Best Practices for Using Bulk COPY to Load Data into Snowflake
 John Ryan
John Ryan
This article summarizes the Snowflake best practices for bulk loading using the COPY INTO TABLE command. After reading this article, you'll understand precisely how the COPY command works and be able to deploy a simple but cost-efficient data-loading strategy.
Although we will summarize the main data ingestion options, the focus is on COPY, one of the most frequently used data loading methods but surprisingly misunderstood.
The techniques described in this article were used to bulk load over 300 TBs of data in just three days. Load sizes varied from a few bytes to terabytes, but the strategy worked incredibly well without any attempt to split data files.
Best of all, the solution was remarkably easy to deploy yet highly scalable and cost-effective.
Snowflake Data Ingestion - What Problem are we trying to solve?
The diagram below illustrates that loading data in any database involves striking a balance between three competing priorities.
Maximizing Throughput: This means loading potentially massive data volumes as quickly as possible, often essential when migrating existing systems or during regular large-volume data loads.
Minimizing Latency: This means loading files as quickly as possible. Often a critical requirement for real-time data delivery and analysis.
Controlling Cost: This means achieving the two previous requirements as efficiently as possible. Remember, Snowflake bills for compute on a consumption basis, and if deployed inefficiently, it can lead to a potentially significant overspend.
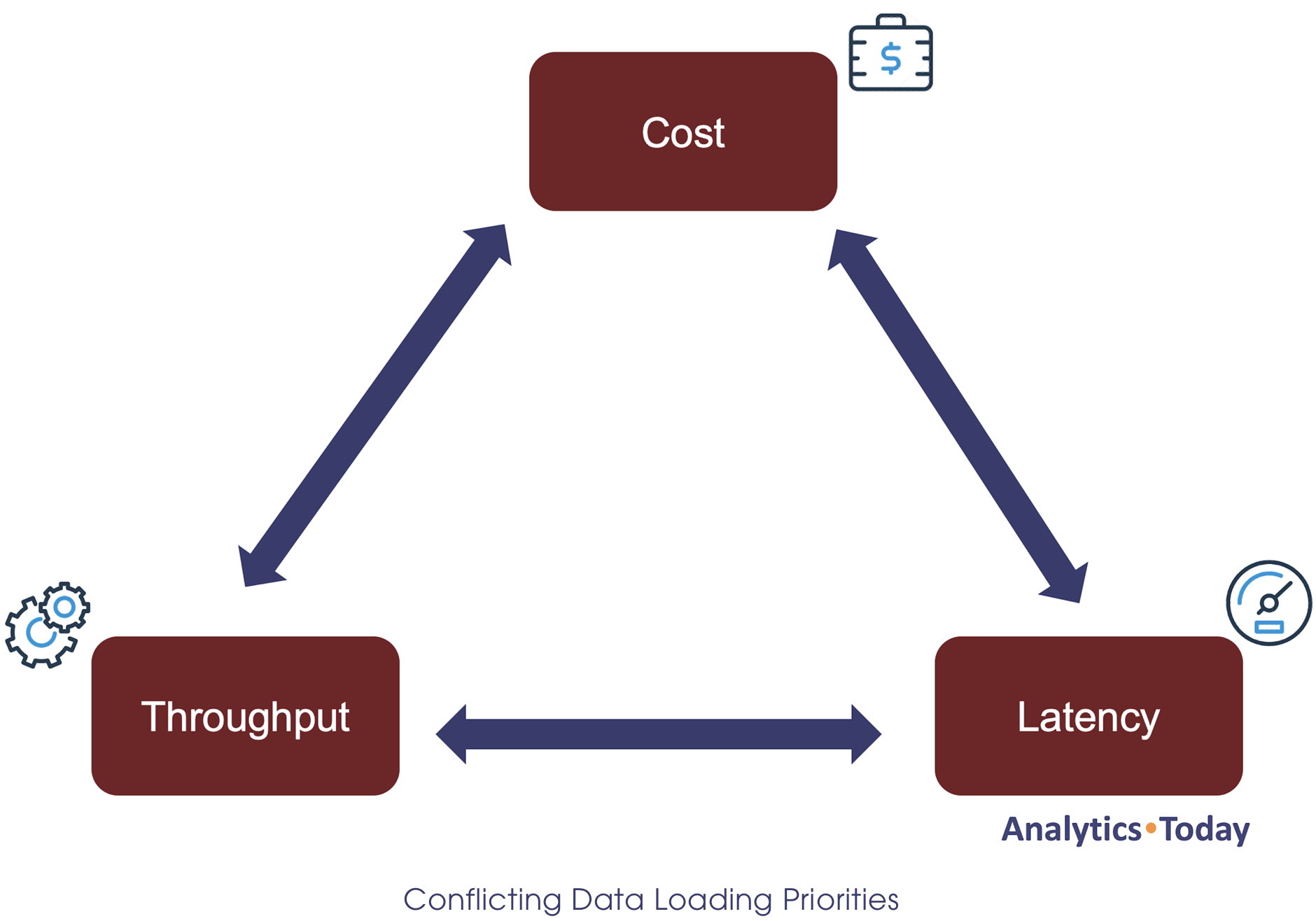
Understanding the above diagram is critical in designing a fast and efficient data ingestion strategy. Understanding the trade-off leads to several key questions which will also help drive the approach:
Delivery Frequency: Is the data pulled regularly or pushed by an external application? Data loads tend to fall into one of these two categories. They are delivered as part of a batch process, perhaps daily or every hour. Regular batch loads often deliver data for several tables, including transactional and related reference data, whereas erratic (push) data delivery tends to provide a smaller number of feeds, for example, temperature measurements from a single IoT device.
Acceptable Latency: Is it critical the data is loaded and processed in near real-time? The definition of real-time can vary from a few minutes to seconds. Often batch loads are less of a priority, whereas real-time delivery needs low-latency data loading to support instant data analysis.
Data Volume: For each Table, what's the approximate size in megabytes or gigabytes? The row count is less critical than the compressed physical data volume. Snowflake is remarkably fast and can load a 5GB data file in under ten minutes. At this scale, the number of rows loaded is not important.
The answer to questions 1 and 2 above helps to identify the most appropriate data loading strategy. In summary, data loading tends to fall into one of the following categories:
Batch Loading: This typically means using a Snowflake COPY command to load data into several tables before starting a batch transform operation to clean and integrate the data ready for analysis. Batch processing prioritizes throughput (loading and transforming large data volumes) rather than reducing latency – how quickly the data is available.
Micro-Batch Loading: Can be implemented using Snowpipe and typically involves loading data as soon as the files are available. This approach means you must deploy a Change Data Capture (CDC) process to identify when new data has arrived. A commonly used approach involves using Snowflake Streams to track the arrival of new rows, coordinated using Snowflake Tasks.
Real-Time Streaming: Uses Snowpipe Streaming. Whereas Snowpipe is designed for bulk loads from files sized around 100-250MB of compressed data (perhaps millions of rows), Snowpipe Streaming works on the row level and reduces latency to a few seconds. While Snowpipe streaming prioritizes latency, the article Snowflake Data Loading Best Practices indicates this technique is both highly scalable and cost-efficient.
Want to learn more from a Snowflake Expert? Click on the image below for training from Analytics Today.

Loading Data into Snowflake: Options Available
The diagram below illustrates the most common techniques for Snowflake data ingestion, including COPY, Snowpipe and Snowpipe Streaming.
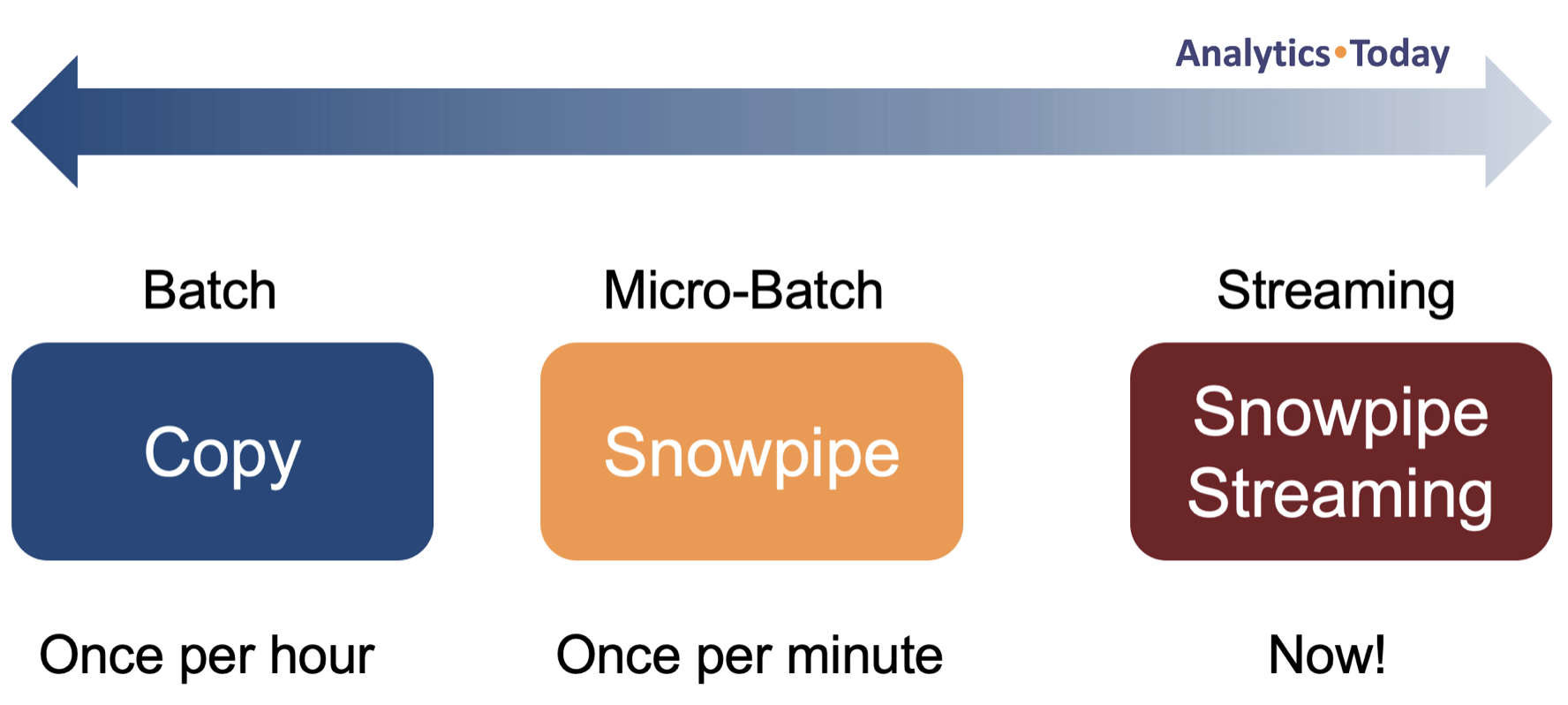
The above diagram highlights the first data loading best practice - use a standard loading mechanism. It may involve using an ELT tool (for example, Matillion or Informatica), which is fine because even 3rd party tools almost certainly use one of the above tools under the hood.
