Day 17/40 Days of K8s: Kubernetes Autoscaling: HPA vs VPA ☸️
 Gopi Vivek Manne
Gopi Vivek Manne
❗Understanding Scaling in Kubernetes
Scaling in Kubernetes means to adjusting the number of servers, workloads, or resources to meet demand. It's different from maintaining a fixed number of replicas, which is handled by the ReplicaSet controller(High Availability).
❓The Need for Autoscaling
Autoscaling becomes important during high-demand situations, such as sales events (e.g: Flipkart's Big Billion Days). Without it, applications may face resource constraints, leading to CPU throttling, high latency, and low throughput.
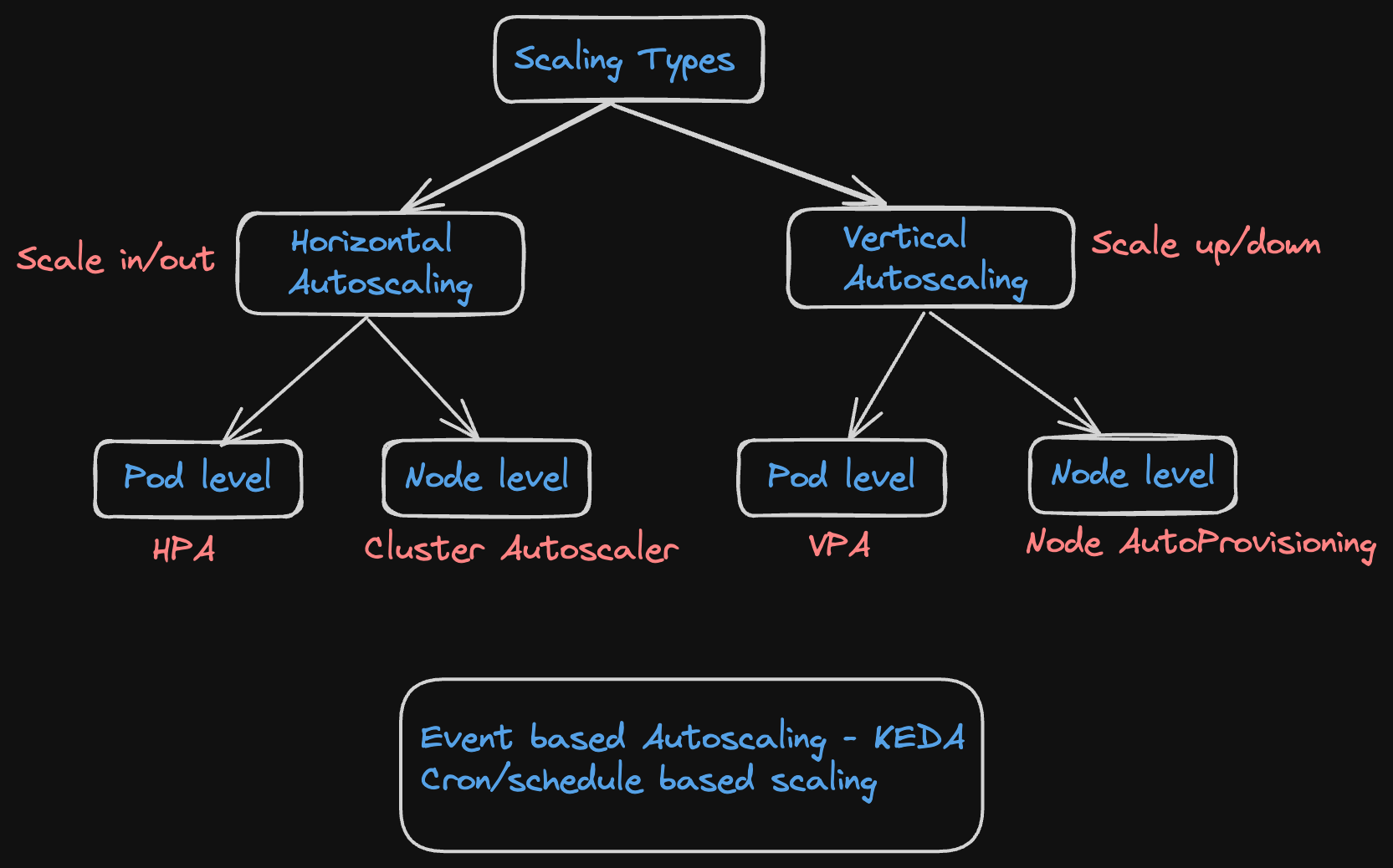
🌟 Types of Autoscaling in Kubernetes
1️⃣ Horizontal Pod Autoscaler (HPA):
Scales out/in by adjusting the number of identical pods.
