SQL Server Tutorials
 Mritunjay Kumar
Mritunjay Kumar
SQL Server is a database management system developed by Microsoft for storing and retrieving data as requested by other software applications.
Database:
A database is a collection of related data. For example, a university database includes information on students, courses, and faculty, while a bank database contains data on customers, accounts, loans, and employees.
Types of Databases:
There are two main types of databases:
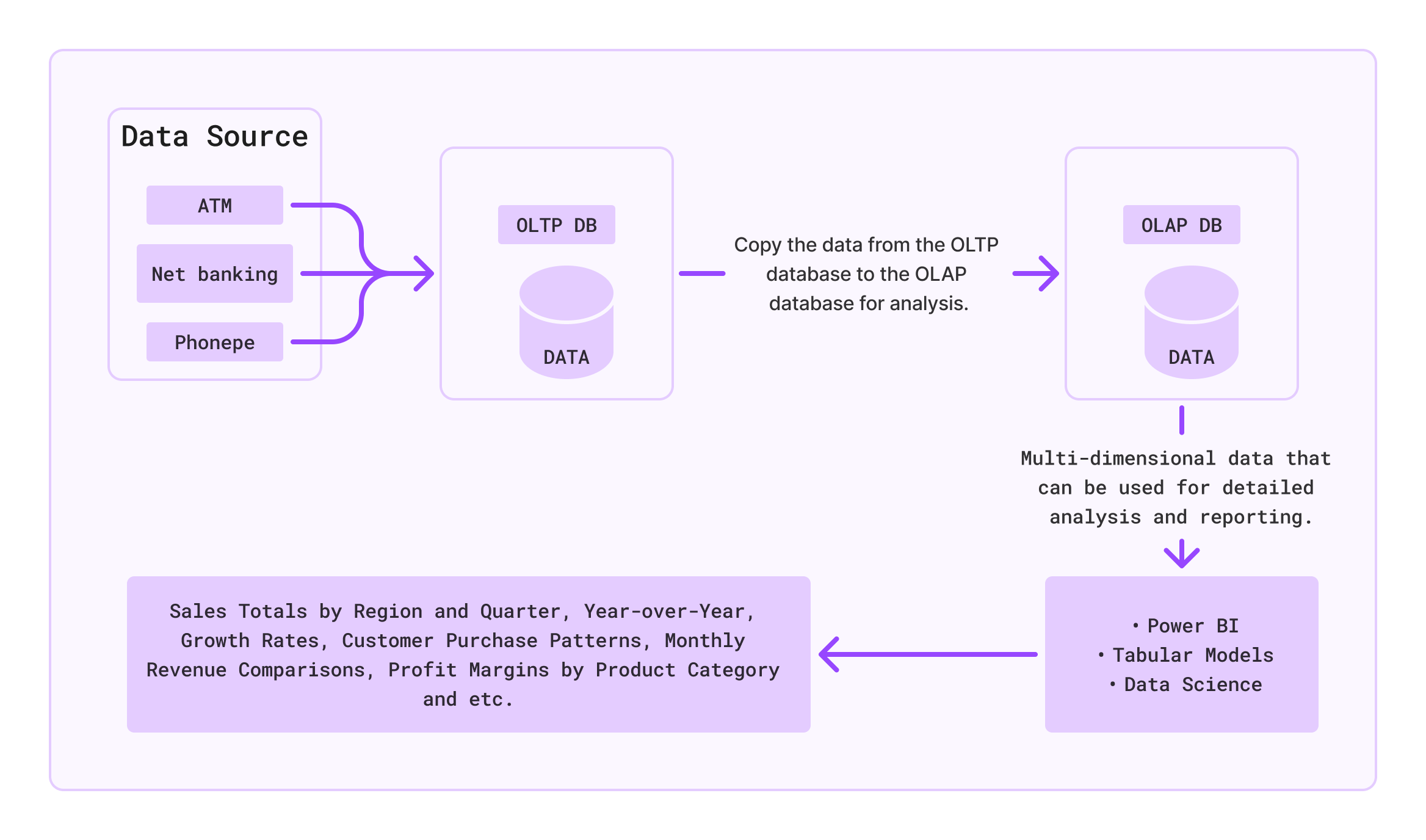
OLTP (Online Transaction Processing) Databases: Used for storing and managing day-to-day transactional data, where operations like Create, Read, Update, and Delete (CRUD) are performed regularly to support business operations.
OLAP (Online Analytical Processing) Databases: Used for analyzing large datasets to gain insights and make strategic decisions. Organizations use OLAP databases to perform complex queries and aggregations that help understand business trends and performance.
Short definition: OLTP databases handle operational tasks, while OLAP databases support analytical tasks by processing and analyzing data.
Difference between OLTP and OLAP databases:
| Feature | OLTP (Online Transaction Processing) | OLAP (Online Analytical Processing) |
| Purpose | Manages day-to-day transactions | Supports complex data analysis |
| Data Operations | CRUD (Create, Read, Update, Delete) | Read-heavy with complex queries |
| Data Volume | Large volume of small transactions | Large volume of historical data |
| Data Structure | Highly normalized | Denormalized with multi-dimensional schemas |
| Query Types | Simple, short queries | Complex queries for analysis |
| Performance | Optimized for transaction speed | Optimized for query performance |
| Examples | Banking systems, order entry | Data warehouses, business intelligence tools |
| User Types | Clerks, front-line workers | Analysts, managers, executives |
| Transaction Types | Short and frequent | Long and less frequent |
| Data Integrity | Critical | Less critical compared to OLTP |
| Response Time | Milliseconds to seconds | Seconds to minutes |
Organizations use OLTP for storing day-to-day transactions and OLAP for analysis.
OLTP systems are crucial for managing daily business operations, while OLAP systems are used to analyze business data for decision-making and planning.
Day-to-day operations on a database include:
C - Create
R - Read
U - Update
D - Delete
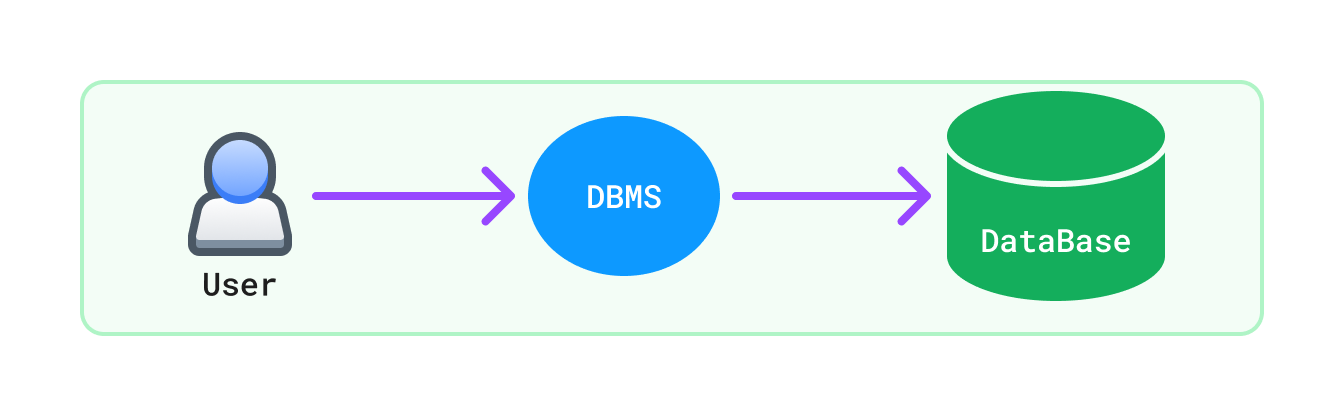
DBMS (Database Management System):
DBMS stands for Database Management System.
It is a software used to create, manage, and manipulate databases.
DBMS allows users to create, read, update, delete data.
DBMS is an inteface between user and database.
Evolution of DBMS:
| Decade | Database System Type | Database system data organizing form |
| 1960s | FMS (File Management System) | Organizing files in a storage medium. |
| 1970s | HDBMS (Hierarchical DBMS) | Organizes data in a tree-like, hierarchical structure. |
| NDBMS (Network DBMS) | Organizes data using a flexible, graph-like structure. | |
| 1980s | RDBMS (Relational DBMS) | Organizes data using tables to store data and allows for complex queries. |
| 1990s | ORDBMS (Object Relational DBMS) | Organizes data using integrates object-oriented features with relational databases. |
Types of DBMS
HDBMS
NDBMS
RDBMS
ORDBMS
RDBMS (Relational DBMS):
A Relational Database Management System (RDBMS) is a type of database management system that uses tables to store and manage data.
Introduced by E.F. Codd, the relational model organizes data into tables, which have rows and columns.
E.F. Codd introduced 12 rules, called Codd's rules, to define what a database management system needs to be a true relational database management system (RDBMS).
Codd's 12 Rules:
Information Rule: All data must be stored in tables, i.e., rows and columns.
Guaranteed Access Rule: Every piece of data should be easy to access without confusion.Every table must contain a primary key to uniquely identify the records.
Systematic Treatment of Null Values: Null values must be treated consistently and differently from actual data.
Dynamic Online Catalog Based on the Relational Model: The database catalog must be relational and accessible using SQL.
Comprehensive Data Sub-language Rule: The system must support at least one relational language with clear syntax and full functionality.
View Updating Rule: All views that can theoretically be updated must be updateable through the system.
High-Level Insert, Update, and Delete: The system must support set-based operations for data manipulation.
Physical Data Independence: Changes to how data is stored should not require changes to the application.
Logical Data Independence: Changes to table structures should not require changes to the application.
Integrity Independence: Integrity constraints must be definable in the relational language and stored in the catalog.
Distribution Independence: The system must work correctly regardless of data distribution.
Non-subversion Rule: Low-level access methods must not bypass integrity constraints.
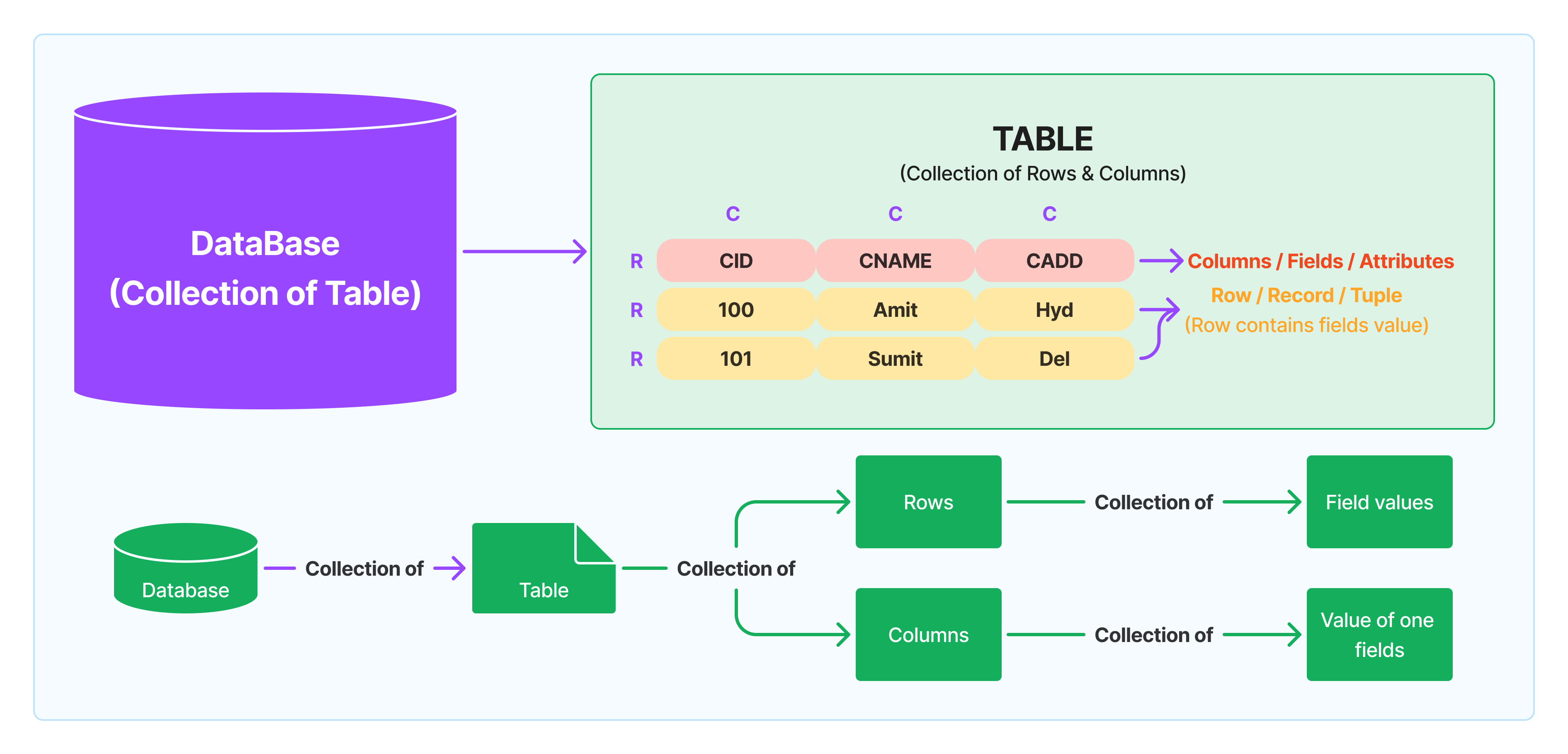
COLUMN: A collection of values assigned to one field.
RDBMS Features
Easy to access and manipulate data (CRUD).
Less redundancy (duplication of data).
More security guarantees data quality.
Supports data sharing (data accessible by multiple users).
Supports data integrity, i.e., data quality.
Supports transactions (ACID properties).
Atomicity: Ensures all operations in a transaction either complete successfully or none do.
Consistency: Guarantees that transactions move the database from one valid state to another.
Isolation: Ensures that transactions do not affect each other.
Durability: Ensures that committed transactions are permanently saved, even if the system fails.
RDBMS Software (SQL Databases)
SQL databases store data in a structured and organized format.
RDBMS Software is commonly known as SQL Databases because they use SQL to handle database operations.
ORACLE
- Vendor: Oracle Corporation
MySQL
- Vendor: Oracle Corporation
SQL SERVER
- Vendor: Microsoft
POSTGRESQL
- Vendor: PostgreSQL Global Development Group
RDS (Relational Database Service)
- Vendor: Amazon Web Services (AWS)
NoSQL Databases
NoSQL databases store data in an unstructured format.
MongoDB
cassandra
ORDBMS (Object Relational Database Management System)
Definition:
ORDBMS is a combination of RDBMS (Relational Database Management System) and OOP (Object-Oriented Programming).
It improves RDBMS by adding object-oriented features like reusability.
Key Points:
Combination: ORDBMS = RDBMS + OOP (Reusability, Security)
Reusability: RDBMS doesn't support reusability, but ORDBMS does.
User-Defined Types (UDT): ORDBMS supports reusability through UDTs (user-defined types).
Examples:
Oracle, SQL Server, PostgreSQL .
What is SQL Serve?
\=> SQL Server is an RDBMS software from Microsoft that also supports ORDBMS features. It is used to create and manage databases.
Database: SQL Server, MongoDB, Oracal, MySql are database.
Database Development Life Cycle
Analyze.
Requirements gathering and feasibility study.
Conceptual design using data modeling techniques.
Design.
Table Design: Developed by database designers or architects.
Techniques Used:
ER Model (Entity-Relationship Model)
Normalization
Develop.
Database is developed by Developer & DBA (Database Admin).
Developer: Responsible for creating database structures and application components.
DBA (Database Administrator): Oversees the installation, configuration, and maintenance of the database environment.
It is developed using only RDBMS tools like SQL Server.
| Role Developer | Role DBA |
| Creating tables | Installation of SQL Server |
| Creating views | Creating DBs |
| Creating synonyms | Creating logins |
| Creating sequence | DB backup & restore |
| Creating indexes | DB export & Import |
| Creating procedures | DB upgration and migration |
| Creating functions | Performance testion |
| Creating triggers | |
| Creating queries |
- Test.
- The database is tested by the QA (Quality Assurance) team using manual testing and automation tools like Selenium.
- Deploy / Implement.
Copying the database from the development server to the production server is called deployment or implementation.
After deployment, end users can use the database for day-to-day transactions.
- Maintenance.
- Ongoing support and optimization of the database system.
Access: Read, Write, and Use:

SQL Server
Definition: SQL Server is a RDBMS software developed by Microsoft that also supports ORDBMS features for creating and managing databases.
Usage: It is utilized for both database development and administration, making it suitable for both developers and database administrators (DBAs).
Versions:
| Version | Year |
| SQL Server 1.0 | 1989 |
| SQL Server 2017 | 2017 |
| SQL Server 2019 | 2019 |
| SQL Server 2022 | 2022 |
Client & Server Architecture:
Server :-
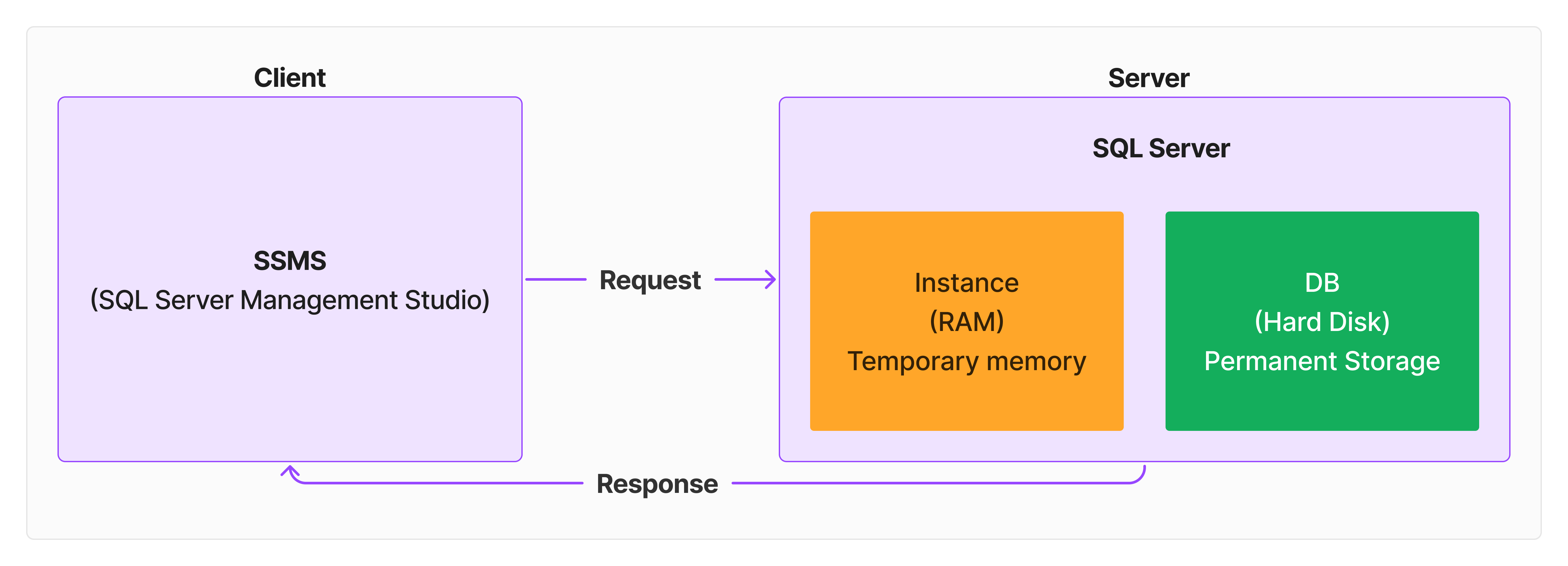
Definition server side: A system where SQL Server is installed and running.
