Prediksi Penyakit Jantung menggunakan Random Forest
 Muhammad Ihsan
Muhammad Ihsan
Setelah mempelajari Decision Tree, sekarang kita mulai belajar algoritma yang merupakan pengembangan dari metode Decision Tree. Kata 'forest' di sini juga secara harfiah menggambarkan sekilas tentang apa yang terjadi di balik layar. Hal ini karena Random Forest menggunakan metode ensemble learning, yang artinya ia menggabungkan prediksi dari beberapa model untuk meningkatkan akurasi dan mengurangi overfitting.
Pengenalan Random Forest
Lantas bagaimana cara kerja dari random forest? Misalnya kita memiliki data kesehatan seperti usia, tekanan darah, kadar kolesterol, dan lain-lain. Kemudian kita ingin memprediksi apakah orang tersebut akan mengalami penyakit jantung berdasarkan data yang diberikan. Salah satu cara yang bisa diterapkan adalah menggunakan decision tree. Namun, kendalanya pada pohon keputusan adalah ia rentan terhadap overfitting, yang mana berpotensi tidak bekerja dengan baik pada data baru.
Lalu kita melakukan langkah alternatif tentang dengan membuat keputusan berdasarkan pendapat sekelompok orang, bukan hanya satu orang. Misalnya, jika pada kasus penyakit jantung tadi kita bertanya kepada 10 dokter tentang prediksinya, kita mungkin mendapatkan jawaban yang lebih akurat dan meyakinkan dengan mengambil mayoritas jawaban mereka, daripada hanya bertanya kepada satu dokter. Kira-kira seperti ini lah perumpamaan dari metode random forest
Cara Kerja Random Forest
Dari subset acak pada data latih, Random Forest bekerja dengan membangun banyak decision tree. Setiap pohon dilatih pada subset data yang berbeda, yang diambil menggunakan teknik yang disebut bootstrap sampling, di mana sampel dipilih secara acak (satu sampel dapat dipilih lebih dari sekali). Selain itu, pada setiap node dalam pohon, hanya subset acak dari semua fitur yang dipertimbangkan untuk dipecah, bukan semua fitur. Hal ini membantu mengurangi korelasi antar pohon. Setelah semua pohon dibuat, Random Forest menggabungkan prediksi dari semua pohon untuk membuat keputusan akhir. Untuk klasifikasi, ini biasanya dilakukan dengan voting mayoritas (prediksi kelas yang paling sering muncul). Untuk regresi, rata-rata dari semua prediksi pohon digunakan.
Random Forest memiliki beberapa keunggulan. Pertama, algoritma ini cenderung memberikan hasil yang lebih akurat dibandingkan dengan satu decision tree saja karena sifatnya yang menggabungkan prediksi dari banyak pohon. Kedua, Random Forest mengurangi risiko overfitting dengan menggabungkan banyak pohon yang dilatih pada subset data yang berbeda. Ketiga, algoritma ini dapat menangani missing value dengan lebih baik. Keempat, Random Forest memungkinkan kita untuk melihat fitur mana yang paling berpengaruh dalam prediksi.
Kelemahan Random Forest
Meskipun memiliki banyak keunggulan, Random Forest juga memiliki beberapa kelemahan. Membangun banyak pohon dan menggabungkan prediksi mereka bisa membutuhkan banyak waktu dan sumber daya komputasi. Selain itu, meskipun kita dapat melihat fitur-fitur yang penting dalam prediksi, secara keseluruhan model Random Forest kurang interpretatif jika dibandingkan dengan decision tree.
Implementasi : Prediksi Heart Failure
Setelah kita mempelajari sekilas tentang konsep random forest. Sekarang kita akan mencoba menerapkannya untuk melakukan klasifikasi kematian pasien menggunakan dataset "Heart Failure Clinical Records". Pertama-tama, kita mengimpor pustaka-pustaka penting seperti pandas, numpy, matplotlib, seaborn, serta modul-modul dari scikit-learn yang digunakan untuk preprocessing dan evaluasi model.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
Kemudian kita memuat dataset menggunakan pandas lalu menampilkan 5 baris teratas dari data.
