Prediksi Harga Rumah dengan Decision Tree Regressor
 Muhammad Ihsan
Muhammad Ihsan
Pendahuluan
Decision Tree adalah salah satu algoritma yang sangat populer dalam machine learning, digunakan baik untuk masalah klasifikasi maupun regresi. Pada artikel ini, kita akan fokus pada Decision Tree Regression terlebih dahulu. Decision Tree Regression adalah algoritma yang memetakan fitur dari dataset untuk memprediksi nilai kontinu (seperti harga rumah, suhu, dll.). Decision Tree di sini memecah data ke dalam subset yang lebih kecil dan semakin kecil dan di saat yang sama dibuat suatu pohon keputusan secara bertahap. Hasil akhirnya adalah sebuah pohon dengan simpul daun dan cabang.
Bagaimana Suatu Decision Tree Bekerja?
Sebuah decision tree terdiri dari tiga jenis node:
Root Node: Node pertama yang memulai pembagian.
Internal Node: Node di dalam pohon yang memisahkan data berdasarkan fitur tertentu.
Leaf Node: Node terakhir yang memberikan prediksi nilai target.
Dalam membangun suatu decision tree, terdapat beberapa tahapan yang terjadi:
Pemilihan Fitur: Memilih fitur yang paling signifikan untuk memisahkan data pada setiap langkah.
Kriteria Pembagian: Menentukan bagaimana memisahkan data pada setiap simpul.
Pembentukan Simpul: Ulangi proses pemisahan sampai memenuhi kriteria tertentu (misalnya, jumlah maksimum kedalaman pohon atau jumlah minimum sampel dalam simpul).
Kriteria Pembagian
Salah satu aspek paling penting dari Decision Tree Regression adalah memilih cara terbaik untuk memisahkan data di setiap simpul. Untuk regresi, biasanya digunakan Mean Squared Error (MSE) sebagai kriteria pembagian.
Rumus Mean Squared Error (MSE):
\( \text{MSE} = \frac{1}{N} \sum_{i=1}^{N} (y_i - \hat{y}_i)^2\)
dimana:
\(N\) adalah jumlah sampel
\(y_i\) adalah nilai target aktual
\(\hat y_i\) adalah nilai prediksi
Algoritma akan mencari pembagian yang meminimalkan MSE pada setiap simpul.
Pemilihan Fitur dan Pembagian
Proses pemilihan fitur melibatkan perhitungan MSE untuk setiap fitur dan titik pembagian yang mungkin. Misalnya, jika kita memiliki fitur X dengan nilai-nilai \([1, 2, 3, 4, 5]\) dan nilai target Y dengan nilai-nilai \([5, 4, 3, 2, 1]\), kita dapat mencoba berbagai titik pembagian seperti \(X < 2.5\), \(X < 3.5\), dll., dan menghitung MSE untuk setiap pembagian. Pembagian dengan MSE terendah akan dipilih.
Setelah fitur dan titik pembagian dipilih, data dipecah menjadi dua subset berdasarkan pembagian tersebut. Proses ini diulang terus menerus pada setiap subset sampai memenuhi kriteria penghentian tertentu, seperti kedalaman maksimum pohon atau jumlah minimum sampel dalam simpul.
Misalkan kita memiliki dataset sederhana dengan fitur X dan nilai target Y:
| X | Y |
| 1 | 5 |
| 2 | 4 |
| 3 | 3 |
| 4 | 2 |
| 5 | 1 |
Kita ingin memprediksi nilai Y menggunakan Decision Tree Regression. Berikut langkah-langkahnya:
Memilih Fitur dan Pembagian:
Cobalah pembagian di ( X < 2.5 ):
Kiri: X = [1, 2] , Y = [5, 4]
Kanan: X = [3, 4, 5] , Y = [3, 2, 1]
Hitung MSE untuk pembagian ini:
\(\text{MSE}_{left} = \frac{1}{2} ((5 - 4.5)^2 + (4 - 4.5)^2) = 0.25\)
\(\text{MSE}_{ right} = \frac{1}{3} ((3 - 2)^2 + (2 - 2)^2 + (1 - 2)^2) = 0.67\)
\( \text{MSE}_{total} = \frac{2}{5} \times 0.25 + \frac{3}{5} \times 0.67 = 0.47\)
Membuat Simpul:
- Pembagian ( X < 2.5 ) memberikan MSE total terendah, jadi kita memecah data pada titik tersebut.