Inside the server SQL server manages DB and Instance.
Server Components:
SQL Server:
- Manages databases (DB) and instances.
Database (DB):
- Created on the hard disk (HDD/SSD) and serves as permanent storage.
Instance:
- Runs in RAM and acts as temporary storage for processing and caching data. The instance is created in RAM and serves as temporary storage.
The database is created on the hard disk and serves as permanent storage.
Client :-
It is also a system from where user can connect to server, submit request and receives request.
Client Tool (SSMS):
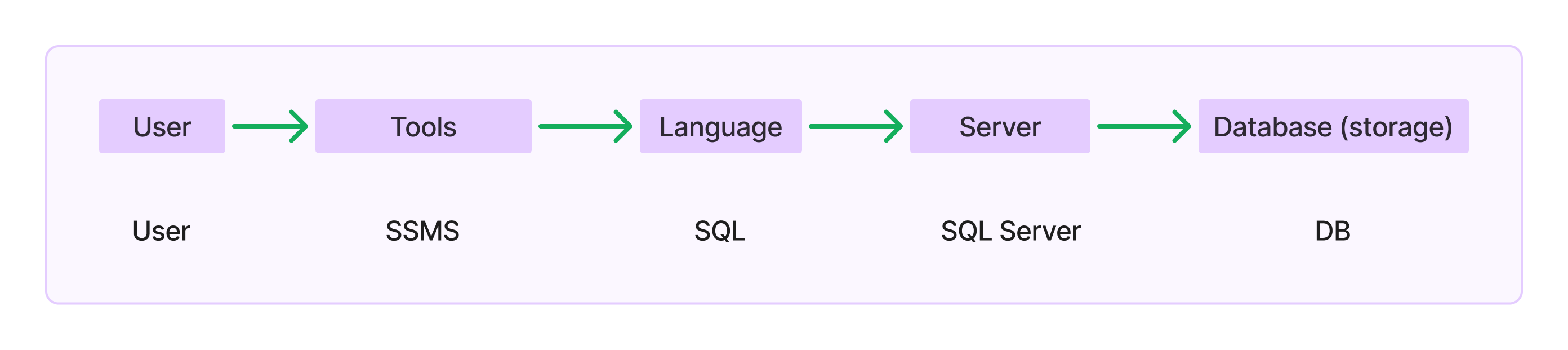
SSMS: SQL Server Management system.
SQL: Structure Query Language.
SQL Server: Database.
SQL (Structured Query Language):
Language Used to Communicate with SQL Server
Definition: Users talk to SQL Server by sending commands called queries.
Query: A command or question sent to SQL Server to do something with the database.
History and Commonality
Origin: SQL was first created by IBM and was originally called "SEQUEL" (Structured English Query Language). It was later renamed to SQL (Structured Query Language).
Commonality: SQL is used by all relational database management systems (RDBMS).
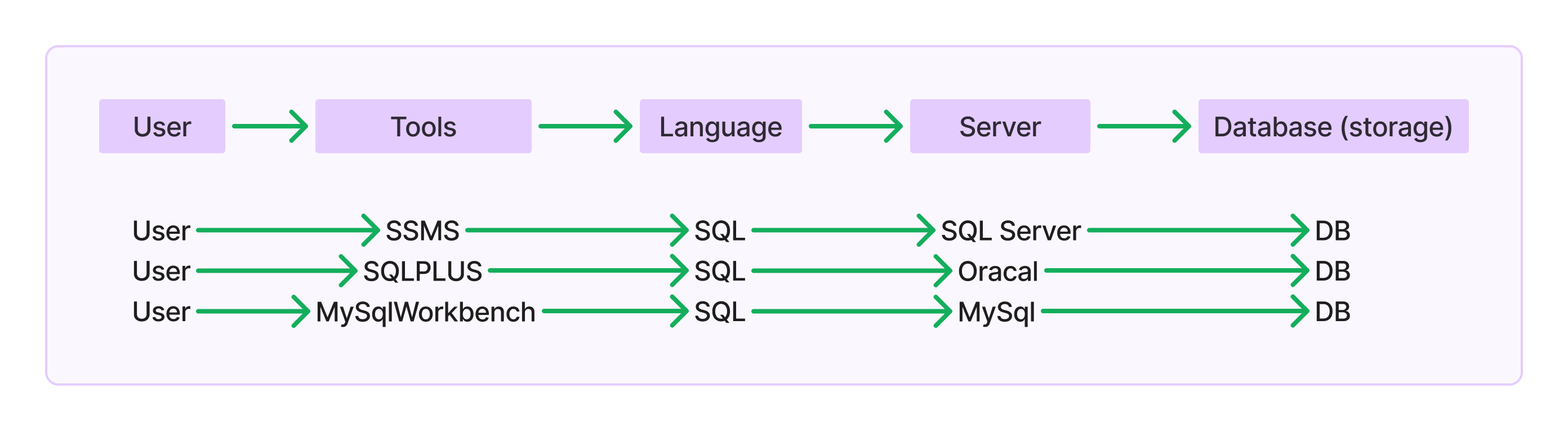
SQL Sub-languages
SQL has different sub-languages based on the operations performed on the database:
DDL (Data Definition Language):
Defines and manages database structures.
Examples:
CREATE,ALTER,DROP,truncate.
DML (Data Manipulation Language):
Manipulates data within the database.
Examples:
INSERT,UPDATE,DELETE,merge.
DQL (Data Query Language):
Queries and retrieves data from the database.
Example:
SELECT.
TCL (Transaction Control Language):
Manages transactions within the database.
Examples:
COMMIT,ROLLBACK,SAVEPOINT.
DCL (Data Control Language):
Controls access to data within the database.
Examples:
GRANT,REVOKE.
Data & Data Defination
Data refers to meaningful information stored in a database, while data definition involves specifying the structure and organization of this data.

Download :
Free version:
Download SQL Server here (SQL Server 2022 Developer is a full-featured free edition, licensed for development and testing in a non-production environment).
If you want to download a specific version, go here:
For SQL Server: https://www.microsoft.com/en-in/sql-server/sql-server-downloads
summary :-
what is db ?
what is dbms ?
what is rdbms ?
what is ordbms ?
db development life cycle ?
Create a new database:
Create a database: In the left-side
Object Explorer, right-click onDatabases, click onNew Database, enter the database name, select the path where you want to create the database or leave it as it is, and pressOK.Another way to create a database: In the left-side
Object Explorer, inside theObject Explorerclick onDatabases, inside theDatabasesclick onSystem Databases, inside theSystem Databasesright-click onmaster, click onNew Database.Write a query to create a new database.
Syntax: CREATE DATABASE <database name> Example: CREATE DATABASE TestWhen you create the database, two files are created: a DATA file and a LOG file.
DATA file
(Stores): Extension is MDF (Master data file).LOG file
(Stores commands/operations): Extension is LDF (Log data file).In the left-side Object Explorer, under
Databases, find your newly created database. Right-click on your database and selectNew Query.
Like creating a database name is Test .
SQL queries are not case-sensitive.
Datatype in SQL Server:
A datatype specifies what type of data allowed in a column.
Amount of memory allocates for column.
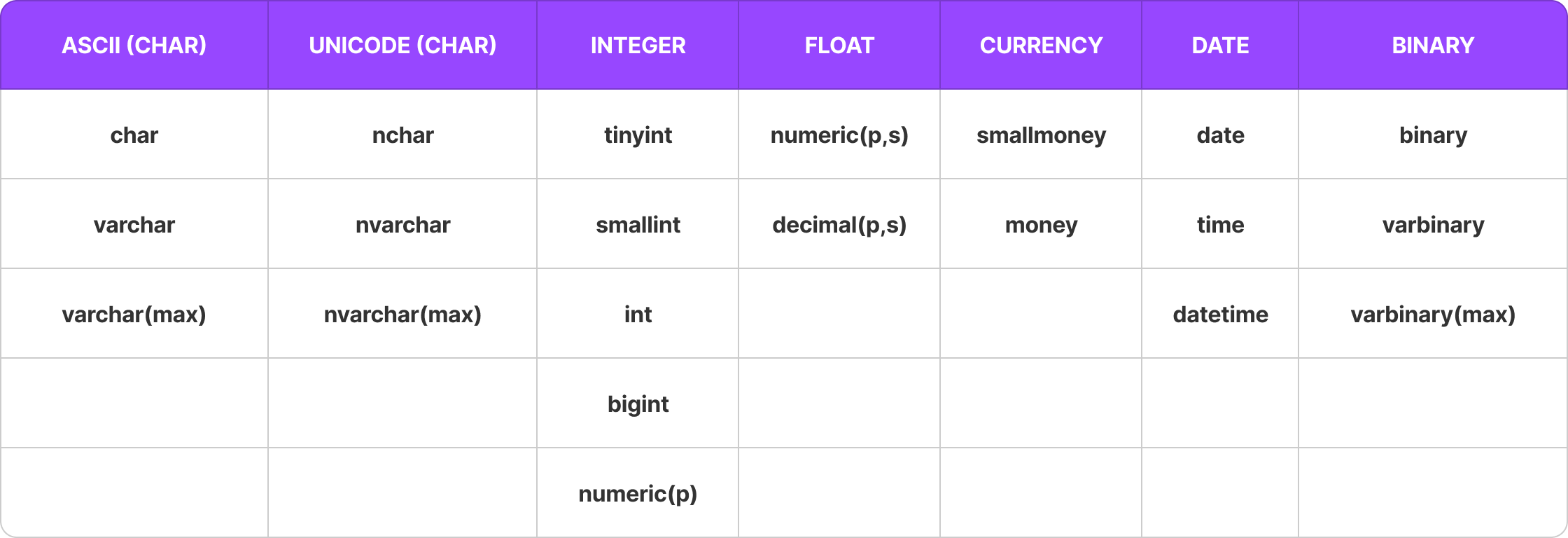
CHAR(size):
CHAR(size)allows character data up to 8000 characters.CHARis recommended for fixed-length character columns.Example: Suppose you define a column
NAME CHAR(10). If you store the name "SACHIN", the remaining characters will be padded with spaces:SACHIN(SACHIN followed by four spaces), resulting in memory waste.A good example of using
CHARis for storing gender.GENDER CHAR(1)will store either 'M' or 'F'.
Varchar(size):
Varchar(size)allows character data up to 8000 characters.Varcharis recommended for variable-length fields.Syntax:
VARCHAR(n)wherenis max length.Example: Suppose you define a column
NAME Varchar(10). If you store the name "SACHIN", only the six characters "SACHIN" will be stored without any extra spaces.
Varchar(max):
Allows character data upto 2GB.
Syntax:
VARCHAR(MAX).
NOTS:
CHAR, VARCHAR, and VARCHAR(MAX) can store standard ASCII characters (like letters a-z, A-Z, numbers 0-9, and basic special characters) and Extended ASCII characters (like accented letters and more special symbols).
However, they cannot store all characters from different languages (like Chinese or Arabic) because they do not fully support Unicode. For storing characters from many languages, you should use NCHAR, NVARCHAR, or NVARCHAR(MAX).
/*Example:-*/ panno char(10) vehno char(10) emailid varchar(20) pwd varchar(10) about varchar(max)
Difference between CHAR(size), VARCHAR(size), and VARCHAR(MAX):
| Aspect | CHAR(size) | VARCHAR(size) | VARCHAR(MAX) |
| Length | Fixed | Variable | Variable |
| Maximum Length | Up to 8000 characters | Up to 8000 characters | Up to 2^31-1 bytes (approx. 2 GB) |
| Storage | Fixed, always uses the specified size | Variable, uses only the required space | Variable, designed for very large data |
| Usage | Fixed-length data | Variable-length data | Very large text data |
| Performance | Efficient for fixed-length data | Efficient for variable-length data | Optimized for large data, less efficient for small texts |
| Memory west | Memory west | No memory west | No memory west |
| Syntax | CHAR(n) | VARCHAR(n) | VARCHAR(MAX) |
NCHAR / NVARCHAR / NVARCHAR(MAX):
Allows unicode chars (65536 chars) that includes all ascii chars and chars belongs to different languages.
Difference between NCHAR(size), NVARCHAR(size), and NVARCHAR(MAX):
| Aspect | NCHAR(n) | NVARCHAR(n) | NVARCHAR(MAX) |
| Definition | Fixed-length Unicode string | Variable-length Unicode string | Variable-length large Unicode string |
| Maximum Length | Up to 4000 characters | Up to 4000 characters | Up to 2^31-1 bytes (approx. 2 GB) |
| Usage | Fixed-length data | Variable-length data | Very large text data |
| Storage | 2 bytes per character (fixed) | 2 bytes per character (variable) | 2 bytes per character (variable) |
| Syntax | NCHAR(n) | NVARCHAR(n) | NVARCHAR(MAX) |
| Example | NCHAR(50) | NVARCHAR(100) | NVARCHAR(MAX) |
| Performance | Efficient for fixed-length data | Efficient for smaller variable-length data | Suitable for large text storage |
INTEGER:
- Allows numbers without decimal (integers).
Differences betweenTINYINT,SMALLINT,INTandBIGINTin SQL Server
| Type | Use Case | Storage Size | Range | Example | Example Explanation |
| TINYINT | Small numbers, counters, flags | 1 byte | 0 to 255 | AgeGroup TINYINT | AgeGroup values: 0 (children), 1(teenagers), 2 (adults), 3 (seniors) |
| SMALLINT | Small-range integers, age, scores | 2 bytes | -32,768 to 32,767 | QuantityOnHand SMALLINT | Quantity ranges from 0 to 32,767 |
| INT | General-purpose integers, primary keys | 4 bytes | -2,147,483,648 to 2,147,483,647 | EmployeeID INT | For id |
| BIGINT | Very large integers, large counters, large monetary values | 8 bytes | -9,223,372,036,854,775,808 to 9,223,372,036,854,775,807 | TransactionID BIGINT | Large unique identifier for each transaction |
| Numeric(p) | Exact numeric data, monetary values, scientific calculations | 5 to 17 bytes | Varies based on precision (p) | empid NUMERIC(4) | 4 is the number of digits (10 - ok,100 - ok, 1000 - ok, 10000 - not ok) |
Example: AGE TINYINT and EMPID SMALLINT .
FLOAT:
Numeric(p):
Allows numbers without decimal upto 38 digits.
Example:
empid NUMERIC(4) /*4 is the number of digits 10 - ok 100 - ok 1000 - ok 10000 - not ok */ phone NUMBERIC(10) aadharno Numeric(12)
Numeric(p,s) / Decimal(p,s):
Allows numbers with decimals (float).
p => precision => total number of digits allowed.
s => scale => number of digits allowed after the decimal.
Example:-
salary Numeric(7,2);--Total number of digit is 7 salary Decimal(7,2); /*5000 - ok 5000.55 - ok 50000.55 - ok 500000.55 - not ok 5000.5689 - ok because roundof 5000.5689n convert to 5000.57 */No difference between Decimal(p,s) and Numeric(p,s).
| Feature | NUMERIC(p, s) or DECIMAL(p, s) |
| Definition | Fixed-point number |
| Precision (p) | Total number of digits |
| Scale (s) | Number of digits to the right of the decimal point |
| Functionality | Identical to DECIMAL(p, s) |
| Storage and Performance | Identical to DECIMAL(p, s) |
| Usage | Interchangeable with DECIMAL(p, s) |
| Common Use Case | Financial and quantitative data |
| SQL Standard | Part of SQL standard |
| Example Usage | NUMERIC(10, 2) |
Currency:
Currency types are used for fields related to money.
Example:
salary SMALLMONEY /*add when creating table*/ balance MONEY /*add when creating table*/
Differences betweenSMALLMONEYandMONEYin SQL Server:
| Aspect | SMALLMONEY | MONEY |
| Storage Size | 4 bytes | 8 bytes |
| Range | -214,748.3648 to 214,748.3647 | -922,337,203,685,477.5808 to 922,337,203,685,477.5807 |
| Precision | Fixed, 4 decimal places | Fixed, 4 decimal places |
| Usage | Suitable for small monetary values | Suitable for large monetary values |
| Performance | More efficient due to smaller storage size | Less efficient compared to SMALLMONEY due to larger storage size |
| Example | SmallAmount SMALLMONEY | LargeAmount MONEY |
| Use Case | Storing prices of everyday items (e.g., groceries) | Storing large financial values (e.g., bank balances) |
DATA:
DATE => allows only dates
TIME => allows only times
DATETIME => allows both date and time
The default date format in SQL Server is yyyy-mm-dd.
The default time format is hh:mi:ss.
Example:
dob DATE /*add when creating table*/ /*2003-03-10 is formate*/
login TIME /*add when creating table*/ /*9:30:00 is formate*/
signup DATETIME /*add when creating table*/ /*2023-09-13 10:00:00 is formate*/
Creating Tables in SQL Server:
- Right-click on the database and click on
New query.
Syntax:
CREATE TABLE <TableName>(
field1 datatype(size),
field2 datatype(size),
---------------------,
---------------------
);
Example:
This example is only to show how to use all data types in a table.
--Create emp database using: CREATE DATABASE emp
CREATE TABLE new_emp
(
Gender CHAR(1),
FullName VARCHAR(100),
AboutUs VARCHAR(MAX),
FirstName NCHAR(50),
LastName NCHAR(50),
ProductName NVARCHAR(100),
AboutProduct NVARCHAR(MAX),
AgeGroup TINYINT,
QuantityOnHand SMALLINT,
EmployeeID INT,
TransactionID BIGINT,
MonthlySalary NUMERIC(4, 2),
Incentive SMALLMONEY,
Package MONEY,
JoiningDate DATE,
OfficeComingTime TIME,
DOB DATETIME
);
Rules:
The name must start with an alphabet.
The name cannot contain spaces or special characters, but can include
_,#, and$.The name can be up to 128 characters long.
A table can have up to 1024 columns.
The number of rows is unlimited.
Examples:
123emp- Invalid (starts with a number)emp 123- Invalid (contains a space)emp*123- Invalid (contains a special character*)emp_123- Valid (follows all rules)
CREATE TABLE emp_123
(
EmpID INT,
EmpName VARCHAR(10),
Job VARCHAR(10),
EmpSalary MONEY,
HireDate DATE,
Age TINYINT,
Gender CHAR(1)
);
The above command created the table structure, definition, and metadata, which includes columns, data types, and sizes.
SP_HELPcommand:
SP_HELP: Stored Procedure for Table Structure.