The remainder of this article will focus on bulk loading using the COPY INTO TABLE.
Bulk Data Loading – Using Snowflake COPY command
Batch data loads should use the Snowflake COPY command. In addition to simplicity and speed, many Snowflake COPY Options are available to perform simple data validation (data type and position) and support multiple file formats.
The diagram below illustrates the overall process:
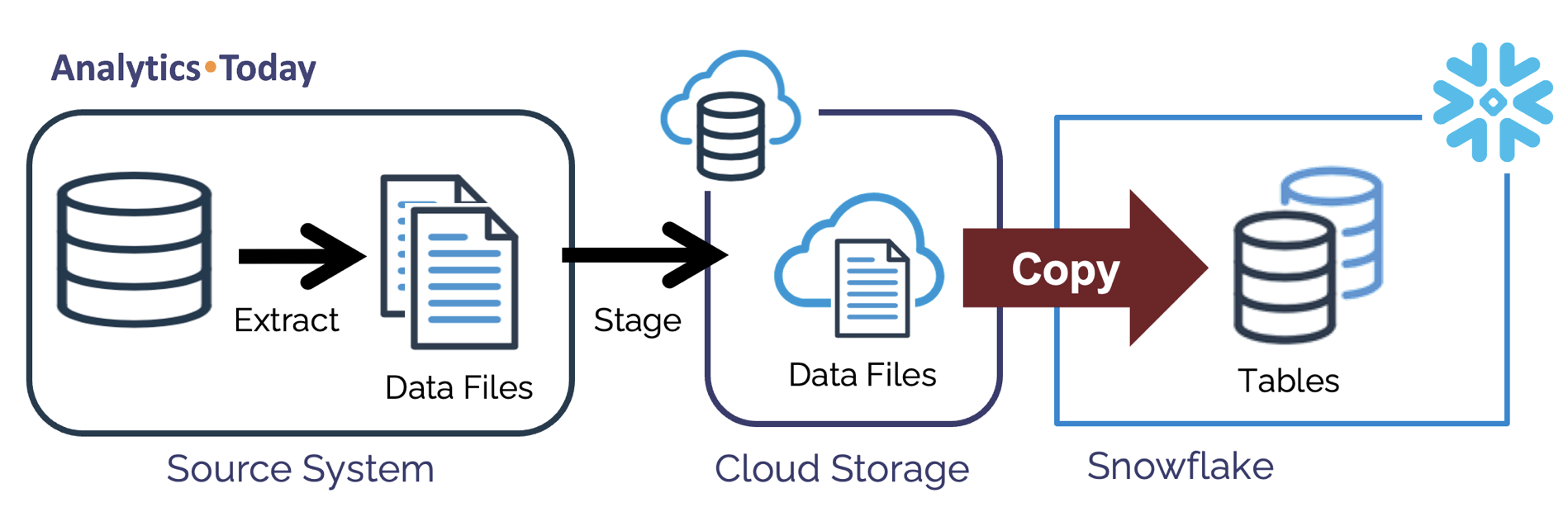
When loading data to Snowflake, the steps include the following:
Extract: Extract data files from the source system. Supported file formats include CSV, JSON, Avro, Parquet, ORC and XML.
Stage: Load the data files to Cloud Storage using a Snowflake Internal or External stage as needed.
Load: Execute a Snowflake COPY command to load the data into a transient staging table.
You will need to deploy a suitably sized Virtual Warehouse to execute the COPY command, which leads to one of the most critical questions: What size virtual warehouse do we need?
Snowflake Copy Command: Warehouse Size?
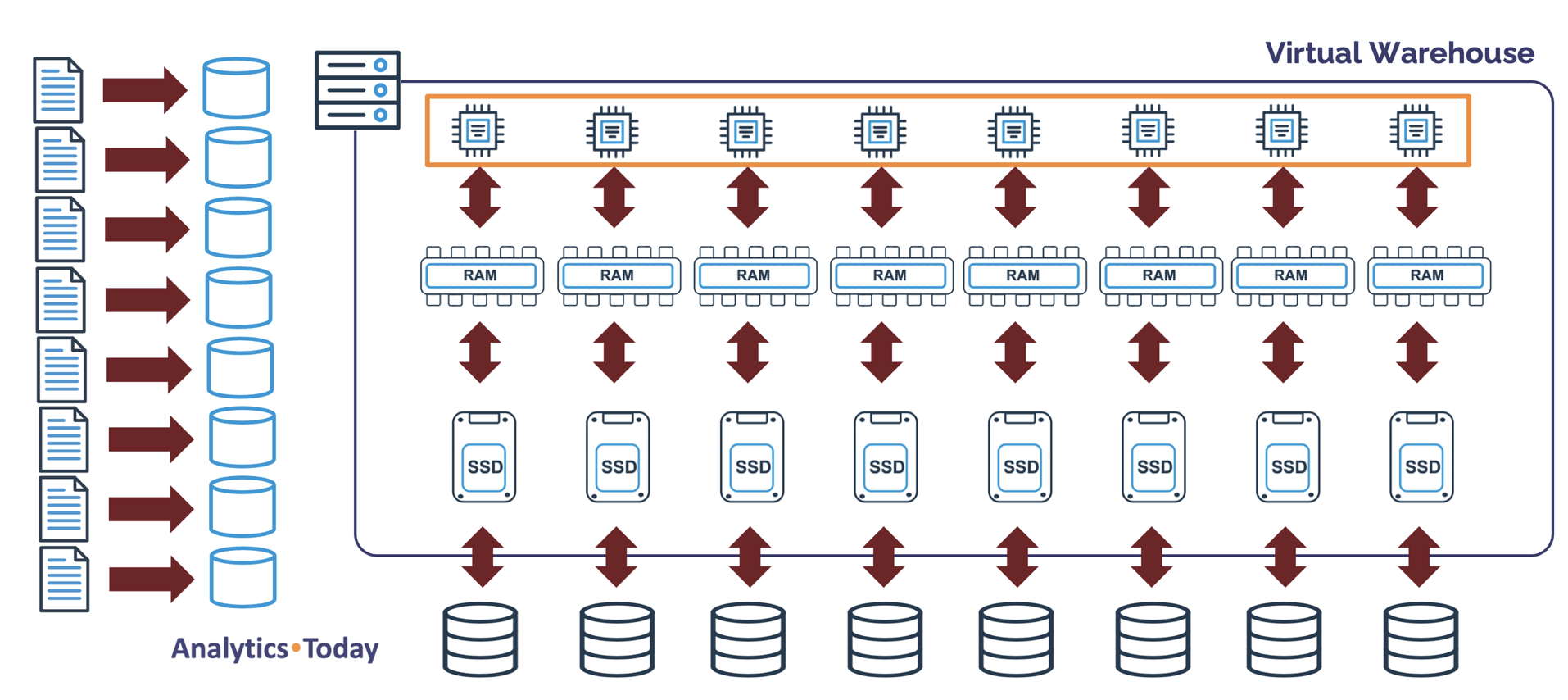
The diagram below illustrates the internals of a Virtual Warehouse node, which currently has eight CPUs, memory, and SSD local storage. The cloud provider's memory and SSD size varies, but the CPU count is presently fixed at eight.