Proses ini diulang untuk subset yang dihasilkan sampai kriteria penghentian terpenuhi.
Kelebihan dan Kekurangan
Sebagaimana model machine learning pada umumnya. Decision Tree juga memiliki kelebihan dan kekurangannya. Decision Tree mudah diinterpretasikan dan divisualisasikan. Decision tree juga dapat menangani hubungan non-linear antara fitur dan target. Algoritma decision tree juga akan secara otomatis memilih fitur yang paling signifikan untuk melakukan prediksi.
Adapun kekurangannya antara lain hasil decision tree cenderung overfitting pada data training, terutama jika kita tidak mengatur kedalamannya. Selain itu, decision tree juga sangat sensitif terhadap perubahan kecil dalam data., perubahan kecil dapat menghasilkan struktur pohon yang sangat berbeda.
Studi Kasus : Prediksi Harga Rumah
Kode di bawah ini adalah contoh implementasi model Decision Tree Regressor menggunakan dataset House Prices dari Kaggle. Langkah-langkahnya mencakup loading data, eksplorasi data, penanganan missing values, pemisahan data, pelatihan model, evaluasi model, dan visualisasi hasil.
Import Libraries
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeRegressor
from sklearn.metrics import mean_squared_error, r2_score
pandas dan numpy digunakan untuk manipulasi data.
matplotlib dan seaborn digunakan untuk visualisasi.
train_test_split dari sklearn digunakan untuk membagi data menjadi set pelatihan dan pengujian.
DecisionTreeRegressor dari sklearn digunakan untuk membuat model regresi pohon keputusan.
mean_squared_error dan r2_score digunakan untuk evaluasi performa model.
Load Dataset
df = pd.read_csv('/kaggle/input/house-prices-advanced-regression-techniques/train.csv')
Membaca data dari file CSV yang berisi informasi harga rumah dan fitur-fitur yang terkait. Kemudian kita menampilkan 5 baris pertama untuk mendapatkan dambaran umum tentang data.
df.head()

Descriptive Statistics
df.describe()
Menampilkan statistik deskriptif seperti mean, std, min, max untuk setiap kolom dalam dataset.

Karena data yang kita gunakan memiliki kolom yang sangat banyak, kita juga perlu mengetahui tentang tipe data yang ada di setiap kolom.
df.info()
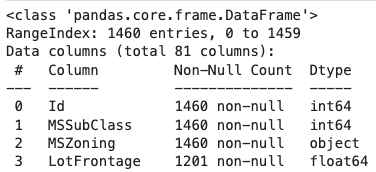
Deteksi Missing Values
for col in df.columns:
miss = df[col].isna().sum()
if miss > 0:
print(f"{col} has total {miss} missing values")
Menghitung dan menampilkan jumlah nilai yang hilang untuk setiap kolom.

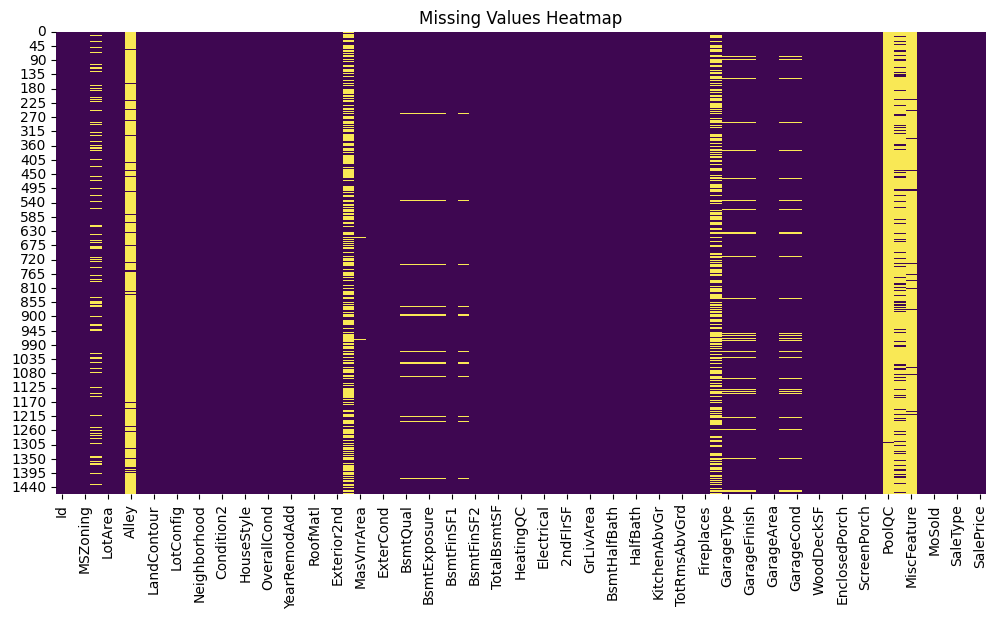
Visualisasi Missing Values
plt.figure(figsize=(12, 6))
sns.heatmap(df.isnull(), cbar=False, cmap='viridis')
plt.title('Missing Values Heatmap')
plt.show()
Menggunakan heatmap untuk memvisualisasikan lokasi missing values dalam dataset.