Definition:
SP_HELPis a system stored procedure that provides information about the structure of a specified table, including its columns, data types, and other relevant details.Syntax:
SP_HELP <tablename>Example:
SP_HELP empOutput Example: When you run
SP_HELP emp, you might see an output like:
Column Name Data Type Length
-------------------------------------
EMPID tinyint 1
ENAME varchar 10
JOB varchar 10
SAL smallmoney 4
HIREDATE date 3
AGE tinyint 1
GENDER char 1
Explanation of Output:
Column Name: The name of each column in the table.
Data Type: The data type of each column (e.g.,
tinyint,varchar,smallmoney, etc.).Length: The maximum storage size for that column (e.g., the length of
varchartypes).
Inserting Data into the Table:
The "INSERT" command is used to add data to a table.
We can insert a single row or multiple rows.
To insert data into our table, we use the
INSERT INTOstatement followed by the table name and the values we want to add.
Inserting Single Row Data into the table:
Syntax:
INSERT INTO <tabname> VALUES(v1,v2,v3,-,-,-,-,-);
Example:
INSERT INTO emp VALUES (1, 'John Doe', 'Manager', 50000, '2023-01-15', 35, 'M');
Inserting Multiple Row Data into the table:
Syntax:
INSERT INTO <tabname> VALUES(v1,v2,v3,-,-,-,-,-), (v1,v2,v3,-,-,-,-,-);
Example:
INSERT INTO emp VALUES (1, 'John Doe', 'Manager', 50000, '2023-01-15', 35, 'M'),
(2, 'Dev Doe', 'Sub Manager', 30000, '2023-01-15', 35, 'M');
Inserting Null Value:
A null means blank or empty, and it is not equal to 0 or space.
Nulls can be inserted in two ways.
By Explicit:
INSERT INTO emp VALUES(104,'ravi',null,null,'2018-02-12',25,'m');
By Implicit:
INSERT INTO emp(empid,ename,hiredate,age,gender)
VALUES(105,'sindhu',getdate(),30,'f');
Remaining two fields job, sal are filled with nulls.
Operators in SQL Server:
Arithmetic Operators:
+,-,*,/,%.Relational Operators:
>,>=,<,<=,=,<>.Logical Operators:
AND,OR,NOTSpecial Operators:
BETWEEN,IN,LIKE,IS,ANY,ALL,EXISTS,PIVOT.Set Operators:
UNION,UNION ALL,INTERSECT,EXCEPT.
Displaying Data:
The SELECT command is used to display data from a table.
We can display all rows and all columns.
We can display specific rows and columns.
Syntax:
SELECT columns FROM tabname; -- Use to select the particular columns
--or
SELECT * FROM tabname; -- Use to select the all columns
SQL is like English.
Queries are like sentences.
Clauses are like words.
Examples:
Display all the data from the EMP table.
SELECT * FROM EMP;
*means all columns.
Display employee names and salaries.
SELECT ENAME, SAL FROM EMP;
EXAMPLES:
Create database name is SawMill:
CREATE DATABASE SawMill;Create Table name is Emp:
CREATE TABLE Emp ( Id SMALLINT, FullName VARCHAR(100), Qualification VARCHAR(50), Gender CHAR(1), Salary NUMERIC(5,2), Discription VARCHAR(MAX) );Show Table Structure:
SP_HELP Emp;Insert Single Row Data into Table:
INSERT INTO Emp VALUES (101, 'Mritunjay Kumar', 'BCA', 'M', 500.75, 'Hello');Insert Multiple Row Data into Table:
INSERT INTO Emp VALUES (102, 'Mritunjay Kumar', 'BCA', 'M', 500.75, 'Hello'), (103, 'Awnish Kumar', 'BCA', 'M', 300.75, 'Hello');Insert Null value in Table:
INSERT INTO Emp VALUES (104, 'Amit Kumar', 'BCA', 'M', Null, Null); /*OR*/ INSERT INTO Emp(Id, FullName, Qualification, Gender) VALUES (105, 'Amit Kumar', 'BCA', 'M');Display all the data:
SELECT * FROM Emp;Display particular data:
SELECT FullName, Qualification, Salary FROM Emp;
WHERE Clause:
Where clause is used to get specific rows from table based on a condition.
The
WHEREclause is used to filter records that match certain conditions. It helps to get specific rows from a table based on a given condition.Syntax:
SELECT columns FROM tabname WHERE <condition>;Conditions: The condition typically follows the format.
COLNAME OP VALUECOLNAME: The column name to apply the condition to.OP: A relational operator (e.g.,>,>=,<,<=,=,<>).VALUE: The value to compare against.Examples:
-- Display employee details whose empid = 103 ? SELECT * FROM EMP WHERE EMPID = 103; -- Or -- Display employee details whose name = ravi ? SELECT * FROM EMP WHERE ENAME = 'ravi'; -- Or -- Display employee details earning more than 5000 ? SELECT * FROM EMP WHERE SAL > 5000; --Or -- Employees joined after 2020 ? SELECT * FROM EMP WHERE HIREDATE > '2020-12-31'; --Or -- Employees joined befor 2020 ? SELECT * FROM EMP WHERE HIREDATE < '2020-12-31';
WHERE Clause Compound Condition:
- A compound condition involves multiple conditions combined using
ANDandORoperators.
AND Operator:
Both conditions must be true for the result to be true.
Truth table for
AND:codecond1 | cond2 | RESULT ------------------------ T | T | T T | F | F F | T | F F | F | F
OR Operator:
At least one condition must be true for the result to be true.
Truth table for
OR:codecond1 | cond2 | RESULT ------------------------ T | T | T T | F | T F | T | T F | F | F
Examples of Compound Conditions:
Example 01:-
-- Employees working as clerk or manager:
SELECT *
FROM EMP
WHERE JOB = 'CLERK' OR JOB = 'MANAGER';
-- Or
-- Employees whose id is 100 or 103:
SELECT *
FROM EMP
WHERE EMPID = 100 OR EMPID = 103;
-- Or
-- Display male employees older than 30:
SELECT *
FROM EMP
WHERE GENDER = 'M' AND AGE > 30;
-- Or
-- Employees who joined in the year 2020:
SELECT *
FROM EMP
WHERE HIREDATE >= '2020-01-01' AND HIREDATE <= '2020-12-31';
-- Or
-- Employees earning more than 5000 and less than 10000:
SELECT *
FROM EMP
WHERE SAL > 5000 AND SAL < 10000;
Example 02:-
-- Table structure
CREATE TABLE STUDENT
(
SID INT,
SNAME VARCHAR(10),
S1 TINYINT,
S2 TINYINT,
S3 TINYINT
);
-- Insert sample data
INSERT INTO STUDENT VALUES (1, 'A', 80, 90, 70), (2, 'B', 30, 60, 50);
-- List of students who passed all subjects
SELECT *
FROM STUDENT
WHERE S1 >= 35 AND S2 >= 35 AND S3 >= 35;
-- List of students who failed in at least one subject
SELECT *
FROM STUDENT
WHERE S1 < 35 OR S2 < 35 OR S3 < 35;
IN operator :
Use the IN operator for list comparison. Use the IN operator for "=" comparison with multiple values.
The IN operator is used for list comparisons, allowing for a cleaner and more readable way to check if a value matches any value in a list.
Usage:
Invalid syntax using
=for multiple values:WHERE COLNAME = V1, V2, V3, -- => INVALIDValid syntax using
INfor multiple values:WHERE COLNAME IN (V1, V2, V3, ...) -- => VALID
Examples of Using the IN Operator:
Employees whose id is 100, 103, or 105:
SELECT * FROM EMP WHERE EMPID IN (100, 103, 105);Employees working as a clerk, manager, or analyst:
SELECT * FROM EMP WHERE JOB IN ('CLERK', 'MANAGER', 'ANALYST');Employees not working as a clerk or manager:
SELECT * FROM EMP WHERE JOB NOT IN ('CLERK', 'MANAGER');
Using the IN operator simplifies the query and makes it easier to read and maintain.
BETWEEN Operator in SQL:
The BETWEEN operator is used for range comparisons, allowing you to select values within a given range.
Usage:
WHERE COLNAME BETWEEN V1 AND V2
Examples of Using the BETWEEN Operator:
- Employees earning between 5000 and 10000:
SELECT * FROM EMP
WHERE SAL BETWEEN 5000 AND 10000;
What happens when you use
BETWEENwith the range in reverse?SELECT * FROM EMP WHERE HIREDATE NOT BETWEEN '2020-01-01' AND '2020-12-31';Question:
What happens when you use
BETWEENwith the range in reverse?SELECT * FROM EMP WHERE SAL BETWEEN 10000 AND 5000;Options:
A: ERROR
B: RETURNS ROWS
C: RETURNS NO ROWS
D: NONE
Answer: The correct answer is C: RETURNS NO ROWS, because
BETWEEN 10000 AND 5000is logically equivalent to(SAL >= 10000 AND SAL <= 5000), which will not match any rows.Correct usage for employees earning between 5000 and 10000:
WHERE SAL BETWEEN 5000 AND 10000 -- (SAL >= 5000 AND SAL <= 10000) WHERE SAL BETWEEN 10000 AND 5000 --(SAL>=10000 AND SAL<=5000)Employees list working as clerk or manager, earning between 5000 and 10000, joined in 2023, and gender must be male:
SELECT * FROM EMP WHERE JOB IN ('CLERK', 'MANAGER') AND SAL BETWEEN 5000 AND 10000 AND HIREDATE BETWEEN '2023-01-01' AND '2023-12-31' AND GENDER = 'M';List of Samsung and Realme mobile phones priced between 10000 and 20000:
SELECT * FROM PRODUCTS WHERE BRAND IN ('SAMSUNG', 'REALME') AND CATEGORY = 'MOBILES' AND PRICE BETWEEN 10000 AND 20000;
Note:
- Use the
BETWEENoperator with the lower value first and the upper value second to ensure correct results.
LIKE Operator in SQL:
The LIKE operator is used for pattern matching in SQL. It allows you to search for a specified pattern in a column.
Wildcard Characters:
%: Represents zero or more characters_: Represents a single character
Examples of Using the LIKE Operator:
Employees whose name starts with 's':
SELECT * FROM EMP WHERE ENAME LIKE 's%';Employees whose names end with 'd':
SELECT * FROM EMP WHERE ENAME LIKE '%d';Employees whose name contains 'a':
SELECT * FROM EMP WHERE ENAME LIKE '%a%';Employees where 'a' is the 2nd character in their name:
SELECT * FROM EMP WHERE ENAME LIKE '_a%';'a' is the 3rd character from the last:
SELECT * FROM EMP WHERE ENAME LIKE '%a__';Names containing exactly 4 characters:
SELECT * FROM EMP WHERE ENAME LIKE '____';Names starting with 'a', 'r', or 'v':
SELECT * FROM EMP WHERE ENAME LIKE '[arv]%';Names starting between 'a' and 'p':
SELECT * FROM EMP WHERE ENAME LIKE '[a-p]%';Employees who joined in October (yyyy-mm-dd):
SELECT * FROM EMP WHERE HIREDATE LIKE '_____10___';Employees who joined in the year 2020:
SELECT * FROM EMP WHERE HIREDATE LIKE '2020%';Names containing an underscore (
_):SELECT * FROM CUST WHERE CNAME LIKE '%_%';Names containing a literal underscore (
_), using escape character:SELECT * FROM CUST WHERE CNAME LIKE '%\_%' ESCAPE '\';Names containing a percent sign (
%), using escape character:SELECT * FROM CUST WHERE CNAME LIKE '%\%%' ESCAPE '\';Names containing two underscores (
__), using escape character:SELECT * FROM CUST WHERE CNAME LIKE '%\_%\_%' ESCAPE '\';
IS Operato:
The IS operator is used to compare a column's value with NULL. To check for NULL values, use IS NULL and IS NOT NULL.
To find rows where a column has no value (NULL), use IS NULL.
To find employees who are not earning a salary
:SELECT * FROM EMP WHERE SAL IS NULL;To find rows where a column has a value (is not NULL), use IS NOT NULL.
To find employees who are earning a salary:
SELECT * FROM EMP WHERE SAL IS NOT NULL;
Practice questions 01:
Q1. Create Database and Emp table.
CREATE DATABASE Tcs;Q2. Insert this data (101, 'John', 'Manager', 75000, '2020-01-15', 45, 'M').
Q3. Insert this data (102, 'Jane', 'Analyst', 60000, '2019-03-12', 34, 'F'), (103, 'Mike', 'Clerk', 35000, '2018-07-23', 28, 'M')
Q4. Insert this data also
:(104, 'Linda', 'Manager', 85000, '2021-05-01', 39, 'F'), (105, 'James', 'Analyst', 62000, '2017-09-30', 29, 'M'), (106, 'Emily', 'Clerk', 36000, '2020-11-18', 26, 'F'), (107, 'Chris', 'Analyst', 64000, '2019-12-25', 31, 'M'), (108, 'Anna', 'Manager', 82000, '2022-01-11', 42, 'F')Q5. Display all employee details.
SELECT FROM EMP;Q6. List the names and job titles of all employees.
SELECT ENAME, JOB FROM EMP;Q7. Find the employees who are managers.
SELECT FROM EMP WHERE JOB = 'Manager';Q8. Show the details of employees earning more than 60,000.
SELECT FROM EMP WHERE SAL > 60000;Q9. Retrieve the names and salaries of employees whose salary is between 35,000 and 75,000.
SELECT ENAME, SAL FROM EMP WHERE SAL BETWEEN 35000 AND 75000;Q10. Find the names of employees who joined after January 1, 2020.
SELECT ENAME FROM EMP WHERE HIREDATE > '2020-01-01';Q11. List the details of male employees.
SELECT FROM EMP WHERE GENDER = 'M';Q12. Find the employees whose names start with 'J'.
SELECT FROM EMP WHERE ENAME LIKE 'J%';Q13. Show the details of employees who are either Analysts or Clerks.
SELECT FROM EMP WHERE JOB IN ('Analyst', 'Clerk');Q14. List the names and ages of employees who are older than 30.
SELECT ENAME, AGE FROM EMP WHERE AGE > 30;Q15. Find the employees who were hired in the year 2020.
SELECT FROM EMP WHERE HIREDATE BETWEEN '2020-01-01' AND '2020-12-31';Q16. Display the details of employees earning exactly 62,000.
SELECT FROM EMP WHERE SAL = 62000;Q17. Find the female employees working as Managers.
SELECT FROM EMP WHERE GENDER = 'F' AND JOB = 'Manager';Q18. List the names of employees who have 'a' as the second character in their names.
SELECT ENAME FROM EMP WHERE ENAME LIKE '_a%';Q19. Show the details of employees who are earning more than 35,000 but less than 65,000.
SELECT FROM EMP WHERE SAL > 35000 AND SAL < 65000;Q20. Retrieve the details of employees who joined before July 1, 2020.
SELECT FROM EMP WHERE HIREDATE < '2020-07-01';Q21. Find the employees whose job title is either 'Manager' or 'Analyst' and their age is greater than 30.
SELECT FROM EMP WHERE JOB IN ('Manager', 'Analyst') AND AGE > 30;Q21. List the employees' names and hire dates who were hired in the month of December.
SELECT ENAME, HIREDATE FROM EMP WHERE HIREDATE LIKE '-12-%';Q22. Show the details of employees whose salary is not between 35,000 and 70,000.
SELECT FROM EMP WHERE SAL NOT BETWEEN 35000 AND 70000;Q22. Find the employees who were hired in 2021 or 2022.
SELECT FROM EMP WHERE HIREDATE LIKE '2021%' OR HIREDATE LIKE '2022%';Q23. Find the employees whose names contain at least one digit.
SELECT FROM EMP WHERE ENAME LIKE '%[0-9]%';Q24. List the employees whose job title is 'Analyst' and their age is not between 30 and 40.
SELECT FROM EMP WHERE JOB = 'Analyst' AND (AGE < 30 OR AGE > 40);Q23. Show the details of employees who were hired in the second quarter of any year (April to June).
SELECT * FROM EMP WHERE HIREDATE LIKE '-04-%' OR HIREDATE LIKE '-05-%' OR HIREDATE LIKE '-06-%';Q24. Find the employees whose names start with a vowel (A, E, I, O, U).
SELECT FROM EMP WHERE ENAME LIKE '[AEIOU]%';Q25. Show the details of employees who joined in either January, February, or March of any year.
SELECT FROM EMP WHERE HIREDATE LIKE '-01-%' OR HIREDATE LIKE '-02-%' OR HIREDATE LIKE '__-03-%';Q26. Find the employees whose job titles do not start with 'A' or 'C'.
SELECT FROM EMP WHERE JOB NOT LIKE 'A%' AND JOB NOT LIKE 'C%';Q27. Find the employees who not earning Salary?
Select from emp where Sal is NULL;Q28. Find the employees who earning Salary?
Select * from emp where Sal IS NOT NULL;
ALIAS:
Alias means temporary name another name or alternative name. Used to change column heading.
Syntax:
SELECT column_name AS alias_name FROM table_name;
column_name: The original name of the column or expression.
alias_name: The new name for the column in the query results.
Displaying Employee Names and Annual Salaries:
SELECT ENAME, SAL * 12 AS ANNSAL FROM EMP;Aliases can be enclosed in double quotes if they contain spaces or special characters.
SELECT ENAME, SAL * 12 AS "ANNUAL SAL" FROM EMP;You can use the calculated column in the
WHEREclause for filtering:SELECT *, SAL * 12 AS ANNSAL FROM EMP WHERE SAL * 12 > 60000;Calculating and Displaying Multiple Columns:
SELECT ENAME, SAL, SAL * 0.2 AS HRA, -- House Rent Allowance (20% of SAL) SAL * 0.3 AS DA, -- Dearness Allowance (30% of SAL) SAL * 0.1 AS TAX, -- Tax (10% of SAL) SAL + (SAL * 0.2) + (SAL * 0.3) - (SAL * 0.1) AS TOTSAL -- Total Salary FROM EMP;Handling NULL Values with NVL Function:
NVL(COMM, 0)replacesNULLwith0.SELECT ENAME, SAL, COMM, SAL + NVL(COMM, 0) AS TOTSAL FROM EMP;Use
NVLor equivalent function to handleNULLvalues in calculations.Displaying Total and Average Scores:
SELECT SID, S1 + S2 + S3 AS TOTAL, (S1 + S2 + S3) / 3 AS AVG FROM STUDENT;| SNO | SNAME | S1 | S2 | S3 | | --- | --- | --- | --- | --- | | 1 | A | 80 | 90 | 70 | | 2 | B | 30 | 60 | 50 |
ORDER BY Clause
The ORDER BY clause is used to sort the table based on one or more columns, either in ascending (ASC) or descending (DESC) order. By default, the sorting order is ascending if not specified.
Syntax:
SELECT columns
FROM table_name
[WHERE condition]
ORDER BY column1 [ASC|DESC], column2 [ASC|DESC], ...;
Example:
Arranging Employees by Name in Ascending Order:
SELECT * FROM EMP ORDER BY ENAME ASC;Arranging Employees by Salary in Descending Order:
SELECT * FROM EMP ORDER BY SAL DESC;Arranging Employees by Department (Ascending) and Within Department by Salary (Descending):
SELECT EMPNO, ENAME, SAL, DEPTNO FROM EMP ORDER BY DEPTNO ASC, SAL DESC;Breakdown of Sorting Process:
First Level of Sorting (DEPTNO ASC): The database will first sort all employees by the
DEPTNOcolumn in ascending order.Second Level of Sorting (SAL DESC): Within each department (group of rows with the same
DEPTNO), the database will then sort the rows by theSALcolumn in descending order.
