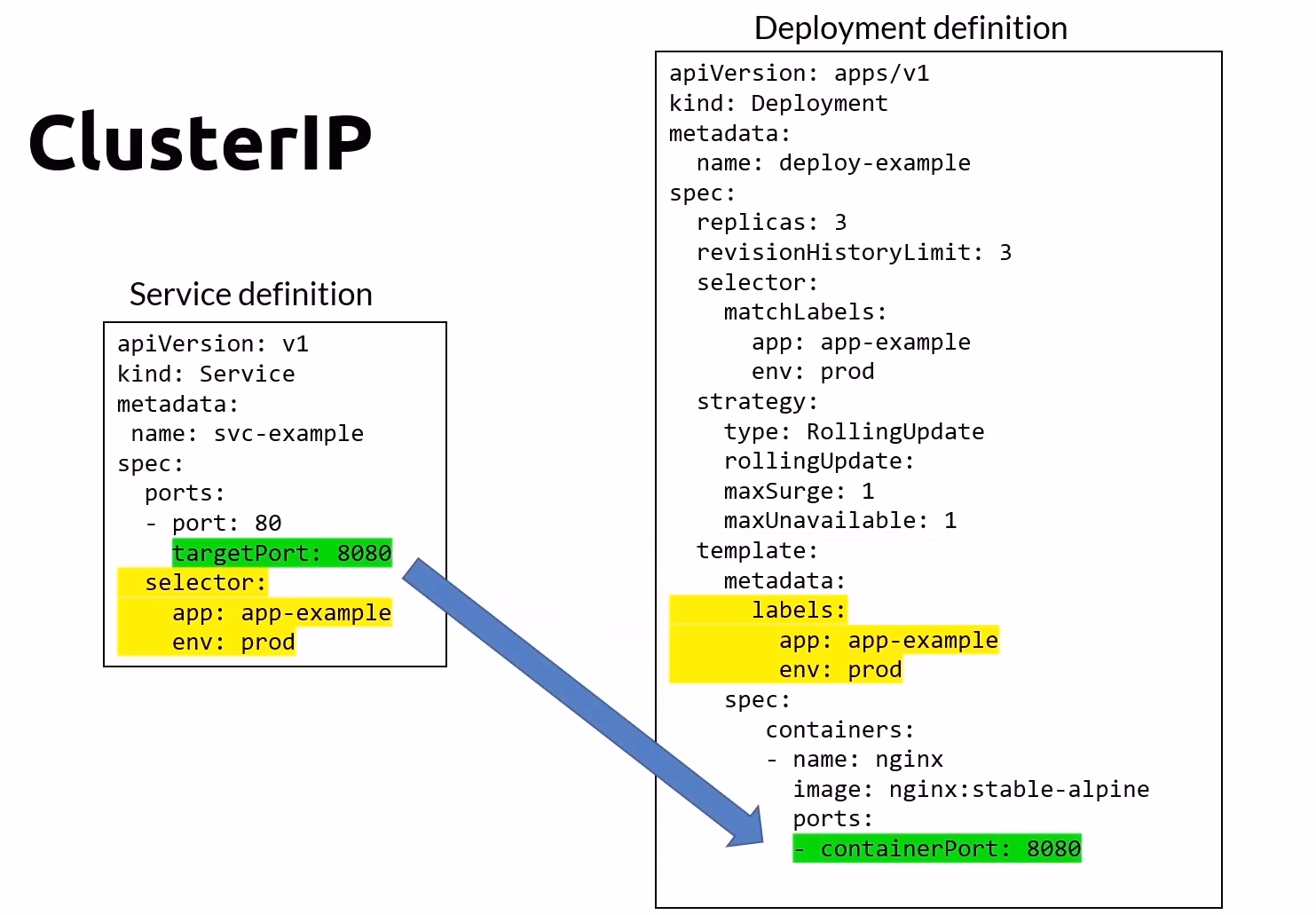
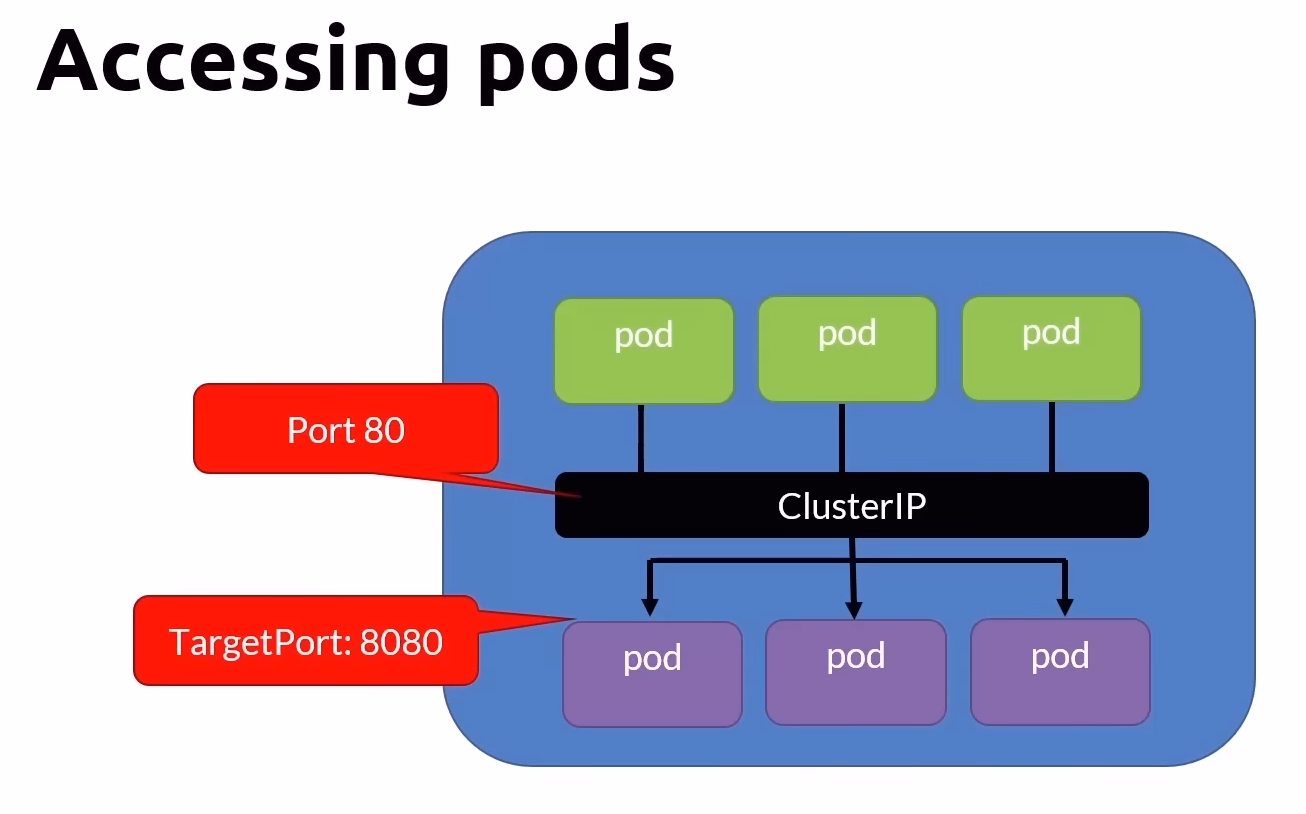
ClusterIP (Default)
The ClusterIP type is the default service type in Kubernetes. It exposes the service on a cluster-internal IP, making the service accessible only within the cluster.
Visibility: Internal to the cluster.
Port: The port the service listens to.
TargetPort: The port where the Pods are listening.
Load Balancing: Uses round-robin by default, with configurable session affinity.
Use Case: Provides a durable way to communicate with Pods inside the cluster.
