Improve Snowflake Query Speed by Preventing Spilling to Storage
 John Ryan
John Ryan
This article will demonstrate how a simple Snowflake virtual warehouse change can lead to queries running over a hundred times faster and 40% cheaper. Plot spoiler - it involves spilling to storage.
We will explain what causes spilling to storage, and explain how increasing the virtual warehouse size can improve query performance without impacting cost. We will understand the impact of spilling to REMOTE storage and summarize the best practices to reduce spilling.
What is Spilling to Storage?
The diagram below illustrates the internals of a Snowflake X-Small Virtual Warehouse, which includes eight CPUs, memory, fast SSD local storage and remote cloud storage.
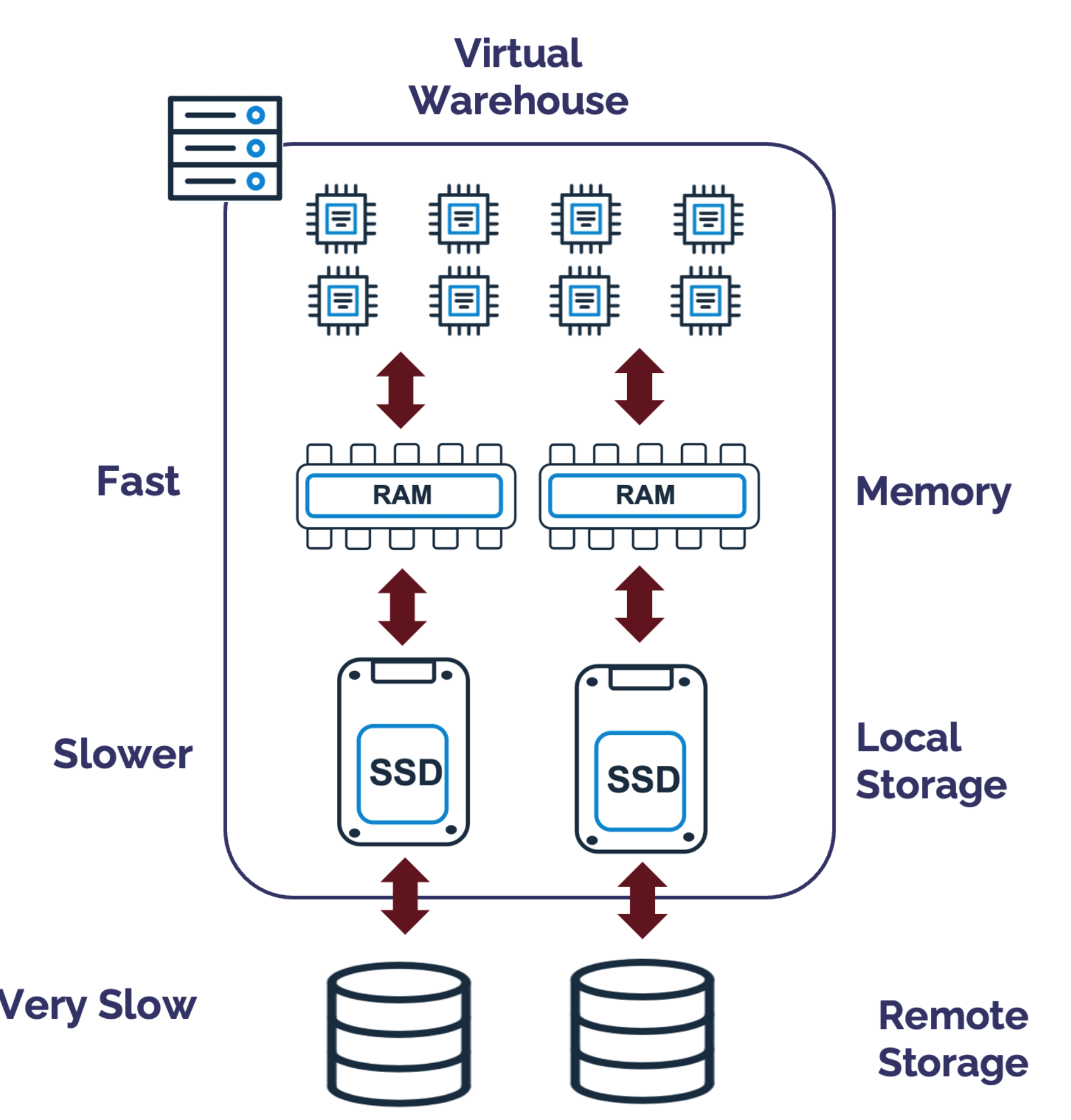
Spilling occurs when Snowflake needs to sort data, which tends to happen when executing an ORDER BY, using Snowflake Window Functions or (more often), because of a GROUP BY operation.