Example Data Before Sorting
| EMPNO | ENAME | SAL | DEPTNO |
| 1 | A | 3000 | 20 |
| 2 | B | 5000 | 10 |
| 3 | C | 4000 | 30 |
| 4 | D | 5000 | 20 |
| 5 | E | 6000 | 10 |
Example Data After Sorting
| EMPNO | ENAME | SAL | DEPTNO |
| 5 | E | 6000 | 10 |
| 2 | B | 5000 | 10 |
| 4 | D | 5000 | 20 |
| 1 | A | 3000 | 20 |
| 3 | C | 4000 | 30 |
Arranging Employees by Department and Within Department by Hire Date in Ascending Order:
SELECT EMPNO, ENAME, HIREDATE, DEPTNO FROM EMP ORDER BY DEPTNO ASC, HIREDATE ASC;Arranging Students by Average Score in Descending Order, then by Marks in M and P:
SELECT SNO, SNAME, M, P, C, (M + P + C) / 3 AS AVG FROM STUDENT ORDER BY AVG DESC, M DESC, P DESC;| SNO | SNAME | M | P | C | AVG | | --- | --- | --- | --- | --- | --- | | 3 | C | 90 | 80 | 70 | 80 | | 4 | D | 90 | 70 | 80 | 80 | | 1 | A | 80 | 90 | 70 | 80 | | 2 | B | 60 | 70 | 50 | 60 |
Arranging Employees Working as Clerk or Manager by Salary in Descending Order:
SELECT EMPNO, ENAME, JOB, SAL FROM EMP WHERE JOB IN ('CLERK', 'MANAGER') ORDER BY SAL DESC;
NOTES:
The
ORDER BYclause can include multiple columns for sorting.Sorting in SQL is case-sensitive and may vary depending on the database system's collation settings.
Order of execution:
Aliases cannot be used in the WHERE clause because the WHERE clause is executed before SELECT.
Aliases can be used in the ORDER BY clause because the ORDER BY clause is executed after SELECT.
DISTINCT Clause:
The DISTINCT clause is used in a SELECT statement to remove duplicate rows from the result set. It ensures that each returned row is unique based on the columns specified in the query.
Syntax:
SELECT DISTINCT column1, column2, ...
FROM table_name;
Example:
| DEPTNO | JOB |
| 10 | CLERK |
| 20 | SALESMAN |
| 30 | ANALYST |
| 10 | MANAGER |
| 30 | CLERK |
| 20 | PRESIDENT |
| 10 | MANAGER |
| 30 | SALESMAN |
| 20 | CLERK |
| 10 | CLERK |
Selecting Distinct Job Titles from the Employee Table:
SELECT DISTINCT JOB FROM EMP;| JOB | | --- | | ANALYST | | CLERK | | MANAGER | | PRESIDENT | | SALESMAN |
Selecting Distinct Department Numbers from the Employee Table:
SELECT DISTINCT DEPTNO FROM EMP;Selecting Distinct Combinations of Department Number and Job Title
SELECT DISTINCT DEPTNO, JOB FROM EMP;- | DEPTNO | JOB | | --- | --- | | 10 | CLERK | | 10 | MANAGER | | 10 | PRESIDENT | | 20 | ANALYST | | 20 | CLERK | | 20 | MANAGER | | 30 | CLERK | | 30 | MANAGER | | 30 | SALESMAN |
Notes
The
DISTINCTkeyword applies to all columns in theSELECTstatement. It treats each unique combination of values in the specified columns as a separate entry.Using
DISTINCTcan be slow on large datasets because the database has to sort and compare rows to remove duplicates.
TOP clause:
Use to fetch the top N records based on a specific ordering.
Syntax:
SELECT TOP n *
FROM table_name
ORDER BY column_name;
n: The number of rows to return.column_name: The column used to order the data.
Example:
Display the First 3 Rows from the Employee Table:
SELECT TOP 3 * FROM EMP;- This query returns the first 3 rows from the
EMPtable based on the default row order.
- This query returns the first 3 rows from the
Display the Top 3 Highest Paid Employees:
SELECT TOP 3 * FROM EMP ORDER BY SAL DESC;- This query returns the top 3 employees with the highest salaries, sorted in descending order.
Display the Top 3 Employees Based on Experience:
SELECT TOP 3 * FROM EMP ORDER BY HIREDATE ASC;- This query returns the top 3 employees, sorted by the hire date in ascending order.
Display the Top 3 Maximum Salaries:
SELECT DISTINCT TOP 4 SAL FROM EMP ORDER BY SAL DESC;
Notes
The
TOPclause is specific to certain SQL dialects like SQL Server and may not be supported or may have different syntax in other databases. For example, in MySQL, you would useLIMITinstead, and in Oracle, you would useROWNUM.When used with
ORDER BY, theTOPclause can retrieve the highest or lowest values according to the specified order.
Practice questions 01:
Q29. Create a query to display employee names and their annual salaries using aliases.
SELECT ENAME, SAL 12 AS ANNUAL_SALARY FROM EMP;Q30. Write a SQL query to show employee names along with their total salary (base salary plus 20% bonus) and use aliases to label the calculated columns.
SELECT ENAME, SAL AS BASE_SALARY, SAL 0.2 AS BONUS, SAL + (SAL 0.2) AS TOTAL_SALARY FROM EMP;Q31. Generate a query to display employee names, salaries, and their department with aliases for the calculated columns.
SELECT ENAME AS EMPLOYEE_NAME, SAL AS SALARY, DEPTNO AS DEPARTMENT_NUMBER FROM EMP;Q32. Write a query to display employee names and their experience (calculated as the difference between the current date and the hire date), using an alias for the calculated column.
SELECT ENAME, ROUND(DATEDIFF(YEAR, HIREDATE, GETDATE())) AS EXPERIENCE_YEARS FROM EMP;Q33. Display all employee details sorted by their salaries in descending order.
SELECT FROM EMP ORDER BY SAL DESC;Q34. Write a SQL query to sort employee records first by department in ascending order and then by hire date in descending order within each department.
SELECT FROM EMP ORDER BY DEPTNO ASC, HIREDATE DESC;Q35. Retrieve employee details ordered by job title in ascending order and then by salary in descending order.
SELECT FROM EMP ORDER BY JOB ASC, SAL DESC;Q36. Show a list of employees ordered by their names in alphabetical order, and then by hire date in descending order if names are the same.
SELECT FROM EMP ORDER BY ENAME ASC, HIREDATE DESC;Q37. Write a query to list all unique job titles from the employee table.
SELECT DISTINCT JOB FROM EMP;Q38. Create a query to find distinct department numbers from the employee table.
SELECT DISTINCT DEPTNO FROM EMP;Q39. Generate a query to show unique combinations of job title and department number.
SELECT DISTINCT JOB, DEPTNO FROM EMP;Q40. Write a query to find unique salary figures from the employee table.
SELECT DISTINCT SAL FROM EMP;Q41. Retrieve the top 5 highest-paid employees from the employee table.
SELECT TOP 5 FROM EMP ORDER BY SAL DESC;Q42. Show the top 10 employees based on their years of experience (sorted from most experienced to least experienced).
SELECT TOP 10 FROM EMP ORDER BY DATEDIFF(YEAR, HIREDATE, GETDATE()) DESC;Q43. Write a query to get the top 3 employees with the lowest salaries.
SELECT TOP 3 FROM EMP ORDER BY SAL ASC;Q44. Display the top 4 employees who joined the company most recently.
SELECT TOP 4 FROM EMP ORDER BY HIREDATE DESC;Q45. What is the purpose of using an alias in SQL? Can you provide an example where it improves the readability of a query?
Purpose of Alias: An alias in SQL is used to provide a temporary name to a table or column for the duration of a query. This can make queries more readable and easier to understand, especially when dealing with complex expressions or multiple tables.Q46. How does using an alias for a column differ from using an alias for a table? Provide an example of each.
When you need to simplify complex expressions:SELECT SAL 0.2 AS HRA FROM EMP;.Q47. How does the ORDER BY clause affect the result set of a query? Can you explain the difference between ascending and descending order?
ORDER BY Clause: It sorts the result set based on one or more columns in either ascending or descending order. By default, sorting is done in ascending order.Q48. If you need to sort a result set by multiple columns, how do you specify the sorting order for each column? Can you provide an example query?
Multiple Columns: You can specify the sorting order for each column in theORDER BYclause, separating them with commas.SELECT FROM EMP ORDER BY DEPTNO ASC, SAL DESC;Q49. Explain how the ORDER BY clause can be used in conjunction with other SQL clauses like LIMIT or OFFSET for pagination.
Pagination: UseORDER BYto sort the results andLIMITorOFFSETto fetch a specific subset of the result set.Q50. What does the DISTINCT clause do in SQL? Can you provide an example where it is used to eliminate duplicate rows?
DISTINCT Clause: Removes duplicate rows from the result set.SELECT DISTINCT DEPTNO FROM EMP;.Q51. This retrieves unique department numbers from the EMP table.
Multiple Columns:DISTINCTapplies to the combination of all specified columns, removing duplicates based on those combinations.SELECT DISTINCT DEPTNO, JOB FROM EMP;.Q52. Can you explain a scenario where DISTINCT might be used incorrectly, and what the consequences would be?
Incorrect Use: UsingDISTINCTwhen it’s unnecessary can lead to inefficient queries.Q53. How would you use the TOP clause to retrieve the top 10 highest salaries from an employee table? Provide a sample query.
TOP Clause for Highest Salaries:SELECT TOP 10 FROM EMP ORDER BY SAL DESC;Q54. Explain how to combine the TOP clause with the ORDER BY clause to get the top N rows based on a specific sorting criterion.
Combining TOP with ORDER BY:
#SQL Sub-languages:
DML Commands (Data manuipulation Lang):
INSERT
UPDATE
DELETE
MARGE
Characteristics:
1. All DML commands act on table data.
2. All DML operations are auto-committed by default.
3. To stop auto-commit, execute: SET IMPLICIT_TRANSACTIONS ON.
SET IMPLICIT_TRANSACTIONS ON. This command ensures that changes are not automatically committed until you explicitly save them.4. To save the operation, execute COMMIT.
IMPLICIT_TRANSACTIONS is on, you need to use the COMMIT command to save your changes permanently to the database. This is a way to confirm that you want the changes to be applied.5. To cancel the operation, execute ROLLBACK.
ROLLBACK command. This command undoes all the changes made since the last commit, effectively cancelling the transaction.UPDATE Command:
The UPDATE command is used to modify table data. It can update all rows or specific rows, and can target single or multiple columns.
Syntax:
UPDATE table_name
SET column_name = value, column_name = value, ...
[WHERE condition]
Example:
Update all employees' commission to 500:
UPDATE EMP SET COMM = 500Update employees' commission to 500 where commission is NULL:
UPDATE EMP SET COMM = 500 WHERE COMM IS NULLUpdate employees' commission to NULL where commission is not NULL:
UPDATE EMP SET COMM = NULL WHERE COMM IS NOT NULLUpdate salary to 2000 and commission to 800 where employee number is 7369:
UPDATE EMP SET SAL = 2000, COMM = 800 WHERE EMPNO = 7369Increase salary by 20% and commission by 10% for salesmen hired in 1981:
UPDATE EMP SET SAL = SAL * 1.2, COMM = COMM * 1.1 WHERE JOB = 'SALESMAN' AND HIREDATE LIKE '1981%'Transfer all employees from department 10 to department 20:
UPDATE EMP SET DEPTNO = 20 WHERE DEPTNO = 10Increase prices by 10% for Samsung, Redmi, and Realme mobile phones:
UPDATE PRODUCTS SET PRICE = PRICE * 1.1 WHERE CATEGORY = 'mobiles' AND BRAND IN ('samsung', 'redmi', 'realme')
DELETE command:
The DELETE command is used to remove row(s) from a table in a database.
Syntax:
DELETE FROM <table_name> [WHERE condition];
Examples:
Delete all rows from the
EMPtable:DELETE FROM EMP;This command removes all records from the
EMPtable. Use this with caution, as it will delete all data without a condition.Delete employees who joined in the 2nd quarter of the year 1981:
DELETE FROM EMP WHERE HIREDATE BETWEEN '1981-04-01' AND '1981-06-30';This command deletes rows from the
EMPtable where theHIREDATEfalls within the second quarter of 1981, specifically between April 1st and June 30th, 1981.
Make sure to always use the WHERE clause with the DELETE command to avoid removing unintended rows. If no WHERE clause is provided, all rows in the table will be deleted.
DDL Commands (Data Definition Lang):
DDL commands are used to define and modify the structure of database objects such as tables.
Common DDL Commands:
CREATE: Used to create a new table or database object.
ALTER: Used to modify an existing table's structure.
DROP: Used to remove a table or other database objects.
TRUNCATE: Used to remove all rows from a table without deleting the table structure.
ALTER Command:
The ALTER command modifies the structure of an existing table.
Uses ofALTER Command:
Adding Columns:
To add a new column to a table.
Example: Add a column
GENDERto theEMPtable:ALTER TABLE EMP ADD GENDER CHAR(1);After adding, the new column is filled with
NULLby default. To update the new column with data, use theUPDATEcommand:UPDATE EMP SET GENDER = 'M' WHERE EMPNO = 7369;
Dropping Columns:
To remove an existing column from a table.
Example: Drop the column
GENDERfrom theEMPtable:ALTER TABLE EMP DROP COLUMN GENDER;
Modifying Columns:
To change the data type or size of an existing column.
Example: Change the data type of the
EMPNOcolumn toINT:ALTER TABLE EMP ALTER COLUMN EMPNO INT;Example: Increase the size of the
ENAMEcolumn to 20 characters:ALTER TABLE EMP ALTER COLUMN ENAME VARCHAR(20);
DROP Command:
The DROP command is used to remove a table from the database. This command deletes the table structure along with all the data contained in it.
Syntax:
DROP TABLE <table_name>;Example:
DROP TABLE EMP;
TRUNCATE Command:
The TRUNCATE command deletes all data from a table but keeps the table structure. It also frees up the memory used by the data.Syntax:
TRUNCATE TABLE <table_name>;Example:
TRUNCATE TABLE EMP;
Use TRUNCATE and DROP commands with caution as they affect all rows in the table and can lead to data loss.
DELETE vs. TRUNCATE
| DELETE | TRUNCATE |
| DML Type | DDL Type |
| Delete specific rows | Cannot delete specific rows |
| Delete all rows | Deletes all rows |
| Use WHERE condition | WHERE condition cannot be used |
| Used with DELETE command | Used with TRUNCATE command |
| Deletes rows one-by-one | Deletes all rows at once |
| Generally slower | Generally faster |
| Not release memory | Releases memory |
| Not reset identity columns | Resets identity columns |
SP_RENAME
SP_RENAME is used to change the name of a table or a column.
Syntax:
SP_RENAME 'old_name', 'new_name';Examples:
Rename table
EMPtoEMPLOYEES:SP_RENAME 'EMP', 'EMPLOYEES';Rename column
COMMtoBONUSin theEMPLOYEEStable:SP_RENAME 'EMPLOYEES.COMM', 'BONUS';
List of Tables Created-by-user:
To list all tables created by the user in the database, use:
SELECT * FROM INFORMATION_SCHEMA.TABLES;
The command SELECT * FROM INFORMATION_SCHEMA.TABLES is a SQL query used to retrieve information about the tables within a database.
INFORMATION_SCHEMA is a standardized set of read-only views that provide metadata about the database objects, such as tables, columns, data types, and constraints. These views are part of the SQL standard and are supported by many database systems, including SQL Server, MySQL, and PostgreSQL.
This comparison and usage information helps clarify when to use DELETE or TRUNCATE and how to rename database objects using SP_RENAME.
Built-in Functions in SQL Server:
In SQL Server, built-in functions are predefined functions that perform calculations and return a single value based on the input provided. These functions help in data manipulation, querying, and analysis. A function accepts some input performs some calculation and returns one value.
Types of Built-in Functions:
Date Functions:
- Functions that deal with date and time data types. Examples include
GETDATE(),DATEPART(),DATENAME(),DATEADD(),DATEDIFF(),EOMONTH(), andFORMAT().
- Functions that deal with date and time data types. Examples include
String Functions:
- Functions used for manipulating string data. Examples include
LEN(),LOWER(),LEFT(),SUBSTRING(),CHARINDEX(),RIGHT(),REPLACE(),REPLICATE(),TRANSLATE(),STUFF(), andUPPER().
- Functions used for manipulating string data. Examples include
Numeric Functions:
- Functions that perform operations on numeric data. Examples include
ABS(),CEILING(),FLOOR(),ROUND(), andPOWER().
- Functions that perform operations on numeric data. Examples include
Conversion Functions:
- Functions that convert data from one data type to another. Examples include
CAST(),CONVERT(), andPARSE().
- Functions that convert data from one data type to another. Examples include
Special Functions:
- Functions that perform specialized tasks, such as
COALESCE(),NULLIF(), andISNULL().
- Functions that perform specialized tasks, such as
Analytical Functions:
- Functions used for advanced data analysis, often involving windowing and ranking. Examples include
ROW_NUMBER(),RANK(),DENSE_RANK(), andLEAD().
- Functions used for advanced data analysis, often involving windowing and ranking. Examples include
Aggregate Functions:
- Functions that perform calculations on a set of values and return a single value. Examples include
SUM(),AVG(),COUNT(),MIN(), andMAX().
- Functions that perform calculations on a set of values and return a single value. Examples include
DATE Functions in SQL Server:
GETDATE():
This function returns the current date and time.
Example:
SELECT GETDATE()might return2023-09-21 19:15:59.130.
DATEPART():
Used to extract a specific part of a date, such as year, month, day, etc.
Syntax:
DATEPART(interval, date)Example:
SELECT DATEPART(yy, GETDATE())=>2023(Year)SELECT DATEPART(mm, GETDATE())=>09(Month)SELECT DATEPART(dd, GETDATE())=>21(Day)SELECT DATEPART(dy, GETDATE())=>264(Day of the year)SELECT DATEPART(dw, GETDATE())=>5(Day of the week)SELECT DATEPART(hh, GETDATE())=> HourSELECT DATEPART(mi, GETDATE())=> MinutesSELECT DATEPART(ss, GETDATE())=> SecondsSELECT DATEPART(qq, GETDATE())=>3(Quarter)
Q. Display ENAME , SAL , year of join ?
SELECT ENAME,SAL,DATEPART(YY,HIREDATE) AS YEAR FROM EMPQ. Display employees joined in 1980,1983,1985 ?
SELECT FROM EMP WHERE DATEPART(YY,HIREDATE) IN (1980,1983,1985)Q. Employees joined in leap year ?
SELECT FROM EMP WHERE DATEPART(yy,hiredate)%4=0Q. Employees joined in jan,apr,dec months ?
SELECT FROM EMP WHERE DATEPART(MM,HIREDATE) IN (1,4,12)Q. Employees joined in 2nd quarter of 1981 year ?
