Why Virtual Warehouses Are Core to Snowflake’s Power—and How to Use Them Right
 John Ryan
John Ryan
If you’re using Snowflake and haven’t given much thought to how your virtual warehouses are configured, you’re probably leaving money—or performance—on the table.
Snowflake’s virtual warehouse model is deceptively simple on the surface: spin up compute when you need it, let it suspend when you don’t. But under the hood, your choice of warehouse size, concurrency model, scaling policy, and workload separation can make or break your cost efficiency and query performance.
This article is a practical guide to understanding how Snowflake warehouses really work. We’ll cut through the marketing and get straight to what matters: how to design, size, and manage virtual warehouses so they serve your workloads—not the other way around.
The Overall Snowflake Architecture
A virtual warehouse on Snowflake is a cluster of database servers deployed on-demand to execute user queries. On a traditional on-premises database, this would be an MPP server (Massively Parallel Processing), which is a fixed hardware deployment. However, on Snowflake, a Virtual Warehouse is a dynamically allocated cluster of database servers consisting of CPU cores, memory, and SSD, maintained in a hardware pool and deployed within milliseconds. To the end-user, this process is entirely transparent.
The diagram below shows the Snowflake Architecture and how a Virtual Warehouse provides the compute services for Snowflake and is coordinated by the Cloud Services layer.
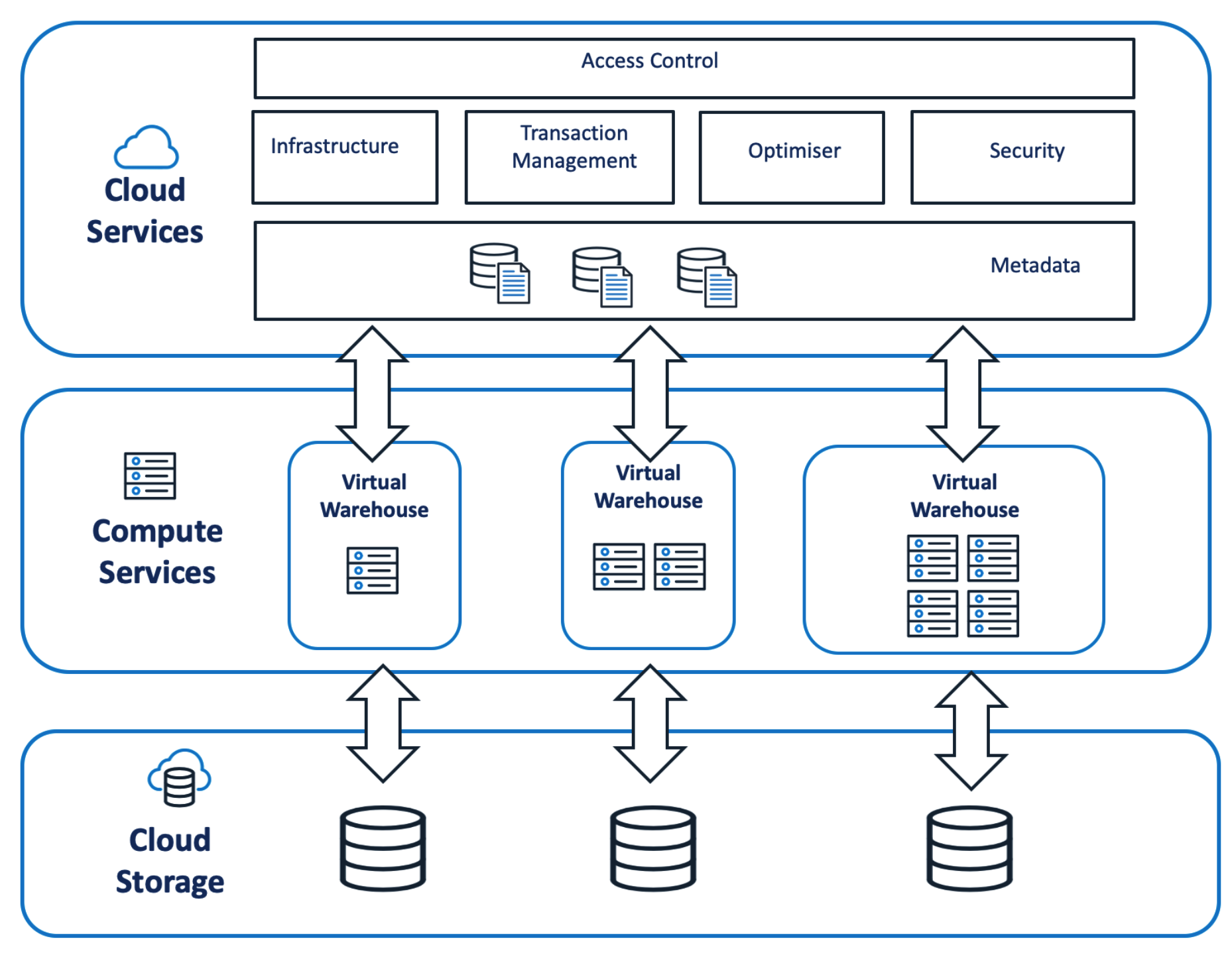
When users connect to Snowflake, the connection is handled by hardware in the Cloud Services Layer. This is responsible for controlling access, managing hardware and transactions, optimizing queries, and overall security.
Effectively, queries in the Cloud Services layer are free, as although they technically incur cost, this tends to be tiny (in the order of a few dollars per day) and will not be billed unless it's more than 10% of the daily compute costs from warehouse warehouses.
When a SQL statement (or Python program) is executed, it's executed on a Virtual Warehouse.
What is a Virtual Warehouse?
A Virtual Warehouse is a cluster of one or more machines that execute queries. Each node is a computer server with eight CPUs, memory, and Solid State Disk (SSD) for storage, as illustrated in the diagram below.
