How Gradient Boosting Machines Work: A Machine Learning Overview
 Sujit Nirmal
Sujit Nirmal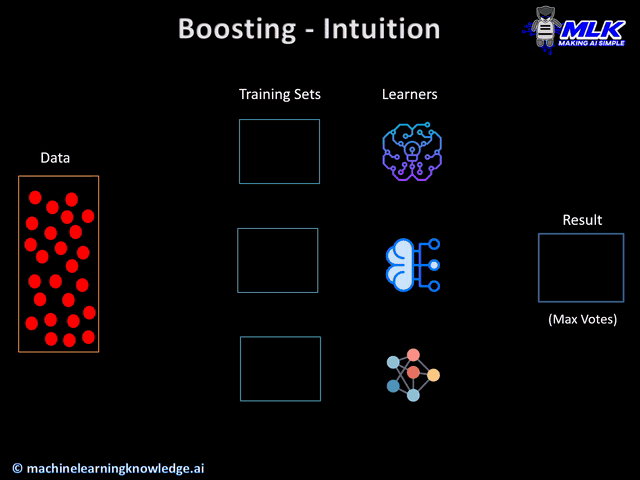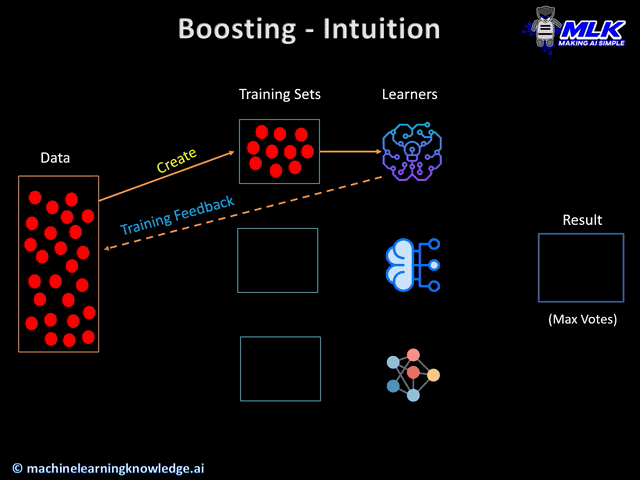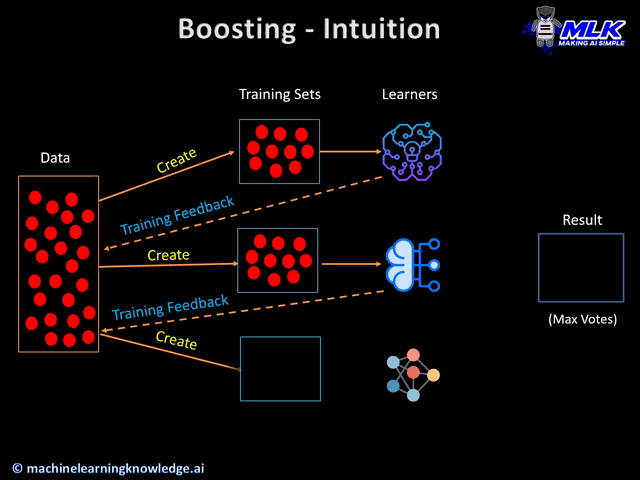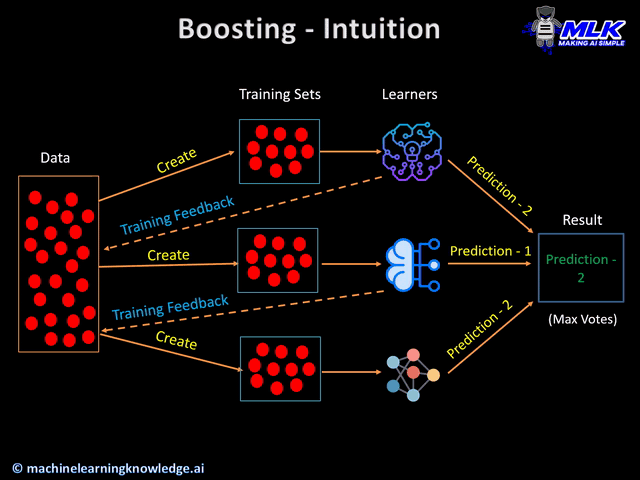
Introduction
Gradient Boosting Machines (GBM) are a powerful ensemble learning technique that builds models sequentially, with each new model correcting the errors of the previous ones. This method is highly effective for both classification and regression tasks and is widely used in various machine learning competitions and real-world applications.
What is Gradient Boosting?
Gradient Boosting is an iterative process that combines the predictions of multiple weak learners (typically decision trees) to create a strong predictive model. Unlike Random Forests, which build trees independently, GBM builds trees sequentially, with each tree trying to correct the errors of the previous ones.