Penanganan Missing Values
manyMiss = [col for col in df.columns if df[col].isna().sum() > 500]
lessMiss = [col for col in df.columns if df[col].isna().sum() <= 500]
df = df.drop(columns=manyMiss)
for col in df.columns:
if df[col].dtype == 'O':
df[col] = df[col].fillna(df[col].mode()[0])
else:
df[col] = df[col].fillna(df[col].mean())
manyMiss: Kolom dengan lebih dari 500 missing values dihapus.
lessMiss: Kolom dengan kurang dari 500 missing values diisi dengan mode untuk tipe objek dan mean untuk tipe numerik.
Eksplorasi Data
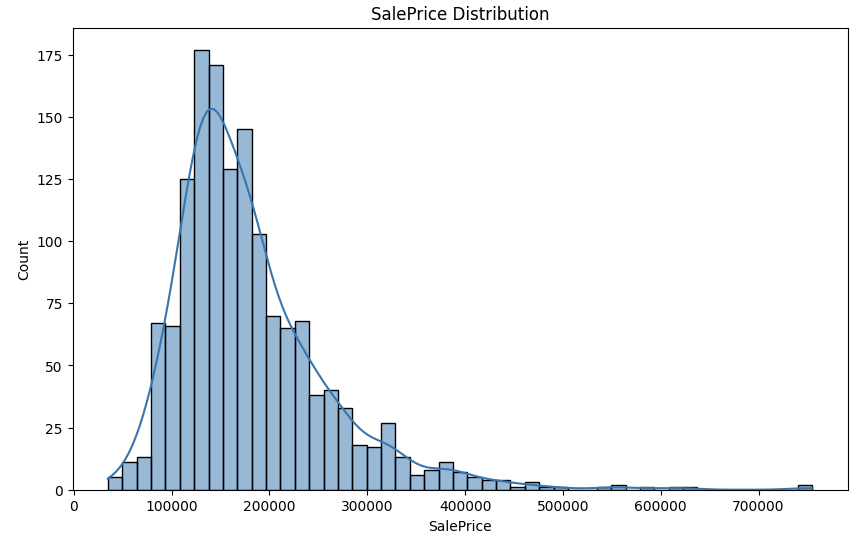
Distribusi SalePrice
plt.figure(figsize=(10, 6))
sns.histplot(df['SalePrice'], kde=True)
plt.title('SalePrice Distribution')
plt.show()
Di sini kita ingin memprediksi harga rumah, maka tidak ada salahnya melakukan plotting untuk melihat distribusi yang ada.
Pemilihan Fitur Numerik
numeric_features = df.select_dtypes(include=[np.number])
numeric_features = numeric_features.drop(columns=['SalePrice'])
y = df['SalePrice']
X = numeric_features
Untuk project ini kita hanya memilih kolom-kolom yang memiliki tipe data numerik. Kemudian kita menentukan kolom SalePrice sebagai variabel target / y. Setelah menentukan variabel X dan y kemudian kita membaginya menjadi data train dan data test
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Train Model
model = DecisionTreeRegressor(random_state=42)
model.fit(X_train, y_train)
Di sini kita membuat dan melatih model Decision Tree Regressor pada data latih.