SELECT FROM EMP WHERE DATEPART(QQ,HIREDATE)=2 AND DATEPART(YY,HIREDATE)=1981DATENAME():
Used to get the name of the specified date part.
Example:
SELECT DATENAME(dw, GETDATE())=>FridayTo find employees who joined on Sunday:
SELECT * FROM EMP WHERE DATENAME(dw, HIREDATE) = 'SUNDAY'.
Q. Display ENAME DAY OF THE WEEK ?
SELECT ENAME,DATENAME(DW,HIREDATE) AS DAY FROM EMPQ. Write a query to display on which day india got independence ?
SELECT DATENAME(DW,'1947-08-15')FORMAT():
Formats a date/time value into a specified format.
Syntax:
FORMAT(date, 'format')Examples:
SELECT FORMAT(GETDATE(), 'dd.MM.yyyy')=>22.09.2023SELECT FORMAT(GETDATE(), 'HH:mm:ss')=>18:51:20SELECT FORMAT(GETDATE(),'hh:mm:ss') => 6:51:23SELECT FORMAT(GETDATE(), 'MM/dd/yyyy')for date formatting inMM/DD/YYYY.
Q. Display ENAME HIREDATE ? display hiredate in MM/DD/YYYY format ?
SELECT ENAME,FORMAT(HIREDATE,'MM/dd/yyyy') AS HIREDATE FROM EMPScenario:
INSERT INTO EMP(EMPNO,ENAME,SAL,HIREDATE) VALUES(999,'ABC',5000,GETDATE())List of employees joined today ?
SELECT * FROM EMP WHERE HIREDATE = GETDATE()=> NO ROWS2023-09-22 = 2023-09-22 18:58:33.133
SELECT * FROM EMP WHERE HIREDATE = FORMAT(GETDATE(),'yyyy-MM-dd')2023-09-22 = 2023-09-22
DATEADD():
Adds or subtracts a specified number of units to/from a date(used to add / subtract days,months,years to / from a date).
Syntax:
DATEADD(interval, number, date)Examples:
SELECT DATEADD(yy, 1, GETDATE())=> Adds 1 year.SELECT DATEADD(mm, 2, GETDATE())=> Adds 2 months.SELECT DATEADD(dd, -10, GETDATE())=> Subtracts 10 days.
Q. Display today's gold rate ?
SELECT FROM GOLD_RATES WHERE DATEID = FORMAT(GETDATE(),'yyyy-MM-dd')Q. Display yesterday's gold rate ?
SELECT FROM GOLD_RATES WHERE DATEID = FORMAT(DATEADD(DD,-1,GETDATE()),'yyyy-MM-dd')Q. Display last month same day gold rate ?
SELECT FROM GOLD_RATES WHERE DATEID = FORMAT(DATEADD(MM,-1,GETDATE()),'yyyy-MM-dd')Q. Display last year same day gold rate ?
SELECT FROM GOLD_RATES WHERE DATEID = FORMAT(DATEADD(YY,-1,GETDATE()),'yyyy-MM-dd')Q. Last 1 month gold rates ?
SELECT * FROM GOLD_RATES WHERE DATEID BETWEEN FORMAT(DATEADD(MM,-1,GETDATE()),'yyyy-MM-dd') AND FORMAT(GETDATE(),'yyyy-MM-dd')DATEDIFF():
Calculates the difference between two dates in the specified interval.
Syntax:
DATEDIFF(interval, startdate, enddate)Examples:
SELECT DATEDIFF(yy, '2022-09-22', GETDATE())=> Difference in years.SELECT DATEDIFF(mm, '2022-09-22', GETDATE())=> Difference in months.
Q. Display ENAME EXPERIENCE in years ?
SELECT ENAME,DATEDIFF(YY,HIREDATE,GETDATE()) AS EXPERIENCE FROM EMPQ. Display ENAME EXPERIENCE ? M YEARS N MONTHS
SELECT ENAME, DATEDIFF(MM, HIREDATE, GETDATE()) / 12 AS YEARS, DATEDIFF(MM, HIREDATE, GETDATE()) % 12 AS MONTHS FROM EMPEOMONTH():
Returns the last day of the month for a given date, with an optional offset.
Syntax:
EOMONTH(date, offset)Examples:
SELECT EOMONTH(GETDATE(), 0)=> Last day of the current month.SELECT EOMONTH(GETDATE(), 1)=> Last day of the next month.SELECT EOMONTH(GETDATE(), -1)=> Last day of the previous month.
Examples:
To display an employee's name and their experience in years and months:
SELECT ENAME, DATEDIFF(mm, HIREDATE, GETDATE()) / 12 AS YEARS, DATEDIFF(mm, HIREDATE, GETDATE()) % 12 AS MONTHS FROM EMP;To find all employees who joined in the second quarter of 1981:
SELECT * FROM EMP WHERE DATEPART(qq, HIREDATE) = 2 AND DATEPART(yy, HIREDATE) = 1981;
Q. Display next month first day ?
Q. Display current month first day ?
Q. Display next year first day ?
Q. Display current year first day ?
String Functions in SQL Server:
UPPER():
Converts a string to uppercase.
UPPER(arg)Example:
SELECT UPPER('hello') => HELLO
LOWER():
Converts a string to lowercase.
LOWER(arg)Example:
SELECT LOWER('HELLO') => helloDisplay
ENAMEandSALin lowercase:SELECT LOWER(ENAME) AS ENAME, SAL FROM EMPConvert names to lowercase in the table:
UPDATE EMP SET ENAME = LOWER(ENAME)
LEN():
Returns the length of a string (i.e., number of characters).
LEN(arg)Example:
SELECT ENAME, LEN(ENAME) AS LEN FROM EMPDisplay employees' names with 4 characters:
SELECT * FROM EMP WHERE LEN(ENAME) = 4
LEFT():
Returns the specified number of characters from the left side of a string.
LEFT(STRING, NO_OF_CHARS)Example:
SELECT LEFT('HELLO WELCOME', 5) => HELLO
RIGHT():
Returns the specified number of characters from the right side of a string.
RIGHT(STRING, NO_OF_CHARS)Example:
SELECT RIGHT('HELLO WELCOME', 7) => WELCOMEEmployees whose names start with 's':
SELECT * FROM EMP WHERE LEFT(ENAME, 1) = 's'Employees whose names end with 's':
SELECT * FROM EMP WHERE RIGHT(ENAME, 1) = 's'Employees whose names start and end with the same character:
SELECT * FROM EMP WHERE LEFT(ENAME, 1) = RIGHT(ENAME, 1)
Scenario:
Generate email IDs for employees:
SELECT empno, ename, LEFT(ename, 3) + LEFT(empno, 3) + '@tcs.com' AS emailid FROM empStore email IDs in the database:
Step 1: Add emailid column to the emp table:
ALTER TABLE EMP ADD EMAILID VARCHAR(30)Step 2: Update the column with email IDs:
UPDATE EMP SET EMAILID = LEFT(ename, 3) + LEFT(empno, 3) + '@tcs.com'
SUBSTRING():
Extracts a part of a string starting from a specific position.
SUBSTRING(string, start, length)Example:
SELECT SUBSTRING('HELLO WELCOME', 7, 4) => WELC SELECT SUBSTRING('HELLO WELCOME', 10, 3) => COM
REPLICATE():
Repeats a given character a specified number of times.
REPLICATE(char, length)Example:
SELECT REPLICATE('*', 5) => *****Display
ENAMEandSALwith masked salary:SELECT ENAME, REPLICATE('*', LEN(SAL)) AS SAL FROM EMP
Scenario:
Masking account numbers:
SELECT REPLICATE('X', 4) + RIGHT(ACCNO, 4) AS MASKED_ACCNO FROM ACCOUNTS
REPLACE():
Replaces occurrences of a specified string with another string.
REPLACE(str1, str2, str3)Example:
SELECT REPLACE('hello', 'ell', 'abc') => habco SELECT REPLACE('hello', 'l', 'abc') => heabcabco SELECT REPLACE('@@he@@ll@@o@@', '@', '') => helloDisplay employees whose names contain exactly one 'a':
SELECT * FROM EMP WHERE LEN(ENAME) - LEN(REPLACE(ENAME, 'A', '')) = 1
TRANSLATE():
Translates one character to another in a string.
TRANSLATE(str1, str2, str3)Example:
SELECT TRANSLATE('hello', 'elo', 'abc') => habbcEncryption example:
SELECT ENAME, TRANSLATE(SAL, '0123456789.', '$bT*h@U%#^&') AS SAL FROM EMPRemove special characters from a string:
SELECT REPLACE(TRANSLATE('%@he*&ll^$o@#', '%@*&^$#', '*******'), '*', '')
NOTE :- Translate function can be used to encrypt data i.e. converting plain text to cipher text.
STUFF():
Replaces a part of a string with another string, based on a starting position and length.
STUFF(str1, start, length, str2)Example:
SELECT STUFF('hello welcome', 10, 3, 'abc') => hello welabce
CHARINDEX():
Returns the starting position of a specified substring within a string.
CHARINDEX(char, string, [start])Example:
SELECT CHARINDEX('o', 'hello welcome') => 5 SELECT CHARINDEX('x', 'hello welcome') => 0 SELECT CHARINDEX('o', 'hello welcome', 6) => 11 SELECT CHARINDEX('e', 'hello welcome', 10) => 13
Scenario:
Split full names into first and last names:
SELECT CID, SUBSTRING(CNAME, 1, CHARINDEX(' ', CNAME) - 1) AS FNAME, SUBSTRING(CNAME, CHARINDEX(' ', CNAME) + 1, LEN(CNAME)) AS LNAME FROM CUST
Q. Split names into first, middle, and last names.
Numeric Functions in SQL Server:
Let's include the descriptions for the POWER() and ABS() functions:
ROUND():
Rounds a number to a specified number of decimal places or to an integer(rounds number to integer or to decimal places based on avg).
ROUND(number, decimal_places)Examples:
Rounding to the nearest integer:
ROUND(38.5678, 0) => 39 ROUND(38.3647, 0) => 38Rounding to two decimal places:
ROUND(38.5638, 2) => 38.56 ROUND(38.5678, 2) => 38.57Rounding to one decimal place:
ROUND(38.5678, 1) => 38.6Rounding to the nearest hundred:
ROUND(386, -2) => 400Rounding to the nearest ten:
ROUND(386, -1) => 390Rounding to the nearest thousand:
ROUND(386, -3) => 0Round all employee salaries to the nearest hundred:
UPDATE EMP SET SAL = ROUND(SAL, -2)
CEILING():
Rounds a number up to the nearest integer.
CEILING(number)Example:
SELECT CEILING(3.1) => 4
FLOOR():
Rounds a number down to the nearest integer.
FLOOR(number)Example:
SELECT FLOOR(3.9) => 3
POWER():
Raises a number to the power of another number.
POWER(base, exponent)Example:
SELECT POWER(2, 3) => 8 -- 2 raised to the power of 3
ABS():
Returns the absolute value of a number, removing any negative sign.
ABS(number)Example:
SELECT ABS(-5) => 5 SELECT ABS(5) => 5
Conversion Functions in SQL Server:
CAST
CONVERT
PARSE
All these functions are used to convert data from one type to another.
CAST():
Converts an expression of one data type to another data type.
CAST(source_value AS target_type)Examples:
Converting a decimal to an integer:
SELECT CAST(10.5 AS INT) => 10Displaying employee names and salaries with a string concatenation:
SELECT ENAME + ' earns ' + CAST(SAL AS VARCHAR) FROM EMPDisplaying a message with hire date and job:
SELECT ENAME + ' joined on ' + CAST(HIREDATE AS VARCHAR) + ' as ' + JOB FROM EMP
Q. Display smith joined on 1980-12-17 as clerk ?
SELECT ename + ' joined on ' + CAST(hiredate AS VARCHAR) + ' as ' + job FROM empCONVERT():
Similar to
CAST, but with more flexibility for date and monetary formats.CONVERT(target_type, source_value, [style])Examples:
Converting a decimal to an integer:
SELECT CONVERT(INT, 10.5) => 10
Differences between
CASTandCONVERT:
Using
convertwe can display dates in different formats but not possible usingcast.Using
convertwe can display money in different formats but not possible usingcast.
Date Styles inCONVERT:
Use
CONVERTto display dates in different formats with style numbers.CONVERT(VARCHAR, date, style_number)Examples:
U.S. style (MM/DD/YYYY):
SELECT CONVERT(VARCHAR, GETDATE(), 101) => 09/26/2023British/French style (DD MMM YYYY):
SELECT CONVERT(VARCHAR, GETDATE(), 106) => 26 Sep 2023Time in HH:MM:SS:MMM format:
SELECT CONVERT(VARCHAR, GETDATE(), 114) => 19:06:44:713Displaying hire dates in a specific format:
SELECT ENAME, CONVERT(VARCHAR, HIREDATE, 105) AS HIREDATE FROM EMP
Money Styles inCONVERT:
Formats monetary values with different style numbers.
CONVERT(VARCHAR, money, style_number)Examples:
No style specified (default):
SELECT CONVERT(VARCHAR, SAL, 0) FROM EMP -- 2 digits after the decimalWith a thousand separator:
SELECT CONVERT(VARCHAR, SAL, 1) FROM EMPDisplaying salaries with a thousand separator:
SELECT ENAME, CONVERT(VARCHAR, SAL, 1) AS SAL FROM EMP
PARSE():
Converts a string to a specified data type, often used for parsing date and numeric values from strings.
PARSE(source_value AS target_type [USING culture])Examples:
Parsing a string to a datetime:
SELECT PARSE('2023-09-26' AS DATETIME) => 2023-09-26 00:00:00.000Parsing a string to a numeric type:
SELECT PARSE('12345.67' AS DECIMAL(10, 2)) => 12345.67Using a specific culture for parsing:
SELECT PARSE('26 Sep 2023' AS DATETIME USING 'en-US') => 2023-09-26 00:00:00.000Parsing and formatting data:
SELECT ENAME, PARSE(SAL AS DECIMAL(10, 2)) AS SAL FROM EMP
The PARSE() function is especially useful when dealing with data that includes regional formatting, such as different date formats or numeric separators.
Special Functions in SQL Server:
ISNULL():
The
ISNULL()function in SQL is used to replaceNULLvalues with a specified replacement value (used to convert null values).It takes two arguments: the expression to check for
NULLand the value to return if the expression isNULL.
ISNULL(expression, replacement_value)
Behavior:
If
expressionis notNULL, thenISNULL()returns the value ofexpression(or you can say:-if(expression<>null) returnsexpression).If
expressionisNULL,ISNULL()returnsreplacement_value(or you can say:- if(expression=null) then returnsreplacement_value).
Examples:
Basic Usage:
SELECT ISNULL(100, 200) => 100 SELECT ISNULL(NULL, 200) => 200Displaying Employee Information:
Displaying Total Salary (TOTSAL):
- The query below calculates the total salary (
TOTSAL) by addingSALandCOMM, usingISNULL()to handleNULLvalues inCOMM.
- The query below calculates the total salary (
SELECT ENAME, SAL, COMM, SAL + ISNULL(COMM, 0) AS TOTSAL
FROM EMP
Output:
ENAME | SAL | COMM | TOTSAL
--------------------------------------
WARD | 1300.00| 500.00 | 1800.00
JONES | 3000.00| NULL | 3000.00
Handling NULL COMM Values:
If
COMMisNULL, display 'N/A' instead.The
CAST()function is used to convertCOMMto aVARCHARtype to allow the display of 'N/A'.
SELECT ENAME, SAL, ISNULL(CAST(COMM AS VARCHAR), 'N/A') AS COMM
FROM EMP
Output:
ENAME | SAL | COMM
-------------------------
WARD | 1300.00| 500.00
JONES | 3000.00| N/A
Note:
- The
ISNULL()function is particularly useful when dealing with optional columns or fields that may containNULLvalues, ensuring that reports and calculations do not encounter errors due toNULLdata.
COALESCE():
- The
COALESCE()function in SQL returns the first non-NULLvalue from a list of expressions. If all expressions areNULL, it returnsNULL.
COALESCE(expression1, expression2, ..., expressionN)
Behavior:
Evaluates the expressions in order and returns the first non-
NULLexpression.If all expressions are
NULL, it returnsNULL.
Examples:
Basic Usage:
SELECT COALESCE(NULL, NULL, 'default') => 'default' SELECT COALESCE(NULL, 'value1', 'value2') => 'value1'Display Employee Salary or Commission:
- This example returns the salary if it exists; otherwise, it returns the commission, and if both are
NULL, it returns 'N/A'.
- This example returns the salary if it exists; otherwise, it returns the commission, and if both are
SELECT ENAME, COALESCE(SAL, COMM, 'N/A') AS INCOME
FROM EMP
NULLIF():
- The
NULLIF()function returnsNULLif the two specified expressions are equal; otherwise, it returns the first expression.
NULLIF(expression1, expression2)
Behavior:
Compares two expressions: if they are equal,
NULLIF()returnsNULL.If they are not equal, it returns the first expression.
Examples:
Basic Usage:
SELECT NULLIF(100, 100) => NULL SELECT NULLIF(100, 200) => 100Avoid Division by Zero:
NULLIF()can be useful in calculations where dividing by zero may occur.The example below ensures that division by zero does not happen by returning
NULLinstead.
SELECT ENAME, SAL / NULLIF(COMM, 0) AS SALARY_TO_COMM_RATIO
FROM EMP
- Here, if
COMMis0,NULLIF(COMM, 0)returnsNULL, preventing a division by zero error.
These functions (ISNULL(), COALESCE(), and NULLIF()) are essential in handling NULL values in SQL, providing flexibility in data manipulation and ensuring data integrity.
Analytical Functions in SQL Server:
RANK & DENSE_RANK:
Both functions are used to find ranks.
Ranking is based on a specific column.
For rank functions, the data must be sorted.
RANK():
The
RANK()function assigns a rank to each row within a result set like (find the ranks of the employees based on sal and highest paid employee should get 1st rank ?).Ranks may have gaps when there are ties (i.e., rows with the same values).
RANK() OVER (ORDER BY colname ASC/DESC)
DENSE_RANK():
- The
DENSE_RANK()function also assigns ranks to rows but without gaps, even if there are ties.
DENSE_RANK() OVER (ORDER BY colname ASC/DESC)
Examples:
Finding Ranks Based on Salary:
- Highest paid employee should get the 1st rank.
SELECT empno, ename, sal,
RANK() OVER (ORDER BY sal DESC) AS rnk
FROM emp;
--Or
SELECT empno, ename, sal,
DENSE_RANK() OVER (ORDER BY sal DESC) AS drnk
FROM emp;
Difference Between RANK and DENSE_RANK:
RANK can produce gaps in the ranking sequence.
DENSE_RANK does not produce gaps.
In rank function ranks are not in sequence but in dense_rank ranks are always in sequence
| SAL | RNK | DRNK |
| 5000 | 1 | 1 |
| 4000 | 2 | 2 |
| 3000 | 3 | 3 |
| 3000 | 3 | 3 |
| 3000 | 3 | 3 |
| 2000 | 6 | 4 |
| 2000 | 6 | 4 |
| 1000 | 8 | 5 |
Finding Ranks Based on Salary and Hire Date:
- Ranking by salary first, and if salaries are the same, ranking by hire date.