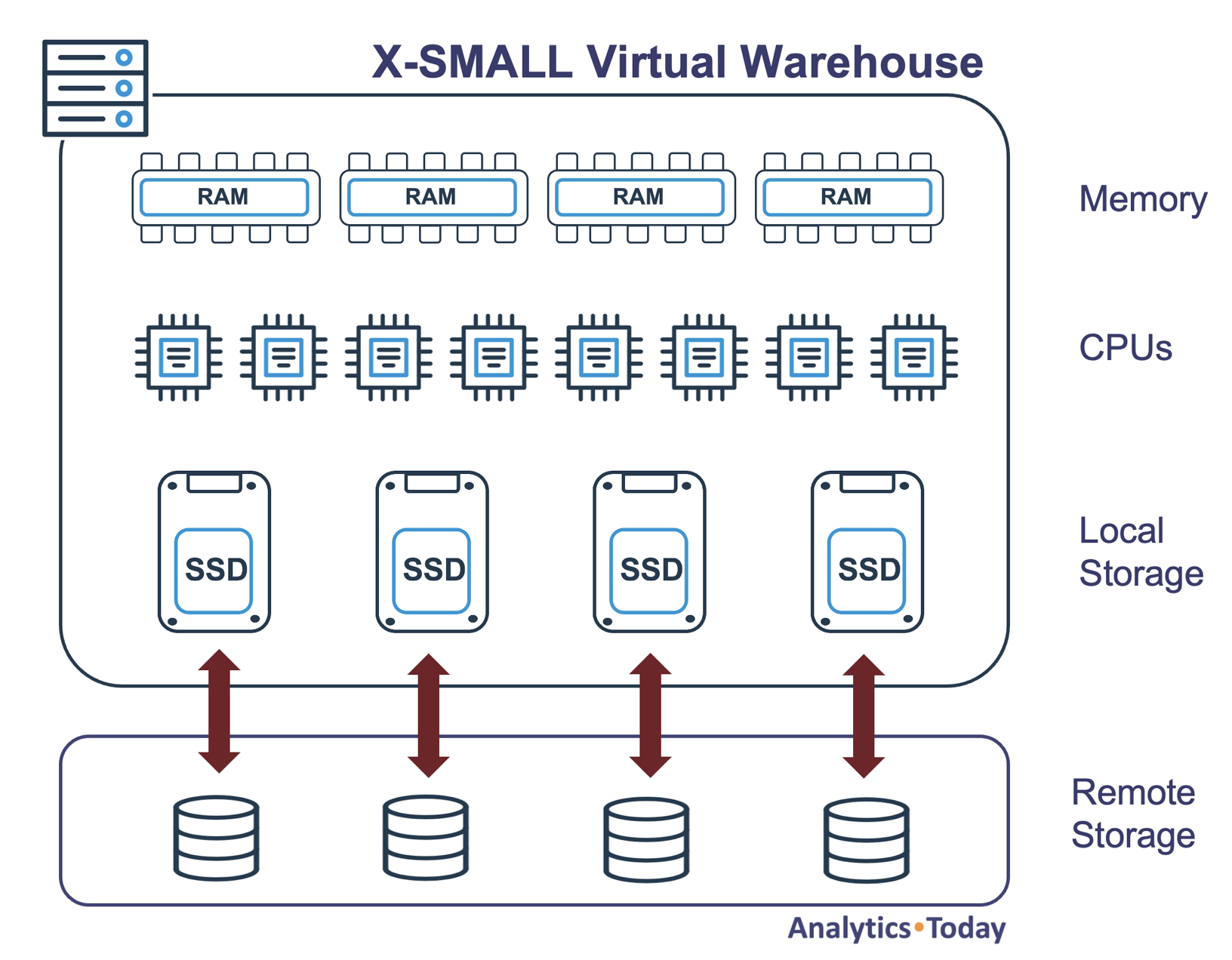
As illustrated above, an XSMALL virtual warehouse consists of 8 CPUs, and a critical aspect of Snowflake is that any given warehouse can execute multiple queries in parallel. Equally, a single query can (if sensible) execute queries in parallel using all eight CPUs to maximize performance.
Finally, Snowflake allocates memory and SSD as a Virtual Warehouse Cache to help further improve query performance.
What is a Snowflake Virtual Warehouse Cluster?
While an XSMALL warehouse (which has a single server) is a powerful machine capable of querying and summarizing hundreds of megabytes of data, Snowflake is equally capable of processing gigabytes or even terabytes of data within minutes.
To achieve this, Snowflake can deploy a cluster of servers with 1-512 times the power of a single XSMALL warehouse.
The diagram below illustrates how a SQL query submitted to a single MEDIUM-sized virtual warehouse is automatically split up and executed in parallel across the available nodes.

As data is loaded into Snowflake, metadata statistics are automatically captured and stored in the Cloud Services Layer. Snowflake uses this data to allocate work to each available node, allowing the query to be executed in parallel.
Warehouse Sizes
Unlike traditional hardware systems, which are specified in terms of CPU speeds, memory sizes, and fiber channel links, Snowflake simplifies the hardware into a set of T-shirt sizes.
The table below shows the Snowflake warehouse sizes, which start at an XSMALL, which has a single node, and go up to the gigantic X6LARGE machine, which is over 500 times larger.
| Size | Nodes | Virtual CPUs |
| XSMALL | 1 | 8 |
| SMALL | 2 | 16 |
| MEDIUM | 4 | 32 |
| LARGE | 8 | 64 |
| XLARGE | 16 | 128 |
| X2LARGE | 32 | 256 |
| X3LARGE | 64 | 512 |
| X4LARGE | 128 | 1,024 |
| X5LARGE | Double Capacity | Double Capacity |
| X6LARGE | Double Capacity | Double Capacity |
This simple hardware architecture delivers increasingly powerful compute resources, and typically, each size doubles the potential throughput.