Suitable for customer-facing, mission-critical applications
No pod restart required.
2️⃣ Vertical Pod Autoscaler (VPA):
Resizes existing pods by adjusting their resource allocation
Better for non-mission-critical, stateless applications
It requires pod restart may lead to temporary downtime.
3️⃣ Cluster Autoscaler:
Manages node-level scaling in cloud-based clusters (e.g: AWS EKS)
Adds or removes nodes based on pod resource requirements and pending pods status.
🌟 Prerequisites for HPA
- Make sure the metrics server is deployed in the cluster. HPA is enabled by default in a Kubernetes cluster, it is usually included with the Kubernetes control plane components.
🤔 How HPA Works
How does HPA knew about the resources usage of pods? Where does it gathers metrics data from?
The Metrics Server is deployed in the
kube-systemnamespace but it runs as a deployment across the cluster, which means it can run on any worker node.Function: The Metrics Server collects resource usage metrics (CPU and memory) from the kubelets running on each node and exposes these metrics via the Kubernetes API-server.
HPA will query the api-server for the metrics data by default for every 30 sec, and works in conjunction with control manager to make sure the desired state is always maintained.
HPA: Decides when scaling is needed based on metrics and scaling policy set.
HPA Controller: Responsible for implementing the scaling actions to maintain the desired state and meet demand.
🌟 Other Autoscaling Approaches
Event-based Autoscaling: Using tools like KEDA.
Cron/Schedule-based Autoscaling: For predictable traffic patterns.
🌟 Cloud vs Kubernetes Autoscaling
Cloud: Uses Auto Scaling Groups (ASG) for instance-level scaling.
Kubernetes:
HPA for pod-level scaling.
Cluster Autoscaler for node-level scaling in cloud environments.
VPA for existing pod resource adjustments.
Node AutoProvisioning for existing node resource adjustments.
🌟 TASK
Make sure the metrics-server is deployed in the cluster using this
metrics-server.yamlapiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server rbac.authorization.k8s.io/aggregate-to-admin: "true" rbac.authorization.k8s.io/aggregate-to-edit: "true" rbac.authorization.k8s.io/aggregate-to-view: "true" name: system:aggregated-metrics-reader rules: - apiGroups: - metrics.k8s.io resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: labels: k8s-app: metrics-server name: system:metrics-server rules: - apiGroups: - "" resources: - nodes/metrics verbs: - get - apiGroups: - "" resources: - pods - nodes verbs: - get - list - watch --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server-auth-reader namespace: kube-system roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: extension-apiserver-authentication-reader subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: metrics-server:system:auth-delegator roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:auth-delegator subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: labels: k8s-app: metrics-server name: system:metrics-server roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: system:metrics-server subjects: - kind: ServiceAccount name: metrics-server namespace: kube-system --- apiVersion: v1 kind: Service metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: ports: - name: https port: 443 protocol: TCP targetPort: https selector: k8s-app: metrics-server --- apiVersion: apps/v1 kind: Deployment metadata: labels: k8s-app: metrics-server name: metrics-server namespace: kube-system spec: selector: matchLabels: k8s-app: metrics-server strategy: rollingUpdate: maxUnavailable: 0 template: metadata: labels: