A Step-by-Step Guide to Random Forest in Machine Learning
 Arbash Hussain
Arbash HussainTable of contents
- Introduction
- What is Random Forest?
- Random Forest for Regression and Classification
- Implementation Steps
- Step 1: Class Initialization
- Step 2: Fit Method
- Step 3: Create Samples Method
- Step 4: Majority Vote Method
- Step 5: Predict Method
- Step 6: Accuracy and MSE Functions
- Example Usage
- Output
- Common Misconceptions about Random Forest
- When to Apply Random Forest
- Advantages of Random Forest
- Disadvantages of Random Forest
- Conclusion

Introduction
Welcome to the sixth blog post in our machine learning series! Today, we will explore Random Forest, a powerful and versatile algorithm used for both classification and regression tasks. As always, we will also implement this algorithm from scratch in Python. By the end of this blog, you will have a comprehensive understanding of Random Forest, its mathematical intuition, and when to use it.
Prerequisite: Decision Trees
Implementation code on my GitHub.
What is Random Forest?
Random Forest is an ensemble learning method used for classification and regression tasks. It works by training multiple decision trees in parallel and then outputting the most common class (for classification) or the average prediction (for regression) of the individual trees. Random Forest uses bagging (bootstrap aggregation) as its ensemble learning technique, where multiple models (decision trees) are trained on different subsets of the data and features, and their outputs are combined for final predictions.
Ensemble Learning and Bagging
Ensemble learning is a technique where multiple models are trained and combined to solve a problem, improving the model's performance. Bagging, specifically, involves creating multiple versions of a predictor and using these to get an aggregated predictor. This helps reduce variance and makes the model more robust.
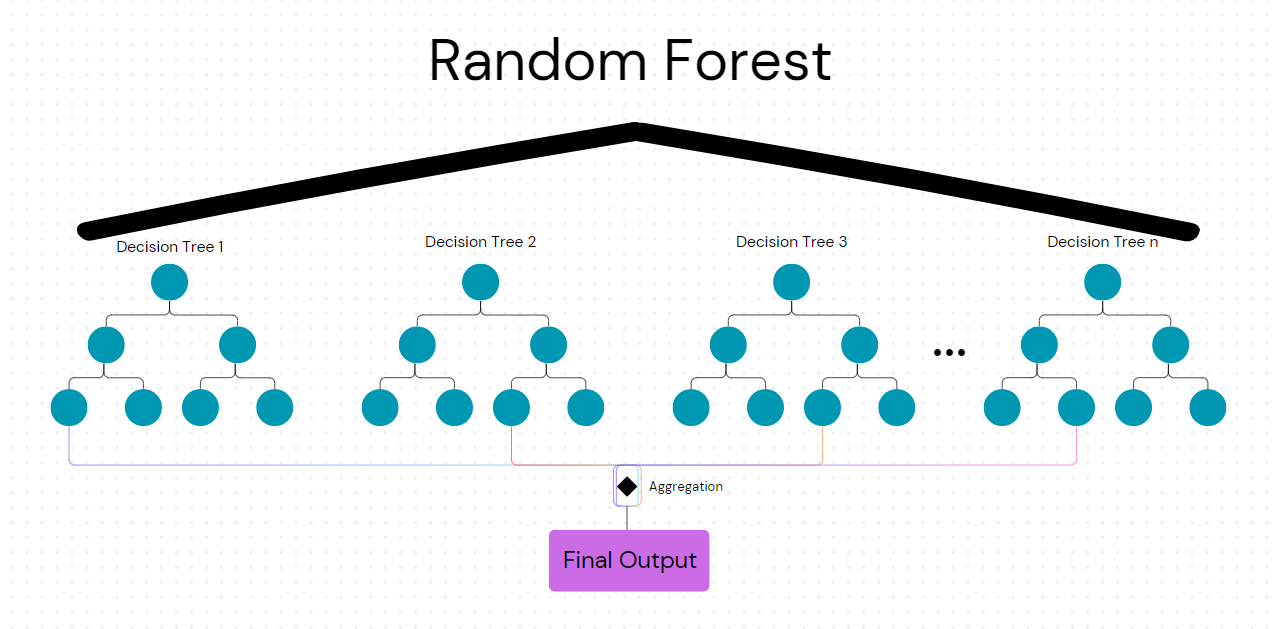
Random Forest for Regression and Classification
Random Forest can be used for both classification and regression tasks.
Classification
Training Phase:
A random subset of the training data is selected (with replacement) to create each tree.
For each tree, a random subset of features is chosen at each split.
Each tree is trained on its subset to produce a decision tree classifier.
Prediction Phase:
Each tree makes a classification for a given input.
The final classification is determined by the majority vote of all trees.
Regression
Training Phase:
Similar to classification, a random subset of the training data is used to create each tree.
Each tree is trained on its subset to produce a decision tree regressor.
Prediction Phase:
Each tree makes a prediction for a given input.
The final prediction is the average of all tree predictions.
Mathematical Intuition
Classification
Each decision tree is created by selecting random subsets of features and training data.
The final classification for a new data point is based on the majority vote of all the trees.
Regression
Each decision tree predicts a continuous value for a given input.
The final prediction is the average of all the tree predictions.
Note: When we say each Decision Tree is built with a random subset of features, it doesn't mean that only a random subset of features is sent to the tree. In fact, all the features are sent, but during the splitting process, only a limited random number of features are considered for each split.
