Scraping the Web Like a Boss with ScrapeGraphAI
 Lê Đức Minh
Lê Đức MinhTable of contents
Harness the Power of AI to Automate Your Data Collection
Introduction
My previous postings focused heavily on leveraging external tools to increase the quality of the end output while applying the Augmented Language Models framework. However, I realized that I did not mention any tools, particularly. While a framework is made up of a stack of components, each one plays an important part in ensuring the system's robust functioning. As a result, I will begin my adventure with web scraping.
Imagine trying to unlock a treasure chest with a rusty old key. Traditional web scraping is a lot like that – we need to know the right "key" (like HTML syntax) to access the data we want. This can be a real headache!
Traditional scraping often requires coding knowledge and an understanding of web technologies. It's like needing to be a locksmith just to get to the treasure inside. Plus, websites are constantly changing, so our scraper might break if the website's structure updates. It's like the lock on the chest keeps changing! And let's not forget the time and resources it takes. Building and maintaining a scraper can be a huge undertaking, especially for complex websites.
But what if there was a magic spell that could open any chest, no matter the lock? That's what LLMs are doing for web scraping! These powerful AI models can understand information from any website, regardless of its format. By combining LLMs with scraping tools, we're unlocking a new era of data access—faster, easier, and more intuitive than ever before. No more rusty keys or broken locks!

ScrapeGraphAI’s logo.
Meet ScrapeGraphAI, an open-source Python package that aims to redefine scraping technologies. In today's data-intensive digital world, this library stands out by combining Large Language Models (LLMs) with modular graph-based pipelines to automate data scraping from a variety of sources (e.g., websites, local files). Simply provide the information we want to extract, and ScrapeGraphAI will do the rest, delivering a more versatile and low-maintenance solution than standard scraping solutions.
The content of this writing is structured as follows:
ScrapeGraphAI: I make a brief introduction ScrapeGraphAI, including what it is, why it matters, and some interesting functions of this fascinating library.
Code Implementation: I will conduct an experiment as a showcase of what ScrapeGraphAI is capable of.
Conclusion: I conclude our journey as well as discuss the potential of ScrapeGraphAI in products.
I’ll leave ScrapeGraphAI’s documentations here. I highly suggest the .onrender version; it appears to be more detailed than its .readthedocs version:
Read the docs: https://scrapegraph-ai.readthedocs.io/en/latest/introduction/overview.html
Website: https://scrapegraph-doc.onrender.com/docs/category/graphs
ScrapeGraphAI