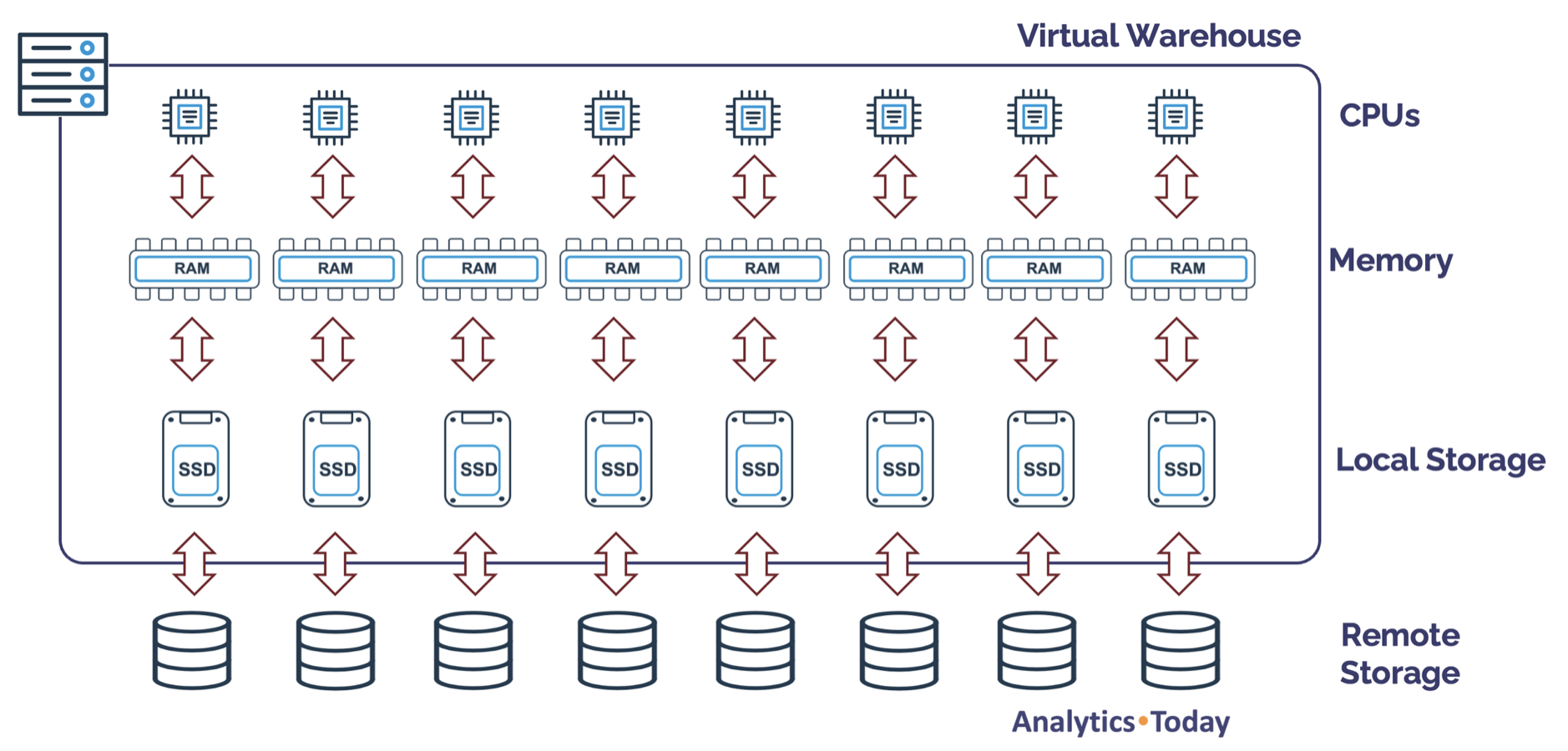
The number of CPUs per node is critical as it determines the number of files a Snowflake COPY command can load in parallel. This ranges from 8 CPUs on an XSMALL cluster to over a thousand on an X4LARGE.
It's important to understand as we increase the T-Shirt size, we increase not only the number of nodes (and therefore potential load throughput) but also the charge rate. For example, an X4LARGE warehouse is charged 128 credits per hour compared to an X-SMALL.
Let's discuss how Snowflake behaves as you increase the Virtual Warehouse size.
Snowflake COPY into Table: XSMALL Warehouse
The following SQL statement executes a COPY INTO TABLE to load data files into the SALES table.
copy into sales
from @sales-stage;
Snowflake automatically tracks which data files have already been loaded, and assuming there was only one new file to load, the diagram below illustrates the virtual warehouse utilization.
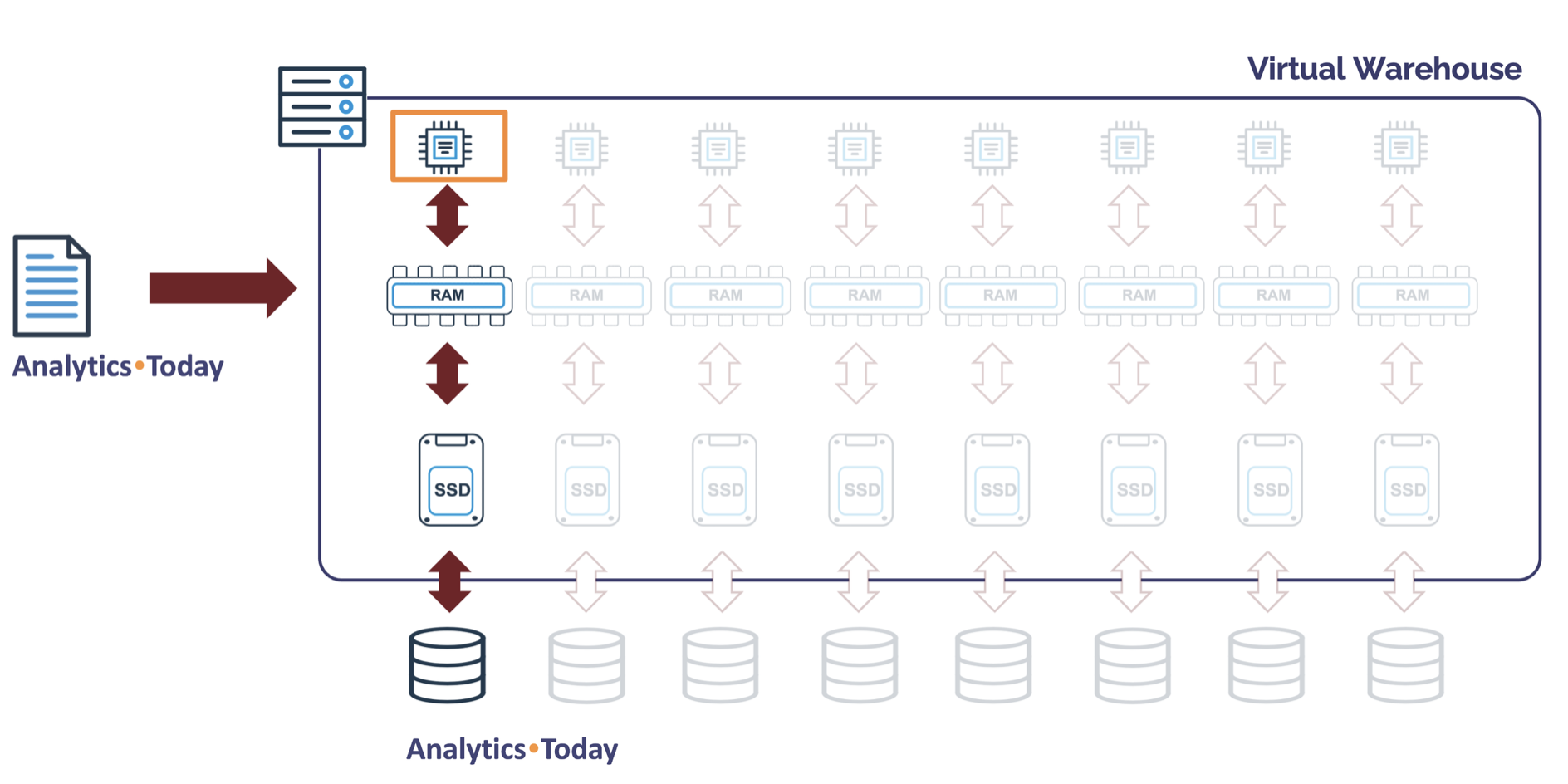
Snowflake sequentially reads each file using a single CPU and loads the data. If, however, several files are available to ingest to a table, they will be loaded in parallel.
To demonstrate the load rate on an XSMALL warehouse, I ran a benchmark load of ~86m rows from the sample table, STORE_SALES, which produced between one and eight data files sized ~5GB.
Loading a single 5GB file on an XSMALL warehouse took 7m 34s. However, loading eight files in parallel ingested nearly 40GB of data in just 9m 15s. There is a clear advantage in loading multiple data files in parallel, even on an XSMALL warehouse.
Snowflake COPY into Table: MEDIUM size Warehouse
The diagram below illustrates how Snowflake handles a single COPY INTO TABLE operation with a single file on a MEDIUM-size warehouse.