Hyperparameters in Random Forest
Random Forest has several hyperparameters that can be adjusted to improve performance. Some of the important ones are:
Number of Trees (
n_trees): The number of decision trees in the forest.Maximum Depth (
max_depth): The maximum depth of each tree.Minimum Samples Split (
min_sample_split): The minimum number of samples required to split a node.Number of Features (
n_feature): The number of features to consider when looking for the best split.
Implementation Steps
Step 1: Class Initialization
We initialize the Random_Forest class with parameters like the number of trees, maximum depth, minimum samples for a split, and the number of features.
class Random_Forest:
def __init__(self, task='classification', n_trees=10, max_depth=10, min_sample_split=2, n_feature=None):
self.n_trees = n_trees
self.max_depth = max_depth
self.min_sample_split = min_sample_split
self.n_feature = n_feature
self.trees = []
self.task = task
Step 2: Fit Method
The fit method creates each decision tree by sampling the data and fitting the tree on the sampled data.
Decision_Treeis a separate class that is imported. It was explained in a previous blog. Its code can be found here.
def fit(self, X, y):
for _ in range(self.n_trees):
dt = Decision_Tree(max_depth=self.max_depth,
min_sample_split=self.min_sample_split,
n_features=self.n_feature)
X_sampled, y_sampled = self.create_samples(X, y)
dt.fit(X_sampled, y_sampled)
self.trees.append(dt)
Step 3: Create Samples Method
The create_samples method randomly selects samples with replacement from the training data.
def create_samples(self, X, y):
n_samples = X.shape[0]
indices = np.random.choice(n_samples, n_samples, replace=True)
return X[indices], y[indices]
Step 4: Majority Vote Method
For classification tasks, the majority_vote method determines the most common prediction among the trees.
def majority_vote(self, y):
counter = Counter(y)
return counter.most_common(1)[0][0]
Step 5: Predict Method
The predict method predicts the class or regression value for the input data by aggregating predictions from all trees.
- Here, the
swapaxesfunction changes the shape oftree_predsso that the predictions for each sample are grouped together.
def predict(self, X):
if self.task == "classification":
tree_preds = np.array([tree.predict(X) for tree in self.trees])
tree_preds = np.swapaxes(tree_preds, 0, 1)
predictions = np.array([self.majority_vote(tree_pred) for tree_pred in tree_preds])
return predictions
else:
tree_preds = np.array([tree.predict(X) for tree in self.trees])
tree_preds = np.swapaxes(tree_preds, 0, 1)
predictions = np.array([np.mean(tree_pred) for tree_pred in tree_preds])
return predictions
Step 6: Accuracy and MSE Functions
These functions calculate the accuracy for classification and mean squared error for regression, respectively.
def accuracy_score(y_true, y_pred):
return np.sum(y_true == y_pred) / len(y_true)
def mse(y_true, preds):
return np.mean((y_true - preds)**2)
Example Usage
Classification Example
if __name__ == "__main__":
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
#* Classification
X, y = load_breast_cancer(return_X_y = True)
X_train, X_test, y_train, y_test = train_test_split(X,y,test_size = 0.2, random_state = 42)
rf = Random_Forest(n_trees = 10)
rf.fit(X_train,y_train)
preds = rf.predict(X_test)
print("Classification")
print("Accuracy:",accuracy_score(y_test,preds))
Regression Example
if __name__ == "__main__":
from sklearn.model_selection import train_test_split
#* Regression
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
X_train, X_test, y_train, y_test = train_test_split(data,target,test_size = 0.2, random_state = 42)
rf = Random_Forest(n_trees = 10, task = 'regression')
rf.fit(X_train,y_train)
preds = rf.predict(X_test)
print("Regression")
print("Mean Squared Error:",mse(y_test,preds))
Output

Common Misconceptions about Random Forest
Overfitting: Random Forest is less likely to overfit compared to individual decision trees due to the averaging of multiple trees.
Complexity: While the algorithm may seem complex, it is essentially a collection of simple decision trees.
When to Apply Random Forest
When you need high accuracy and can afford to sacrifice interpretability.
When you have a large dataset with many features.
When you want a robust model that generalizes well to unseen data.
When other supervised algorithms do not generalize well on the data.
Advantages of Random Forest
High Accuracy: Due to the ensemble method.
Robustness: Less likely to overfit.
Versatility: Can be used for both classification and regression tasks.
Disadvantages of Random Forest
Complexity: Harder to interpret compared to a single decision tree.
Computational Cost: More resource-intensive due to multiple trees.
Conclusion
I hope this guide is useful to you. If so, please like and follow. You can also check out my other blogs in my series on machine learning algorithms. Try implementing these algorithms on your own datasets and share your experiences in the comments!
Subscribe to my newsletter
Read articles from Arbash Hussain directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Arbash Hussain
Arbash Hussain
I'm a Computer Science Engineer with a passion for data science and AI. My interest for computer science has motivated me to work with various tech stacks like Flutter, Next.js, React.js, Pygame and Unity. For data science projects, I've used tools like MLflow, AWS, Tableau, SQL, and MongoDB, and I've worked with Flask and Django to build data-driven applications. I'm always eager to learn and stay updated with the latest in the field. I'm looking forward to connecting with like-minded professionals and finding opportunities to make an impact through data and AI.