NVIDIA A10 vs. A100: Best GPUs for Stable Diffusion Inference
 Spheron Network
Spheron Network
NVIDIA's A10 and A100 GPUs are instrumental in powering a variety of model inference workloads, from large language models (LLMs) and audio transcription to image generation. The A10 is an economical option capable of handling many modern models, while the A100 excels in highly efficient processing large models.
When choosing between the A10 and A100 for your model inference needs, consider factors such as latency, throughput, model size, and budget. Additionally, you can leverage multiple GPUs to optimize performance and cost. For instance, large models that exceed the capacity of a single A100 can be run by combining multiple A100s in one instance. Conversely, distributing large model inference tasks across several A10s can save costs.
This guide will assist you in balancing inference time and cost when selecting GPUs for your model inference workload.
Overview of Ampere GPUs
The "A" in A10 and A100 signifies that these GPUs are built on NVIDIA's Ampere microarchitecture. Named after physicist André-Marie Ampère, the Ampere microarchitecture is the successor to NVIDIA's Turing microarchitecture. Released in 2020, it powers the RTX 3000 series of consumer GPUs, with the GeForce RTX 3090 Ti being the flagship model.
Ampere's influence extends significantly into the data center, where six GPUs are based on this architecture: NVIDIA A2, A10, A16, A30, A40, and A100 (available in 40 and 80 GiB versions).
The A10 and A100 are the most frequently used for model inference tasks. The A10G, an AWS-specific variant of the A10, is also commonly used and can be interchanged with the standard A10 for most model inference purposes. This article compares the standard A10 with the 80-gigabyte A100.