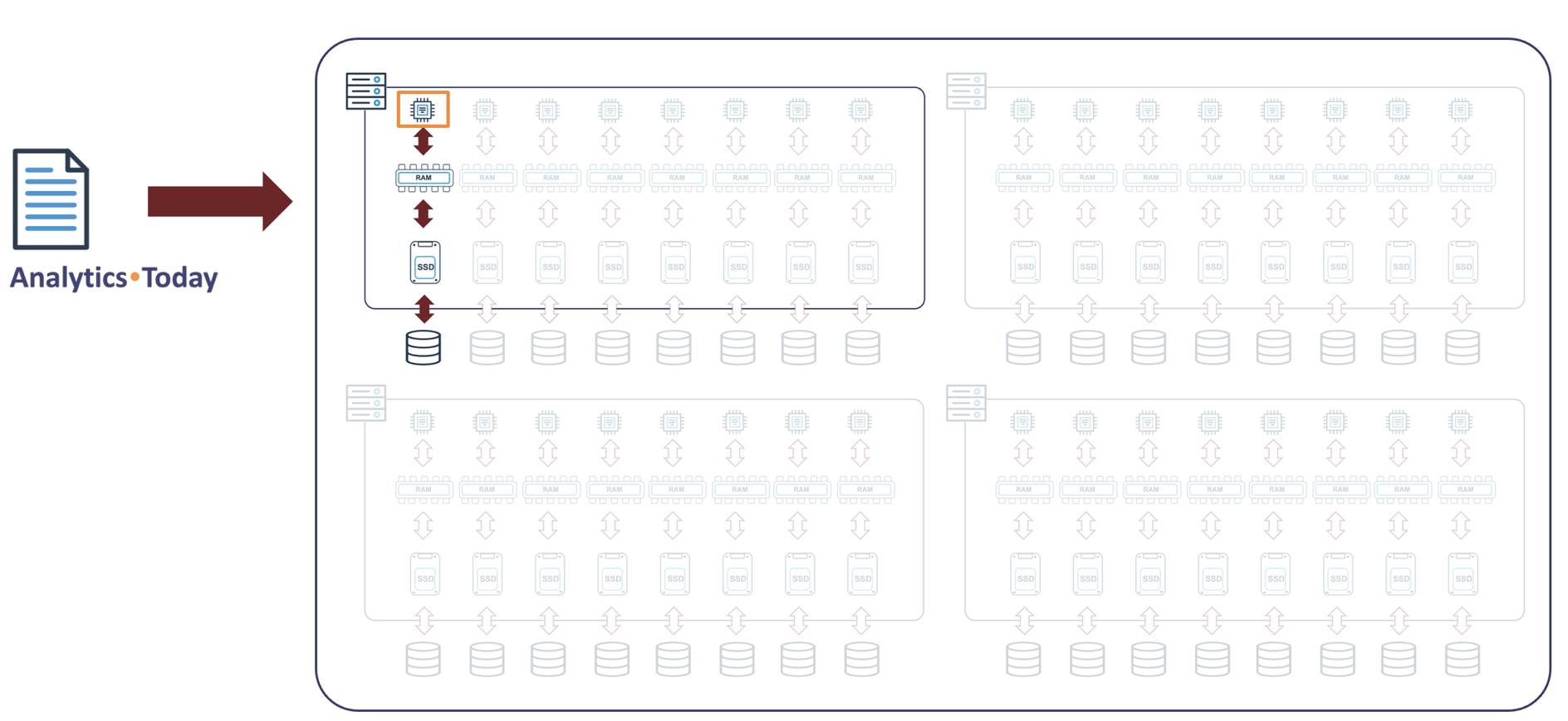
As the above diagram illustrates, only one CPU is used, and since the remaining 31 CPUs are idle (assuming no other running queries), the warehouse utilization is potentially as low as 0.03%.
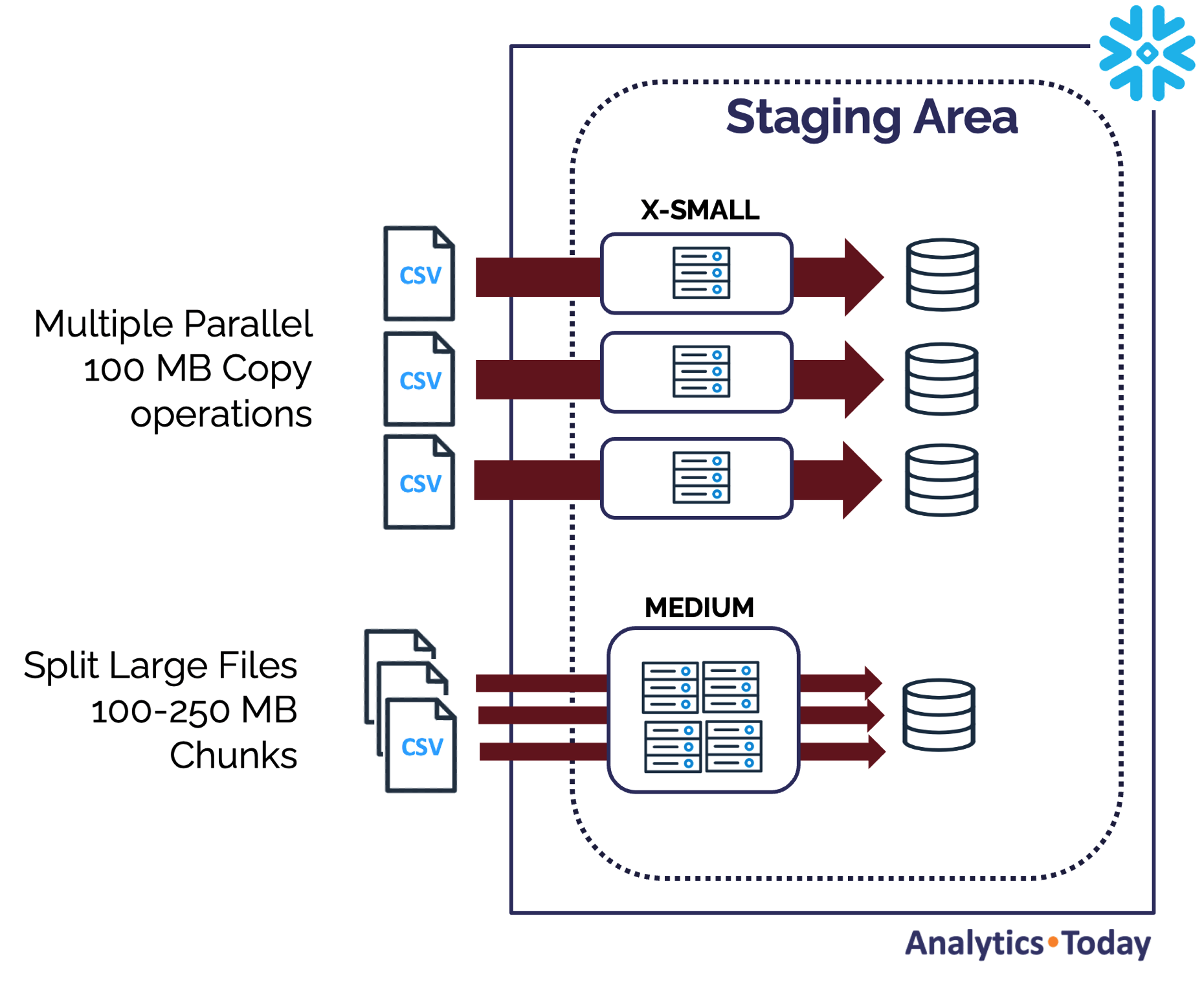
Snowflake File Size Recommendations
Snowflake recommends a file size of between 100-250MB and that we split large files into chunks and match the warehouse CPU count to the approximate number of files to be loaded.
On a large and complex data-intensive platform with thousands of tables loaded daily, it's unsurprising that many Snowflake deployments ignore the advice and load the data on the same warehouse used for transformation. This is, however, a potentially expensive mistake.
Warehouse Utilization and Credit Cost
It's reasonable to assume that the load rate in a virtual warehouse will vary throughout the day. The diagram below illustrates a situation where a single MEDIUM-sized warehouse is deployed to COPY data into Snowflake.