Commands Cheat Sheet for ClusterIP
Create a Service to Expose a Pod:
kubectl expose pod [podName] --port=80 --name=frontend --target-port=8080Create a Service to Expose a Deployment:
kubectl expose deployment [deployName] --port=80 --target-port=8080Deploy the Service from a YAML File:
kubectl apply -f [definition.yaml]Get the List of Services:
kubectl get svcGet Extra Info about Services:
kubectl get svc -o wideDescribe a Specific Service:
kubectl describe svc [serviceName]Delete a Service from a YAML File:
kubectl delete -f [definition.yaml]Delete a Service by Name:
kubectl delete svc [serviceName]
Here’s an example of a ClusterIP service definition:
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
NodePort Service
A NodePort service extends the ClusterIP service by exposing the service on each Node's IP at a static port. This makes the service accessible both internally within the cluster and externally from outside the cluster.
Key Points
Extends ClusterIP Service: NodePort builds upon the ClusterIP service by adding an external port.
Visibility:
Internal: Accessible within the cluster.
External: Accessible from outside the cluster using the Node’s IP address.
NodePort:
The port the service listens to externally.
Can be statically defined or dynamically allocated from the range 30000-32767.
Port:
- The port the service listens to internally (within the cluster).
TargetPort:
- The port where the Pods are listening.
Nodes:
Must have public IP addresses to be accessible externally.
Use any Node IP + NodePort to access the service.
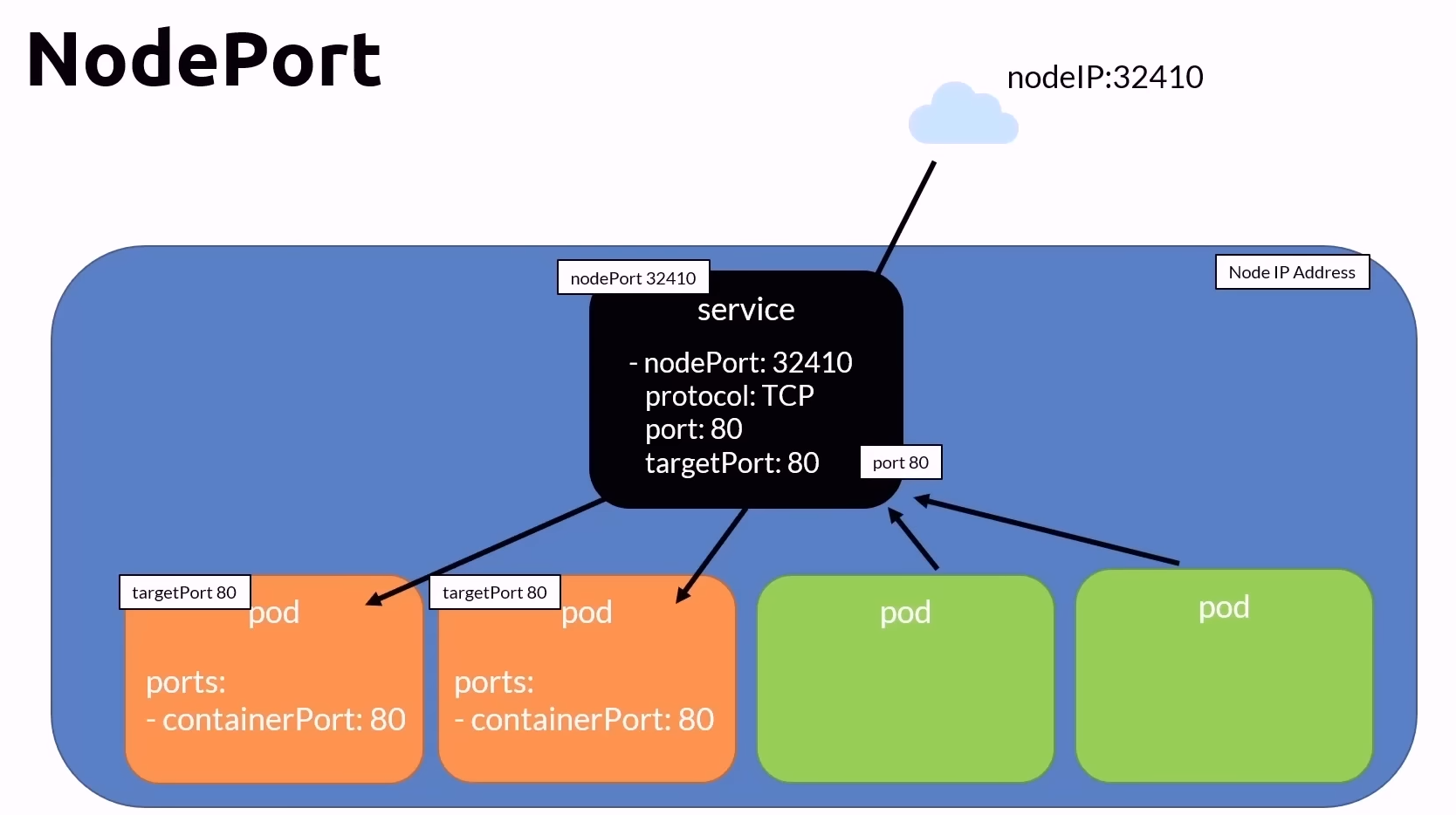
Commands Cheat Sheet for NodePort
Create a Service to Expose a Pod:
kubectl expose pod [podName] --port=80 --type=NodePort --target-port=8080Create a Service to Expose a Deployment:
kubectl expose deployment [deployName] --port=80 --target-port=8080 --type=NodePort --name=frontendOther commands to create, describe, and delete are the same.
Example of a NodePort Service Definition YAML
apiVersion: v1
kind: Service
metadata:
name: frontend
spec:
type: NodePort
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
nodePort: 30036
Load Balancer Types
Load balancing can be categorized into Layer 4 (L4) and Layer 7 (L7) load balancing, each serving different purposes and offering distinct capabilities.
Layer 4 Load Balancing (L4)
Layer 4 load balancing operates at the transport layer (TCP/UDP) and focuses on distributing network traffic across multiple nodes or endpoints based on IP addresses and ports. Key characteristics include:
Transport Level: Operates at the transport layer (TCP/UDP), handling traffic based on IP addresses and ports.
Decision Making: Unable to make decisions based on the content of the traffic.
Simple Algorithms: Uses straightforward algorithms like round-robin for distributing traffic.
Use Cases: Effective for protocols that do not require inspection of application-level data, such as raw TCP or UDP traffic.
Layer 7 Load Balancing (L7)
Layer 7 load balancing operates at the application layer (HTTP, HTTPS, SMTP, etc.) and offers more advanced capabilities compared to L4. Key characteristics include:
Application Level: Operates at the application layer (HTTP, HTTPS, SMTP, etc.), allowing it to inspect and make decisions based on the content of messages.
Content-Based Decisions: Capable of making intelligent load balancing decisions based on HTTP headers, URL paths, cookies, etc.
Optimizations: Provides content optimizations such as SSL termination, caching, and request routing rules.
Use Cases: Ideal for applications where routing decisions need to be based on application-level information, such as HTTP-based services.
Example of LoadBalancer and Ingress Definitions
LoadBalancer Service Definition
apiVersion: v1
kind: Service
metadata:
name: my-loadbalancer-service
spec:
type: LoadBalancer
selector:
app: my-app
ports:
- protocol: TCP
port: 80
targetPort: 8080
Ingress Definition (L7)
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: my-ingress
spec:
rules:
- host: myapp.example.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: my-service
port:
number: 80
Storage and Persistence

Containers: Ephemeral and Stateless
Containers are typically ephemeral and stateless by design:
Ephemeral Nature: Containers are designed to be transient, meaning they can be easily created and destroyed.
Stateless: They do not inherently store data persistently. Any data written to the container's local writable layer is non-persistent and will be lost when the container is terminated.
