KeyBERT: Effortless Keyword Extraction
 Lê Đức Minh
Lê Đức MinhUncover the Most Important Keywords from Your Text with Ease
Introduction
While developing the RAG system, I discovered that users typically write vague statements rather than serious inquiries. It is tough for an LLM to understand it, and it is much more difficult for the retriever to search the vector database for something similar to the words. Some approaches must be developed to address this problem.

Image generated by Playground.com. The prompt: A word cloud composed of various keywords, with the most frequently used keywords appearing larger and more prominent. The word cloud represents the landscape of search terms and their relative importance.
Keywords are vital for every successful piece of content, whether it's a discussion, a piece of writing, or something else. This strategy involves looking for keywords in the user's queries, which will help the retriever focus on those terms to identify comparable phrases, making it simpler to obtain proximal results.
KeyBERT is an LLM-based tool for keyword extraction. It employs BERT embeddings and basic cosine similarity to determine which sub-phrases in a document are the most similar to the document itself. The way it works is described below:
Document embeddings are extracted with BERT to get a document-level representation.
Word embeddings are used to extract N-gram words/phrases.
KeyBERT employs cosine similarity to determine which words/phrases are most similar to the document. The most corresponding phrases were selected as the ones that best characterize the whole document.
Here is the KeyBERT Github’s repo:
Note: I strongly recommend visiting the KeyBERT repo because it introduces integrating with
sentence_transformersand LLMs, allowing the KeyBERT to stay up to date with the latest innovations in the area.
Code Implementation
Problem statement: Extract important words or a document.
Solution: Assuming the document is in .pdf format, I will use pypdf to read the PDF file. After that, I use KeyBERT to extract keywords from the parsed data.
To begin with, I installed and called the necessary libraries:
# Install necessary packages
!pip install -q keybert pypdf
# Our sample
!wget https://arxiv.org/pdf/1706.03762.pdf
# Import libraries
import re
from keybert import KeyBERT
from pypdf import PdfReader
Then, I parsed the .pdf file with the PdfReader. We can view that number of pages and the content of each page:
reader = PdfReader("/content/1706.03762.pdf")
print(len(reader.pages)) # 15 pages
page_no = 0
page = reader.pages[page_no]
text = page.extract_text()
print(text)
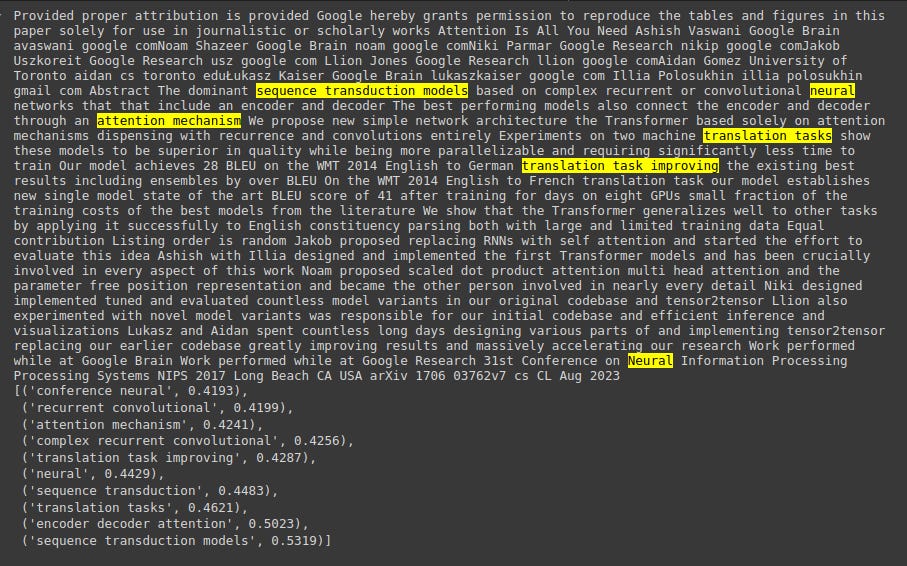
"""Provided proper attribution is provided, Google hereby grants permission to
reproduce the tables and figures in this paper solely for use in journalistic or
scholarly works.
Attention Is All You Need
Ashish Vaswani∗
Google Brain
avaswani@google.comNoam Shazeer∗
Google Brain
noam@google.comNiki Parmar∗
Google Research
nikip@google.comJakob Uszkoreit∗
Google Research
usz@google.com
Llion Jones∗
Google Research
llion@google.comAidan N. Gomez∗ †
University of Toronto
aidan@cs.toronto.eduŁukasz Kaiser∗
Google Brain
lukaszkaiser@google.com
Illia Polosukhin∗ ‡
illia.polosukhin@gmail.com
Abstract
The dominant sequence transduction models are based on complex recurrent or
convolutional neural networks that include an encoder and a decoder. The best
performing models also connect the encoder and decoder through an attention
mechanism. We propose a new simple network architecture, the Transformer,
based solely on attention mechanisms, dispensing with recurrence and convolutions
entirely. Experiments on two machine translation tasks show these models to
be superior in quality while being more parallelizable and requiring significantly
less time to train. Our model achieves 28.4 BLEU on the WMT 2014 English-
to-German translation task, improving over the existing best results, including
ensembles, by over 2 BLEU. On the WMT 2014 English-to-French translation task,
our model establishes a new single-model state-of-the-art BLEU score of 41.8 after
training for 3.5 days on eight GPUs, a small fraction of the training costs of the
best models from the literature. We show that the Transformer generalizes well to
other tasks by applying it successfully to English constituency parsing both with
large and limited training data.
....
"""
I used KeyBERT to extract keywords:
# You can un-note the remove \n if you want.
# text = text.replace("\n", " ")
kw_model = KeyBERT()
keywords = kw_model.extract_keywords(text, keyphrase_ngram_range=(1, 3), highlight=True, stop_words='english', use_maxsum=True, top_n=10)
Here are some explanations about the code:
To specify the length of the generated keywords/keyphrases, you can use the
keyphrase_ngram_rangeparameter. For example, setkeyphrase_ngram_rangeto (1, 2) or higher, depending on how many words you want in the generated keyphrases.The
use_maxsumfunction in KeyBERT selects the 2 x top_n most comparable words/phrases in the document. Then it takes alltop_npossibilities from the 2 xtop_nwords and extracts the combination with the least cosine similarity.The
top_nindicates the number of response keywords that you want.
Here is the result:
Conclusion
In this post, I quickly presented KeyBERT, an incredible keyword extraction tool that uses BERT-embeddings and basic cosine similarity to identify the sub-phrases in a text that are the most similar to the content itself. From my perspective, the tool is lightweight and simple to use. Furthermore, it supports a wide range of alternative models and LLMs, making it easy to combine with other systems. As a result, this collection is essential for people looking to improve their skills in the NLP profession.
Subscribe to my newsletter
Read articles from Lê Đức Minh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by