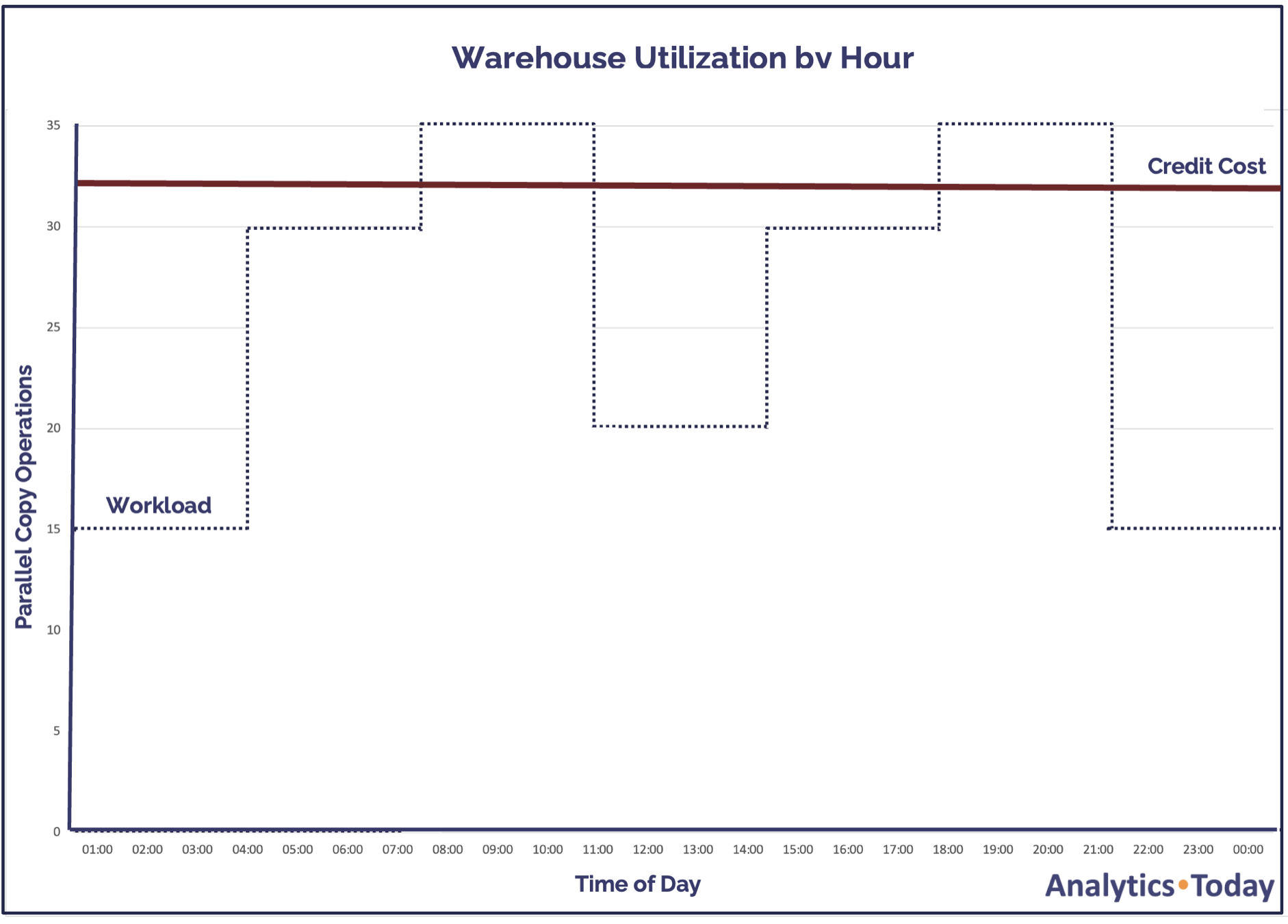
Assuming data is loaded from various source systems throughout the day, it would cost 96 credits per day (4 x 24).
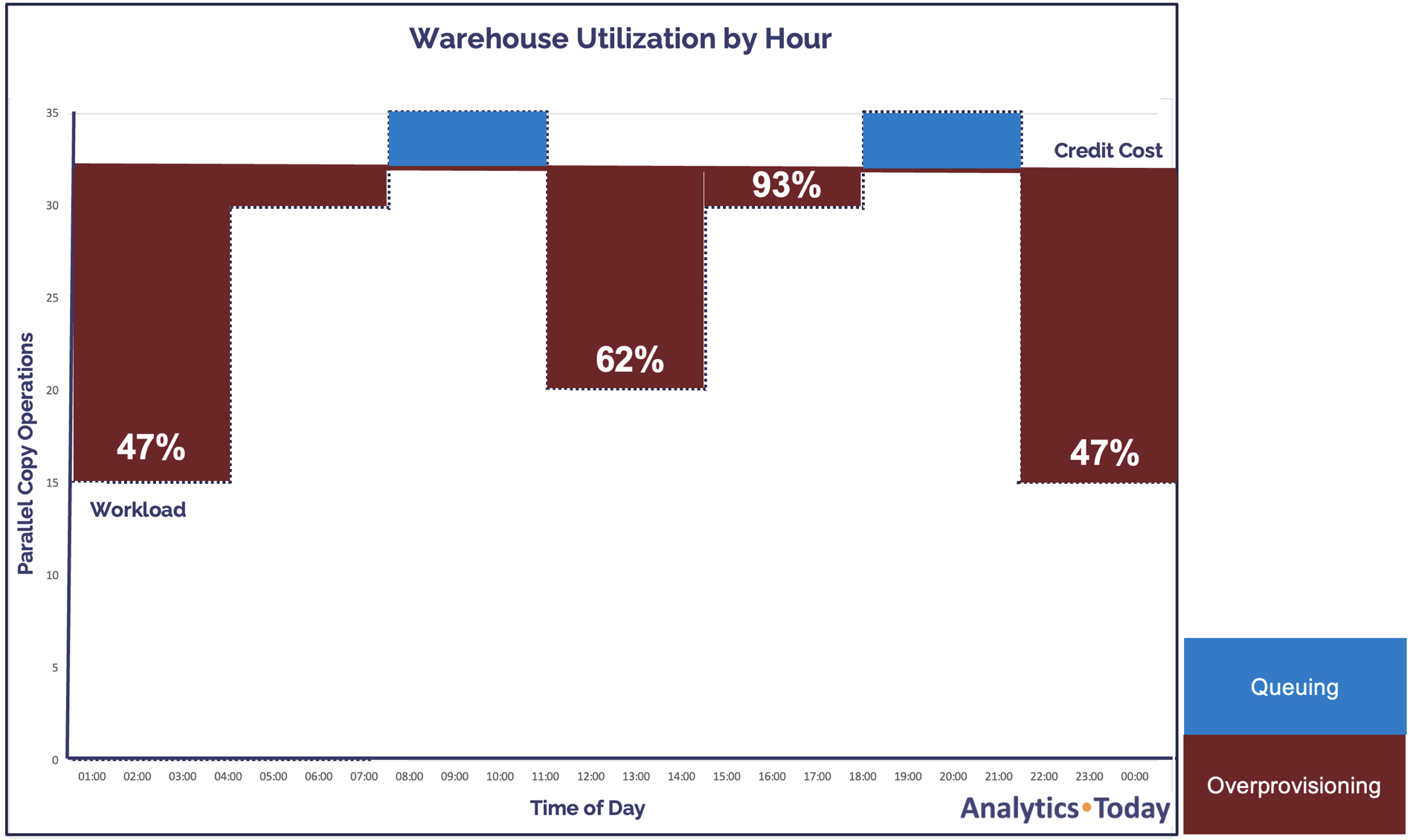
The diagram below illustrates the potential for over-provisioning and consequent inefficient credit spend. Depending upon the number of loads executed, we can expect some queuing (where Snowflake queues COPY commands until sufficient resources are available). Still, equally, warehouse utilization falls as low as 47%.
Data Ingestion Using the Snowflake Multi-Cluster feature
An alternative to the fixed-size warehouse described above involves using the Snowflake multi-cluster feature,which automatically adds additional same-size clusters as the number of concurrent queries increases during the day.
The SQL Statement below shows a statement to create a multi-Cluster warehouse available on Snowflake Enterprise Edition or above.
create warehouse prod_standard_copy_wh with
warehouse_size = XSMALL
min_cluster_count = 1
max_cluster_count = 4
auto_suspend = 60
scaling_policy = STANDARD;
The multi-cluster feature is more commonly associated with end-user queries and is designed to avoid queuing impacting overall query performance during busy times. Using this feature, clusters are automatically adjusted to cope with varying numbers of concurrent COPY operations.
The diagram below illustrates how this approach affects the load profile. Snowflake automatically adjusts the number of clusters as it detects queuing, in this case, up to a limit of four clusters. Clusters are automatically suspended as the number of concurrent queries subsides.
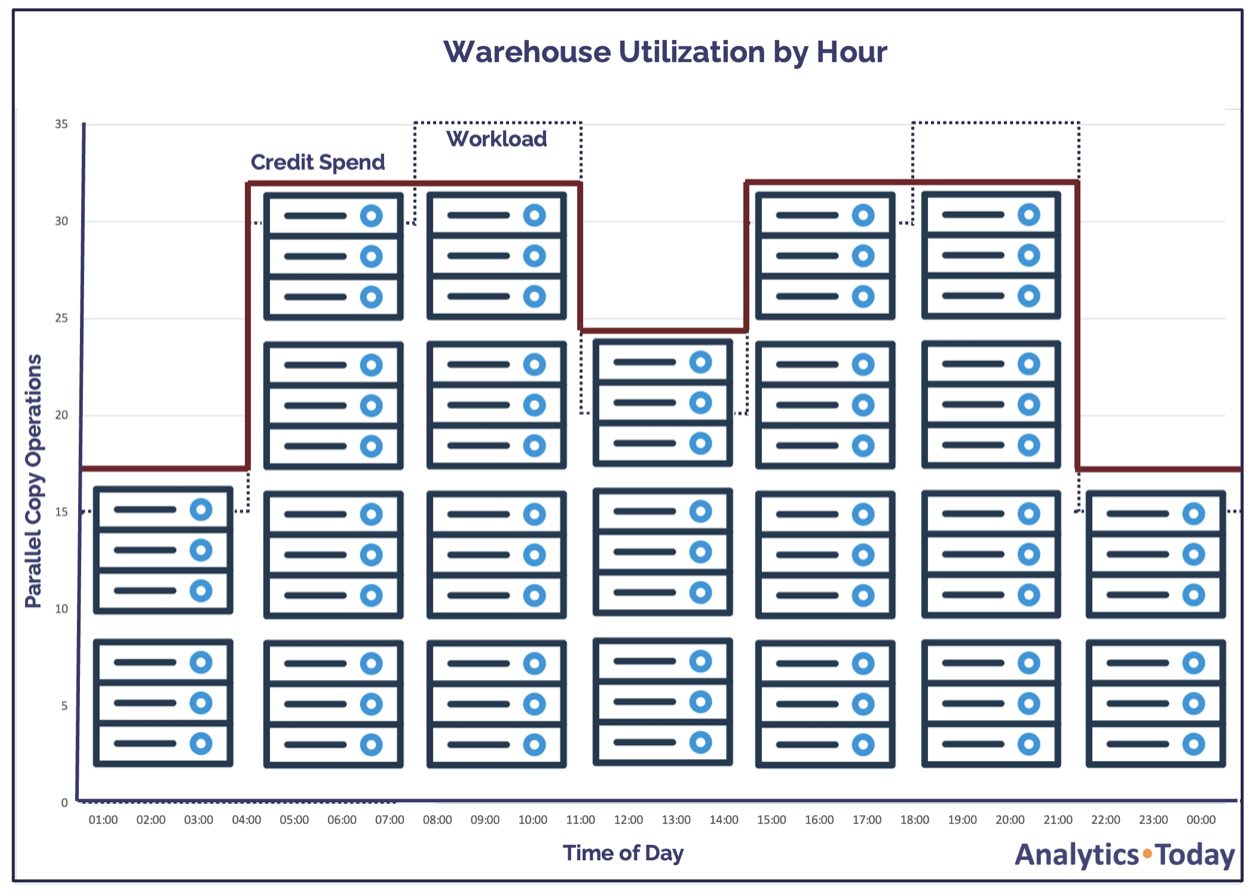
Depending upon the need to deliver data quickly, we could adjust the SCALING POLICY to ECONOMY, which waits until there is six minutes of work queued before adding additional clusters. This approach prioritizes cost saving over minimizing latency and will lead to additional queuing but is a sensible approach if low latency is not the priority.