Comparing A10 and A100 GPUs: Specifications and Performance for ML Inference
The A10 and A100 GPUs have extensive specifications, but a few key points highlight their performance differences for machine learning (ML) inference tasks.
Key Specifications
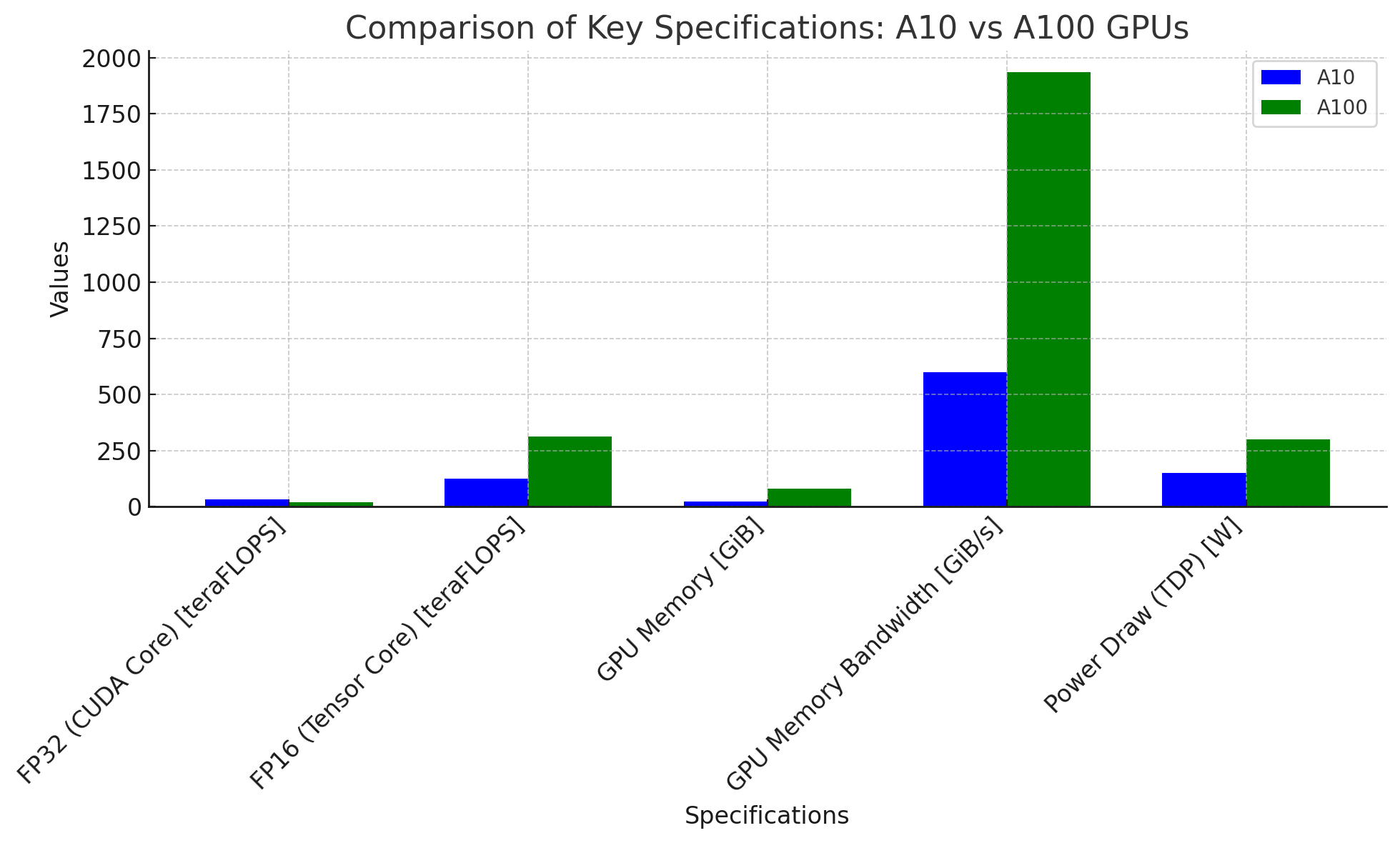
| Specification | NVIDIA A10 | NVIDIA A100 |
| FP32 (CUDA Cores) | 31.2 TeraFLOPs | 19.5 TeraFLOPS |
| FP16 (Tensor Cores) | 125 TeraFLOPS | 312 TeraFLOPS |
| GPU Memory | 24 GB | 80 GB |
| GPU Memory Bandwidth | 600 GiB/s | 1,935 GiB/s |
| Power Draw (TDP) | 150 Watts | 300 Watts |
FP16 Tensor Core performance is crucial for ML inference. The A100 boasts 312 teraFLOPS, more than double the A10's 125 teraFLOPS. The A100 also offers over three times the VRAM, which is essential for handling large models.
Core Count and Core Type
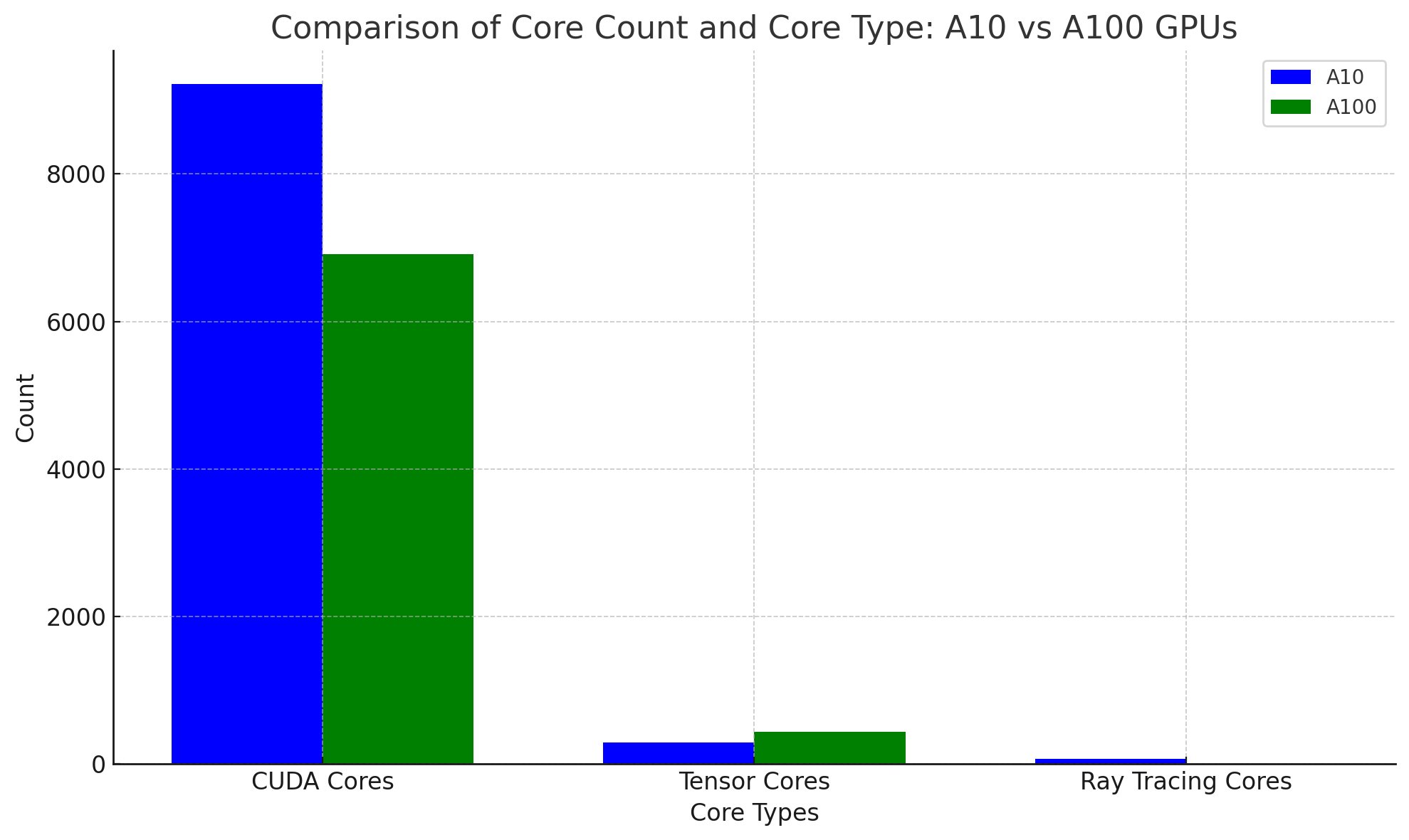
- | Specification | NVIDIA A10 | NVIDIA A100 | | --- | --- | --- | | CUDA Cores | 9,216 | 6,912 | | Tensor Cores | 288 | 432 | | Ray Tracing Cores | 72 | 0 |
The A100's superior performance stems from its higher Tensor Core count, which is vital for ML inference. Despite the A10 having more CUDA cores, Tensor Cores are more critical for this application. The A100's third-generation Tensor Cores enhance matrix multiplication, a computationally intensive task in ML inference.
Ray tracing cores in the A10 are not typically used in ML inference but are geared towards rendering tasks. The A100 is optimized for ML inference and high-performance computing (HPC) tasks, hence its lack of ray tracing cores.
VRAM and Memory Type
VRAM, the memory on a GPU for storing data for calculations, can often be a bottleneck for model invocation. The A10 has 24GiB of DDR6 VRAM, while the A100 comes in 40GiB and 80GiB versions, utilizing the faster HBM2 memory architecture. HBM2, being more expensive to produce, is reserved for flagship GPUs like the A100.
