Need for speed, but where do I store all of this data?
 Shreyan Das
Shreyan Das
Dear Diary,
The most dreaded day in the life of any data engineer came to me a while ago — our TL sat us down to tell us that we had been billed an enormous amount for our cloud storage in the last quarter, and we needed to find a way to cut down storage costs. As if cleaning frightfully messy data, trying not to doze off monitoring pipeline executions, and resolving job failures at supersonic speed weren't pain enough! Optimising storage is every data engineer's horror story, and my nightmare had just begun.
Now, I'm not one to grind; if I see a low-hanging fruit, I'd promptly pluck it and make a run for it. And a low-hanging fruit I did see — our entire staging layer was a big mountain of CSV files. If you've read some of my other articles, you'd know I work on a comprehensive Business Intelligence and Analytics project for a big client. That's a lot of data to store in CSV format, raw, clunky, uncompressed, and unimpressive. I thought I had the answer, just change all the file formats from CSV to Parquet, et voilà, done and dusted. Turns out, I should have paid more attention to the daily Scripture readings and taken a lesson from Eve: lead us not into temptation, because the tempting fruit is usually tainted.
For those reading that don't know, Parquet is an efficient file format which stores relational data in a columnar arrangement, which makes it super fast for analytics use cases. Additionally, it squeezes data into compact blocks, immensely reducing volume by factor by a factor of up to 10, depending on the data type and structure. The other benefits of parquet though important are not relevant to the matter at hand.

So, I sat down to test my hypothesis. I tried using our existing ingestion architecture to pull data from one of client's massive tables and toss it into our blob storage as a parquet file, but, of course, that would make my life too easy, and the universe won't allow it. Our servers did not have Java Runtime Environment (which is required for creating parquets) and I do not have installation privileges. And, thus, began my painful journey of simulating a production environment ... on my 8 gigabyte personal laptop (sorry, MacBook, I love you to the core, but you're a toy tank opposite the Godzilla-sized compute clusters we have on the cloud).
First, I had to get my hands on a large-enough, realistic database. Fortunately, MySQL's Official Pages contain a few sample databases that are quite life-like and fit the bill. I went with the airportdb database cos it kinda looked cool. If you thought the challenges ended with that, prepare to pity me. On downloading and unzipping the database I found that they had been compressed to ZST files. A bit of Googling revealed I needed to decompress the file using specific tools, and I hate downloading unnecessary applications. But there was no way I could use those ZST files as they were. I mean, just look at this! There's no way I could parse this!