# Load the dataset
url = "/kaggle/input/heart-failure-clinical-data/heart_failure_clinical_records_dataset.csv"
data = pd.read_csv(url)
# Display the first few rows of the dataset
data.head()

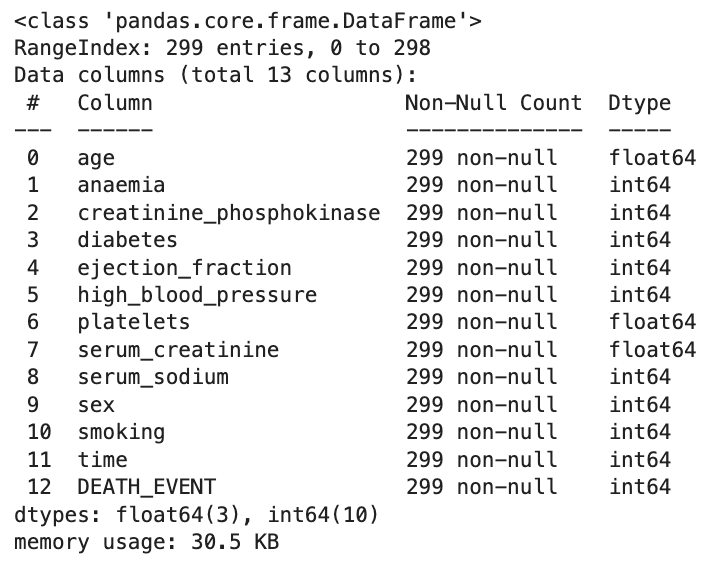
Selanjutnya adalah mengecek informasi dasar tentang dataset menggunakan data.info(). Di sini kita bisa mengetahui jumlah entri, kolom, tipe data, dan jumlah nilai non-null.
# Check the basic info of the dataset
data.info()
Setelah itu kita juga menampilkan ringkasan statistik dasar dari dataset menggunakan data.describe().
# Statistical summary of the dataset
data.describe()

Untuk keperluan visualisasi, di sini kita akan melihat distribusi variabel target / 'DEATH_EVENT'.
# Plotting the distribution of target variable
sns.countplot(x='DEATH_EVENT', data=data)
plt.title('Distribution of Target Variable')
plt.show()
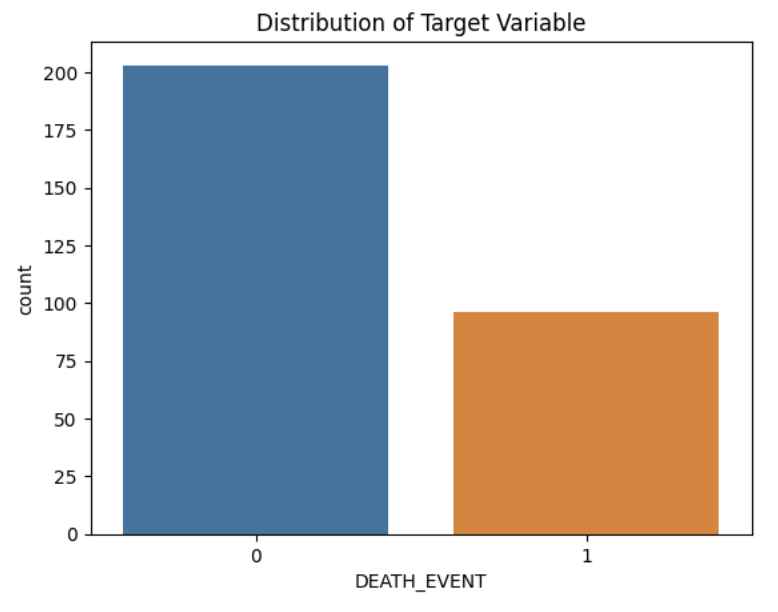
Dari hasil di atas terlihat bahwa data dengan label 0 lebih banyak daripada label 1. Selanjutnya kita akan membuat heatmap untuk melihat korelasi antar matrix.