We stand on the precipice of a new era in web data extraction, an era powered by the intelligence of Large Language Models (LLMs). ScrapeGraphAI, an open-source Python library, ushers in this revolution by seamlessly blending LLMs and graph logic to automate the creation of scraping pipelines. Unlike traditional tools that struggle with website structure changes, ScrapeGraphAI adapts and evolves, ensuring consistent data extraction with minimal human intervention.
I believe this is a game-changer for anyone seeking to harness the vast ocean of information available online. ScrapeGraphAI supports a diverse range of LLMs, including industry giants like GPT and Gemini, as well as local models through Ollama. Our ability to handle various document formats, from XML and HTML to JSON and beyond, makes ScrapeGraphAI the ultimate tool for unlocking insights hidden within the digital world.
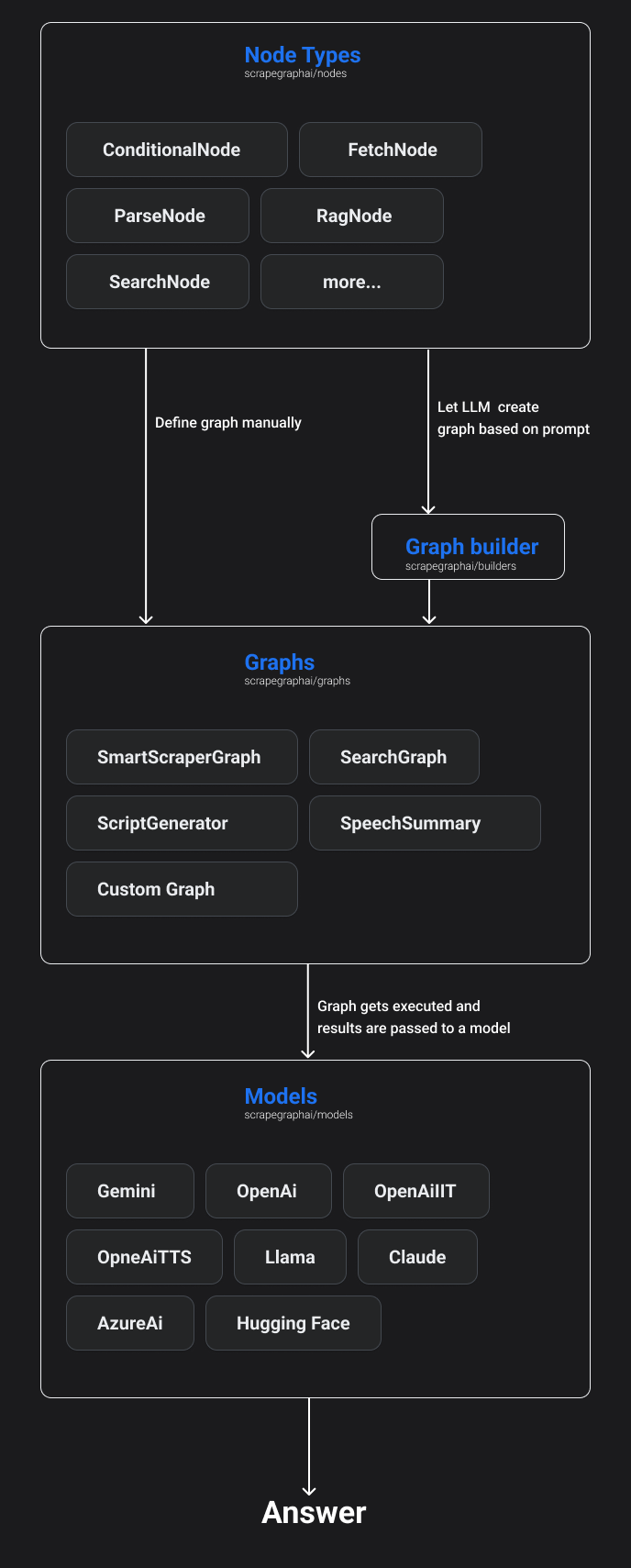
ScrapeGraphAI handles the context window limit of LLMs by breaking down large websites/documents into pieces with overlaps and using compression techniques to decrease the number of tokens. If numerous chunks are available, it will have various responses to the user query; therefore, it will combine them in the last phase of the scraping pipeline.
ScrapeGraphAI's design, as seen in the Figure, is graph-based. It means that the entire process is broken down by connecting discrete nodes in charge of various tasks. Those nodes would be sent to two additional components: the Graph, which defines the scraping process, and the GraphBuilder, which lets LLMs get a graph based on the prompt. The GraphBuilder result is then concatenated with the graph. Finally, the Graph is performed, and the results are provided to an LLM model for interpretation.
ScrapeGraph crafts for us several “on-ready” pipelines that we can use easily. There are several types of graphs available in the library, each with its own purpose and functionality. The most common ones are:
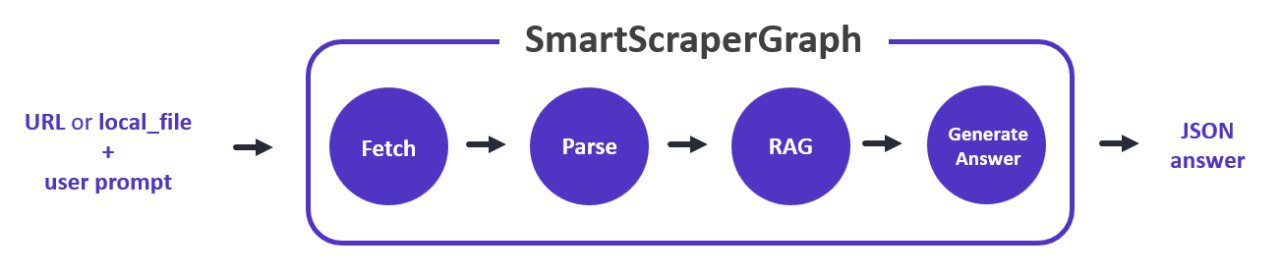
SmartScraperGraph: one-page scraper that requires a user-defined prompt and a URL (or local file) to extract information using LLM.
SearchGraph: multi-page scraper that only requires a user-defined prompt to extract information from a search engine using LLM. It is built on top of SmartScraperGraph.
SpeechGraph: text-to-speech pipeline that generates an answer as well as a requested audio file. It is built on top of SmartScraperGraph and requires a user-defined prompt and a URL (or local file).
ScriptCreatorGraph: script generator that creates a Python script to scrape a website using the specified library (e.g. BeautifulSoup). It requires a user-defined prompt and a URL (or local file).
There are also two additional graphs that can handle multiple sources:
SmartScraperMultiGraph: similar to SmartScraperGraph, but with the ability to handle multiple sources.
ScriptCreatorMultiGraph: similar to ScriptCreatorGraph, but with the ability to handle multiple sources.