Performance degrades drastically when a warehouse runs out of memory while executing a query because memory bytes must “spill” onto local disk storage.
Initially, Snowflake attempts to complete the sort operation in memory, but once that's exhausted, data is temporarily spilled to local storage. For huge sorts, or sort operations on warehouses too small for the job, even the local SSD can be used up, in which case data will be spilled to remote cloud storage.
The key point is main memory access is much faster than SSD, which is considerably faster than cloud storage. To put this in context, if a single CPU cycle took one second, access to main memory would take around 6 minutes, access to SSD around three days and access to cloud storage up to a year.
Spilling to storage can have a significant impact on query performance.
Benchmarking Spilling to Local Storage
To demonstrate the impact of spilling, I executed the same query against a range of virtual warehouse sizes from X-Small to X4-Large and recorded the results. The query below fetches and sorts over 288 billion rows, sorting around a terabyte of data.
select ss_sales_price
from snowflake_sample_data.tpcds_sf100tcl.store_sales
order by ss_sales_price;
The table below shows the improvement in execution time as we increased the warehouse size. It shows a speed improvement of over 140 times from 7.5 hours to just three minutes while the cost remained around the $20 level.
| Warehouse Size | Execution Time & Difference | Query Cost | Local Spilling |
| XSMALL | 7h 38m (n/a) | $19.09 | 253 GB |
| SMALL | 3h 55m (97% faster) | $19.61 | 260 GB |
| MEDIUM | 2h 3m (95% faster) | $20.63 | 261 GB |