Creating a Virtual Warehouse
The SQL script below shows the command to create a virtual warehouse that will automatically suspend after 60 seconds and immediately resume when queries are submitted.
-- Need SYSADMIN to create warehouses
use role SYSADMIN;
create warehouse PROD_REPORTING with
warehouse_size = SMALL
auto_suspend = 60
auto_resume = true
initially_suspended = true
comment = 'PROD Reporting Warehouse';
Once created, use the following command to select a virtual warehouse:
use warehouse PROD_REPORTING;
Any SQL statements executed from this point forward will run on the virtual warehouse. Using this method, different teams can be provided dedicated virtual warehouses, and it’s possible to set a default warehouse for each team.
Snowflake Warehouse - Separation of workloads
One of the most important benefits of the Snowflake Virtual Warehouse architecture is the ability to separate workloads. The diagram below illustrates this, where warehouses of different sizes are allocated to other teams for different purposes.
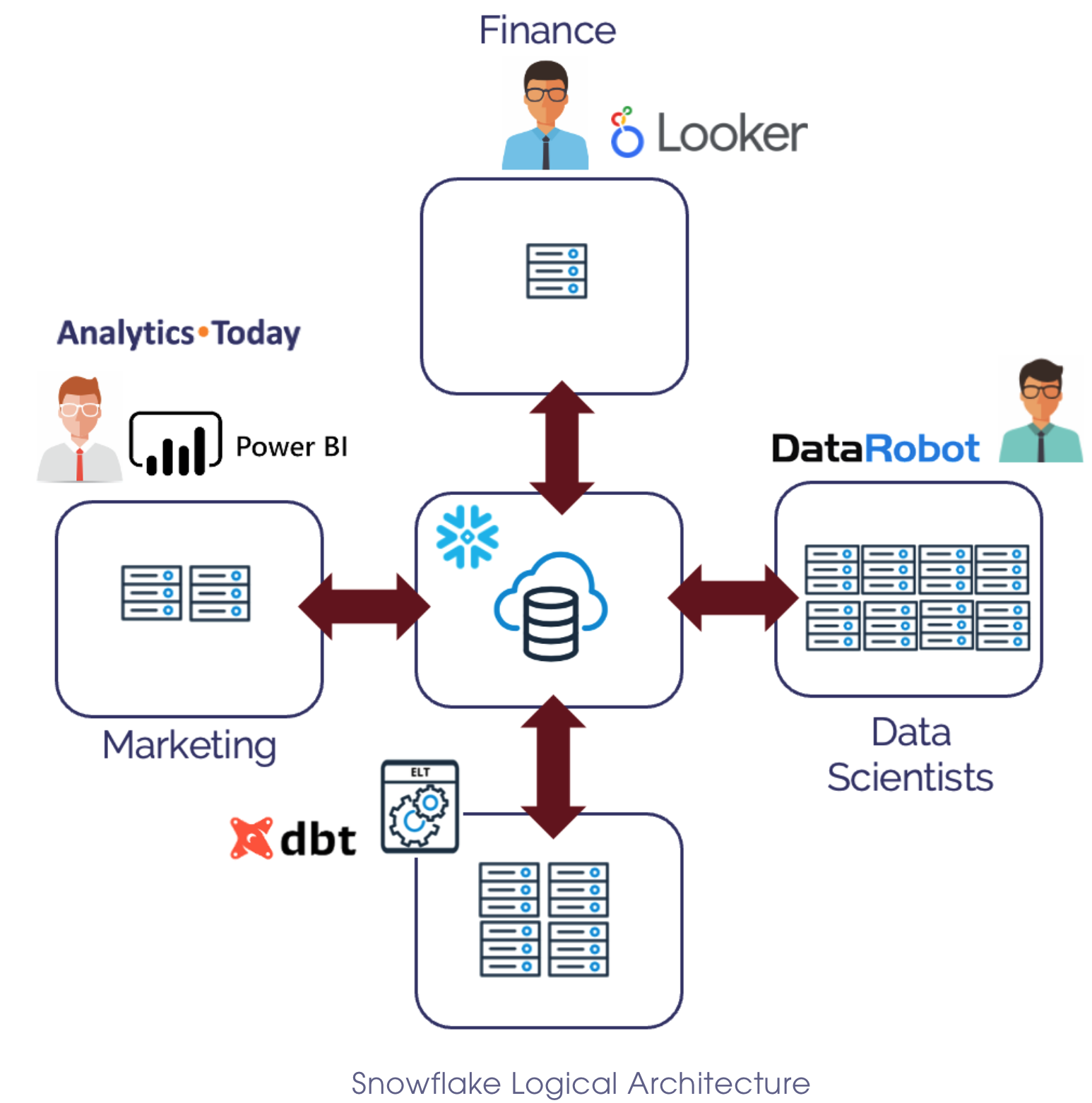
The most misunderstood aspect of Virtual Warehouse deployment is the need to separate workloads to avoid contention. In my experience, most Snowflake customers deploy warehouses by team to prevent contention. This means, for example, that the Sales, Inventory, and Marketing teams each have a separate set of virtual warehouses.
While this seems sensible at first, it's a bad mistake that typically leads to massive overspending.
In reality, it's best practice to combine workloads from many teams but separate workloads by size. This ensures most short, fast queries execute on an XSMALL warehouse while larger, more complex queries run on MEDIUM or size warehouses or even bigger.

Virtual Warehouse Queuing
On traditional databases like Oracle or SQL Server, the overall query performance subsides as the number and size of queries grows, which can be hugely frustrating. However, as each new query is submitted, Snowflake automatically estimates the resources needed on Snowflake. As the workload approaches 100% of machine capacity, additional queries are automatically queued until sufficient capacity is available.