# Correlation matrix
plt.figure(figsize=(12, 8))
sns.heatmap(data.corr(), annot=True, cmap='coolwarm')
plt.title('Correlation Matrix')
plt.show()
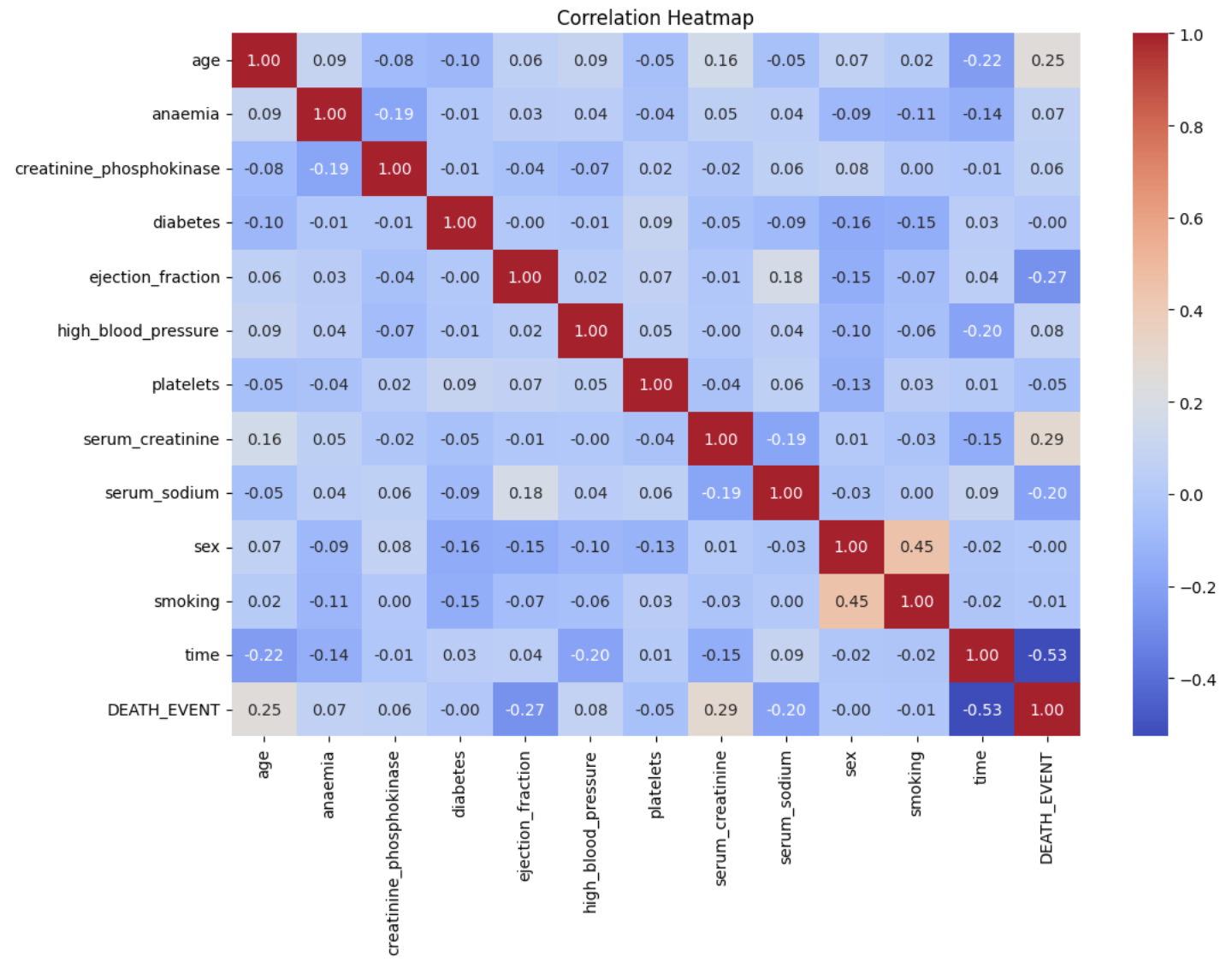
Selesai dengan visualisasi. Selanjutnya kita mempersiapkan data untuk training. Di sini kita memisahkan data menjadi fitur (X) dan target (y), dimana kolom 'DEATH_EVENT' dipisahkan dari dataset dan sisanya dijadikan fitur.
# Splitting the data into features and target
X = data.drop('DEATH_EVENT', axis=1)
y = data['DEATH_EVENT']
Dataset kemudian dibagi menjadi set pelatihan dan pengujian dengan perbandingan 80:20 menggunakan train_test_split, memastikan hasil yang dapat direproduksi dengan random_state=42.
# Splitting the data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Fitur-fitur kemudian dinormalisasi menggunakan StandardScaler untuk mengurangi bias yang mungkin terjadi jika tidak dinormalisasi.