| LARGE | 56m (109% faster) | $18.86 | 195 GB |
| XLARGE | 29m (97% faster) | $19.47 | 197 GB |
| X2LARGE | 13m (106% faster) | $18.42 | 198 GB |
| X3LARGE | 7m (97% faster) | $19.07 | 134 GB |
| X4LARGE | 3m (93% faster) | $20.53 | 136 GB |
The graph below illustrates the reduction in execution time as the warehouse size is increased. It again demonstrates run time is reduced by around 50% each time.
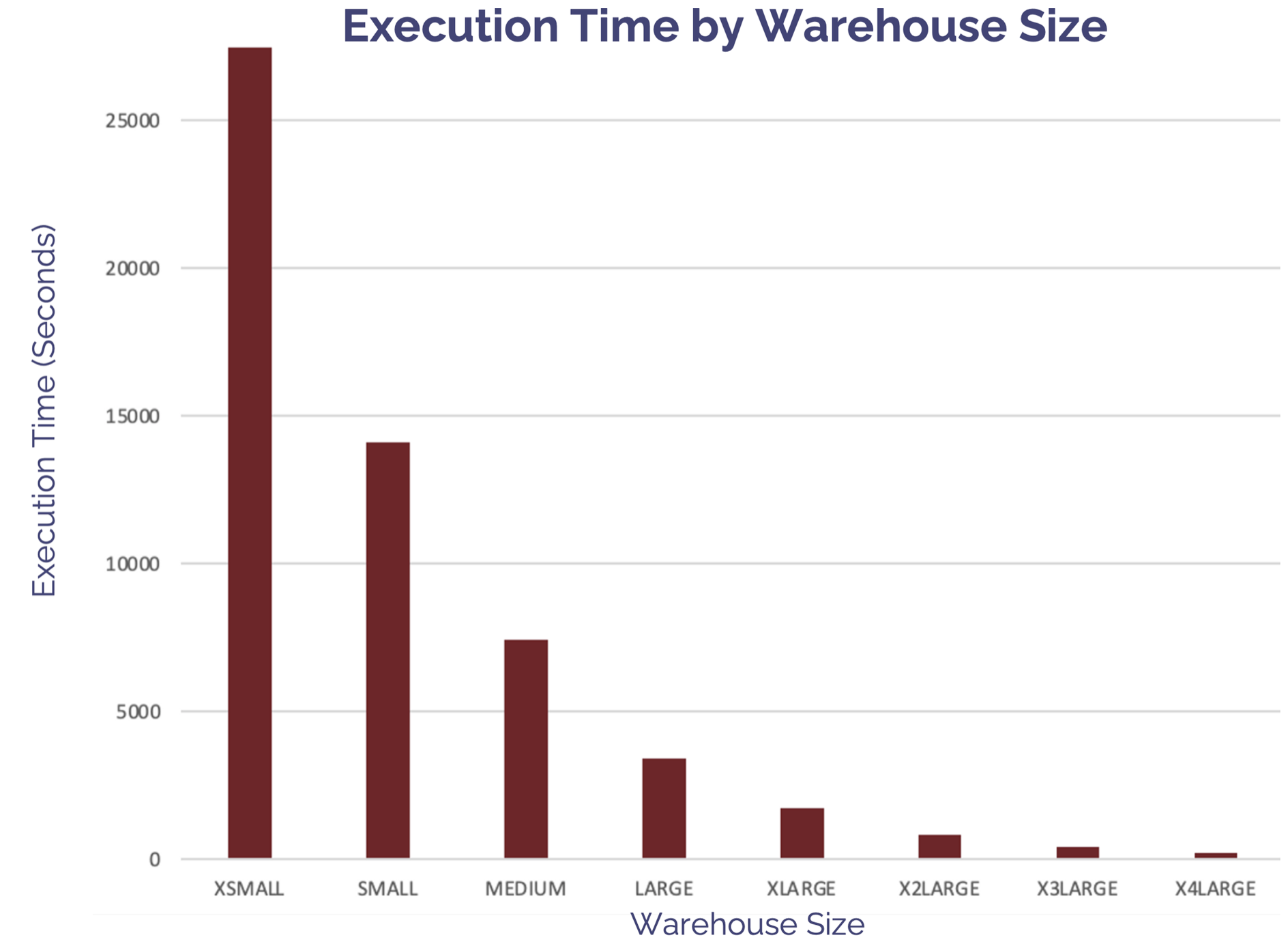
This is consistent with previous tests on a Snowflake Virtual Warehouse which show that, provided the query is large enough, increasing the warehouse size produces the same results twice as fast for the same cost.
 ](https://analytics-today.notion.site/20e8a7c79dbb8089be7be96e292dd2d1?pvs=105)
](https://analytics-today.notion.site/20e8a7c79dbb8089be7be96e292dd2d1?pvs=105)
Benchmarking Spilling to Remote Storage
As described above, spilling to remote storage is even slower but often needs a monster query on a smaller warehouse to reproduce.
The SQL statement below was executed on varying warehouse sizes and the results recorded.
SELECT ss_sales_price
From snowflake_sample_data.tpcds_af100tcl.store_sales
order by SS_SOLD_DATE_SK, SS_SOLD_TIME_SK, SS_ITEM_SK, SS_CUSTOMER_SK,
SS_CDEMO_SK, SS_HDEMO_SK, SS_ADDR_SK, SS_STORE_SK, SS_PROMO_SK, SS_TICKET_NUMBER, SS_QUANTITY;
The table below shows the results of running the above query, which sorts ten terabytes of data on varying warehouse sizes. It shows the query running over a hundred times faster on an X4LARGE while the query cost fell from over $150 to $95, a 40% reduction in cost while the query performance was over a hundred times faster.