Volumes
To manage data persistence effectively, Kubernetes provides Volumes, which allow containers to store data externally:
External Storage Systems: Volumes enable containers to store data outside of the container itself.
Plugins: Storage vendors create plugins compatible with Kubernetes' Container Storage Interface (CSI) to facilitate integration with various storage systems.
Static and Dynamic Provisioning: Volumes can be provisioned statically by an administrator or dynamically by Kubernetes based on storage classes and policies.
Storage - The Static Way
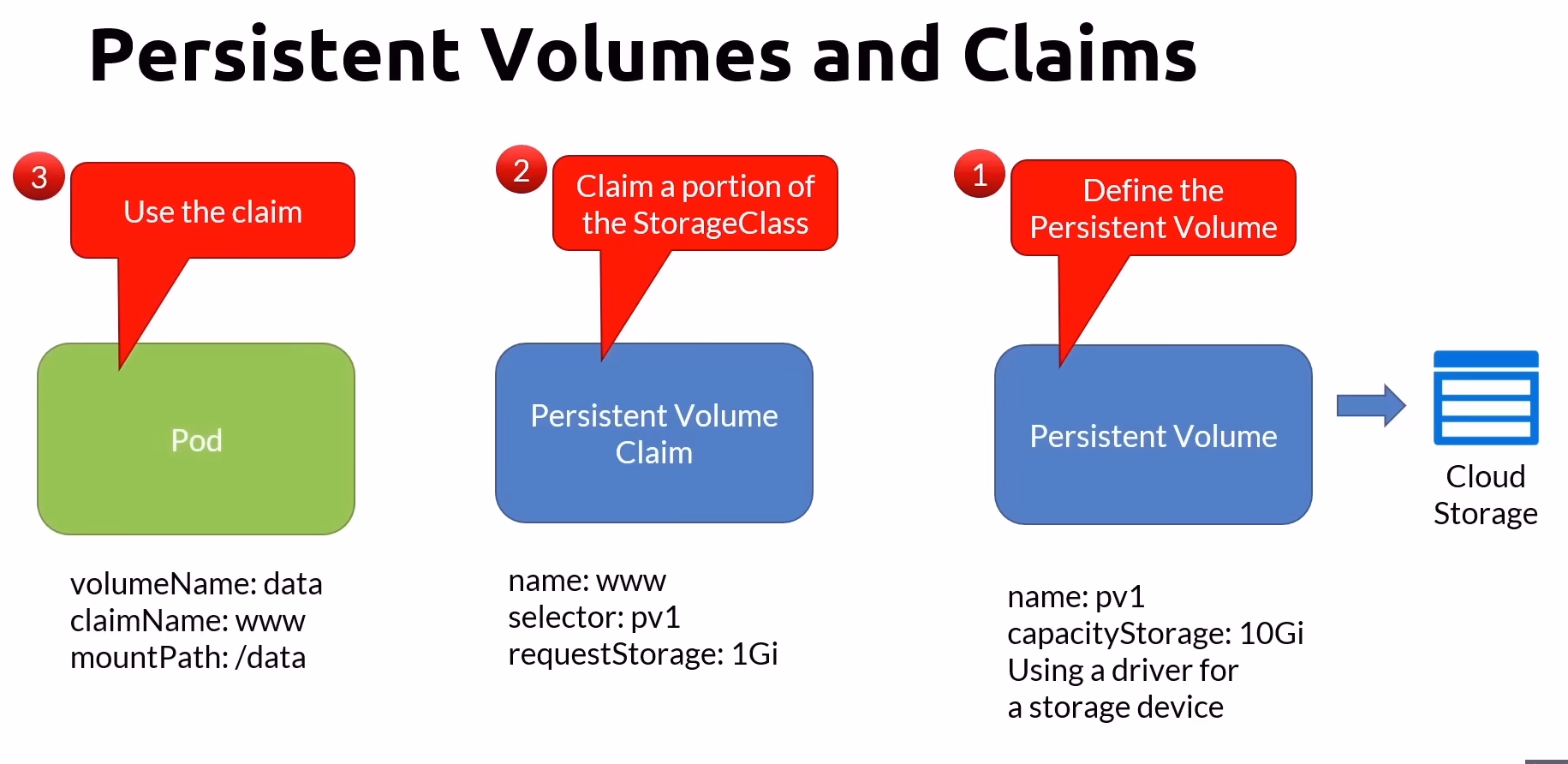
Persistent Volume (PV) and Persistent Volume Claim (PVC)
Persistent Volumes and Claims provide a structured way to manage storage in Kubernetes
Persistent Volumes (PV):
Represent a storage resource provisioned in the cluster.
Managed at the cluster level, provisioned by an administrator.
Persistent Volume Claims (PVC):
Requests for storage by users or applications, which are bound to Persistent Volumes.
Provide a way to consume storage resources defined by Persistent Volumes.
One or more pods can use a Persistent Volume Claim
Can be consumed by any of the containers within the pod
Types of Persistent Volumes
Various types of Persistent Volumes are available, including:
- HostPath: Uses the host node's filesystem, suitable for single-node testing but not recommended for production multi-node clusters due to limitations and lack of data replication.
Main Drawback
When a Pod claims a Persistent Volume (PV), the entire storage volume is reserved for that Pod, even if the Pod consumes only a fraction of the available storage. As a result, other Pods or applications are unable to utilize the remaining storage capacity, leading to potential inefficiencies in resource allocation and utilization.
Reclaim Policies
Persistent Volumes support different reclaim policies upon deletion:
Delete: Deletes the data stored in the Persistent Volume when the associated Pods using it are deleted (default behavior).
Retain: Keeps the data intact even after the associated Pods are deleted, allowing manual cleanup.
Access Modes
Persistent Volumes offer different access modes based on how they can be mounted by Pods:
ReadWriteMany: Allows multiple Pods to mount the volume as read-write simultaneously.
ReadOnlyMany: Allows multiple Pods to mount the volume as read-only simultaneously.
ReadWriteOnce: Allows a single Pod to mount the volume as read-write. Other Pods can mount it as read-only concurrently.
Persistent Volume States
Persistent Volumes exist in various states throughout their lifecycle:
Available: Indicates a free resource not yet bound to a Persistent Volume Claim.
Bound: Indicates the volume is bound to a Persistent Volume Claim and is actively used.
Released: Indicates the volume is no longer bound to a claim but hasn't been reclaimed yet.
Failed: Indicates a volume that has failed its automatic reclamation process due to errors.


Commands Cheat Sheet for PVs and PVCs
Deploy the PVs and PVCs from a YAML File:
kubectl apply -f [definition.yaml]Get the List of Persistent Volumes (PV):
kubectl get pvGet the List of Persistent Volume Claims (PVC):
kubectl get pvcDescribe a Specific Persistent Volume (PV):
kubectl describe pv [pvName]Describe a Specific Persistent Volume Claim (PVC):
kubectl describe pvc [pvcName]Delete Persistent Volumes and Persistent Volume Claims (PVs and PVCs) from a YAML File:
kubectl delete -f [definition.yaml]Delete a Specific Persistent Volume (PV) by Name:
kubectl delete pv [pvName]Delete a Specific Persistent Volume Claim (PVC) by Name:
kubectl delete pvc [pvcName]
Storage - The Dynamic Way
StorageClass
StorageClass provides dynamic provisioning of Persistent Volumes (PVs) without the need for manual intervention:
Description: Defines classes of storage offered by the cluster administrator.
Abstraction Layer: Acts as an abstraction layer over external storage resources.
Capacity Management: Does not require setting a specific capacity, eliminating the need for administrators to pre-provision PVs.