# Standardizing the features
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_test = scaler.transform(X_test)
Setelah data seiap, kita inisialisasi model Random Forest dan melatihnya pada set pelatihan.
# Initialize the Random Forest Classifier
rf_classifier = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
rf_classifier.fit(X_train, y_train)
Setelah pelatihan, model digunakan untuk memprediksi hasil pada set pengujian.
# Make predictions
y_pred = rf_classifier.predict(X_test)
Evaluasi model dilakukan menggunakan metrik seperti accuracy score, classification report, dan confusion matrix.
# Evaluate the model
print("Accuracy Score:", accuracy_score(y_test, y_pred))
print("\nClassification Report:\n", classification_report(y_test, y_pred))
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues')
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
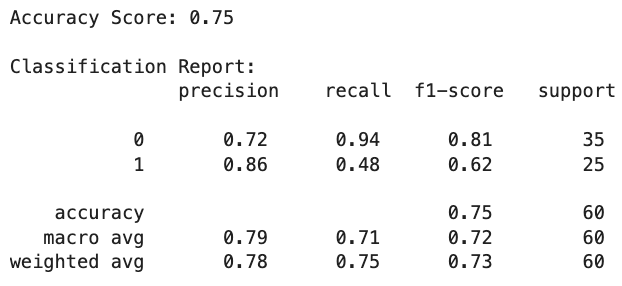
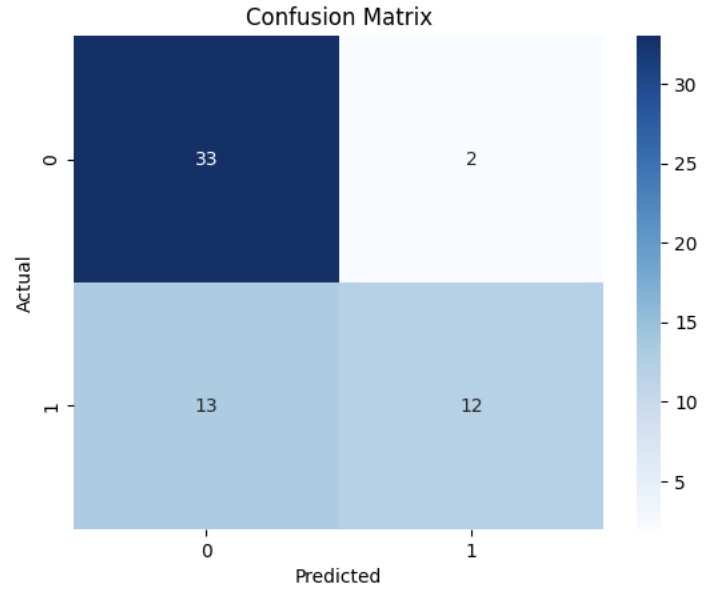
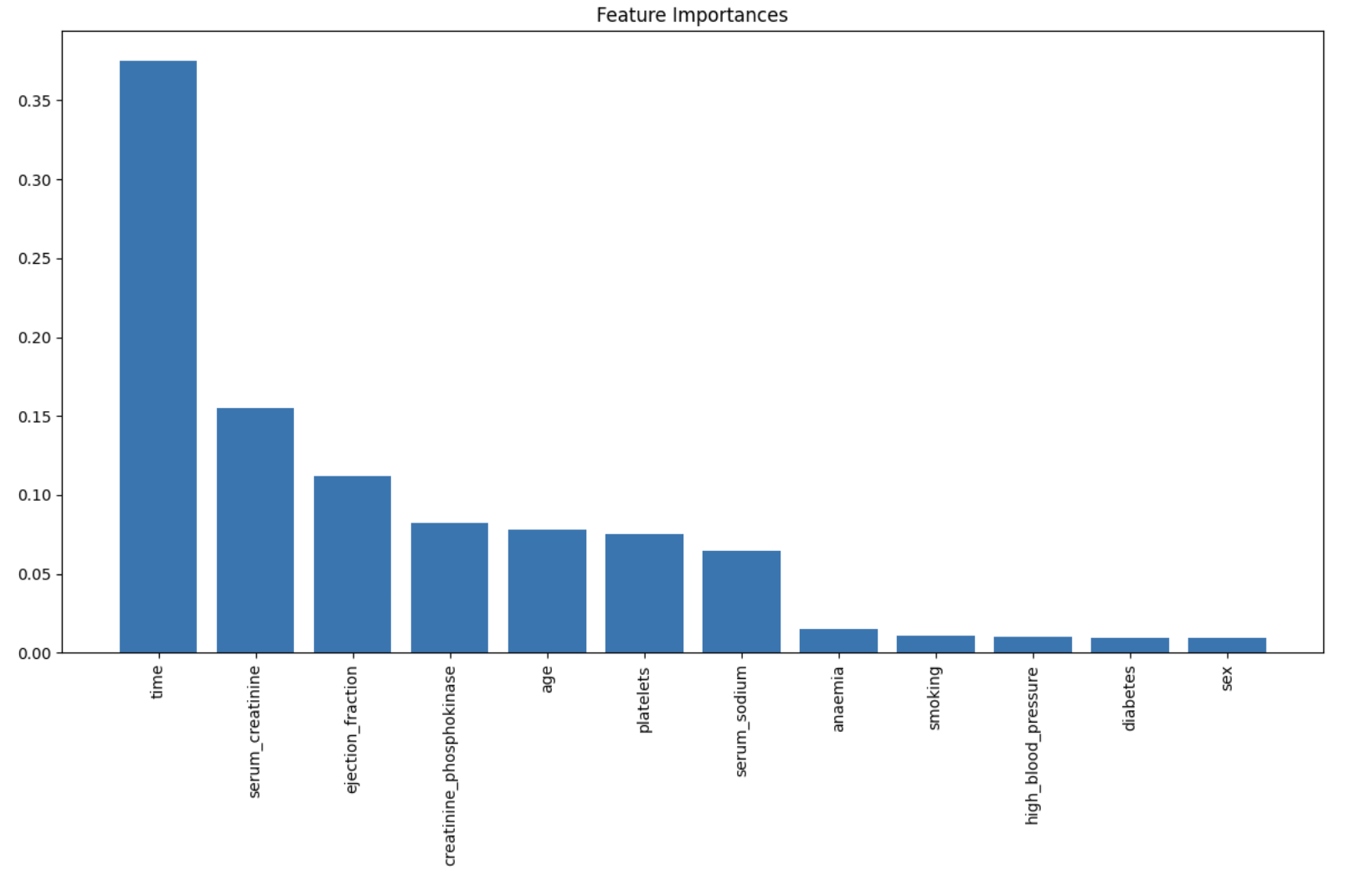
Hasil evaluasi menunjukkan akurasi model serta metrik precision, recall, dan f1-score untuk masing-masing kelas target. Matriks kebingungan digambarkan menggunakan heatmap untuk visualisasi yang lebih baik. Terakhir, kita bisa melihat nilai fitur-fitur penting yang digunakan dalam prediksi menggunakan atribut feature_importances_ yang ada di model Random Forest.