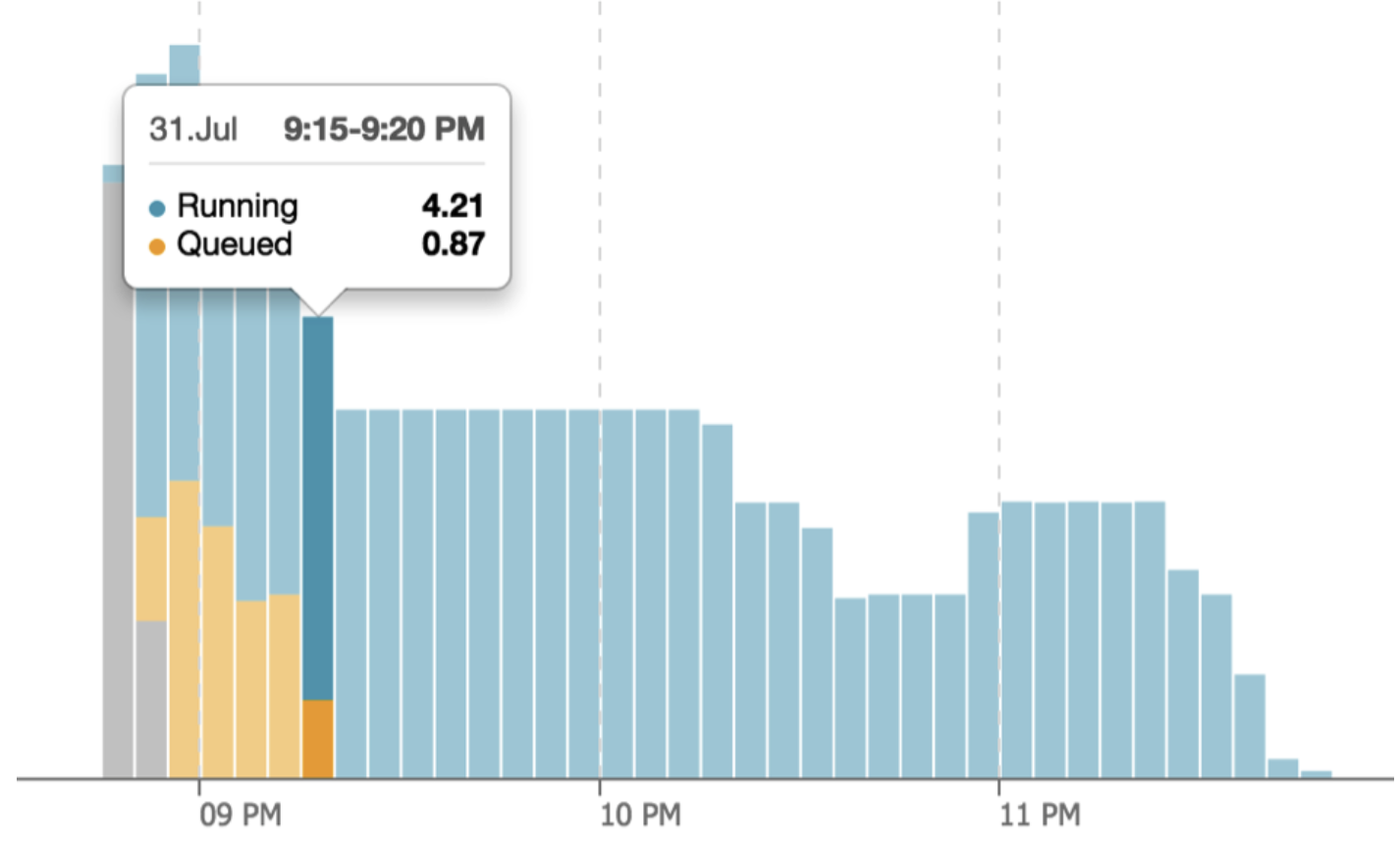
The screenshot above illustrates how, during busy times, queries are queued to prevent poor overall query performance.
Scaling Up for Large Data Volumes
When users experience poor query performance, it's often because the complexity and data volumes are too large for the allocated warehouse. One option is to scale up the warehouse to process the data faster.
The diagram below illustrates how Snowflake can dynamically resize a virtual warehouse from SMALL to LARGE without any service interruption.