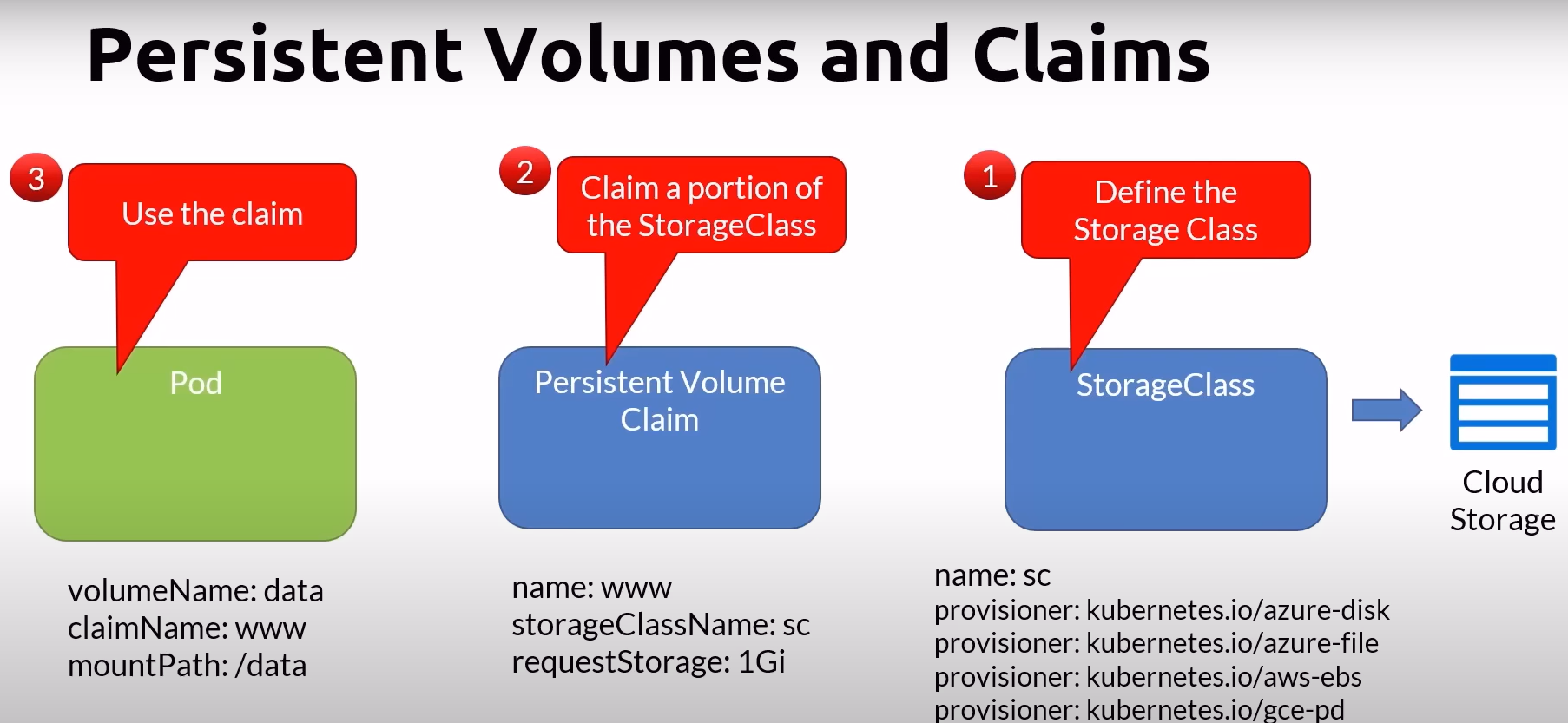
Reclaim Policies
Persistent Volumes and StorageClasses support different reclaim policies upon deletion:
Delete: Deletes the data stored in the volume upon deletion of associated Pods (default behavior).
Retain: Retains the data even after deletion of associated Pods, allowing manual cleanup.
Access Modes
Persistent Volumes and StorageClasses offer various access modes for Pods:
ReadWriteMany: Allows multiple Pods to mount the volume as read-write simultaneously.
ReadOnlyMany: Allows multiple Pods to mount the volume as read-only simultaneously.
ReadWriteOnce: Allows a single Pod to mount the volume as read-write, with other Pods in read-only mode. The first Pod to mount it gets write access.
Commands Cheat Sheet for StorageClass and PVC
Deploy the StorageClass or PVC from a YAML File:
kubectl apply -f [definition.yaml]Get the List of StorageClasses:
kubectl get scGet the List of Persistent Volume Claims (PVC):
kubectl get pvcDescribe a Specific StorageClass:
kubectl describe sc [className]Delete StorageClass and PVC from a YAML File:
kubectl delete -f [definition.yaml]Delete a Specific StorageClass by Name:
kubectl delete sc [className]Delete a Specific Persistent Volume Claim (PVC) by Name:
kubectl delete pvc [pvcName]
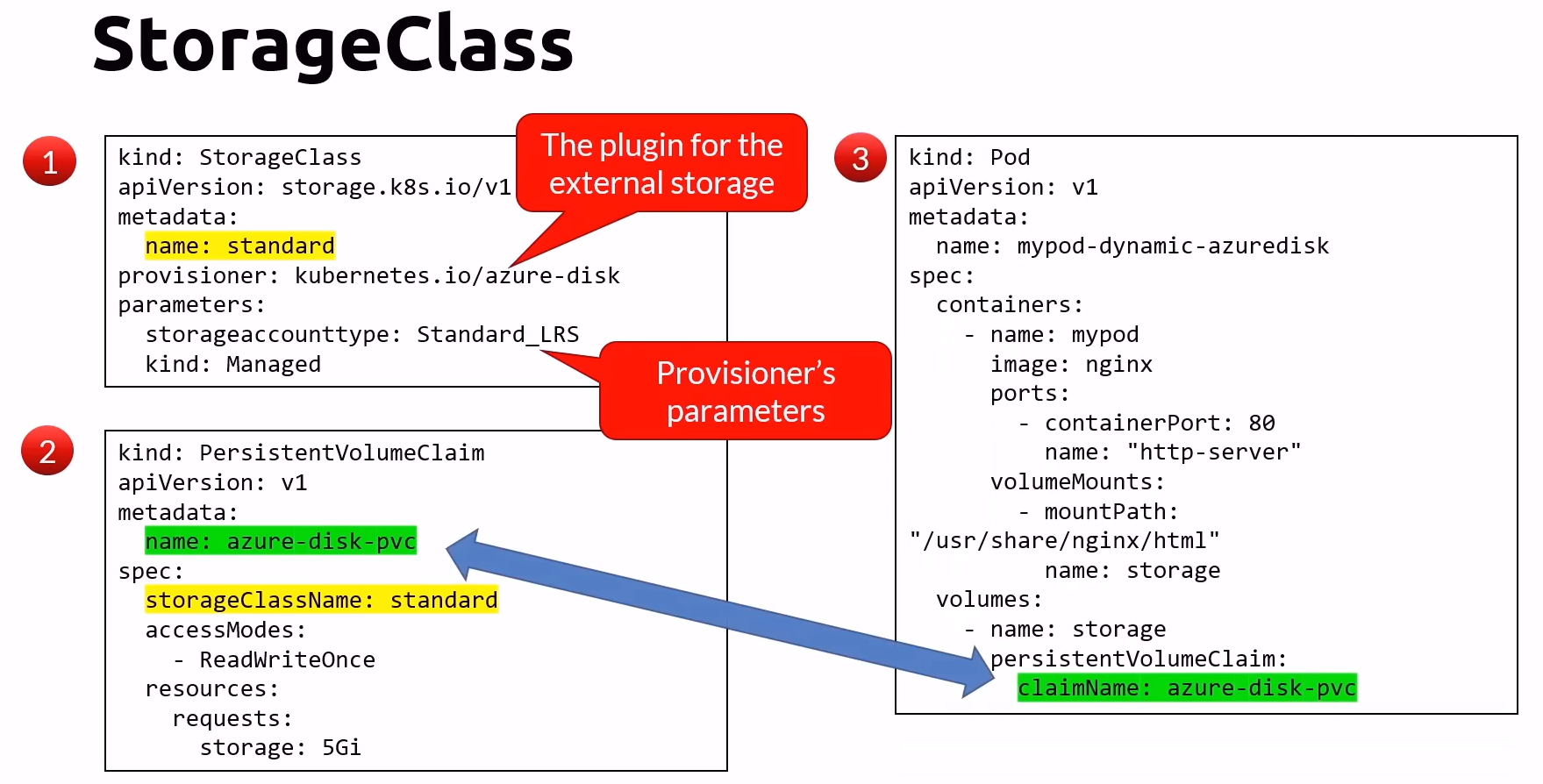
PersistentVolume vs StorageClass

PersistentVolume (PV) and StorageClass serve different purposes in Kubernetes:
PersistentVolume (PV)
Capacity Defined: PVs define the capacity of the storage available, specifying attributes such as size (e.g., 1GiB, 10GiB).