With the introduction of GPT-4o, two new powerful graphs have been created:
OmniScraperGraph: similar to SmartScraperGraph, but with the ability to scrape images and describe them.
OmniSearchGraph: similar to SearchGraph, but with the ability to scrape images and describe them.
Code Implementation
In this experiment, we will use ScrapeGraphAI to summarize a blog post. We will use Ollama for the embedding and the LLMs, therefore, visit this post to learn how to install Ollama. The machine I used for this experiment utilizes Linux.
For models choice, we use:
LLMs: llama3
Embedding model: nomic-embed-text
Note: I chose to run Ollama because it seemed to be working flawlessly right now. I've tried HuggingFaceAPI, Gemini, and Groq, but they always fail me. I believe the developers will address this issue in the near future.
To begin with, we would install dependencies. ScrapeGraphAI is built on top of LangChain; therefore, the library would take us a while to download the whole package.
pip install scrapegraphai nest_asyncio playwright
apt install chromium-chromedriver
Some may ask that those packages seem to relate nothing to what we want to do; besides, why do need to install the chrome-driver. Answering those questions, ScrapeGraphAI uses playwright as the backend engine for scraping the web. The chrome-driver is a stand-alone server that uses the W3C WebDriver specification. WebDriver is an open-source tool for automated testing of online applications across many browsers. Its interface enables the control and introspection of user agents locally or remotely via capabilities.
Note: the nest_asyncio is installed for solving the asyncio routine conflix. It was the issue #179. I stuck on it and using the library can solve the problem.
Now, let’s call important libraries
import json
from scrapegraphai.graphs import SmartScraperGraph
import nest_asyncio
nest_asyncio.apply()
The configuration of the graph is easily implemented as follows:
graph_config = {
"llm": {
"model": "ollama/llama3",
"temperature": 0,
"format": "json", # Ollama needs the format to be specified explicitly
"base_url": "http://localhost:11434", # set Ollama URL
},
"embeddings": {
"model": "ollama/nomic-embed-text",
"base_url": "http://localhost:11434", # set Ollama URL
},
"verbose": True,
}
Now is the moment of truth, can it run or not?
search_url = "https://lilianweng.github.io/posts/2023-10-25-adv-attack-llm/"
search_prompt = "Summary the article into 3 paragraphs, including an introduction, a brief discussion about the blog and a conclusion."
smart_scraper_graph = SmartScraperGraph(
prompt=search_prompt,
source=search_url,
config=graph_config
)
result = smart_scraper_graph.run()
output = json.dumps(result, indent=2)
line_list = output.split("\n") # Sort of line replacing "\n" with a new line
for line in line_list:
print(line)
"""
{
"summary": [
{
"paragraph1": "The article discusses the recent advancements in large language models (LLMs) and their potential impact on the field of artificial intelligence. The author highlights the impressive capabilities of these models, which have been trained on vast amounts of text data."
},
{
"paragraph2": "The blog post also touches on the topic of adversarial attacks on LLMs, exploring the ways in which malicious actors might exploit these models' vulnerabilities to manipulate their outputs. The author emphasizes the importance of developing robust defenses against such attacks."
},
{
"paragraph3": "In conclusion, the article provides a thought-provoking analysis of the current state of LLMs and the challenges they pose for AI researchers. By examining both the benefits and risks associated with these models, the author encourages readers to consider the broader implications of their development."
}
]
}
"""
To be honest, the result is beyond what I would expect. I took around 2–3 minutes (on my machine). The reason for that latency is because of the process of SmartScraperGraph. It suffers from 4 nodes, including: Fetching, Parsing, RAG (for reference), and Generating answers.
Conclusion
ScrapeGraphAI ushers in a new era of web scraping, democratizing access to online information with its intuitive LLM-powered approach. Its ability to adapt to website changes, handle diverse document formats, and offer a range of specialized graphs makes it a versatile tool for researchers, developers, and anyone seeking to unlock the wealth of information hidden within the digital landscape. By providing the code and walking through its implementation, we aim to empower the harnessing of this powerful tool for our own data extraction needs.
However, as with any technology, it's crucial to approach ScrapeGraphAI with a critical eye. Understanding its limitations, such as the potential for bias in LLM outputs and the need for careful prompt engineering, is essential for responsible and accurate data extraction. Continuous refinement and validation of results remain paramount.
Despite these challenges, ScrapeGraphAI's potential is undeniable. By providing the code and guiding you through its implementation, we encourage you to explore its capabilities firsthand. Experiment with different graphs, fine-tune your prompts, and discover the transformative power of LLM-driven web scraping. The future of data extraction is here, and it's waiting to be explored.
Subscribe to my newsletter
Read articles from Lê Đức Minh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by