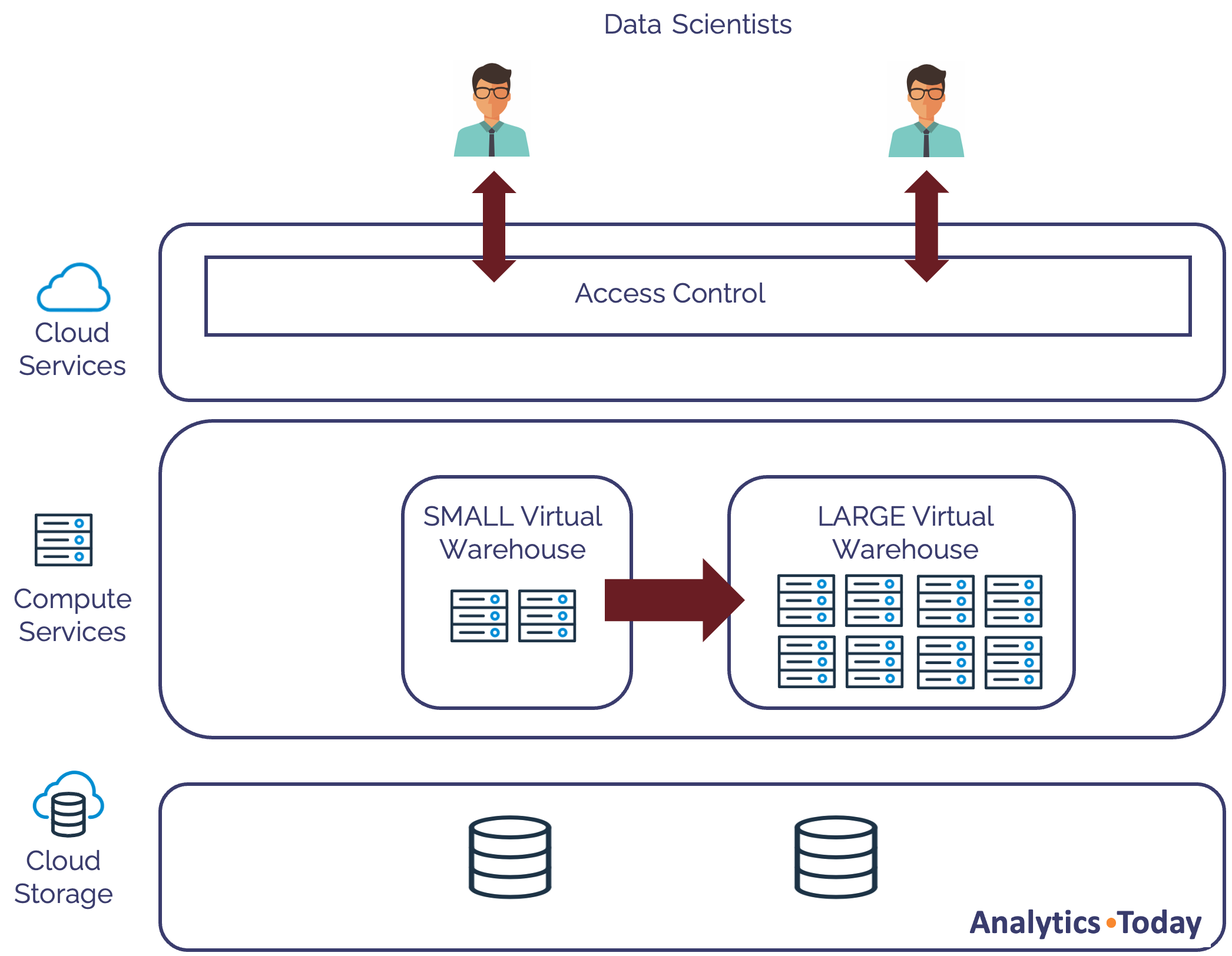
Using this option provides a machine with eight times the processing capacity and in many cases, queries that take an hour to complete can complete within minutes.
alter warehouse PROD_REPORTING set
warehouse_size = LARGE;
The alter warehouse command above allocates a LARGE warehouse, and any queued queries are immediately started on this larger machine. Meanwhile, existing queries continue to completion, after which the SMALL warehouse is suspended.
Using this method, the virtual warehouse size can be dynamically resized, up and down, without downtime.
Scale Out to Maximise Concurrency
While scaling up to a bigger warehouse is a sensible approach for larger data volumes, we often see situations where queuing is caused by too many concurrent queries. In this case, simply increasing the warehouse is potentially wasteful as it means we are charged for the larger warehouse regardless of whether one or fifty queries are executed.
The diagram below illustrates a better solution in which we scale out (rather than scale up).
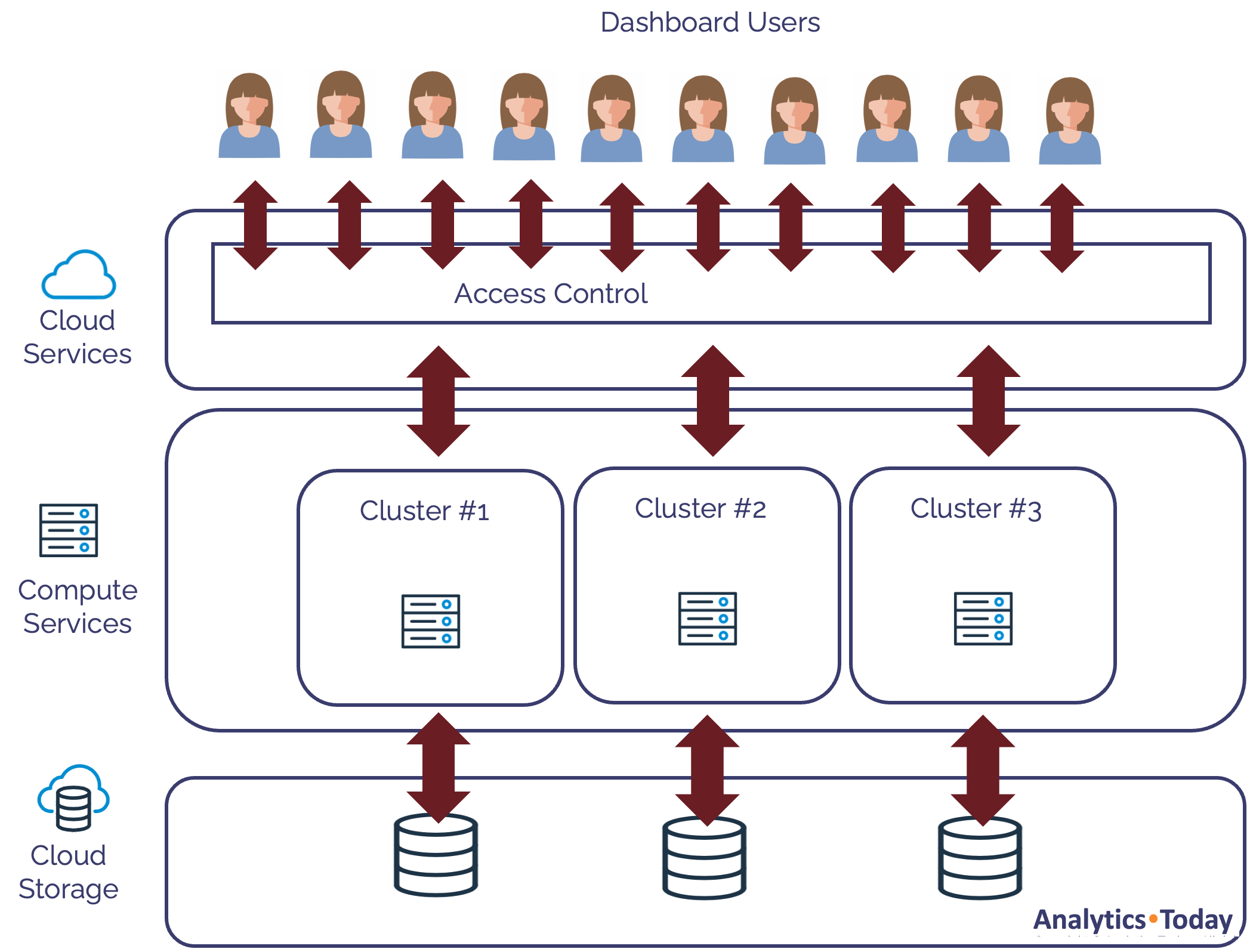
Using this method, Snowflake will automatically allocate additional same-size clusters as the number of concurrent queries increases. In the example above, Snowflake has allocated two additional clusters to the existing warehouse.