Performance Comparison
While specs are informative, real-world benchmarks provide practical insights. For example, Llama 2 and Stable Diffusion models work with GPUs to evaluate their performance in actual use cases.
Llama 2 Inference
Llama 2, an open-source large language model by Meta, comes in three sizes: 7 billion, 13 billion, and 70 billion parameters. Larger models yield better results but require more VRAM.
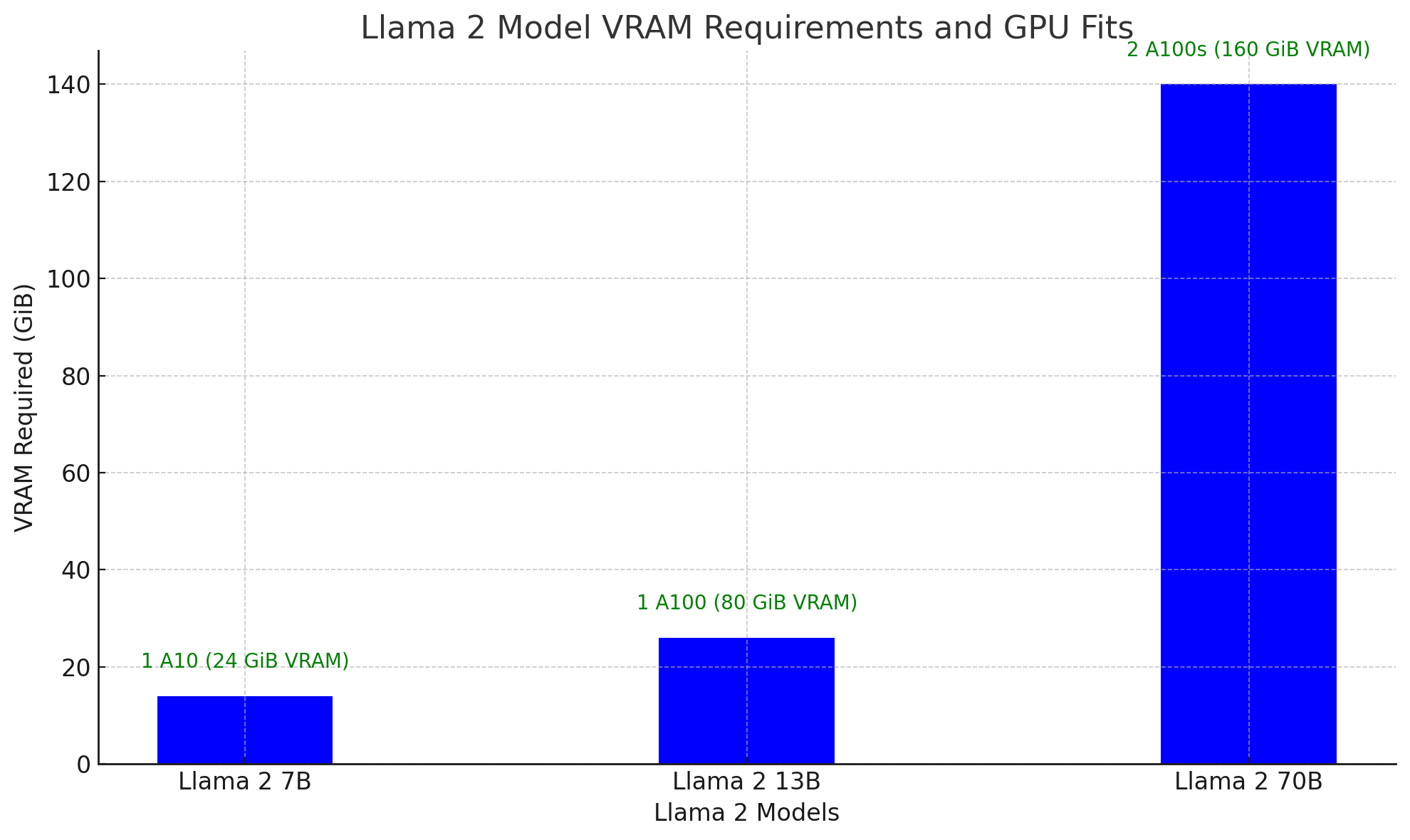
| Model | Size | Inference Memory | GPU Requirement | Total VRAM Required |
| Llama 2 7B | 7 Billion | Included | NVIDIA A10 | 24 GB |
| Llama 2 13B | 13 Billion | Included | NVIDIA A100 | 80 GB |
| Llama 2 70B | 70 Billion | Included | 2 x NVIDIA A100 | 160 GB |
The A100 allows you to run larger models, and for models exceeding its 80 GiB capacity, multiple GPUs can be used in a single instance.
Stable Diffusion Inference
Stable Diffusion can run on A10 and A100, as the A10's 24 GiB VRAM is sufficient. However, the A100 performs inference roughly twice as fast.
Inference time for 50 steps:
A10: 1.77 seconds
A100: 0.89 seconds
Cost Considerations
While the A100 offers superior performance, it is significantly more expensive. Smaller models can be run on the A100 for quicker results and faster inference time, but costs accumulate quickly. For throughput-focused tasks, scaling horizontally with multiple A10s is more cost-effective.
Calculating Model Throughput
To achieve a throughput of 1,000 images per minute using Stable Diffusion:
| Instance Type | Images Per Minute Per Instance | Number of Instances Required | Cost Per Minute | Total Cost Per Minute |
| A10 | 34 | 30 | $0.60 | $18.00 |
| A100 | 67 | 15 | $1.54 | $23.10 |
Scaling horizontally with A10s is more cost-efficient unless individual image generation time is crucial.