Manual Allocation: Administrators manually allocate and manage PVs, configuring storage properties like access modes (ReadWriteOnce, ReadOnlyMany, ReadWriteMany) and reclaim policies (Delete, Retain).
Exclusive Allocation: Once a PV is claimed by a node or application, the entire capacity is occupied by that entity. Other nodes or applications cannot use the same PV simultaneously unless it is released.
StorageClass
Dynamic Provisioning: StorageClass enables dynamic provisioning of PVs based on defined classes, automating the allocation process without manual intervention.
Access Specification: Specifies how storage can be accessed by nodes, including access modes like ReadWriteOnce, ReadOnlyMany, and ReadWriteMany.
Shared Resource: Unlike PVs, StorageClass allows multiple nodes or applications to dynamically request and utilize available storage resources based on defined policies and access modes.
ConfigMap
ConfigMaps are used to decouple and externalize configuration settings from application code, allowing for greater flexibility and easier management of environment-specific configurations.
Features of ConfigMap
Decoupling Configuration: ConfigMaps allows you to separate configuration data from your container images, promoting better management and versioning configuration settings.
Environment Variables: ConfigMaps can be referenced as environment variables in Pods, making it easy to pass configuration data to applications.
Creation Methods:
Manifests: Define configuration data in YAML or JSON manifest files.
Files: Create ConfigMaps from individual files.
Directories: Create ConfigMaps from directories containing one or more files.
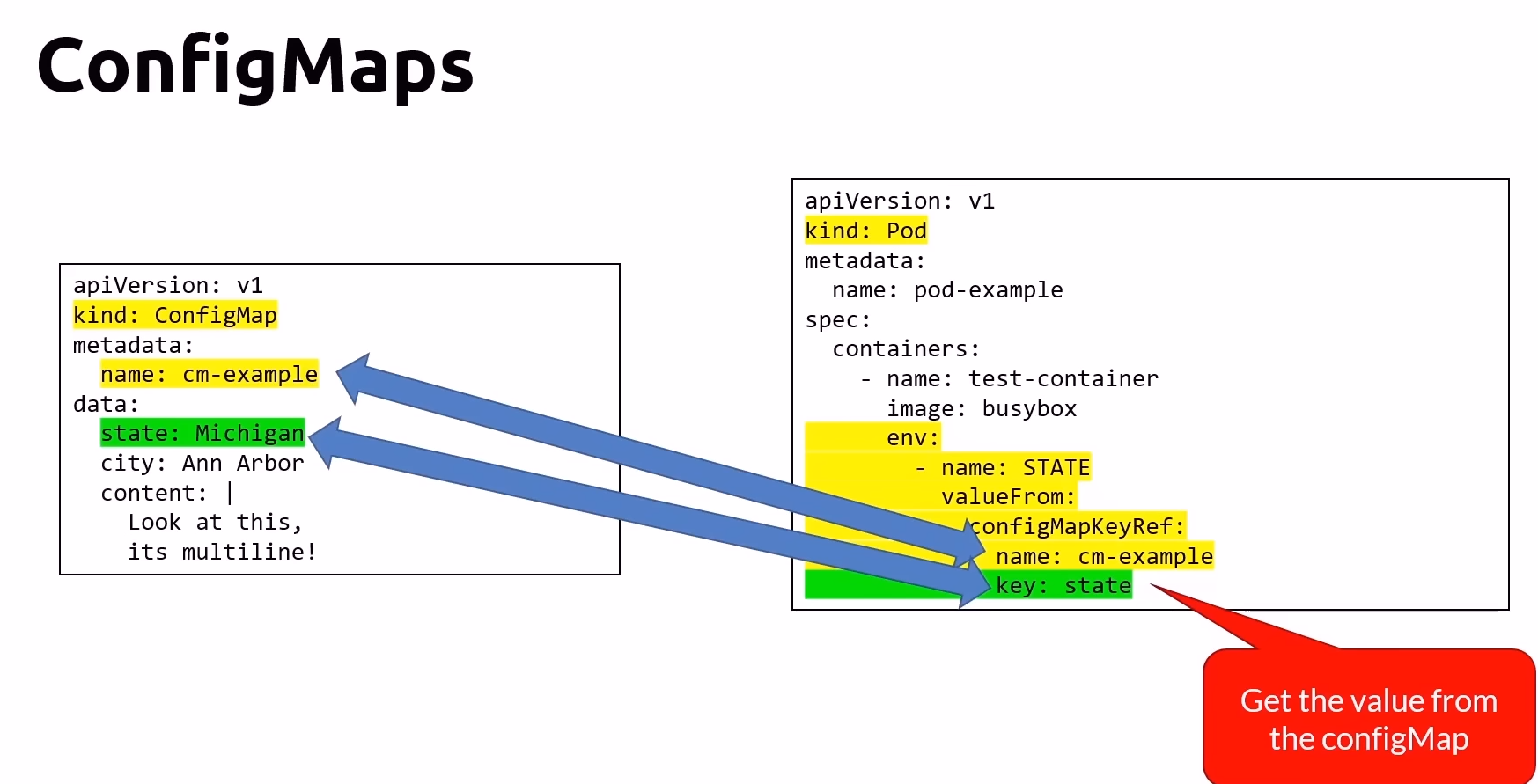
Static Issue with ConfigMaps
- Static Nature: By default, if you change the values in a ConfigMap, the running containers will not automatically pick up the changes. The containers need to be restarted to reflect the new configuration values.
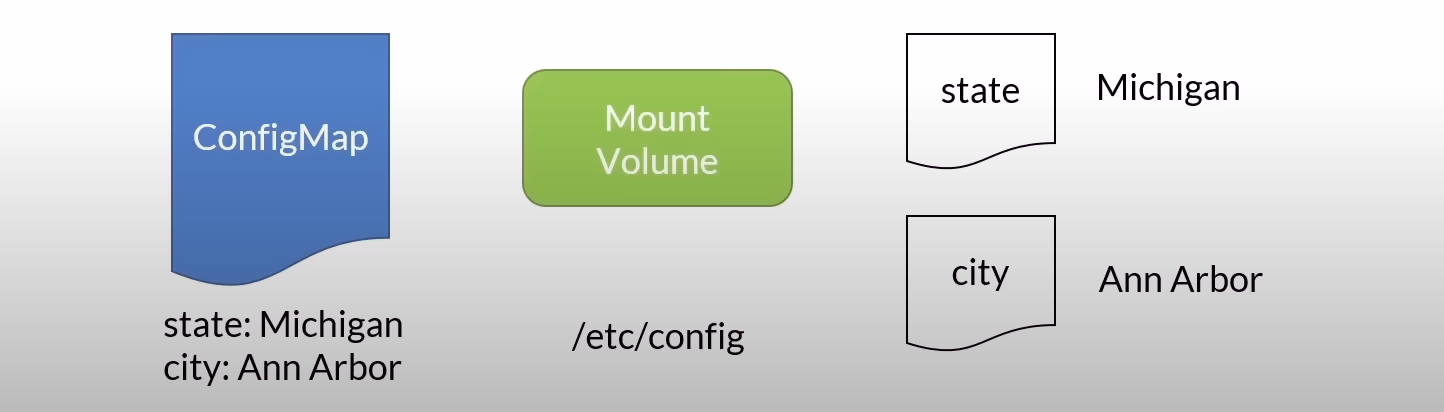
Solving the Static Issue: ConfigMap and Volumes
Dynamic Updates: By mounting ConfigMaps as volumes in your Pods, any updates to the ConfigMap values are automatically reflected in the containers without requiring a restart.