Snowflake automatically suspends one or more clusters as the number of concurrent queries subsides, as illustrated in the diagram below.
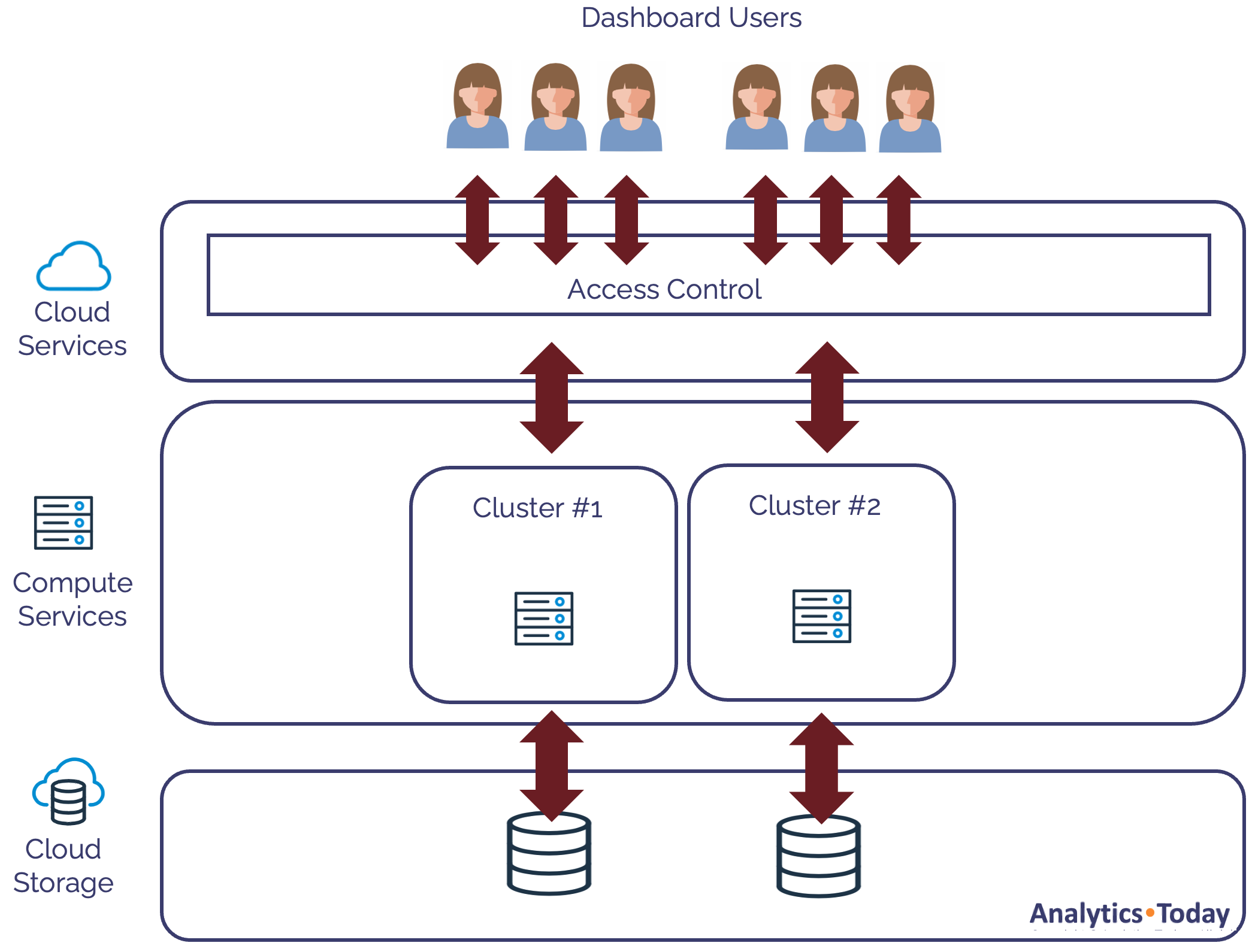
Using this technique, the compute resources are automatically increased or reduced to match the concurrent query demands.
Deliveroo successfully deployed this technique to handle concurrent queries from up to 1,500 data analysts with fantastic performance.
Configuring the MAX_CLUSTER_COUNT
The SQL statement below shows the code needed to configure a virtual warehouse to set the MAX_CLUSTER_COUNT. In this case, the PROD_REPORTING warehouse is allowed to allocate up to 5 clusters.
alter warehouse PROD_REPORTING set
warehouse_size = MEDIUM
min_cluster_count = 1
max_cluster_count = 5
scaling_policy = ‘STANDARD’;
The SCALING_POLICY defines how quickly Snowflake should allocate new clusters. Options include:
STANDARD: This option attempts to minimize queuing and thereby maximize query performance. When queuing is detected, it immediately allocates an additional virtual warehouse. This is best used for warehouses used by end-users where fast query performance is critical.