Using Multiple A10s vs. One A100
The A10 GPU can enable vertical scaling by providing more significant instances to support bigger machine-learning models. For example, if you wanted to run a model like Llama-2-chat 13B, which exceeds the capabilities of a single A10, you could consider using multiple A10s within a single instance rather than opting for a more expensive A100-powered instance. Two A10 GPUs offer 48 GB of VRAM combined to run the 13 billion parameter model.
However, it's important to note that while employing several A10s within an instance allows you to handle larger models, it does not increase the inference speed. This alternative allows you to balance the tradeoff between cost and speed according to your specific needs and financial constraints.
Choosing the Right GPU
The A100 is a powerful choice for demanding ML inference tasks, but the A10, especially in multi-GPU configurations, offers a cost-effective solution for many workloads. The choice ultimately depends on your specific needs and budget.
As the demand for GPU resources continues to surge, especially for AI and machine learning applications, ensuring the security and ease of access to these resources has become paramount.
Spheron’s decentralized architecture aims to democratize access to the world’s untapped GPU resources and strongly emphasizes security and user convenience. Let’s unpack how Spheron protects your GPU resources and data and ensures that the future of decentralized compute is both efficient and secure.
Interested in learning more about Spheron’s network capabilities and user benefits?Review the whitepaper in full.
Subscribe to my newsletter
Read articles from Spheron Network directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Spheron Network
Spheron Network
On-demand DePIN for GPU Compute