Prediksi dan Evaluasi
Setelah melatih pada data yang dipilih, kemudian kita melakukan prediksi pada data baru. Dalam hal ini kita menggunakan data tes yang sudah dituliskan sebelumnya (20% dari dataset)
# Predictions
y_pred_train = model.predict(X_train)
y_pred_test = model.predict(X_test)
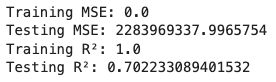
# Evaluation metrics
mse_train = mean_squared_error(y_train, y_pred_train)
mse_test = mean_squared_error(y_test, y_pred_test)
r2_train = r2_score(y_train, y_pred_train)
r2_test = r2_score(y_test, y_pred_test)
print(f'Training MSE: {mse_train}')
print(f'Testing MSE: {mse_test}')
print(f'Training R²: {r2_train}')
print(f'Testing R²: {r2_test}')
y_pred_train dan y_pred_test: Hasil prediksi untuk set pelatihan dan pengujian.
mse_train dan mse_test: Mean Squared Error untuk set pelatihan dan pengujian.
r2_train dan r2_test: R² score untuk set pelatihan dan pengujian.
Menampilkan hasil evaluasi performa model.
Visualisasi Decision Tree
from sklearn.tree import plot_tree
plt.figure(figsize=(20, 10))
plot_tree(model, filled=True, feature_names=X.columns, max_depth=2, fontsize=10)
plt.show()
Menggunakan plot_tree untuk memvisualisasikan struktur pohon keputusan sampai kedalaman 2.
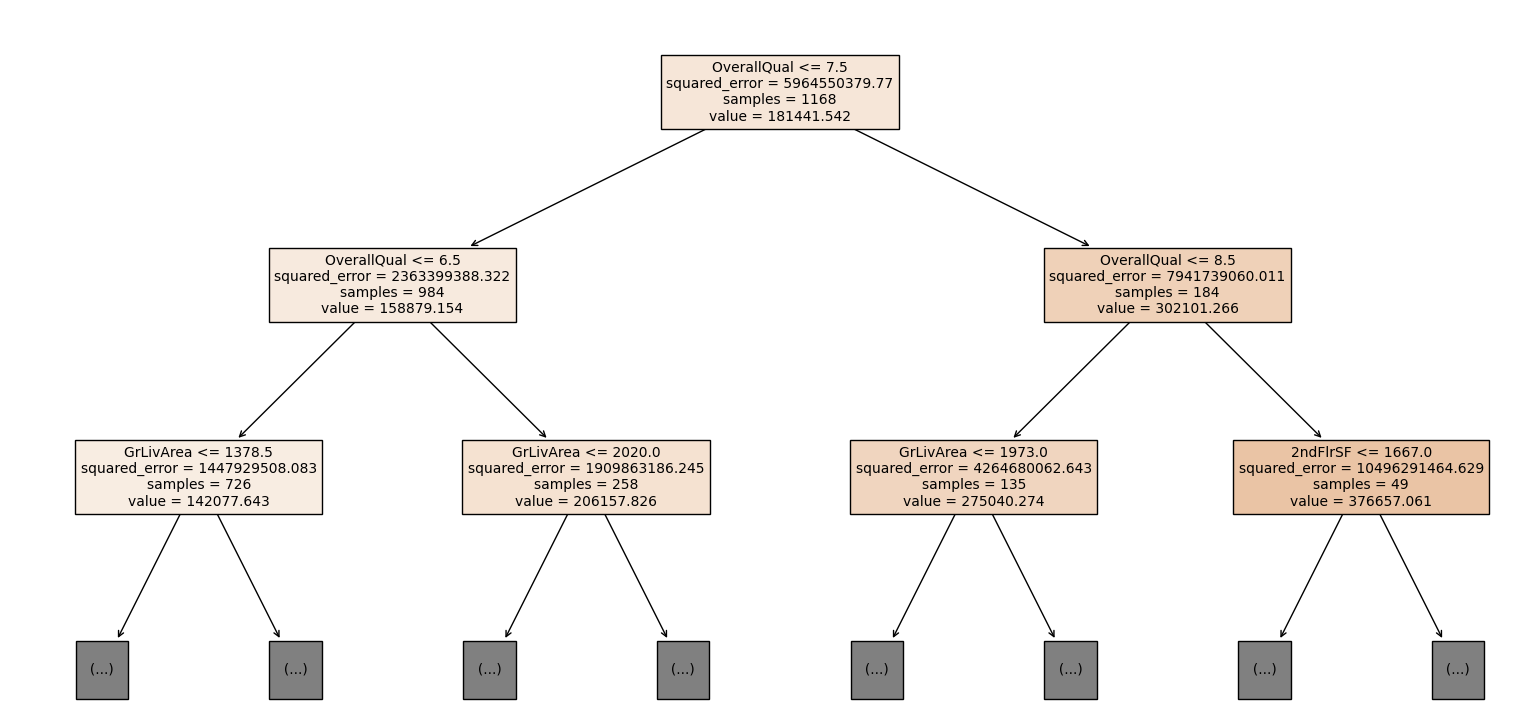
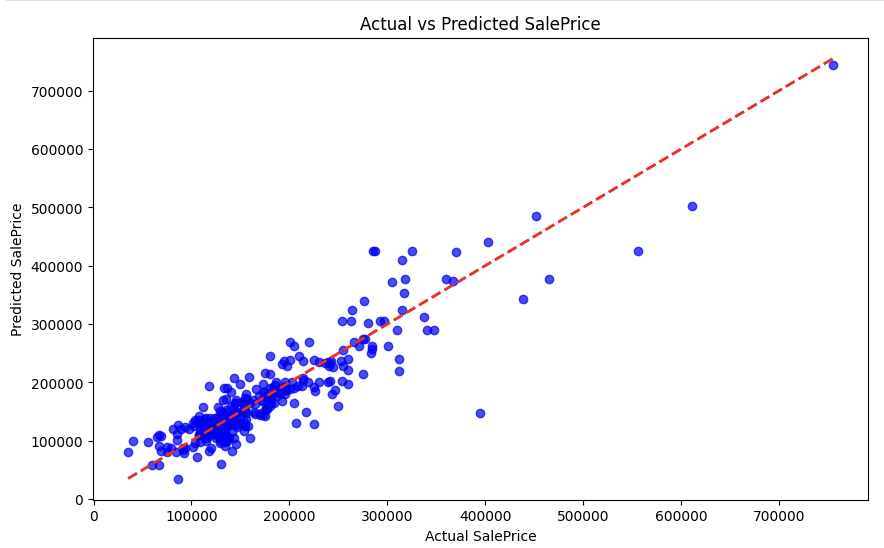
Di atas kita membuat visualisasi hasil decision tree dengan kedalaman 2. Pada kenyataannya, pohon keputusan memiliki cabang yang sangat banyak dan dalam. Setelah mendapatkan hasil prediksi, kita buat visualisasi untuk melihat perbandingan data real dengan hasil prediksi.