It’s worth knowing, that in the context of batch processing, a moderate level of query queuing is acceptable as it demonstrates the virtual warehouse is fully utilized.
The diagram below shows the impact on daily credit spend and warehouse utilization. Unlike the fixed-size MEDIUM warehouse approach described above, this solution has a minimum warehouse utilization of around 83% and is far more cost-effective.
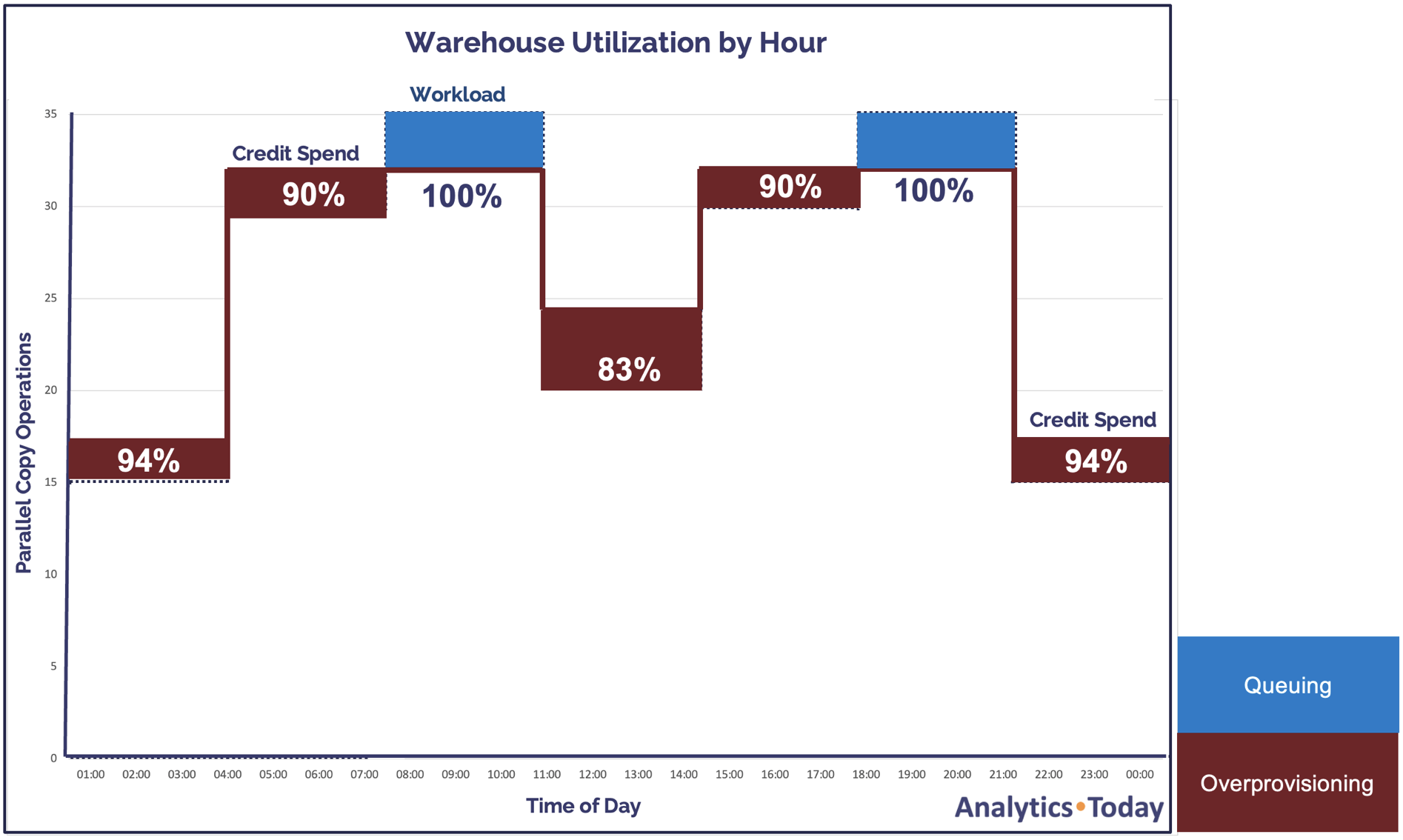
Assuming a repeating daily workload pattern, the fixed size MEDIUM approach would cost 96 credits per day, whereas the multi-cluster approach reduces cost by 28%. Assuming a credit cost of $3.00, this remarkably simple change leads to a potential annual saving of up to $30,000 per year.
Snowflake Training by an Expert.
Click in the image below for more detail

The Impact of File Size on Load Cost
As stated above, Snowflake recommends a file size of between 100-250MB, and it's worth considering why. The diagram below illustrates the impact of file size on load rate and cost. It shows that tiny files (around 100 bytes per file) have a relatively low load rate and high credit cost per file.
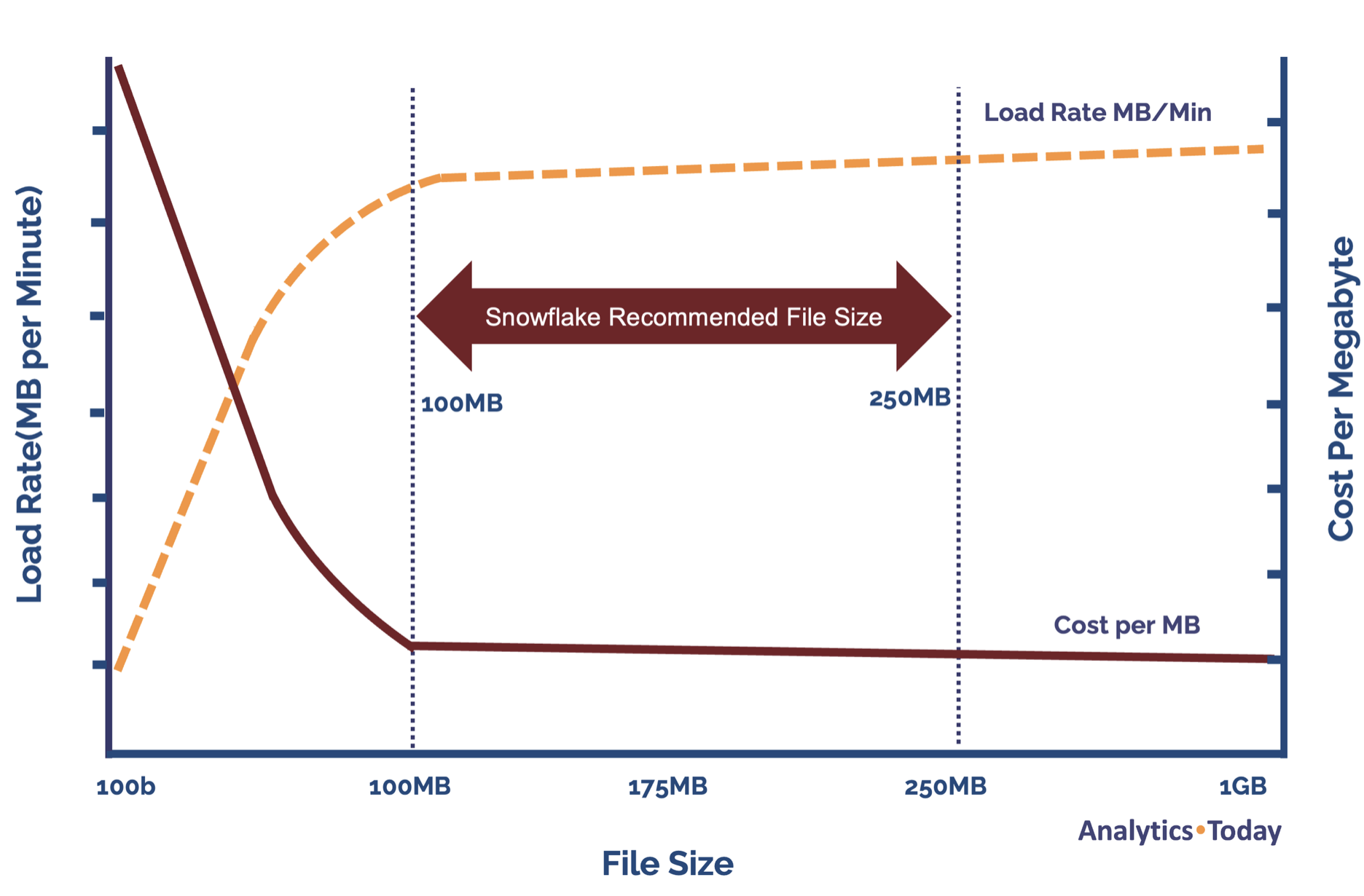
The load rate (measured megabytes per minute) climbs sharply but tends to flatten out at around 100MB but continues to improve gradually. Likewise, the cost per megabyte drops sharply and again flattens out at around 100MB.