SELECT empno, ename, hiredate, sal,
DENSE_RANK() OVER (ORDER BY sal DESC, hiredate ASC) AS drnk
FROM emp;
PARTITION BY Clause:
Used with ranking functions to find ranks within a group.
For example, finding ranks within departments.
Example:
SELECT empno, ename, sal, deptno,
DENSE_RANK() OVER (PARTITION BY deptno ORDER BY sal DESC) AS rnk
FROM emp;
ROW_NUMBER():
Assigns a unique sequential integer to rows within a partition of a result set.
Returns record numbers.
It is also based on some column.
Data must be sorted
Useful for pagination and uniquely ordering data.
ROW_NUMBER() OVER (ORDER BY colname ASC/DESC)
Example:
SELECT empno, ename, sal,
ROW_NUMBER() OVER (ORDER BY empno ASC) AS rno
FROM emp;
| SAL | RNK | DRNK | RNO |
| 5000 | 1 | 1 | 1 |
| 4000 | 2 | 2 | 2 |
| 3000 | 3 | 3 | 3 |
| 3000 | 3 | 3 | 4 |
| 3000 | 3 | 3 | 5 |
| 2000 | 6 | 4 | 6 |
| 2000 | 6 | 4 | 7 |
| 1000 | 8 | 5 | 8 |
SAL: The salary of the employees.
RNK: The rank assigned using the
RANK()function, which may have gaps.DRNK: The rank assigned using the
DENSE_RANK()function, without gaps.RNO: The row number assigned using the
ROW_NUMBER()function.
LAG & LEAD:
LAG()provides access to a row at a given physical offset before the current row within the result set (LAG(colname,int) OVER (ORDER BY---) => returns previous value).LEAD()provides access to a row at a given physical offset after the current row (LEAD(colname,int) OVER (ORDER BY---) => returns next value).
LAG():
LAG(colname, offset) OVER (ORDER BY colname ASC/DESC)
LEAD():
LEAD(colname, offset) OVER (ORDER BY colname ASC/DESC)
Example:
Using LAG to Get Previous Salary:
SELECT empno, ename, sal, LAG(sal, 1) OVER (ORDER BY empno ASC) AS prev_sal FROM emp;Calculating the Number of Days Between Hires:
SELECT ename, hiredate, DATEDIFF(DD, LAG(hiredate, 1) OVER (ORDER BY hiredate ASC), hiredate) AS days FROM emp;| EMPNO | ENAME | SAL | PREV_SAL | | --- | --- | --- | --- | | 7369 | Smith | 2000.00 | NULL | | 7499 | Allen | 1600.00 | 2000.00 | | 7521 | Ward | 1250.00 | 1600.00 |
Q. Display ENAME HIREDATE DAYS ?
SELECT ENAME,HIREDATE, DATEDIFF(DD, LAG(HIREDATE,1) OVER (ORDER BY HIREDATE ASC), HIREDATE) AS DAYS FROM EMP
Out:-
| EMPNO | ENAME | HIREDATE | DAYS |
| 7369 | VIJAY | 1980-12-17 | NULL |
| 7499 | ALLEN | 1981-02-20 | 65 |
Aggregate Functions/ Group Functions in SQL Server:
Aggregate functions process a group of rows and return a single value. They include functions such as MAX, MIN, SUM, AVG, COUNT and COUNT(*).
MAX()
Description: Returns the maximum value from a set of values.
Syntax:
MAX(expression)Examples:
SELECT MAX(SAL) FROM EMP;→ Returns 5000SELECT MAX(HIREDATE) FROM EMP;→ Returns '1983-01-12'SELECT MAX(ENAME) FROM EMP;→ Returns 'WARD'
MIN()
Description: Returns the minimum value from a set of values.
Syntax:
MIN(expression)Examples:
SELECT MIN(SAL) FROM EMP;→ Returns 800SELECT MIN(HIREDATE) FROM EMP;→ Returns '1980-12-17'
SUM()
Description: Returns the sum of a numeric column.
Syntax:
SUM(expression)Examples:
SELECT SUM(SAL) FROM EMP;→ Returns 29300.00To round the total salary to the nearest thousand:
SELECT ROUND(SUM(SAL), -3) FROM EMP;→ Returns 29000
To display the total salary with a thousand separator:
SELECT CONVERT(VARCHAR, ROUND(SUM(SAL), -3), 1) FROM EMP;→ Returns '29,000.00'
To calculate total salary including commissions:
SELECT SUM(SAL + COMM) FROM EMP;or
SELECT SUM(SAL + ISNULL(COMM, 0)) FROM EMP;
AVG()
Description: Returns the average value of a numeric column.
Syntax:
AVG(expression)Examples:
SELECT AVG(SAL) FROM EMP;→ Returns 2092.8571To round the average salary down to the nearest integer:
SELECT FLOOR(AVG(SAL)) FROM EMP;→ Returns 2092
Note: The
SUMandAVGfunctions cannot be applied to date or character columns.
COUNT()
Description: Counts the number of non-null values in a column.
Syntax:
COUNT(expression)Examples:
SELECT COUNT(EMPNO) FROM EMP;→ Returns 14SELECT COUNT(COMM) FROM EMP;→ Returns 4 (Null values are not counted)
COUNT(*)
Description: Counts the total number of rows in a table, including those with null values.
Syntax:
COUNT(*)Examples:
SELECT COUNT(*) FROM EMP;→ Returns 14
Differences Between COUNT and COUNT(*)
COUNT(expression)does not include nulls.COUNT(*)includes nulls and not-null.
Example: Given a table T1 with a column F1 containing values (10, NULL, 20, NULL, 30):
COUNT(F1)→ Returns 3 (Only non-null values are counted)COUNT(*)→ Returns 5 (All rows are counted)
Notes:
Finding specific conditions:
To count employees who joined in 1981:
SELECT COUNT(*) FROM EMP WHERE HIREDATE LIKE '1981%';To count employees who joined on a Sunday:
SELECT COUNT(*) FROM EMP WHERE DATENAME(DW, HIREDATE) = 'SUNDAY';Aggregate functions are not allowed in the WHERE clause. They are only allowed in the SELECT and HAVING clauses. Use subqueries to work around this limitation:
SELECT ENAME FROM EMP WHERE SAL = (SELECT MAX(SAL) FROM EMP);To Overcome this problom use other functions or Subqueries:
Date functions:
DATEPART,DATENAME,DATEADD,DATEDIFF,EOMONTH,FORMATCharacter functions:
UPPER,LOWER,LEN,LEFT,RIGHT,SUBSTRING,REPLICATE,REPLACE,TRANSLATE,CHARINDEXNumeric functions:
ROUND,CEILING,FLOORConversion functions:
CAST,CONVERTSpecial functions:
ISNULLAnalytical functions:
RANK,DENSE_RANK,ROW_NUMBER,LAG,LEADAggregate functions:
MAX,MIN,SUM,AVG,COUNT,COUNT(*)
CASE STATEMENT:
The CASE statement in SQL is used to implement conditional logic, similar to an IF-ELSE structure. It allows you to return values based on specified conditions. There are two types of CASE statements:
Simple CASE
Searched CASE
Simple CASE
A simple CASE expression is used when the conditions are based on equality (=) comparisons.
Syntax:
CASE expression
WHEN value1 THEN result1
WHEN value2 THEN result2
...
ELSE result
END
Example: Display ENAME and a description based on the JOB:
SELECT ENAME,
CASE JOB
WHEN 'CLERK' THEN 'WORKER'-- if JOB = 'CLERK' then display 'WORKER'
WHEN 'MANAGER' THEN 'BOSS'
WHEN 'PRESIDENT' THEN 'BIG BOSS'
ELSE 'EMPLOYEE'
END AS JOB_DESCRIPTION
FROM EMP;
Notes:-
The
CASEstatement must end with theENDkeyword. This keyword marks the end of theCASElogic and is followed by an alias name, which labels the column in the result set.
AS JOB_DESCRIPTION: This part gives a name (alias) to the column that holds the results of theCASEstatement. Here,JOB_DESCRIPTIONis the alias for the column that shows the job descriptions based on the conditions.Without an alias, the resulting column would be unnamed or have a system-generated name, which might not be clear or useful. Giving an alias like
JOB_DESCRIPTIONmakes the output easier to read and understand.
Example: Increment employee salaries based on their department:
UPDATE EMP
SET SAL = CASE DEPTNO
WHEN 10 THEN SAL + (SAL * 0.1) -- If DEPTNO = 10, increase SAL by 10%
WHEN 20 THEN SAL + (SAL * 0.15) -- If DEPTNO = 20, increase SAL by 15%
WHEN 30 THEN SAL + (SAL * 0.2) -- If DEPTNO = 30, increase SAL by 20%
ELSE SAL + (SAL * 0.05) -- For other DEPTNOs, increase SAL by 5%
END;
Searched CASE
A searched CASE expression allows for more complex conditions that aren't necessarily based on equality.
Syntax:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
...
ELSE result
END
Example: Calculate total marks and result for students:
SELECT SNO,
(S1 + S2 + S3) AS TOTAL,
(S1 + S2 + S3) / 3 AS AVG,
CASE
WHEN S1 >= 35 AND S2 >= 35 AND S3 >= 35 THEN 'PASS'
ELSE 'FAIL'
END AS RESULT
FROM STUDENT;
Example: Classify transactions as 'CREDIT' or 'DEBIT' based on the amount:
SELECT AMT,
CASE
WHEN AMT >= 0 THEN 'CREDIT'
ELSE 'DEBIT'
END AS TRANS
FROM T1;
Out:-
| AMT | TRANS |
| 1000 | CREDIT |
| -2000 | DEBIT |
| 3000 | CREDIT |
| -500 | DEBIT |
| -2000 | DEBIT |
GROUP BY Clause
The GROUP BY clause is used to group rows that have the same values in specified columns. This helps in calculating summary statistics like MIN, MAX, SUM, AVG, and COUNT for each group. In other words, the GROUP BY clause groups rows based on one or more columns to calculate MIN, MAX, SUM, AVG, and COUNT for each group.
Example Table: EMP
| EMPNO | ENAME | SAL | DEPTNO |
| 1 | A | 3000 | 10 |
| 2 | B | 4000 | 20 |
| 3 | C | 2000 | 30 |
| 4 | D | 5000 | 20 |
| 5 | E | 4000 | 10 |
Using the GROUP BY clause, you can turn detailed data into summarized data for analysis.
Syntax:
SELECT columns
FROM tablename
[WHERE condition]
GROUP BY column1, column2, ...
[HAVING condition]
[ORDER BY column ASC/DESC]
Execution Order:
FROM
WHERE
GROUP BY
HAVING
SELECT
ORDER BY
Example: Display department-wise total salary:
SELECT DEPTNO, SUM(SAL) AS TOTSAL
FROM EMP
GROUP BY DEPTNO;
Output:
| DEPTNO | TOTSAL |
| 10 | 7000 |
| 20 | 9000 |
| 30 | 2000 |
Detailed Process:
FROM EMP:
Retrieves all data from the EMP table.
| EMPNO | ENAME | SAL | DEPTNO | | --- | --- | --- | --- | | 1 | A | 3000 | 10 | | 2 | B | 4000 | 20 | | 3 | C | 2000 | 30 | | 4 | D | 5000 | 20 | | 5 | E | 4000 | 10 |
GROUP BY DEPTNO:
Groups rows by department number.
| DEPTNO | EMPNO | ENAME | SAL | DEPTNO (Grouped) | | --- | --- | --- | --- | --- | | 10 | 1 | A | 3000 | 10 | | | 5 | E | 4000 | 10 | | 20 | 2 | B | 4000 | 20 | | | 4 | D | 5000 | 20 | | 30 | 3 | C | 2000 | 30 |
This table shows how the data is grouped by the
DEPTNOcolumn, with theDEPTNOvalues repeated for each employee in the same department.
SELECT DEPTNO, SUM(SAL):
Calculates the total salary for each department.
| DEPTNO | TOTSAL | | --- | --- | | 10 | 7000 | | 20 | 9000 | | 30 | 2000 |
Q: Display job-wise number of employees?
SELECT JOB, COUNT(*) AS CNT
FROM EMP
GROUP BY JOB;
Output:
| JOB | CNT |
| ANALYST | 2 |
| CLERK | 4 |
| MANAGER | 3 |
| PRESIDENT | 1 |
| SALESMAN | 4 |
Q: Display year-wise number of employees joined ?
SELECT DATEPART(YY, HIREDATE) AS YEAR, COUNT(*) AS CNT
FROM EMP
GROUP BY DATEPART(YY, HIREDATE);
Output:
| YEAR | CNT |
| 1980 | 1 |
| 1981 | 10 |
| 1982 | 2 |
| 1983 | 1 |
Q: Display day wise no of employees joined ?
SELECT DATENAME(DW,HIREDATE) AS DAY,COUNT(*) AS CNT
FROM EMP
GROUP BY DATENAME(DW,HIREDATE)
Q: Display month wise no of employees joined in in the year 1981 ?
SELECT DATENAME(mm,HIREDATE) AS MONTH,COUNT(*) AS CNT
FROM EMP
WHERE DATEPART(YY,HIREDATE)=1981
GROUP BY DATENAME(mm,HIREDATE)
Q: Display departments having more than 3 employees?
SELECT DEPTNO, COUNT(*) AS CNT
FROM EMP
GROUP BY DEPTNO
HAVING COUNT(*) > 3;
Output:
| DEPTNO | CNT |
| 20 | 5 |
| 30 | 6 |
Note: The
HAVINGclause is used instead ofWHEREto filter groups based on aggregate values. In this example,COUNT(*) > 3cannot be used directly in theWHEREclause because the count is determined after grouping. SQL Server calculates the department-wise count only after grouping, so we apply the conditionCOUNT(*) > 3using theHAVINGclause.SELECT DEPTNO,COUNT(*) AS CNT FROM EMP GROUP BY DEPTNO HAVING COUNT(*) > 3
WHERE vs. HAVING:
WHERE Clause:
Purpose: Filters rows before grouping.
Usage: Applied to individual rows and used when conditions do not involve aggregate functions.
HAVING Clause:
Purpose: Filters groups after grouping.
Usage: Applied to groups and used when conditions involve aggregate functions.
Key Differences:
| Feature | WHERE | HAVING |
| Filtering | Applies to individual rows | Applies to groups |
| Execution | Before GROUP BY | After GROUP BY |
| Aggregate | Cannot contain aggregate functions | Can contain aggregate functions |
Q: Display department-wise number of employees where department numbers are 10 or 20, and the number of employees in each department is greater than 3.
SELECT DEPTNO, COUNT(*) AS CNT
FROM EMP
WHERE DEPTNO IN (10, 20)
GROUP BY DEPTNO
HAVING COUNT(*) > 3;
Output:
| DEPTNO | CNT |
| 20 | 5 |
Explanation:
The
WHEREclause filters rows whereDEPTNOis either 10 or 20.The
GROUP BYclause groups these rows byDEPTNO.The
HAVINGclause filters these groups to retain only those with more than 3 employees.
Q: Find southern states with a population greater than 5 crores (50 million).
SELECT STATE, COUNT(*) AS CNT
FROM PERSONS
WHERE STATE IN ('AP', 'TS', 'KA', 'KL', 'TN')
GROUP BY STATE
HAVING COUNT(*) > 50000000;
Output:
| STATE | CNT |
| (example states) | (populations above 50 million) |
Explanation:
The
WHEREclause filters rows for the states 'AP', 'TS', 'KA', 'KL', and 'TN'.The
GROUP BYclause groups the data bySTATE.The
HAVINGclause filters out states with a population count not exceeding 50 million.
Range grouping:
Range Grouping is a way to categorize data into different ranges or intervals. This is useful when you want to analyze how data falls into various segments, such as salary ranges, age groups, or other numerical categories.
To group employees based on their salary ranges and count the number of employees in each range:
Example of Range Grouping with Salaries
Imagine you have a list of employees and their salaries, and you want to see how many employees fall into different salary ranges, like:
0 to 2000
2001 to 4000
Above 4000
You can use SQL to create these categories (or "ranges") and count how many employees are in each range.
SQL Query
Here's a simple SQL query that groups employees by salary ranges:
SELECT
CASE
WHEN SAL BETWEEN 0 AND 2000 THEN '0-2000'
WHEN SAL BETWEEN 2001 AND 4000 THEN '2001-4000'
WHEN SAL > 4000 THEN 'ABOVE 4000'
END AS SALRANGE,
COUNT(*) AS CNT
FROM EMP
GROUP BY
CASE
WHEN SAL BETWEEN 0 AND 2000 THEN '0-2000'
WHEN SAL BETWEEN 2001 AND 4000 THEN '2001-4000'
WHEN SAL > 4000 THEN 'ABOVE 4000'
END;
Output:
| SALRANGE | CNT |
| 0-2000 | ? |
| 2001-4000 | ? |
| ABOVE 4000 | ? |
Explanation
CASE Statement: This is used to specify different conditions. In this case, we are checking if the salary (
SAL) falls within certain ranges.WHEN SAL BETWEEN 0 AND 2000 THEN '0-2000': This categorizes salaries from 0 to 2000 into the '0-2000' range.WHEN SAL BETWEEN 2001 AND 4000 THEN '2001-4000': This categorizes salaries from 2001 to 4000 into the '2001-4000' range.WHEN SAL > 4000 THEN 'ABOVE 4000': This categorizes salaries above 4000 into the 'ABOVE 4000' range.
COUNT(*): This function counts the number of employees in each salary range.
GROUP BY: This groups the data based on the salary ranges defined in the CASE statement.
Q. Display dept wise and with in dept job wise total salary ?
To display total salaries for each job within each department:
SELECT DEPTNO, JOB, SUM(SAL) AS TOTSAL
FROM EMP
GROUP BY DEPTNO, JOB
ORDER BY DEPTNO ASC;
Output:
| DEPTNO | JOB | TOTSAL |
| 10 | CLERK | 1430 |
| 10 | MANAGER | 2750 |
| 10 | PRESIDENT | 5500 |
| 20 | ANALYST | 6900 |
| 20 | CLERK | 2185 |
| 20 | MANAGER | 3450 |
| 30 | CLERK | 1200 |
| 30 | MANAGER | 3840 |
| 30 | SALESMAN | 6840 |
Q. Display year wise and with in year quarter wise no of employees ?
To display the number of employees hired each year, broken down by quarter:
SELECT
DATEPART(YY, HIREDATE) AS YEAR,
DATEPART(QQ, HIREDATE) AS QRT,
COUNT(*) AS CNT
FROM EMP
GROUP BY DATEPART(YY, HIREDATE), DATEPART(QQ, HIREDATE)
ORDER BY YEAR ASC;
Output:
| YEAR | QRT | CNT |
| 1980 | 1 | ? |
| 1980 | 2 | ? |
| 1980 | 3 | ? |
| 1980 | 4 | ? |
| 1981 | 1 | ? |
| 1981 | 2 | ? |
| 1981 | 3 | ? |
| 1981 | 4 | ? |
Each row shows the year, quarter, and the number of employees hired during that quarter.