How Does Gradient Boosting Work?
Initialize the Model: Start with an initial model, usually a simple one like the mean of the target values.
Calculate Residuals: Compute the residuals (errors) between the actual target values and the predictions of the current model.
Fit a New Model: Train a new model to predict the residuals.
Update the Model: Add the new model to the existing model to improve the predictions.
Repeat: Repeat steps 2-4 for a specified number of iterations or until the residuals are minimized.
Key Components of GBM
Loss Function: Measures how well the model's predictions match the actual target values. Common loss functions include Mean Squared Error (MSE) for regression and Log-Loss for classification.
Weak Learner: Typically a decision tree with limited depth to prevent overfitting.
Learning Rate: A hyperparameter that controls the contribution of each new model. A smaller learning rate requires more iterations but can lead to better performance.
Code Example: Implementing GBM with Scikit-Learn
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingRegressor
from sklearn.metrics import mean_squared_error
# Load dataset
data = pd.read_csv('your_dataset.csv')
X = data.drop('target', axis=1)
y = data['target']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize and train the model
gbm = GradientBoostingRegressor(n_estimators=100, learning_rate=0.1, max_depth=3, random_state=42)
gbm.fit(X_train, y_train)
# Make predictions
y_pred = gbm.predict(X_test)
# Evaluate the model
mse = mean_squared_error(y_test, y_pred)
print(f'Mean Squared Error: {mse}')
Visualizing the Learning Process
To better understand how GBM improves over iterations, you can visualize the training and validation errors:
import matplotlib.pyplot as plt
# Plot training and validation errors
train_errors = []
val_errors = []
for i, y_pred in enumerate(gbm.staged_predict(X_train)):
train_errors.append(mean_squared_error(y_train, y_pred))
val_errors.append(mean_squared_error(y_test, gbm.staged_predict(X_test)[i]))
plt.plot(train_errors, label='Training Error')
plt.plot(val_errors, label='Validation Error')
plt.xlabel('Number of Trees')
plt.ylabel('Mean Squared Error')
plt.legend()
plt.show()
Resources for Further Learning
Animations and Visuals
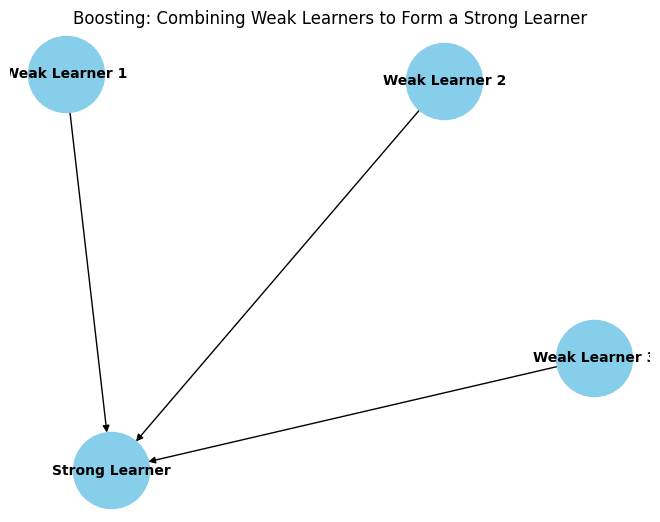
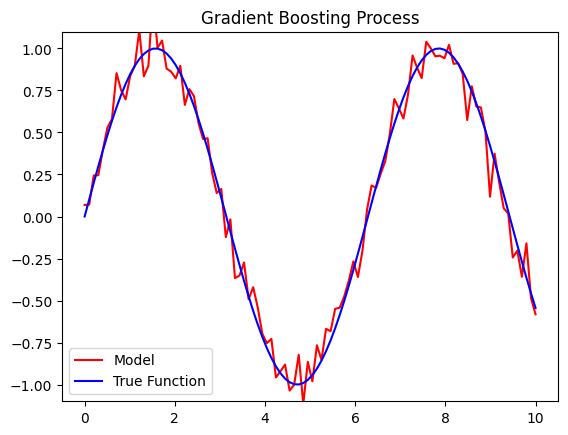
Conclusion
Gradient Boosting Machines are a powerful tool in the machine learning toolkit, offering high accuracy and flexibility. By understanding and implementing GBM, you can tackle more complex problems and improve your predictive models.
"Happy Coding !!!"
"Happy Coding Inferno !!!"
Subscribe to my newsletter
Read articles from Sujit Nirmal directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sujit Nirmal
Sujit Nirmal
👋 Hi there! I'm Sujit Nirmal, a AI /ML Developer with a passion for creating intelligent, seamless ML applications. With a strong foundation in both machine learning and Deep Learning I thrive at the intersection of data and technology.