ECONOMY: This option prioritizes cost over performance and is best used for warehouses executing batch processing where performance is less important. This option allows queries to queue until there are six minutes of work available, at which time additional clusters will be allocated.
The diagram below illustrates how Snowflake automatically allocates additional clusters throughout the day based on the workload and then automatically suspends them when no longer needed. Once configured, the entire process runs automatically.
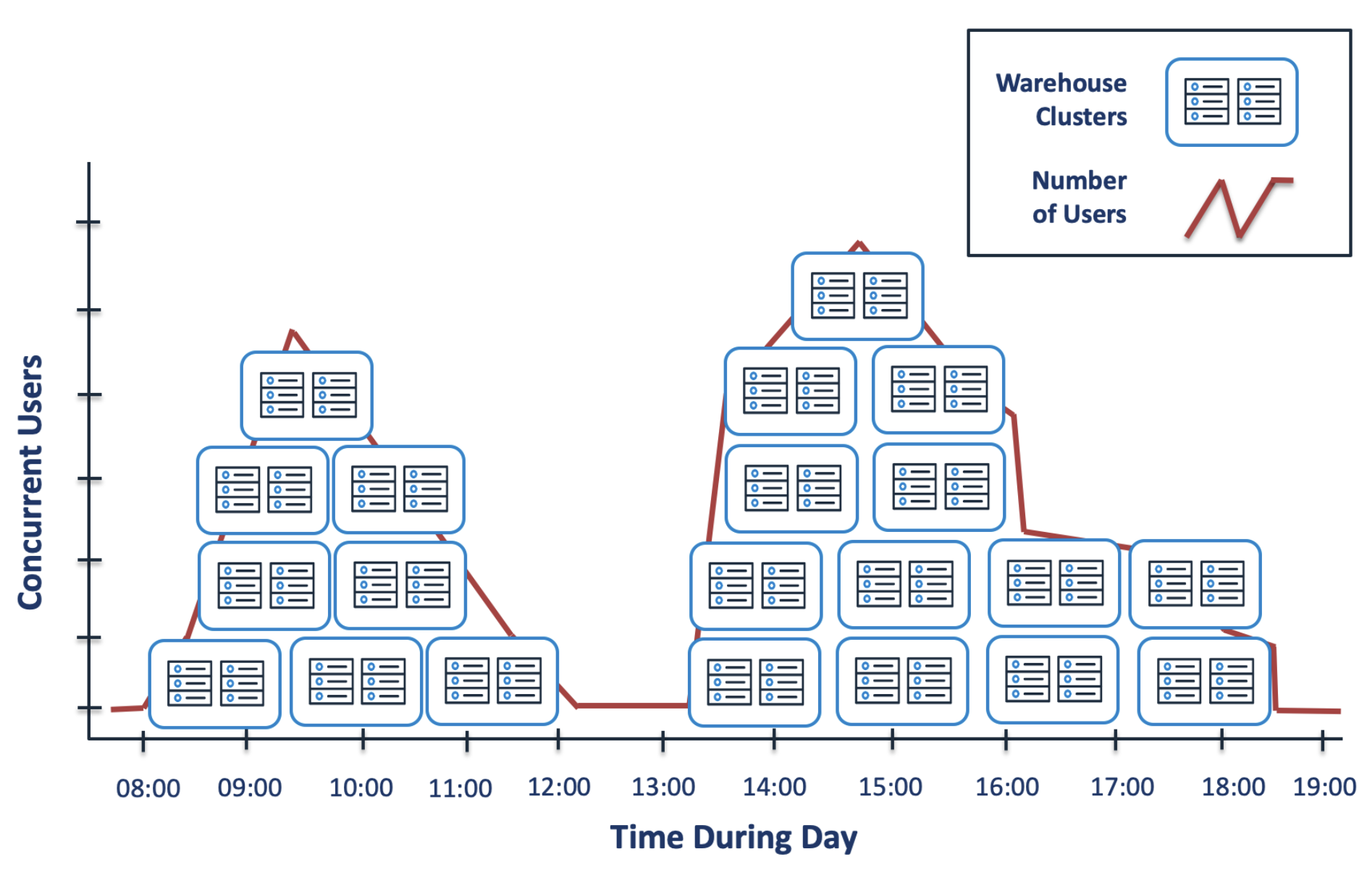
The diagram above shows how no clusters are allocated at 08:00, but this quickly grows to four as additional users run queries. When the workload subsides, the clusters are transparently suspended and rise again after lunch. When all SQL has been completed, the cluster transparently suspends after the predefined AUTO SUSPEND period.
Benchmarking Virtual Warehouse Performance
I repeatedly executed the following SQL query and adjusted the virtual warehouse size to demonstrate the power of different-sized virtual warehouses.
create or replace table lineitem as
select *
from snowflake_sample_data.tpch_sf10000.lineitem;
The above SQL copies a table holding over 60 billion rows of data in nearly two terabytes of storage, considerably bigger than the largest table on any Oracle-based data warehouse I’ve ever worked on. Executing a similar-sized process on the production system at a tier-one investment bank would have taken around 12 hours.
The graph below shows the effect of scaling up the warehouse and its impact on elapsed time and the processing rate.