k8s-app: metrics-server spec: containers: - args: - --cert-dir=/tmp - --secure-port=10250 - --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname - --kubelet-use-node-status-port - --kubelet-insecure-tls - --metric-resolution=15s image: registry.k8s.io/metrics-server/metrics-server:v0.7.1 imagePullPolicy: IfNotPresent livenessProbe: failureThreshold: 3 httpGet: path: /livez port: https scheme: HTTPS periodSeconds: 10 name: metrics-server ports: - containerPort: 10250 name: https protocol: TCP readinessProbe: failureThreshold: 3 httpGet: path: /readyz port: https scheme: HTTPS initialDelaySeconds: 20 periodSeconds: 10 resources: requests: cpu: 100m memory: 200Mi securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL readOnlyRootFilesystem: true runAsNonRoot: true runAsUser: 1000 seccompProfile: type: RuntimeDefault volumeMounts: - mountPath: /tmp name: tmp-dir nodeSelector: kubernetes.io/os: linux priorityClassName: system-cluster-critical serviceAccountName: metrics-server volumes: - emptyDir: {} name: tmp-dir --- apiVersion: apiregistration.k8s.io/v1 kind: APIService metadata: labels: k8s-app: metrics-server name: v1beta1.metrics.k8s.io spec: group: metrics.k8s.io groupPriorityMinimum: 100 insecureSkipTLSVerify: true service: name: metrics-server namespace: kube-system version: v1beta1 versionPriority: 100
Deploy php-apache server using yaml file
apiVersion: apps/v1 kind: Deployment metadata: name: php-apache spec: selector: matchLabels: run: php-apache template: metadata: labels: run: php-apache spec: containers: - name: php-apache image: registry.k8s.io/hpa-example ports: - containerPort: 80 resources: limits: cpu: 500m requests: cpu: 200m --- apiVersion: v1 kind: Service metadata: name: php-apache labels: run: php-apache spec: ports: - port: 80 selector: run: php-apache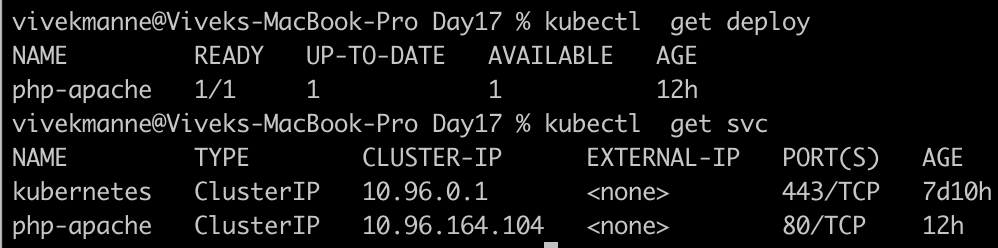
Create the HorizontalPodAutoscaler:
kubectl autoscale deployment php-apache --cpu-percent=50 --min=1 --max=10You can check the current status of the newly-made HorizontalPodAutoscaler, by running:
kubectl get hpa
The current CPU consumption is 0% as there are no clients sending requests to the server.
Increase the Load using the following command
# Run this in a separate terminal # so that the load generation continues and you can carry on with the rest of the steps kubectl run -i --tty load-generator --rm --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep 0.01; do wget -q -O- http://php-apache; done"Now run the command to check the load
kubectl get hpa php-apache --watchHere, CPU consumption has increased to 150% of the request. As a result, the Deployment was resized to 7 replicas:

You should see the pod replica count is 7 now.

This shows that pods are scaled dynamically(HPA in this case) to meet the demand of the load as per scaling policy.
#Kubernetes #HPA #VPA #ClusterAutoscaler #40DaysofKubernetes #CKASeries
Subscribe to my newsletter
Read articles from Gopi Vivek Manne directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Gopi Vivek Manne
Gopi Vivek Manne
I'm Gopi Vivek Manne, a passionate DevOps Cloud Engineer with a strong focus on AWS cloud migrations. I have expertise in a range of technologies, including AWS, Linux, Jenkins, Bitbucket, GitHub Actions, Terraform, Docker, Kubernetes, Ansible, SonarQube, JUnit, AppScan, Prometheus, Grafana, Zabbix, and container orchestration. I'm constantly learning and exploring new ways to optimize and automate workflows, and I enjoy sharing my experiences and knowledge with others in the tech community. Follow me for insights, tips, and best practices on all things DevOps and cloud engineering!