After some more research I was able to whip up a short python script to decompress the files and extract the material. Here's a link to the ZST conversion script I used.
In real-world scenarios, most data engineering applications fetch data from a database and then sink it to a warehouse. So, I then proceeded to load the data into a local MySQL Server. Adrian's article was immensely helpful in this regard.
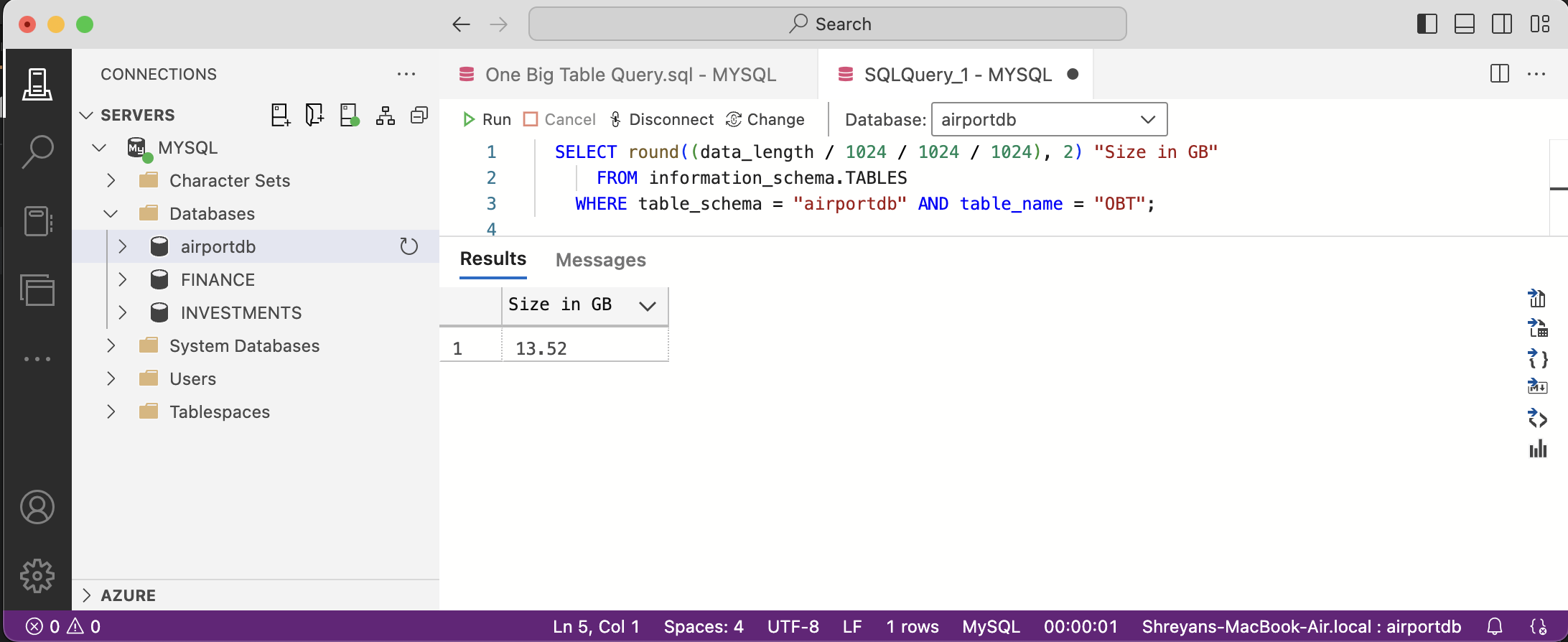
I assumed it would be easier to consolidate all data into a single file instead of creating a separate ingestion pipeline for each of the 14 tables in the database. With that reasoning, I chose the One Big Table data model. Due to duplication of data because of the joins, the data would swell up to volumes resembling those I deal with at my job. Even with most of the tables joined, the total data size only went up to 13GB, and I usually deal with terabytes of data as a data engineer. Take a look at the OBT Query here.
With a database set up and a query planned, I was set to get my hands mucky. All that remained was to run a Python script to 'ingest' this data and save it as a CSV and then a Parquet file and compare the results. Alas, things didn't go as planned. The PySpark job I initially designed crashed. Big time.
Look, I am a rookie with Spark. I am like the little kid carrying a bag twice his size who topples over backwards. Spark is too large a weapon to wield in my hands, and I couldn't configure it to process this one big table to save my life. No matter how I configured it, Spark kept throwing a heartbeatinterval timeout error (heartbeat?? — more like heartless for doing me so wrong). And after excruciating days of waiting and debugging, configuring and reconfiguring that made me want to flatline the damn thing, I decided it was time to part ways and call the grapes sour. I chalked it up to the limited processing power of my laptop.
In the end, I picked a single table and then wrote a mock ingestion pipeline script to mimic the ELT process on my project, which saves the SQL table as flat file. You'll find the code in my GitHub repository. You can follow the steps I took, and check out the OBT that I wanted to ingest (and with any luck, get better results!)
And now, for the pièce de résistance, the outcome of all this labour. As you can see, the parquet file is incredibly slim; it shreds the space occupied by the same data by more than a half. But ...
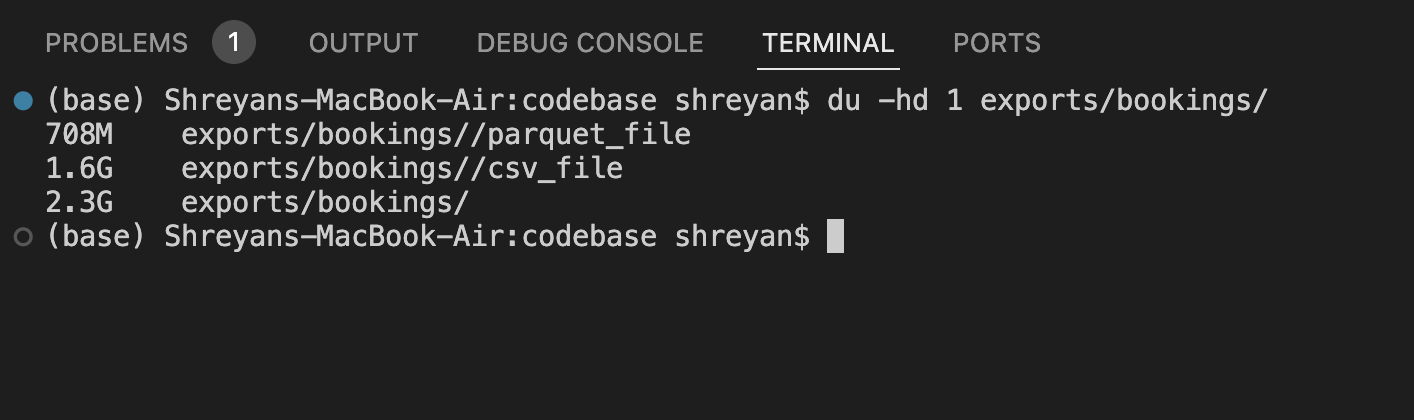
It took me 19 minutes to save as a CSV file and 25 minutes to save as a parquet file.