Key/Value as Files: Each key/value pair in a ConfigMap is represented as a file in the mounted directory, allowing applications to read configuration data directly from the file system.

Commands for Managing ConfigMaps
Create ConfigMap from Literals:
kubectl create configmap literal-example --from-literal="city=Ann Arbor" --from-literal=state=MichiganApply ConfigMap from a Manifest File:
kubectl apply -f [cf.yaml]Create ConfigMap from a File:
kubectl create cm [name] --from-file=myconfig.txtCreate ConfigMap from a Directory:
kubectl create cm [name] --from-file=config/List ConfigMaps:
kubectl get cmGet a ConfigMap in YAML Format:
kubectl get cm [name] -o yamlDelete a ConfigMap from a Manifest File:
kubectl delete -f [cf.yaml]Delete a ConfigMap by Name:
kubectl delete cm [name]
Example: Creating and Using a ConfigMap
ConfigMap Manifest File (configmap-example.yaml)
apiVersion: v1
kind: ConfigMap
metadata:
name: example-configmap
data:
city: "Ann Arbor"
state: "Michigan"
Applying the ConfigMap
kubectl apply -f configmap-example.yaml
Using ConfigMap in a Pod
codeapiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
env:
- name: CITY
valueFrom:
configMapKeyRef:
name: example-configmap
key: city
- name: STATE
valueFrom:
configMapKeyRef:
name: example-configmap
key: state
volumes:
- name: config-volume
configMap:
name: example-configmap
Secrets
Secrets are used to store and manage sensitive information, such as passwords, OAuth tokens, and SSH keys, securely within your cluster.
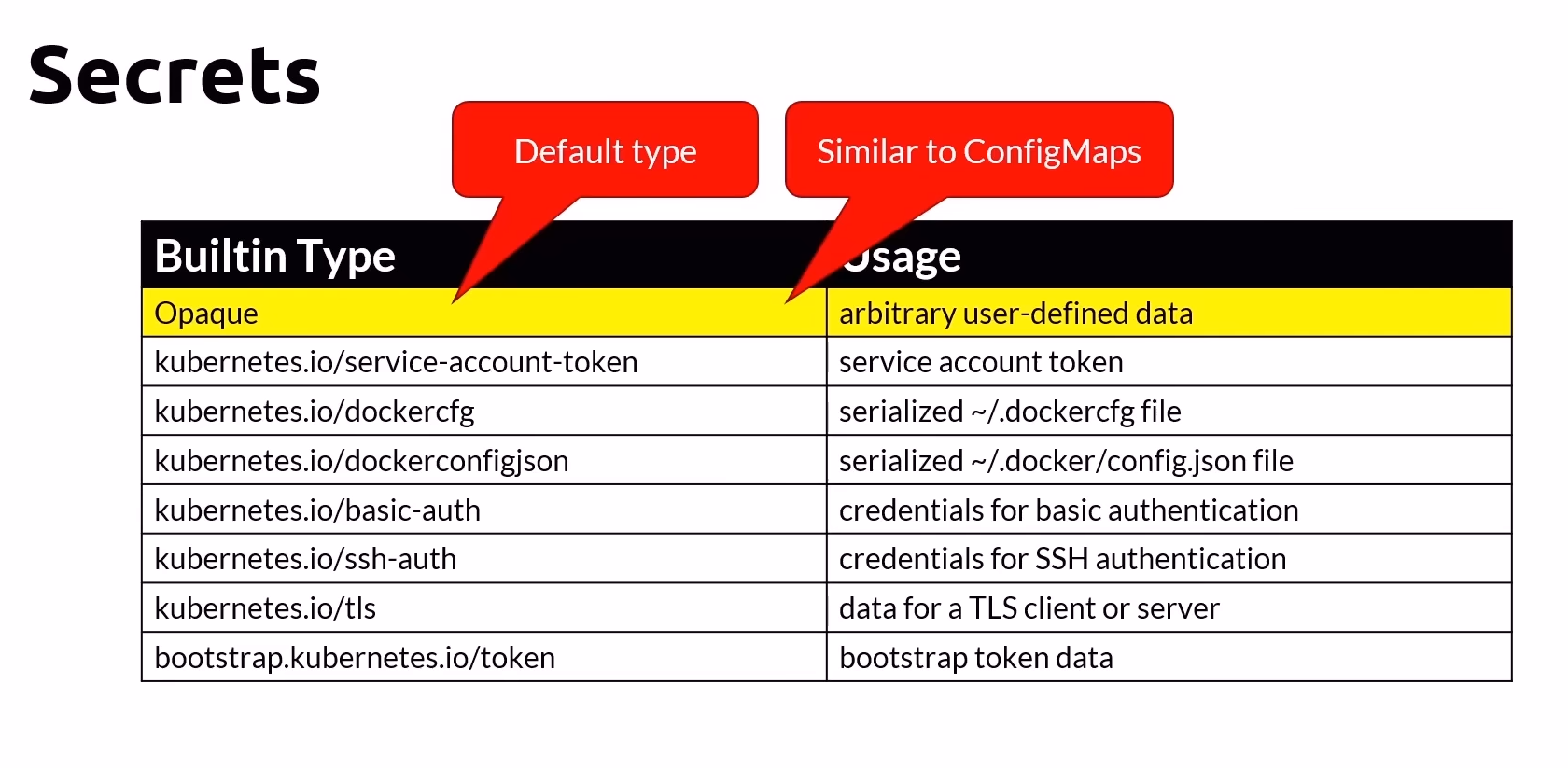
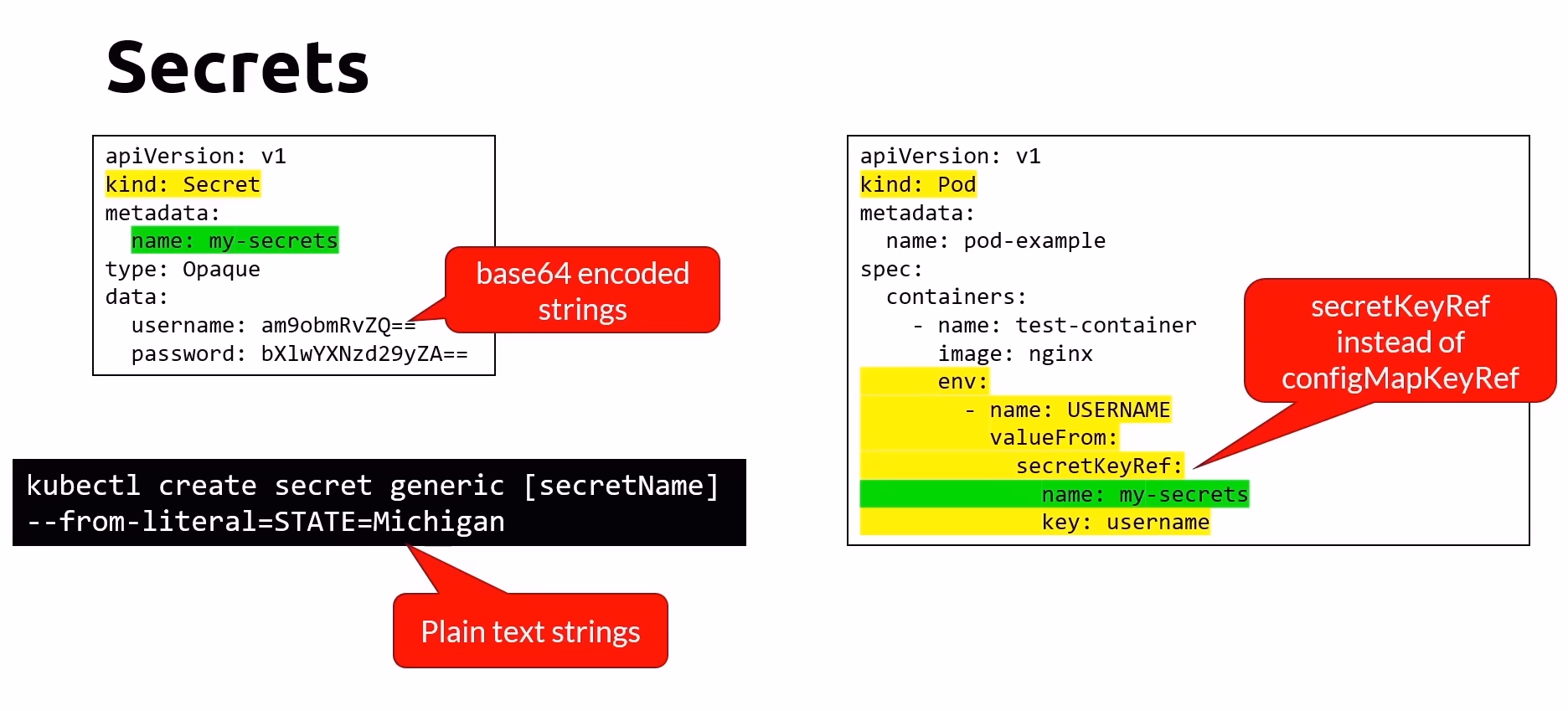
Features of Secrets
Base64 Encoded Strings: Secrets are stored as base64 encoded strings. While base64 encoding obscures the data, it is not a form of encryption and should not be considered secure.