plt.figure(figsize=(10, 6))
plt.scatter(y_test, y_pred_test, alpha=0.7, color='b')
plt.plot([y_test.min(), y_test.max()], [y_test.min(), y_test.max()], '--r', linewidth=2)
plt.xlabel('Actual SalePrice')
plt.ylabel('Predicted SalePrice')
plt.title('Actual vs Predicted SalePrice')
plt.show()
Penutup
Dalam artikel ini, kita telah membahas bagaimana Decision Tree bekerja, mulai dari pemilihan fitur, kriteria pembagian, hingga pembentukan simpul. Kita juga melakukan studi kasus prediksi harga rumah. Model Decision Tree Regression menawarkan interpretabilitas yang tinggi, memudahkan kita untuk memahami dan menjelaskan prediksi yang dihasilkan. Namun, penting untuk diingat bahwa model ini bisa sangat sensitif terhadap perubahan kecil dalam data dan cenderung overfitting jika tidak diatur dengan benar.
Dengan pemahaman yang mendalam tentang bagaimana Decision Tree Regression bekerja dan bagaimana mengimplementasikannya, kita sekarang siap untuk menerapkan algoritma ini pada berbagai masalah prediksi nilai kontinu lainnya. Terima kasih sudah membaca artikel ini, Selamat Belajar!
Source Code : Kaggle
Subscribe to my newsletter
Read articles from Muhammad Ihsan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Muhammad Ihsan
Muhammad Ihsan
AI, ML and DL Enthusiast. https://www.upwork.com/freelancers/emhaihsan https://github.com/emhaihsan https://linkedin.com/in/emhaihsan