(Execution time for exporting CSV file)
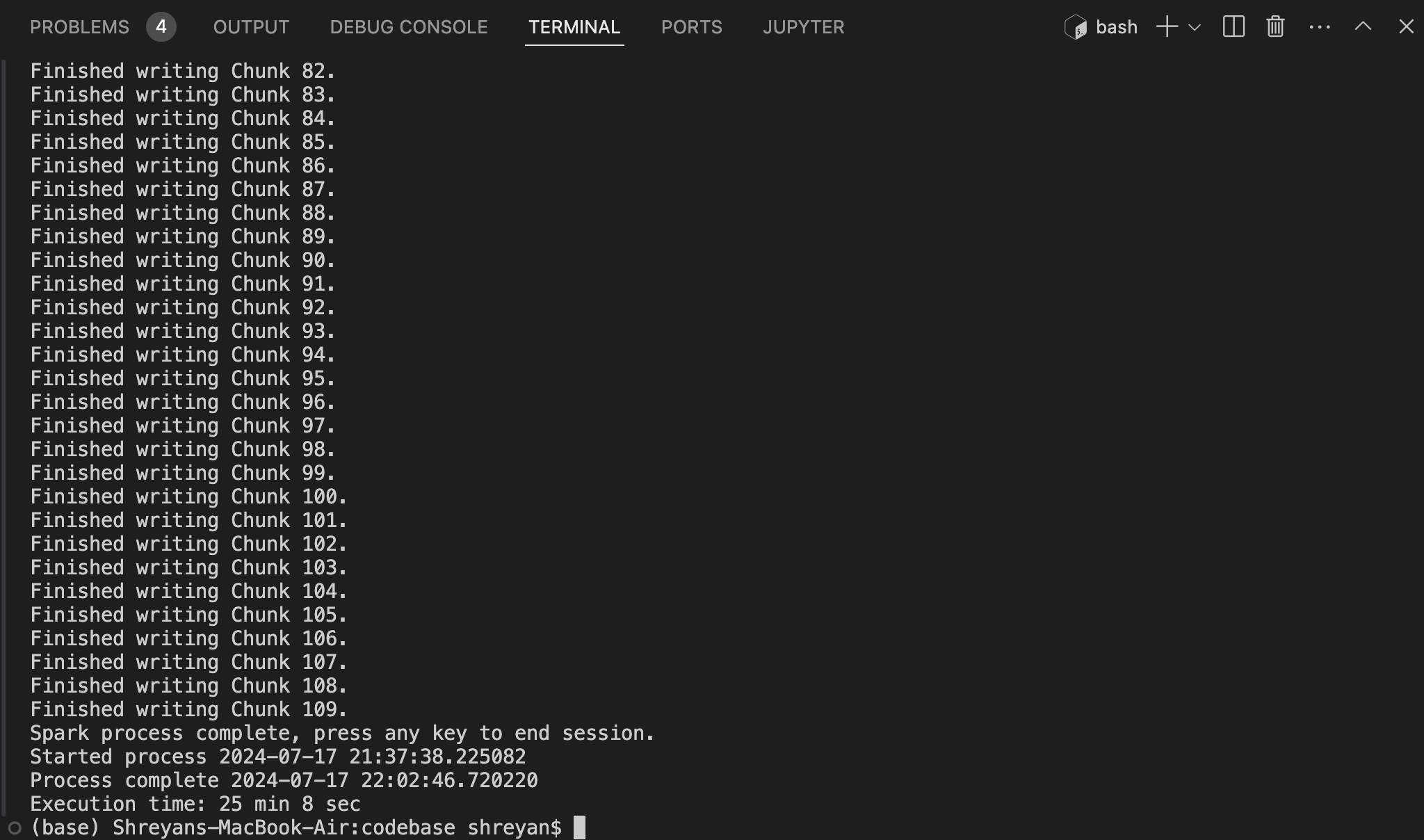
(Execution time for exporting parquet file)
This difference may not seem like much, but imagine how that figure would snowball when you scale it up to the enterprise level where you need to ingest many hundred terabytes of data. You see, there is an overhead associated with compressing the file while saving as parquet as opposed to just flushing the contents as they are (CSV).
A scenario where this wouldn't work
One of the clauses in the contract with our client states that we are not permitted to generate any data requests during business hours, as it imposes a heavy load on the client's servers with the potential of locking out all other business operations. This would severely impact the business because it would halt billing, payments, invoicing, accounting and other critical functions. We have been generously given a very small window to fetch data in, and changing all pipelines to ingest data in parquet format is guaranteed to surpass the timeline.
This was a success story (not really, no)! Even though I didn't solve my problem, I at least learnt something from the experience is what a loser like me would say. But to sum up, parquet has its perks, no doubt, but it's not the one-stop shop for all analytics needs. The CSV file has its uses. It's simple, straightforward, and it writes fast. That's something to consider when architecting any project. Do I prioritise my write speed, or would the extra space make a dent in the wallet?
Shreyan
Subscribe to my newsletter
Read articles from Shreyan Das directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by