ROLLUP & CUBE:
Both functions are used to display subtotals and grand totals:
GROUP BY ROLLUP(col1, col2, ...)GROUP BY CUBE(col1, col2, ...)
I have a query that calculates the total salary for each department:
SELECT Deptno, sum(sal) AS Sumsal
FROM Emp
GROUP BY Deptno
ORDER BY Deptno ASC;
OUT:-
| DEPTNO | SUMSAL |
| 10 | 7450 |
| 20 | 14075 |
| 30 | 9400 |
| 40 | 1300 |
But if the user wants subtotals and a grand total, we use ROLLUP and CUBE.
ROLLUP:
ROLLUP displays subtotals for each group and also shows the grand total.
Purpose: Generates subtotals and a grand total for grouped data.
Syntax:
GROUP BY ROLLUP(col1, col2, ...)
Example:-
SELECT Deptno, sum(sal) AS Sumsal
FROM Emp
GROUP BY ROLLUP(Deptno)
ORDER BY Deptno ASC;
Out:-
| DEPTNO | SUMSAL |
| 10 | 7450 |
| 20 | 14075 |
| 30 | 9400 |
| 40 | 1300 |
| 32220 => Grand Total |
Grand Total is the total salary paid to all the departments.
CUBE:
CUBE displays subtotals for each group by column (deptno, job) and also shows the grand total.
Purpose: Provides subtotals for all possible combinations of grouped columns, as well as the grand total.
Syntax:
GROUP BY CUBE(col1, col2, ...)Example:-
SELECT Deptno, sum(sal) AS Sumsal FROM Emp GROUP BY ROLLUP(Deptno) ORDER BY Deptno ASC;Out:-
| DEPTNO | SUMSAL | | --- | --- | | 10 | 7450 | | 20 | 14075 | | 30 | 9400 | | 40 | 1300 | | | 32220 => Grand Total |
Then what is the diffrence bitween ROOLUP and CUBE?
If I execute the query, the data is as follows:
SELECT Deptno, job, sum(sal) AS Sumsal
FROM Emp
GROUP BY Deptno, job
ORDER BY 1,2;
Out:-
| DEPTNO | JOB | SUMSAL |
| 10 | Manager | 2450 => 2450 represent the total salary paid to Manager in 20th department |
| 10 | President | 5000 => 5000 represent the total salary paid to President in 10th department |
| 20 | Analyst | 6000 => 6000 represent the total salary paid to Analyst in 20th department |
| 20 | Clerk | 5100 => 5100 represent the total salary paid to Clerk in 20th department |
| 20 | Manager | 2975 => 2975 represent the total salary paid to Manager in 20th department |
| 30 | Clerk | 950 => 950represent the total salary paid to Clerk in 20th department |
| 30 | Manager | 2850 => 2850represent the total salary paid to Manager in 20th department |
| 30 | Salesman | 5600 => 5600represent the total salary paid to Salesman in 20th department |
| 40 | Clerk | 1300 => 1300 represent the total salary paid to Clerk in 20th department |
It's calculating the total salary by department and job.
But still user wants subtotals and a grand total.
For example, the subtotal for the Manager in the 10th department is 2450, the subtotal for the President in the 10th department is 5000, and the grand total is 7450 in the 10th department.
Using ROOLUP:
SELECT Deptno, job, sum(sal) AS Sumsal
FROM Emp
GROUP BY ROLLUP(Deptno, job)
ORDER BY 1,2;
Out:-
| DEPTNO | JOB | SUMSAL |
| 10 | Manager | 2450 |
| 10 | President | 5000 |
| 7450 => 7450 is subtotal, the total salary paid to 10th department | ||
| 20 | Analyst | 6000 |
| 20 | Clerk | 5100 |
| 20 | Manager | 2975 |
| 14075 => 14075 is subtotal, the total salary paid to 10th department | ||
| 30 | Clerk | 950 |
| 30 | Manager | 2850 |
| 30 | Salesman | 5600 |
| 9400 => 9400 is subtotal, the total salary paid to 10th department | ||
| 40 | Clerk | 1300 |
| 1300 => 1300 is subtotal, the total salary paid to 10th department | ||
| 32225 => 32225 is Grand total, the total salary paid to all emp. |
Using CUBE:
SELECT Deptno, job, sum(sal) AS Sumsal
FROM Emp
GROUP BY CUBE(Deptno, job)
ORDER BY 1,2;
Out:-
| DEPTNO | JOB | SUMSAL |
| 10 | Manager | 2450 |
| 10 | President | 5000 |
| 7450 => 7450 is subtotal, the total salary paid to 10th department | ||
| 20 | Analyst | 6000 |
| 20 | Clerk | 5100 |
| 20 | Manager | 2975 |
| 14075 => 14075 is subtotal, the total salary paid to 10th department | ||
| 30 | Clerk | 950 |
| 30 | Manager | 2850 |
| 30 | Salesman | 5600 |
| 9400 => 9400 is subtotal, the total salary paid to 10th department | ||
| 40 | Clerk | 1300 |
| 1300 => 1300 is subtotal, the total salary paid to 10th department | ||
| Analyst | 6000 => 6000 is Subtotal, the total salary paid to Analyst. | |
| Clerk | 7350 => 7350 is Subtotal, the total salary paid to Clerk. | |
| Manager | 8275 => 8275 is Subtotal, the total salary paid to Manager. | |
| President | 5000 => 5000 is Subtotal, the total salary paid to President. | |
| Salesman | 5600 => 5600 is Subtotal, the total salary paid to Salesman. | |
| 32225 => 32225 is Grand total, the total salary paid to all emp. |
Diffrence bitween ROOLUP and CUBE:-
| Feature | ROLLUP | CUBE |
| Purpose | Creates subtotals and a grand total | Creates subtotals for all possible combinations of columns, as well as the grand total |
| Subtotals | Provides subtotals in a hierarchical manner, from left to right as specified in the GROUP BY clause | Provides subtotals for every possible combination of the grouped columns |
| Grand Total | Includes a grand total as the last grouping | Includes a grand total as the last grouping |
| Column Combinations | Subtotals are not computed for all combinations, only for the specified order and hierarchy | Subtotals are computed for every combination of the grouped columns |
| Use Case | Useful when there is a natural hierarchy or order in the grouping columns (e.g., department → job) | Useful for comprehensive analysis across all possible group combinations |
| Performance | Generally more efficient than CUBE as it calculates fewer subtotal rows | May require more processing and memory due to the calculation of a larger number of subtotal rows |
| Example | GROUP BY ROLLUP(col1, col2) | GROUP BY CUBE(col1, col2) |
If the end user sees this table, they might not understand what 32225, 7450, 14075, 9400, and 1300 mean. How will they know what these numbers represent?
That's when SQL provides the function called GROUPING_ID().
GROUPING_ID():
Purpose: Identifies the level of aggregation for each row in a result set that uses
ROLLUPorCUBE.Syntax:
GROUPING_ID(col1, col2, ...).
Common Values and Their Meanings:
0: Neither column is aggregated (regular row forROLLUPorCUBE).1: The first column is aggregated (subtotal for the first column if usingROLLUP).2: The second column is aggregated.3: Both columns are aggregated (grand total row for both columns).
For example, with CUBE, we break it down into three totals. A value of 1 means a subtotal for the first group of columns, 2 means a subtotal for the second group of columns, and 3 means the grand total. When we use this, it returns the values 1, 2, or 3.
SELECT Deptno, job, sum(sal) AS Sumsal,
GROUPING_ID(Deptno, job) AS subtotals
FROM Emp
GROUP BY CUBE(Deptno, job)
ORDER BY 1,2;
Out:-
| DEPTNO | JOB | SUMSAL | SUBTOTALS |
| 10 | Manager | 2450 | 0 |
| 10 | President | 5000 | 0 |
| 7450 | 1 | ||
| 20 | Analyst | 6000 | 0 |
| 20 | Clerk | 5100 | 0 |
| 20 | Manager | 2975 | 0 |
| 14075 | 1 | ||
| 30 | Clerk | 950 | 0 |
| 30 | Manager | 2850 | 0 |
| 30 | Salesman | 5600 | 0 |
| 9400 | 1 | ||
| 40 | Clerk | 1300 | 0 |
| 1300 | 1 | ||
| Analyst | 6000 | 2 | |
| Clerk | 7350 | 2 | |
| Manager | 8275 | 2 | |
| President | 5000 | 2 | |
| Salesman | 5600 | 2 | |
| 32225 | 3 |
To make more understable:-
SELECT Deptno, job, sum(sal) AS Sumsal,
CASE GROUPING_ID(Deptno, job)
WHEN 0 THEN 'Amount'
WHEN 1 THEN 'Dept Subtotal'
WHEN 2 THEN 'Job Subtotal'
WHEN 3 THEN 'Grand total'
END AS SUBTOTALS
FROM Emp
GROUP BY CUBE(Deptno, job)
ORDER BY 1,2;
Out:-
| DEPTNO | JOB | SUMSAL | SUBTOTALS |
| 10 | Manager | 2450 | Amount |
| 10 | President | 5000 | Amount |
| 7450 | Dept Subtotal | ||
| 20 | Analyst | 6000 | Amount |
| 20 | Clerk | 5100 | Amount |
| 20 | Manager | 2975 | Amount |
| 14075 | Dept Subtotal | ||
| 30 | Clerk | 950 | Amount |
| 30 | Manager | 2850 | Amount |
| 30 | Salesman | 5600 | Amount |
| 9400 | Dept Subtotal | ||
| 40 | Clerk | 1300 | Amount |
| 1300 | Dept Subtotal | ||
| Analyst | 6000 | Job Subtotal | |
| Clerk | 7350 | Job Subtotal | |
| Manager | 8275 | Job Subtotal | |
| President | 5000 | Job Subtotal | |
| Salesman | 5600 | Job Subtotal | |
| 32225 | Grand total |
Q. Display state-wise and within state gender-wise population and also display state-wise and gender-wise subtotals?
Q. Display year-wise and within year quarter-wise total amount and also display year-wise subtotals?
Note's:
- Column Alias in GROUP BY:
SELECT DATEPART(YY, HIREDATE) AS YEAR, COUNT(*) AS CNT FROM EMP GROUP BY DATEPART(YY, HIREDATE) /* valid */ ORDER BY YEAR ASC /* valid */
- Correction: Use the full expression (
DATEPART(YY, HIREDATE)) in theGROUP BYclause instead of the column alias (YEAR), because theGROUP BYclause is processed before theSELECTclause, where aliases are defined.
- Non-Aggregate Columns in SELECT:
SELECT DEPTNO, COUNT(*) AS CNT FROM EMP GROUP BY DEPTNO /* valid */
- Correction: Only include columns that are part of the
GROUP BYclause or are used in aggregate functions in theSELECTstatement. Including non-aggregated columns likeENAMEwithout grouping them will result in an error.GROUP BY Clause: Must include the actual expressions used, not column aliases.
SELECT Clause with GROUP BY: Should only include grouped columns and aggregate functions.
Semmary:-
Importance of
GROUP BY: Essential for aggregating data by specific columns to perform calculations like totals, averages, and counts for each group.Writing Queries Using
GROUP BY: Use it to group data and apply aggregate functions to those groups.
WHEREvsHAVING:WHEREfilters rows before grouping;HAVINGfilters groups after aggregation.Displaying Subtotals & Grand Total: Use
ROLLUPfor subtotals and grand total;CUBEfor subtotals across all possible combinations.
GROUPING_ID: Identifies the level of aggregation for each row in a result set.
Integrity Constraints:
Integrity constraints are rules enforced on database columns to maintain the accuracy, consistency, and reliability of the data stored in the database. These constraints prevent users from entering invalid data and ensure data quality.
Integrity constraints are rules to maintain data quality and consistency.
They prevent users from entering invalid data.
They enforce rules, such as a minimum balance of 1000.
Types of Integrity Constraints
NOT NULL:
Ensures that a column cannot have a NULL value.
Example:
Name VARCHAR(100) NOT NULL
UNIQUE:
Ensures that all values in a column are unique, meaning no two rows can have the same value for this column.
Example:
Email VARCHAR(255) UNIQUE
PRIMARY KEY:
A combination of NOT NULL and UNIQUE. It uniquely identifies each record in a table.
Example:
ID INT PRIMARY KEY
CHECK:
Ensures that all values in a column satisfy a specific condition.
Example:
Salary DECIMAL(10, 2) CHECK (Salary >= 1000)
FOREIGN KEY:
Ensures the referential integrity of the data in one table to match values in another table. It creates a link between the data in two tables.
Example:
DeptID INT, FOREIGN KEY (DeptID) REFERENCES Department(ID)
DEFAULT:
Provides a default value for a column when no value is specified.
Example:
Status VARCHAR(20) DEFAULT 'Active'
Declaring Constraints
Constraints can be declared at two levels:
Column level
Table level
Column Level:
Constraints are declared immediately after the column definition is called column level.
Suitable for constraints that apply to individual columns.
Syntax:
CREATE TABLE TableName (
ColumnName DataType(Size) CONSTRAINT
...
);
Example:
CREATE TABLE Employees (
ID INT PRIMARY KEY,
Name VARCHAR(100) NOT NULL,
Email VARCHAR(255) UNIQUE,
Salary DECIMAL(10, 2) CHECK (Salary >= 1000)
);
Table Level:
Constraints are declared after all column definitions.
Suitable for constraints that apply to multiple columns or involve relationships between tables.
Syntax:
CREATE TABLE TableName (
ColumnName1 DataType(Size),
ColumnName2 DataType(Size),
...
CONSTRAINT ConstraintName CONSTRAINT_TYPE (Columns)
);
Example:
CREATE TABLE Employees (
ID INT,
Name VARCHAR(100),
DeptID INT,
CONSTRAINT PK_Employee PRIMARY KEY (ID),
CONSTRAINT FK_Dept FOREIGN KEY (DeptID) REFERENCES Department(ID)
);
This structured approach helps in maintaining the integrity and reliability of the database by ensuring that data adheres to predefined rules.
NOT NULL:
The NOT NULL constraint ensures that a column cannot have a NULL value.
A field declared with NOT NULL is considered a mandatory field.
Example:
CREATE TABLE emp11 (
empno INT,
ename VARCHAR(10) NOT NULL
);
INSERT INTO emp11 VALUES (100, NULL); -- ERROR
INSERT INTO emp11 VALUES (101, 'A');
UNIQUE:
The UNIQUE constraint ensures that all values in a column are different.
A column with the UNIQUE constraint cannot have duplicate values.
Example:
CREATE TABLE cust (
custid INT,
cname VARCHAR(10) NOT NULL,
emailid VARCHAR(20) UNIQUE
);
INSERT INTO cust VALUES (100, 'A', 'abc@gmail.com');
INSERT INTO cust VALUES (101, 'B', 'abc@gmail.com'); -- ERROR
INSERT INTO cust VALUES (102, 'C', NULL);
INSERT INTO cust VALUES (103, 'D', NULL); -- ERROR
Note: Depending on the database system, the behavior of UNIQUE with NULLs may vary. Some databases might allow multiple NULLs in a UNIQUE column.
PRIMARY KEY:
The PRIMARY KEY constraint uniquely identifies each record in a table.
A primary key is a combination of UNIQUE and NOT NULL constraints.
Only one primary key is allowed per table.
The primary key column(s) must contain unique values and cannot contain NULLs.
Example:
CREATE TABLE emp13 (
empid INT PRIMARY KEY,
ename VARCHAR(10) NOT NULL
);
INSERT INTO emp13 VALUES (100, 'A');
INSERT INTO emp13 VALUES (100, 'B'); -- ERROR
INSERT INTO emp13 VALUES (NULL, 'C'); -- ERROR
Only one primary key is allowed per table. If you need multiple unique identifiers, declare one column as the primary key and the other columns with the UNIQUE and NOT NULL constraints.
Multiple Unique Columns Example:
CREATE TABLE cust (
custid INT PRIMARY KEY,
cname VARCHAR(10) NOT NULL,
aadharno NUMERIC(12) UNIQUE NOT NULL,
panno CHAR(10) UNIQUE NOT NULL
);
Difference between UNIQUE and PRIMARY KEY:
| UNIQUE | PRIMARY KEY |
| Allows one NULL value (varies by DBMS) | Does not allow NULL values |
| Multiple columns can have UNIQUE | Only one primary key per table |
| Creates a non-clustered index (by default) | Creates a clustered index (by default) |
This explanation helps to understand the purpose and behavior of the NOT NULL, UNIQUE, and PRIMARY KEY constraints in database tables, ensuring data integrity and uniqueness where necessary.
Candidate Key:
A candidate key is a field or combination of fields that can uniquely identify a record in a table and can be chosen as the primary key.
If a table has multiple candidate keys, one is selected as the primary key, and the others can be used as secondary or alternate keys.
A field eligible for primary key is called candidate key.
Example:
Table: VEHICLES
VEHNO NAME MODEL COST CHASSISNO 1 Car A X1 10000 123ABC 2 Car B X2 15000 456DEF
Candidate keys:
VEHNO,CHASSISNOPrimary key:
VEHNOSecondary key (or alternate key):
CHASSISNOWhen creating a table, secondary key columns are declared with
UNIQUE NOT NULL.
CHECK Constraint:
- The CHECK constraint ensures that all values in a column meet a specific condition.
Syntax:
CHECK (condition)
Examples:
- Salary must be a minimum of 3000:
CREATE TABLE emp15 (
empid INT PRIMARY KEY,
ename VARCHAR(10) NOT NULL,
sal MONEY CHECK(sal >= 3000)
);
INSERT INTO emp15 VALUES (100, 'A', 1000); -- ERROR
INSERT INTO emp15 VALUES (101, 'B', 5000);
INSERT INTO emp15 VALUES (102, 'C', NULL); -- CHECK constraint allows NULLs
- Gender must be 'm' or 'f':
gender CHAR(1) CHECK (gender IN ('m', 'f'))
- Amount must be a multiple of 100:
amt MONEY CHECK (amt % 100 = 0)
- Password must be a minimum of 6 characters:
pwd VARCHAR(10) CHECK (LEN(pwd) >= 6)
- Email ID must contain '@' and end with '.com', '.co', or '.in':
emailid VARCHAR(20) CHECK (emailid LIKE '%@%' AND
(emailid LIKE '%.com' OR
emailid LIKE '%.co' OR
emailid LIKE '%.in'))
**Q:**Password must:
Contain lowercase alphabets
* Contain uppercase alphabets
* Contain digits
* Contain
_,@, or$
CREATE TABLE users (
userid INT PRIMARY KEY,
pwd VARCHAR(20) CHECK (
pwd LIKE '%[a-z]%' AND
pwd LIKE '%[A-Z]%' AND
pwd LIKE '%[0-9]%' AND
(pwd LIKE '%[_]%' OR pwd LIKE '%@%' OR pwd LIKE '%$%')
)
);
FOREIGN KEY:
- A foreign key is used to establish a relationship between two tables.
Example:
Before normalization, the table EMP contains redundancy:
EMPNO | ENAME | SAL | DNO | DNAME | LOC
----------------------------------------
1 | A | 3000 | 10 | HR | BLR
2 | B | 3000 | 10 | HR | BLR
3 | C | 3000 | 10 | HR | BLR
The above table contains redundancy. To reduce redundancy, divide the table into two tables and establish a relationship by adding a foreign key.