# Feature importance
importances = rf_classifier.feature_importances_
indices = np.argsort(importances)[::-1]
features = X.columns
# Plotting feature importances
plt.figure(figsize=(12, 8))
plt.title('Feature Importances')
plt.bar(range(X.shape[1]), importances[indices], align='center')
plt.xticks(range(X.shape[1]), features[indices], rotation=90)
plt.tight_layout()
plt.show()
Kesimpulan
Dalam artikel ini, kita telah mempelajari tentang algoritma Random Forest, sebuah metode pembelajaran mesin yang menggabungkan prediksi dari banyak decision tree yang dilatih pada subset acak dari data pelatihan, yang mana hal tersebut akan membantu meningkatkan akurasi dan mengurangi risiko overfitting.
Kita juga mencoba menerapkannya pada dataset "Heart Failure Clinical Records" untuk melakukan klasifikasi kematian pasien. Hasil evaluasi menunjukkan bahwa Random Forest dapat memberikan hasil akurasi 75%. Dan di akhir, kita juga mengidentifikasi fitur-fitur yang paling berpengaruh dalam prediksi. Terima kasih sudah membaca artikel ini, tetap semangat, terus berlatih dan selamat belajar!.
Kode Sumber : Kaggle
Subscribe to my newsletter
Read articles from Muhammad Ihsan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Muhammad Ihsan
Muhammad Ihsan
AI, ML and DL Enthusiast. https://www.upwork.com/freelancers/emhaihsan https://github.com/emhaihsan https://linkedin.com/in/emhaihsan