Security Concerns: Since base64 strings are not encrypted, it is crucial to handle Secrets carefully to prevent unauthorized access.
Best Practices for Using Secrets
RBAC Authorization Policies: Protect Secrets using Role-Based Access Control (RBAC) to restrict who can access and modify them.
External Storage: Consider storing Secrets in a more secure external service provided by cloud providers, such as:
Azure Key Vault
AWS Key Management Service (KMS)
Google Cloud Key Management Service (KMS)
Mounting Secrets as Volumes
Secrets can be mounted as volumes in Pods, allowing containers to securely access sensitive information.
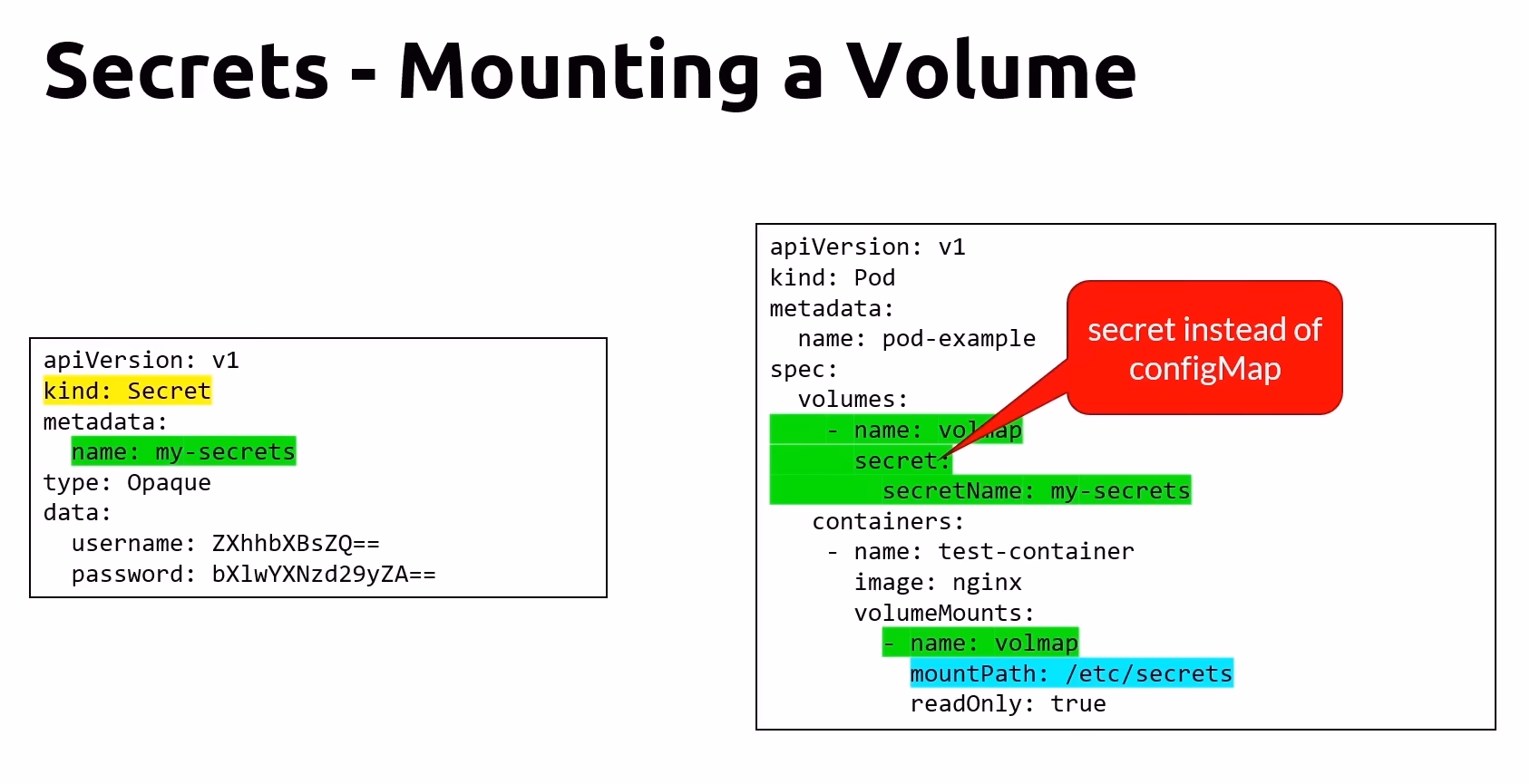
Docker Configuration Secrets
Secrets can also be used to manage Docker configuration, such as Docker registry credentials, to facilitate secure image pulling.

Commands for Managing Secrets
Create Secret from Literal:
kubectl create secret generic [secretName] --from-literal=STATE=MichiganApply Secret from a Manifest File:
kubectl apply -f [secret.yaml]List Secrets:
kubectl get secretsGet a Secret in YAML Format:
kubectl get secrets [secretName] -o yamlDelete a Secret from a Manifest File:
kubectl delete -f [secret.yaml]Delete a Secret by Name:
kubectl delete secrets [secretName]
Example: Creating and Using a Secret
Secret Manifest File (secret-example.yaml)
apiVersion: v1
kind: Secret
metadata:
name: example-secret
type: Opaque
data:
username: YWRtaW4= # base64 encoded value for 'admin'
password: cGFzc3dvcmQ= # base64 encoded value for 'password'
Applying the Secret
kubectl apply -f secret-example.yaml
Using a Secret in a Pod
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: nginx
env:
- name: USERNAME
valueFrom:
secretKeyRef:
name: example-secret
key: username
- name: PASSWORD
valueFrom:
secretKeyRef:
name: example-secret
key: password
volumes:
- name: secret-volume
secret:
secretName: example-secret
Observability
Observability involves monitoring the state and performance of applications and infrastructure to ensure reliability and facilitate troubleshooting.