This load profile is likely due to the elapsed time of cloud-based file operations. Although relatively fast, each file loaded includes a minor overhead to find the file, check if it has already been loaded and then fetch, process and store the data in Snowflake.
The upper limit of 250MB balances the need to control cost while minimizing the latency.
To illustrate this point, we need only to compare the load times of files sized at 100MB and 5GB in the same XSMALL warehouse. We can expect a single 100MB data file to load in approximately 24 seconds, whereas a 5GB data file will take around 7-8 minutes.
What have we learned so far?
We've covered a lot of ground, and it's worth summarizing the key points:
An XSMALL warehouse consists of a single node with eight CPUs which means it can load up to eight files in parallel. As the T-Shirt size increases, the number of nodes (and therefore CPUs available) doubles each time. However, as the virtual warehouse scales, so does the cost.
Assuming a COPY INTO TABLE command loads only a single file, only one CPU will be active, leading to a potentially low warehouse utilization. However, if multiple COPY operations are executed in parallel, each COPY is run on a separate CPU, which can lead to 100% utilization.
Likewise, a single COPY operation can load multiple files into the same table. In this case, (assuming a warehouse with no other queries running), the files will each be loaded in parallel. However, a COPY operation cannot execute on multiple clusters, only multiple nodes within a cluster. For example, a COPY loading 100 files on an XSMALL warehouse can only run eight loads in parallel, whereas loading on a LARGE warehouse will load up to 64 files in parallel with approximately eight times the throughput.
Assuming the project executes multiple loads throughout the day, we'd expect the workload to vary over time. Therefore, deploying a fixed-size warehouse (for example, a MEDIUM size) leads to poor utilization. It's also fair to assume the bigger the warehouse, the greater the potential risk of under-utilization.
However, using the Snowflake multi-cluster warehouse facility, we can deploy a single XSMALL warehouse to automatically scale out as additional COPY commands are executed. Provided each COPY is started in a new session, this process should be highly efficient as clusters are automatically scaled back when no longer needed.
Snowflake, however, recommends file sizes of between 100-250MB to balance throughput and cost requirements. While loading 5GB data files on an XSMALL warehouse may be more cost-effective, Snowflake recommends splitting large files into chunks of up to 250MB. Therefore, as a single COPY command loads multiple files in parallel, it opens the option of scaling up the warehouse to provide more CPUs, improving throughput and delivering results faster.
Aside from the challenge of understanding all the above points, we can expect to load thousands of tables per hour in varying sizes. However cost-efficient it may be, it's seldom worth the effort to design an efficient load mechanism for each case.
We need a strategy that takes account of the above constraints but provides a straightforward solution that can be easily understood, quickly deployed, and easily monitored.
There is, however, one final insight we need to understand, the typical data load size.
Average Table Load Size
The diagram below illustrates the result of an analysis of ~10,000 loads per day on a Snowflake system.
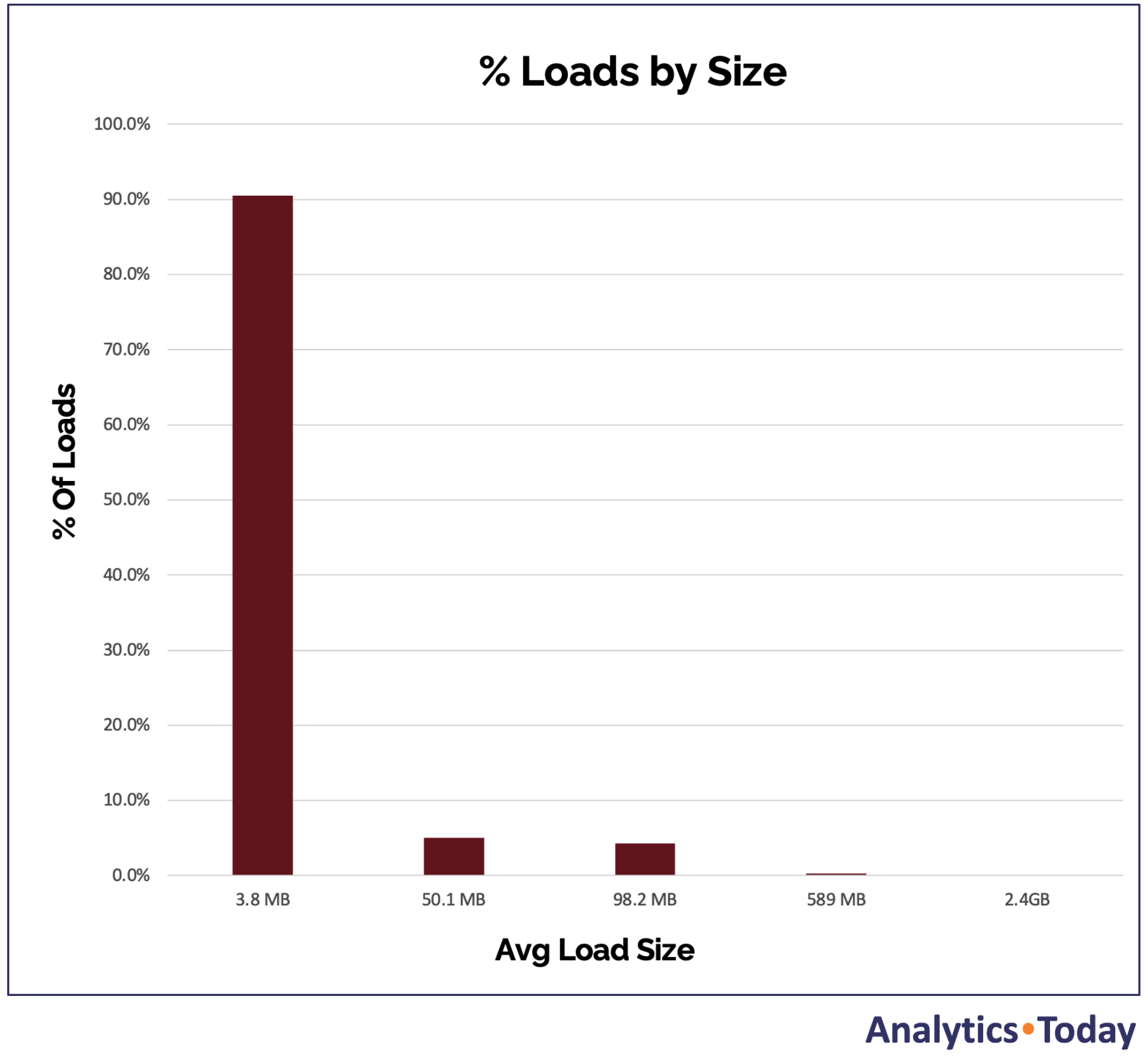
The above graph shows that most data loads are under 100MB and will not benefit from scaling up above an XSMALL warehouse. The loads were grouped by size, and 90% of loads averaged ~4MB with an elapsed time of under 30 seconds.
Around 9% of loads took between one and five minutes, and less than 1% took more than five minutes to complete, with the worst-case load operations completed in under an hour – although this indicates a potential opportunity for improvement.
The above graph means that around 95% of loads should be executed on an XSMALL warehouse configured to scale out automatically. If some COPY operations load more than eight files to a single table, the size could be increased to a SMALL warehouse to reduce queuing while remaining cost-efficient.
The 5% of large loads could be loaded using an XSMALL or SMALL warehouse, provided the latency is acceptable. However, very large loads, including multiple files that need faster throughput, should be loaded on a separate MEDIUM or LARGE size warehouse depending upon the number of files.