To establish the relationship, take the primary key of one table and add it to the other table as a foreign key, declaring it with a references constraint.
Tables after normalization:
DEPT:
DNO | DNAME | LOC
-----------------
10 | HR | BLR
20 | IT | HYD
EMP:
EMPNO | ENAME | SAL | DNO
--------------------------
1 | A | 4000 | 10
2 | B | 3000 | 20
3 | C | 5000 | 90 => INVALID (90 is not in DEPT)
4 | D | 3000 | 10
5 | E | 2000 | NULL
Key Points:
To establish a relationship, take the primary key of one table (e.g.,
DEPT.DNO) and add it to another table (e.g.,EMP.DNO) as a foreign key with theREFERENCESconstraint.The values entered in the foreign key column (
EMP.DNO) should match values in the primary key column (DEPT.DNO).Foreign keys allow duplicates and null values.
Declaring a foreign key creates a parent/child relationship between two tables:
The table with the primary key is the parent (e.g.,
DEPT).The table with the foreign key is the child (e.g.,
EMP).
SQL Example:
Creating DEPT table:
CREATE TABLE DEPT55 (
DNO INT PRIMARY KEY, --Primary key
DNAME VARCHAR(10) UNIQUE NOT NULL
);
INSERT INTO DEPT55 VALUES (10, 'HR'), (20, 'IT');
Creating EMP table:
CREATE TABLE EMP55 (
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(10) NOT NULL,
SAL MONEY CHECK(SAL >= 3000),
DNO INT REFERENCES DEPT55(DNO)-- Foreign key
);
Inserting data into EMP table:
INSERT INTO EMP55 VALUES (1, 'A', 4000, 10);
INSERT INTO EMP55 VALUES (2, 'B', 3000, 90); -- ERROR: 90 is not in DEPT55.DNO
INSERT INTO EMP55 VALUES (3, 'C', 3000, 10);
INSERT INTO EMP55 VALUES (4, 'D', 5000, NULL); -- NULL is allowed
This corrected explanation clearly outlines how to establish relationships between tables using the foreign key constraint and includes relevant examples to demonstrate the concept.
Relationship Types:
One-to-One
One-to-Many
Many-to-One
Many-to-Many
- Default relationship in SQL Server: One-to-Many
One-to-One Relationship:
- To establish a one-to-one relationship, declare the foreign key with a unique constraint.
Example:
DEPT Table:
DNO | DNAME
-----------
10 | HR
20 | IT
MGR Table:
MGRNO | MNAME | DNO
-------------------
1 | A | 10
2 | B | 20
SQL Example:
Creating the DEPT table:
CREATE TABLE DEPT (
DNO INT PRIMARY KEY,
DNAME VARCHAR(10) NOT NULL
);
INSERT INTO DEPT VALUES (10, 'HR'), (20, 'IT');
Creating the MGR table:
CREATE TABLE MGR (
MGRNO INT PRIMARY KEY,
MNAME VARCHAR(10) NOT NULL,
DNO INT UNIQUE REFERENCES DEPT(DNO)
);
Inserting data intoMGR table:
INSERT INTO MGR VALUES (1, 'A', 10);
INSERT INTO MGR VALUES (2, 'B', 20);
Key Points:
The
DNOcolumn in theMGRtable is both a foreign key and unique. This ensures that each department (DEPT.DNO) is linked to exactly one manager (MGR.DNO), creating a one-to-one relationship.The
DNOcolumn in theMGRtable references theDNOcolumn in theDEPTtable and must be unique to keep the one-to-one relationship.
This explanation shows how to create a one-to-one relationship using a foreign key and a unique constraint, with examples to illustrate the concept.
Many-to-Many Relationship:
- To establish a many-to-many relationship, create a third table that includes the primary keys of both tables as foreign keys.
Example:
CUST Table:
CID | NAME | ADDR
-----------------
1 | A | HYD
2 | B | BLR
PRODUCTS Table:
PRODID | PNAME | PRICE
---------------------
100 | A | 500
101 | B | 200
SALES Table:
CID | PRODID | QTY
------------------
1 | 100 | 1
1 | 101 | 2
2 | 100 | 1
2 | 101 | 3
SQL Example:
Creating the CUST table:
CREATE TABLE CUST (
CID INT PRIMARY KEY,
NAME VARCHAR(10),
ADDR VARCHAR(20)
);
INSERT INTO CUST VALUES (1, 'A', 'HYD'), (2, 'B', 'BLR');
Creating the PRODUCTS table:
CREATE TABLE PRODUCTS (
PRODID INT PRIMARY KEY,
PNAME VARCHAR(10),
PRICE MONEY
);
INSERT INTO PRODUCTS VALUES (100, 'A', 500), (101, 'B', 200);
Creating the SALES table:
CREATE TABLE SALES (
CID INT,
PRODID INT,
QTY INT,
FOREIGN KEY (CID) REFERENCES CUST(CID),
FOREIGN KEY (PRODID) REFERENCES PRODUCTS(PRODID),
PRIMARY KEY (CID, PRODID)
);
INSERT INTO SALES VALUES (1, 100, 1), (1, 101, 2), (2, 100, 1), (2, 101, 3);
DEFAULT:
- A column can be declared with a default value as follows.
Example:
CREATE TABLE emp16 (
empno INT PRIMARY KEY,
ename VARCHAR(10) NOT NULL,
hiredate DATE DEFAULT GETDATE()
);
INSERT INTO emp16 (empno, ename) VALUES (100, 'A');
INSERT INTO emp16 VALUES (101, 'B', '2023-01-01');
INSERT INTO emp16 VALUES (102, 'C', NULL);
Out:-
EMPNO | ENAME | HIREDATE
------------------------
100 | A | 2023-10-06
101 | B | 2023-01-01
102 | C | NULL
Table Level:
Use table level to declare constraints for multiple columns or combinations of columns.
Table-level constraints are declared after all columns are defined.
Declaring Check Constraint at Table Level:
PRODUCTS Table:
prodid | pname | manufacture_dt| expiry_dt
-----------------------------------------------------
100 | A | 2023-10-01 | 2023-01-01 (INVALID)
Rule: expiry_dt > manufacture_dt
SQL Example:
CREATE TABLE PRODUCTS (
prodid INT PRIMARY KEY,
pname VARCHAR(10) NOT NULL,
manufacture_dt DATE,
expiry_dt DATE,
CHECK (expiry_dt > manufacture_dt)
);
INSERT INTO PRODUCTS VALUES (100, 'A', GETDATE(), '2023-01-01'); -- ERROR
INSERT INTO PRODUCTS VALUES (101, 'B', '2023-01-01', GETDATE()); -- 1 row affected
Composite Primary Key:
If a combination of columns declared as primary key, it is called a composite primary key.
In some tables, a combination of columns is needed to uniquely identify records, and that combination is declared as a primary key at the table level.
Example:
STUDENT Table:
SID | SNAME
-----------
1 | A
2 | B
COURSE Table:
CID | CNAME
-----------
10 | .NET
11 | SQL
REGISTRATIONS Table:
SID | CID | DOR | FEE
------------------------------
1 | 10 | 2023-10-07 | 1000
1 | 11 | 2023-10-07 | 1000
2 | 10 | 2023-10-07 | 1000
1 | 10 | 2023-10-07 | 1000 (ERROR)
SQL Example:
Creating the STUDENT table:
CREATE TABLE STUDENT (
SID INT PRIMARY KEY,
SNAME VARCHAR(10) NOT NULL
);
INSERT INTO STUDENT VALUES (1, 'A'), (2, 'B');
Creating the COURSE table:
CREATE TABLE COURSE (
CID INT PRIMARY KEY,
CNAME VARCHAR(10) NOT NULL
);
INSERT INTO COURSE VALUES (10, '.NET'), (11, 'SQL');
Creating the REGISTRATIONS table:
CREATE TABLE REGISTRATIONS (
SID INT REFERENCES STUDENT(SID),
CID INT REFERENCES COURSE(CID),
DOR DATE,
FEE MONEY,
PRIMARY KEY (SID, CID)
);
INSERT INTO REGISTRATIONS VALUES (1, 10, GETDATE(), 1000);
INSERT INTO REGISTRATIONS VALUES (1, 11, GETDATE(), 1000);
INSERT INTO REGISTRATIONS VALUES (2, 10, GETDATE(), 1000);
Question:
SALES Table:
DATEID | PRODID | CUSTID | QTY | AMT -------------------------------------- 2023-10-05 | 100 | 10 | 1 | 1000 2023-10-05 | 100 | 11 | 1 | 1000 2023-10-05 | 101 | 10 | 1 | 2000 2023-10-06 | 100 | 10 | 1 | 1000Identify the primary key and write the create table script.
Answer:
CREATE TABLE SALES ( DATEID DATE, PRODID INT, CUSTID INT, QTY INT, AMT MONEY, PRIMARY KEY (DATEID, PRODID, CUSTID) );
Composite Foreign Key:
If a combination of columns declared as a foreign key, it is called a composite foreign key.
A composite foreign key refers to a composite primary key.
Example:
REGISTRATIONS Table:
SID | CID | DOR | FEE
------------------------------
1 | 10 | 2023-10-07 | 1000
1 | 11 | 2023-10-07 | 1000
2 | 10 | 2023-10-07 | 1000
CERTIFICATES Table:
CERTNO | DOI | SID | CID
-----------------------------
1000 | 2023-10-07 | 1 | 10
1001 | 2023-10-07 | 1 | 11
1002 | 2023-10-07 | 2 | 11
In the above table SID,CID combination should match with registrations table SID,CID combination.
SQL Example:
Creating the REGISTRATIONS table:
CREATE TABLE REGISTRATIONS (
SID INT REFERENCES STUDENT(SID),
CID INT REFERENCES COURSE(CID),
DOR DATE,
FEE MONEY,
PRIMARY KEY (SID, CID)
);
Creating the CERTIFICATES table:
CREATE TABLE CERTIFICATES (
CERTNO INT PRIMARY KEY,
DOI DATE,
SID INT,
CID INT,
FOREIGN KEY (SID, CID) REFERENCES REGISTRATIONS(SID, CID)
);
INSERT INTO CERTIFICATES VALUES (1000, GETDATE(), 2, 11); -- ERROR
Q. Which of the following constraints cannot be declared at the table level?
A. UNIQUE
B.) CHECK
C.) NOT NULL
D.) PRIMARY KEY
E.) FOREIGN KEY
Answer: C
Q. Which statements are true regarding constraints?
A.) A foreign key cannot contain NULL value - F
B.) A column with UNIQUE constraint can contain NULL value - T
C.) A constraint is enforced only for the INSERT operation on a table - F
D.) All constraints can be defined at the column level and table level - F
Q. Which CREATE TABLE statement is valid?
A.)
CREATE TABLE ord_details ( ord_no NUMERIC(2) PRIMARY KEY, item_no NUMERIC(3) PRIMARY KEY, ord_date DATE NOT NULL );B.)
CREATE TABLE ord_details ( ord_no NUMERIC(2) UNIQUE, NOT NULL, item_no NUMERIC(3), ord_date DATE DEFAULT GETDATE() NOT NULL );C.)
CREATE TABLE ord_details ( ord_no NUMERIC(2), item_no NUMERIC(3), ord_date DATE DEFAULT NOT NULL, UNIQUE (ord_no), PRIMARY KEY (ord_no) );D.)
CREATE TABLE ord_details ( ord_no NUMERIC(2), item_no NUMERIC(3), ord_date DATE DEFAULT GETDATE() NOT NULL, PRIMARY KEY (ord_no, item_no) );Answer: D
Adding Constraints to Existing Table:
Using the ALTER Command to Add Constraints to an Existing Table
CREATE TABLE EMP33
(
EMPNO INT,
ENAME VARCHAR(10),
SAL MONEY,
DNO INT,
EMAILID VARCHAR(20)
);
Adding a Primary Key
Primary key cannot be added to a nullable column.
To add a primary key, first change the column to
NOT NULL.
Step 1: Change the column to NOT NULL
ALTER TABLE EMP33
ALTER COLUMN EMPNO INT NOT NULL;
Step 2: Add the primary key
ALTER TABLE EMP33
ADD PRIMARY KEY (EMPNO);
Adding a Check Constraint
- Add a check constraint to ensure
SAL >= 3000.
ALTER TABLE EMP33
ADD CHECK (SAL >= 3000);
Note: The command below returns an error if existing data violates the constraint (above command returns error because in table some of the employee salaries are less than 3000 . While adding constraint sql server also validates existing data).
ALTER TABLE EMP
ADD CHECK (SAL >= 3000); -- ERROR
Solution: Add the check constraint with WITH NOCHECK to avoid validation of existing data.
WITH NOCHECK:
If a check constraint is added "WITH NOCHECK," SQL Server will not validate existing data; it will only validate new data.
ALTER TABLE EMP
WITH NOCHECK
ADD CHECK (SAL >= 3000);
Adding a Foreign Key
- Add a foreign key to
DNOthat references the primary keyDNOofDEPT55table.
ALTER TABLE EMP33
ADD FOREIGN KEY (DNO) REFERENCES DEPT55 (DNO);
Adding a Unique Constraint
- Add a unique constraint to
EMAILID.
ALTER TABLE EMP33
ADD UNIQUE (EMAILID);
Changing from NULL to NOT NULL
- Modify the column
ENAMEtoNOT NULL.
ALTER TABLE EMP33
ALTER COLUMN ENAME VARCHAR(10) NOT NULL;
Dropping Constraints
- Drop a constraint using the following syntax:
ALTER TABLE <tabname>
DROP CONSTRAINT <name>;
Example: Drop a check constraint in EMP33.
ALTER TABLE EMP33
DROP CONSTRAINT CK__EMP33__SAL__693CA210;
Example: Drop the primary key in the DEPT55 table.
ALTER TABLE DEPT55
DROP CONSTRAINT PK__DEPT55__C035B8C2CC99E6C6; -- ERROR
DROP TABLE DEPT55 => ERROR
TRUNCATE TABLE DEPT55 => ERROR
Note:
A primary key cannot be dropped if referenced by some foreign key.
The primary key table cannot be dropped if it referenced by some foreign key.
The primary key table cannot be truncated if referenced by some foreign key.
DELETE Rules
Declaring DELETE Rules with Foreign Keys
ON DELETE NO ACTION (DEFAULT)
ON DELETE CASCADE
ON DELETE SET NULL
ON DELETE SET DEFAULT
These rules are declared with foreign keys.
DELETE rules specify how child rows are affected when a parent row is deleted.
ON DELETE NO ACTION
- Parent row cannot be deleted if associated with child rows.
CREATE TABLE DEPT88
(
DNO INT PRIMARY KEY,
DNAME VARCHAR(10) UNIQUE NOT NULL
);
INSERT INTO DEPT88 VALUES (10, 'HR'), (20, 'IT');
CREATE TABLE EMP88
(
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(10) NOT NULL,
DNO INT REFERENCES DEPT88(DNO)
);
INSERT INTO EMP88 VALUES (1, 'A', 10), (2, 'B', 10);
DELETE FROM DEPT88 WHERE DNO = 10; -- ERROR
Scenario:
- ACCOUNTS Table
| ACCNO | ACTYPE | BAL |
| 100 | S | 10000 |
- LOANS Table
| ID | TYPE | AMT | ACCNO |
| 1 | H | 30 | 100 |
| 2 | C | 10 | 100 |
Rule: Account closing is not possible if associated with loans.
ON DELETE CASCADE
- Parent row is deleted along with child rows.
CREATE TABLE DEPT88
(
DNO INT PRIMARY KEY,
DNAME VARCHAR(10) UNIQUE NOT NULL
);
INSERT INTO DEPT88 VALUES (10, 'HR'), (20, 'IT');
CREATE TABLE EMP88
(
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(10) NOT NULL,
DNO INT REFERENCES DEPT88(DNO) ON DELETE CASCADE
);
INSERT INTO EMP88 VALUES (1, 'A', 10), (2, 'B', 10);
DELETE FROM DEPT88 WHERE DNO = 10; -- 1 ROW AFFECTED
SELECT * FROM EMP88; -- NO ROWS
Scenario:
- ACCOUNTS Table
| ACCNO | ACTYPE | BAL |
| 100 | S | 10000 |
- TRANS Table
| TRID | TTYPETDATE | TAMT | ACCNO |
| 1 | W | 100 | ON DELETE CASCADE |
| 2 | D | 100 |
ON DELETE SET NULL
- Parent row is deleted but child rows are not deleted; foreign key will be set to NULL.
CREATE TABLE DEPT88
(
DNO INT PRIMARY KEY,
DNAME VARCHAR(10) UNIQUE NOT NULL
);
INSERT INTO DEPT88 VALUES (10, 'HR'), (20, 'IT');
CREATE TABLE EMP88
(
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(10) NOT NULL,
DNO INT REFERENCES DEPT88(DNO) ON DELETE SET NULL
);
INSERT INTO EMP88 VALUES (1, 'A', 10), (2, 'B', 10);
DELETE FROM DEPT88 WHERE DNO = 10; -- 1 ROW AFFECTED
SELECT * FROM EMP88;
-- Result:
-- ENO | ENAME | DNO
-- ----|-------|-----
-- 1 | A | NULL
-- 2 | B | NULL
Scenario:
- PROJECTS Table
| PROJID | NAME | DURATION |
| 100 | Project | |
| 101 | Project |
- EMP Table
| EMPNO | ENAME | PROJID |
| 1 | 100 | |
| 2 | 101 |
Rule: If the project is completed (deleted), set the employee PROJID to NULL.
ON DELETE SET DEFAULT
- Parent row is deleted but child rows are not deleted; foreign key will be set to default value.
CREATE TABLE DEPT88
(
DNO INT PRIMARY KEY,
DNAME VARCHAR(10) UNIQUE NOT NULL
);
INSERT INTO DEPT88 VALUES (10, 'HR'), (20, 'IT');
CREATE TABLE EMP88
(
EMPNO INT PRIMARY KEY,
ENAME VARCHAR(10) NOT NULL,
DNO INT DEFAULT 20 REFERENCES DEPT88(DNO) ON DELETE SET DEFAULT
);
INSERT INTO EMP88 VALUES (1, 'A', 10), (2, 'B', 10);
Summary
Importance of Constraints
- Constraints ensure data integrity and consistency.
Types of Constraints
Primary Key
Foreign Key
Unique
Not Null
Check
Default
Declaring Constraints
Column Level
- Declared within the column definition.
Table Level
- Declared after all columns are defined.
Adding Constraints
- Use
ALTER TABLEto add constraints to existing tables.Dropping Constraints
- Use
ALTER TABLE <tabname> DROP CONSTRAINT <name>to remove constraints.DELETE Rules
ON DELETE NO ACTION: Prevent deletion if child rows exist.
ON DELETE CASCADE: Delete child rows when parent row is deleted.
ON DELETE SET NULL: Set foreign key to NULL when parent row is deleted.
ON DELETE SET DEFAULT: Set foreign key to default value when parent row is deleted.
JOINS:
Subscribe to my newsletter
Read articles from Mritunjay Kumar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by