Pod Crash
Observability tools and techniques help detect and diagnose pod crashes, enabling quick identification of the root cause and resolution.
App Crash
Similarly, observability helps in detecting application crashes and gathering the necessary information to troubleshoot and fix the issues promptly.
Probes
Probes are a key component of Kubernetes observability, providing health checks for containers to ensure they are functioning correctly.
Types of Probes
Startup Probes
Purpose: Determine when a container has successfully started.
Usage: Useful for containers with long initialization times, ensuring they don't receive traffic until they are fully ready.
Readiness Probes
Purpose: Determine when a container is ready to accept traffic.
Usage: Ensures that only containers ready to serve requests are included in the service load balancer.
Impact: A failing readiness probe will stop the application from receiving traffic, preventing disruptions to users.
Liveness Probes
Purpose: Check whether a container is still running.
Usage: Helps detect and recover from application crashes by restarting the container if the probe fails.
Probing the Container
The Kubernetes kubelet periodically checks the health of containers using probes. There are three types of actions that probes can perform:
ExecAction
Description: Executes a specified command inside the container.
Example Usage: Checking the existence of a specific file or the output of a script.
TCPSocketAction
Description: Check if a TCP socket on the specified port is open.
Example Usage: Verifying that a service is listening on a given port.
HTTPGetAction
Description: Performs an HTTP GET request against a specific port and path.
Example Usage: Checking the response code and content of a web application endpoint.
Example Configurations
apiVersion: v1
kind: Pod
metadata:
name: example-pod
spec:
containers:
- name: example-container
image: your-application-image:latest
ports:
- containerPort: 8080
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
startupProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 10
ExecAction
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
TCPSocketAction
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
HTTPGetAction
startupProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
Scaling Pods with Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaling (HPA)
Horizontal Pod Autoscaling automatically adjusts the number of pods in a deployment or replica set based on observed CPU utilization (or, with the custom metrics support, on some other application-provided metrics). This helps ensure that your application can scale to handle varying loads efficiently.
Key Points:
Uses the Kubernetes Metrics Server: HPA relies on the metrics server to monitor resource usage.
Pod Resource Requests and Limits: For HPA to function, pods must have CPU and memory requests and limits defined.
Metrics Check Interval: HPA queries the metrics server every 30 seconds to check current resource usage.
Scaling Parameters:
Min and Max Replicas: Define the minimum and maximum number of pod replicas.
Cooldown / Delay Periods:
Prevent Racing Conditions: Prevents rapid scaling up and down that could destabilize the system.
Default Delays:
Scale Up Delay: 3 minutes
Scale Down Delay: 5 minutes
Horizontal Pod Autoscaling Diagram
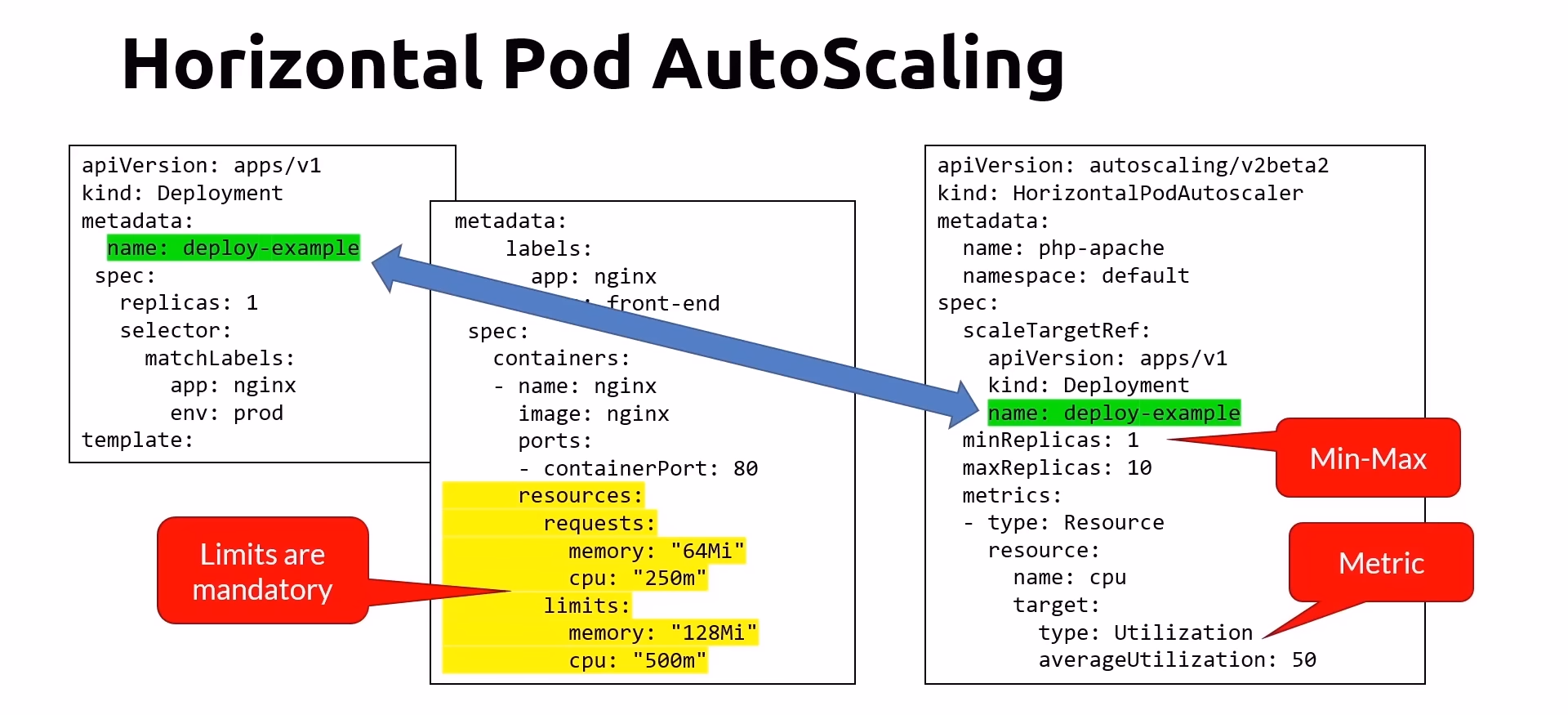
Commands
Imperative Way:
kubectl autoscale --cpu-percent=50 deployment [name] --min=3 --max=10
- Example: Scales the deployment based on CPU usage, keeping between 3 to 10 replicas.
Declarative Way:
kubectl apply -f [hpa.yaml]
- Example YAML File:
apiVersion: autoscaling/v2beta2
kind: HorizontalPodAutoscaler
metadata:
name: example-hpa
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: example-deployment
minReplicas: 3
maxReplicas: 10
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Get the Autoscaler Status:
kubectl get hpa [name]
- Example: Retrieves the current status and metrics of the HPA.
Delete HPA:
kubectl delete -f [hpa.yaml]
kubectl delete hpa [name]
- Example: Deletes the HPA configuration either through a YAML file or by specifying the HPA name.
Additional Information
Metrics Server Installation: Ensure the metrics server is installed and running in your cluster for HPA to function correctly.
Custom Metrics: With custom metrics support, HPA can scale based on application-provided metrics other than CPU and memory.
Best Practices:
Define resource requests and limits for all containers.
Monitor and adjust the cooldown periods to prevent unnecessary scaling actions.
Regularly review and update scaling policies to match the application's load patterns.
Subscribe to my newsletter
Read articles from Darshan Atkari directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Darshan Atkari
Darshan Atkari
Hey there! I'm Darshan Atkari, a dedicated Computer Engineering student. I thoroughly enjoy documenting my learning experiences. Come along on my exciting journey through the world of technology!