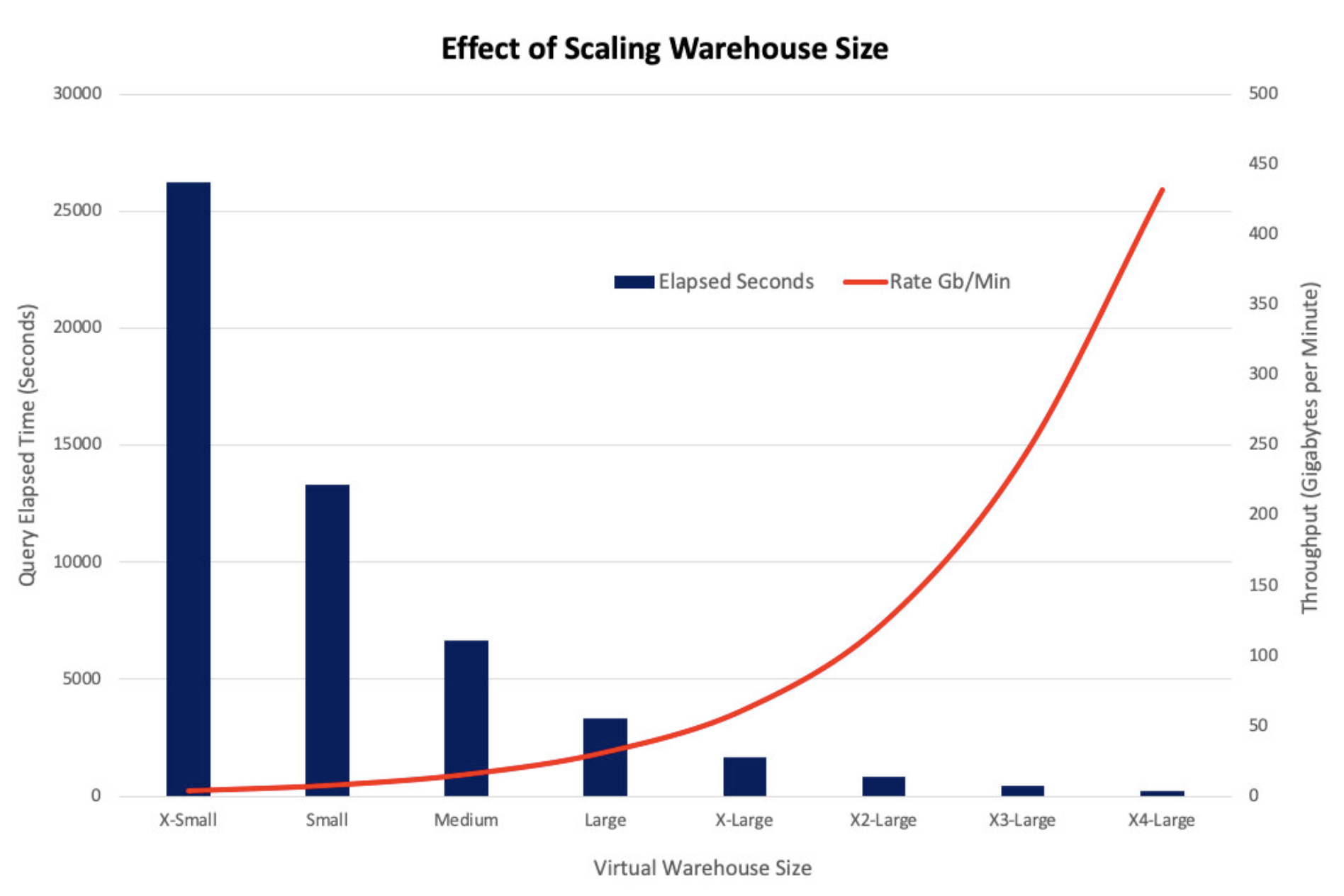
The graph above shows how query performance doubled as the warehouse increased. The elapsed time was reduced from over seven hours on an XSMALL warehouse to just four minutes on an X4LARGE.
It's a subtle but important point that the increase in query performance wasn't due to a faster machine but greater computing capacity.
This is worth noting because this query was able to scale up because it processed massive data volumes efficiently. Experience has demonstrated that queries processing smaller data volumes won't scale up and are better executed on an XSMALL or SMALL warehouse.
In this case, as the warehouse size was increased, the data processing rate increased from around four to 430 gigabytes per minute.
Snowflake Virtual Warehouse Cost
The table below shows the Snowflake Credit usage and estimates the USD cost per hour, assuming one credit costs $3.00.
| Size | Credits/Hour | Cost/Hour |
| XSMALL | 1 | $3.00 |
| SMALL | 2 | $6.00 |
| MEDIUM | 4 | $12.00 |
| LARGE | 8 | $24.00 |
| XLARGE | 16 | $48.00 |
| X2LARGE | 32 | $96.00 |
| X3LARGE | 64 | $192.00 |
| X4LARGE | 128 | $384.00 |
| X5LARGE | 256 | $768.00 |
| X6LARGE | 512 | $1,536.00 |
The actual cost per hour varies depending upon the cloud provider, region, and discount negotiated with Snowflake. However, assuming $3.00 per credit is a sensible starting point.
The critical insight from the above table is that although the cost per hour doubles each time, the capacity (and therefore query performance) also doubles. This means it's possible to execute the same query twice as fast for the exact same cost.
It also underscores the need to execute queries of similar size on the same warehouse size. One of the most common mistakes made by every Snowflake deployment is to execute a mixed workload in the same warehouse.
Conclusion
Virtual warehouses in Snowflake aren’t just a technical detail—they’re a core part of how the platform delivers performance and scales with demand. But too often, they’re treated as a black box. Size it up, leave it running, hope for the best.
What actually matters is understanding how warehouse configuration interacts with your workload. Concurrency, scaling, resource contention—these aren’t abstract concerns. They directly affect query performance, user experience, and cost.
There’s no universal right answer. But there is a right answer for your workload. And once you grasp how Snowflake handles compute behind the scenes, you’re in a much better position to make those decisions with confidence.

Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, he joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment. Certifications include Snowflake Data Superhero, Snowflake Subject Matter Expert, SnowPro Core, and SnowPro Advanced Architect.