Parallel COPY Data Loading
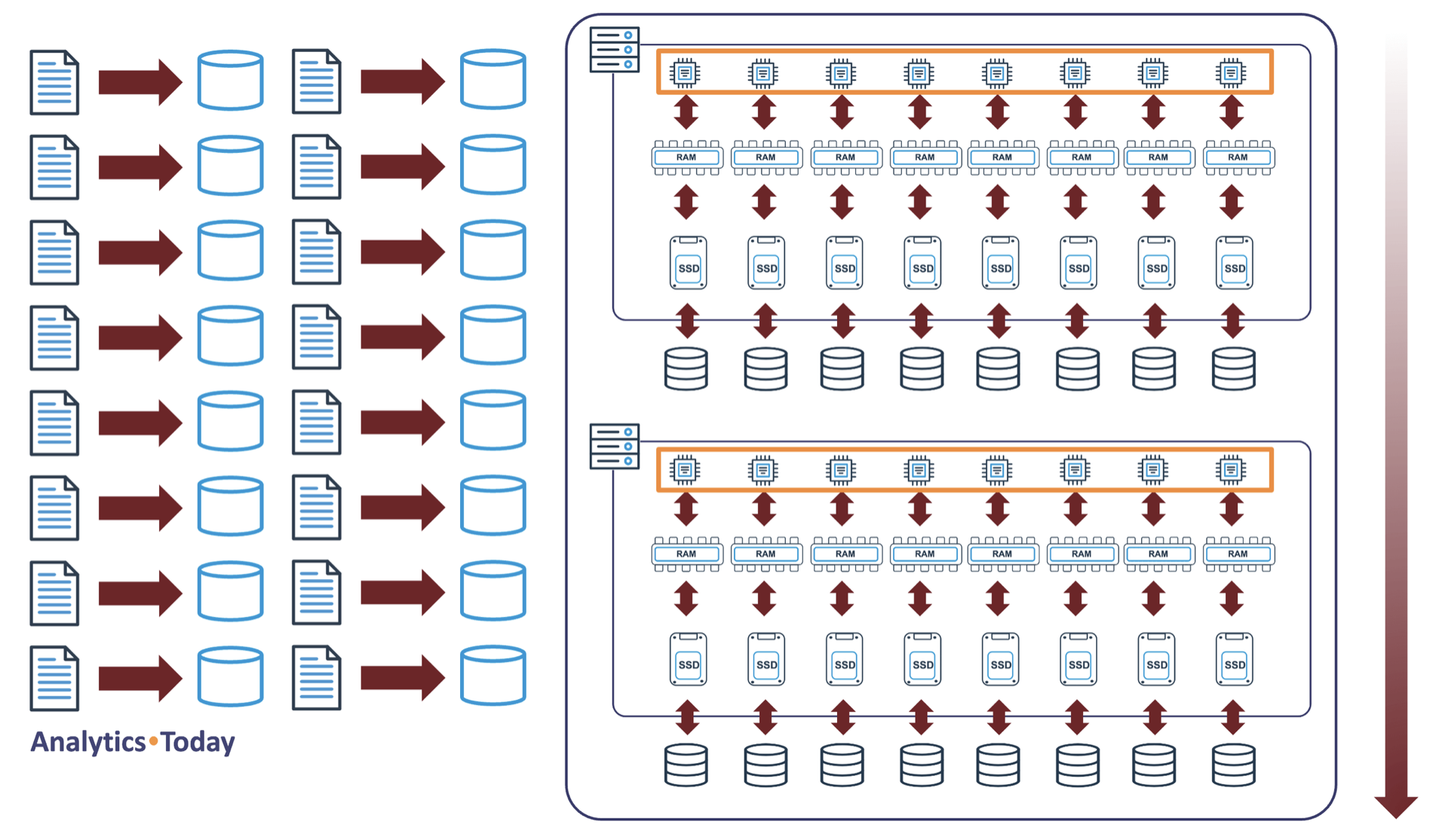
The diagram below illustrates the situation where the XSMALL warehouse is fully utilized and processing eight COPY operations in parallel.
In the above diagram, as each COPY operation is executed in a new session (perhaps initiated by DBT or Airflow), each load runs in parallel on a separate CPU.
When more than eight COPY operations are executed, Snowflake queues the requests until one of the existing loads has finished and resources are available. However, an additional same-size cluster will automatically be started if the warehouse is configured to use the multi-cluster feature.
Conclusion
The diagram below illustrates the Snowflake data loading best practice for cost-effective bulk loading. This approach involves the deployment of two virtual warehouses, an XSMALL warehouse for standard-size loads and a larger (in this case, a MEDIUM) sized warehouse for larger loads in which the files have been broken into chunks of between 100-250MB.
The XSMALL size warehouse is used for 80-90% of data loads and configured to scale out using the multi-cluster feature. This virtual warehouse typically loads single data files up to 250MB, although there's no set upper limit. This approach prioritizes cost over throughput or latency.
The MEDIUM-sized warehouse should also be configured for multi-cluster and can accept multiple parallel COPY INTO TABLE operations. However, this warehouse is sized for exceptionally large high volume, low latency loads. Each COPY operation on a MEDIUM-size virtual warehouse can load up to 32 files in parallel.
Using this method, every COPY operation on the entire Snowflake account uses one of the two available warehouses, which has the advantage of a simple warehouse deployment strategy which is easy to monitor and tune and automatically balances the competing requirements.
Data Loading Priorities – Revisited
I introduced the conflicting data loading priorities at the beginning of this article. We can now adjust the diagram to include the effect of concurrency.
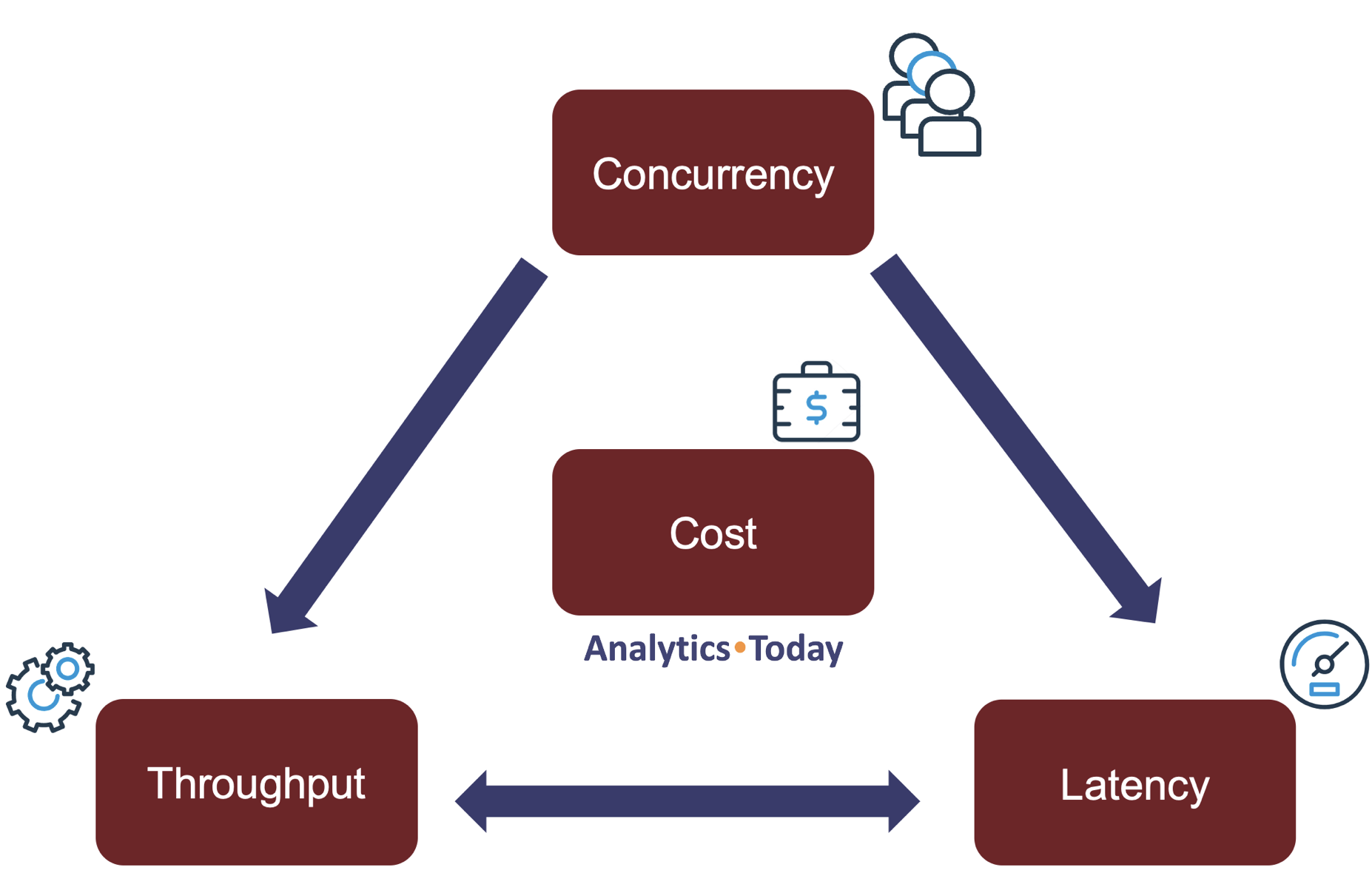
The above diagram illustrates the underlying challenges when ingesting data into any database. We must balance the conflicting need to maximize throughput while minimizing latency and managing cost.
On Snowflake, the multi-cluster feature can be combined with dual virtual warehouses to automatically balance both these priorities while cost is automatically managed as the workload varies.
Snowflake Training from an Expert
We now provide:
Click on the image below for more information.

Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, he joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment. Certifications include Snowflake Data Superhero, Snowflake Subject Matter Expert, SnowPro Core, and SnowPro Advanced Architect.