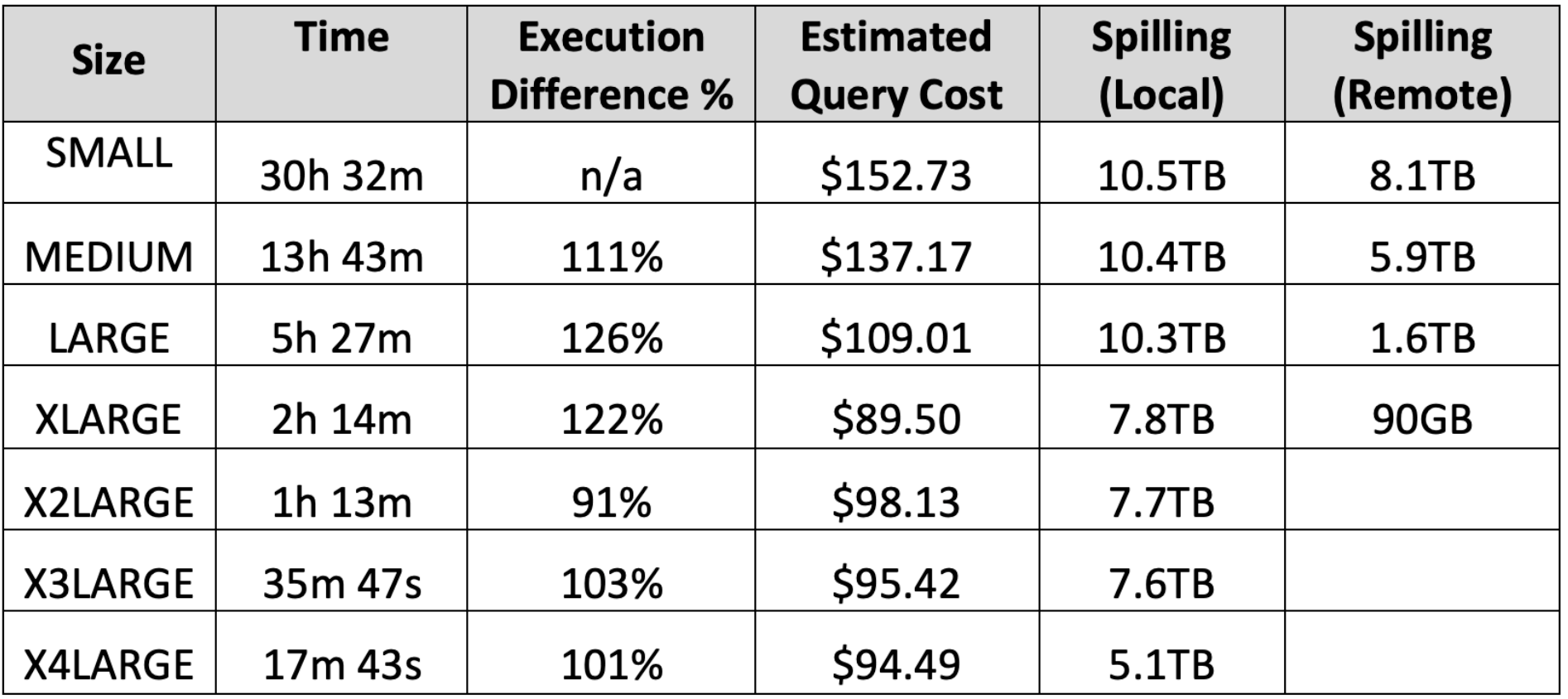
One interesting point worth noting, is that when the execution difference is greater than 100%, this indicates the query cost is cheaper at each step as the charge rate is doubled each time, but the query runs more than twice as fast.
Clearly spilling to remote storage adds to both run time and cost as the query cost levels out after an X2LARGE as remote spilling is eliminated.
Best Practices to Reduce Snowflake Spilling
The best practice approach to reduce Snowflake Spilling include:
Reduce the volume of data sorted.
Move the query (or more likely the batch job) to a larger warehouse
Increase the warehouse size.
My article on tuning Snowflake query performance includes several techniques to reduce the data fetched, which will in turn, reduce the volume of data sorted and help eliminate spilling to storage.
While many system administrators tend to increase the virtual warehouse size, this is often a bad mistake. Remember, any given warehouse will most likely execute a range of SQL including short running queries which won't benefit from a bigger warehouse.
It's a much better practice to identify the queries causing spilling and move them to a larger warehouse. This will improve query performance without increasing the overall cost of the warehouse.
One of the easiest ways of improving query performance and avoiding spilling is to include a LIMIT clause in the query. To demonstrate this, the following query was executed without and then with a LIMIT clause, which returned the top 10 entries or all entries.
select *
from store_returns
order by sr_reason_sk
limit 10;
The screenshot below shows that including a LIMIT improved query performance by over 60 times from over two hours to under two minutes.
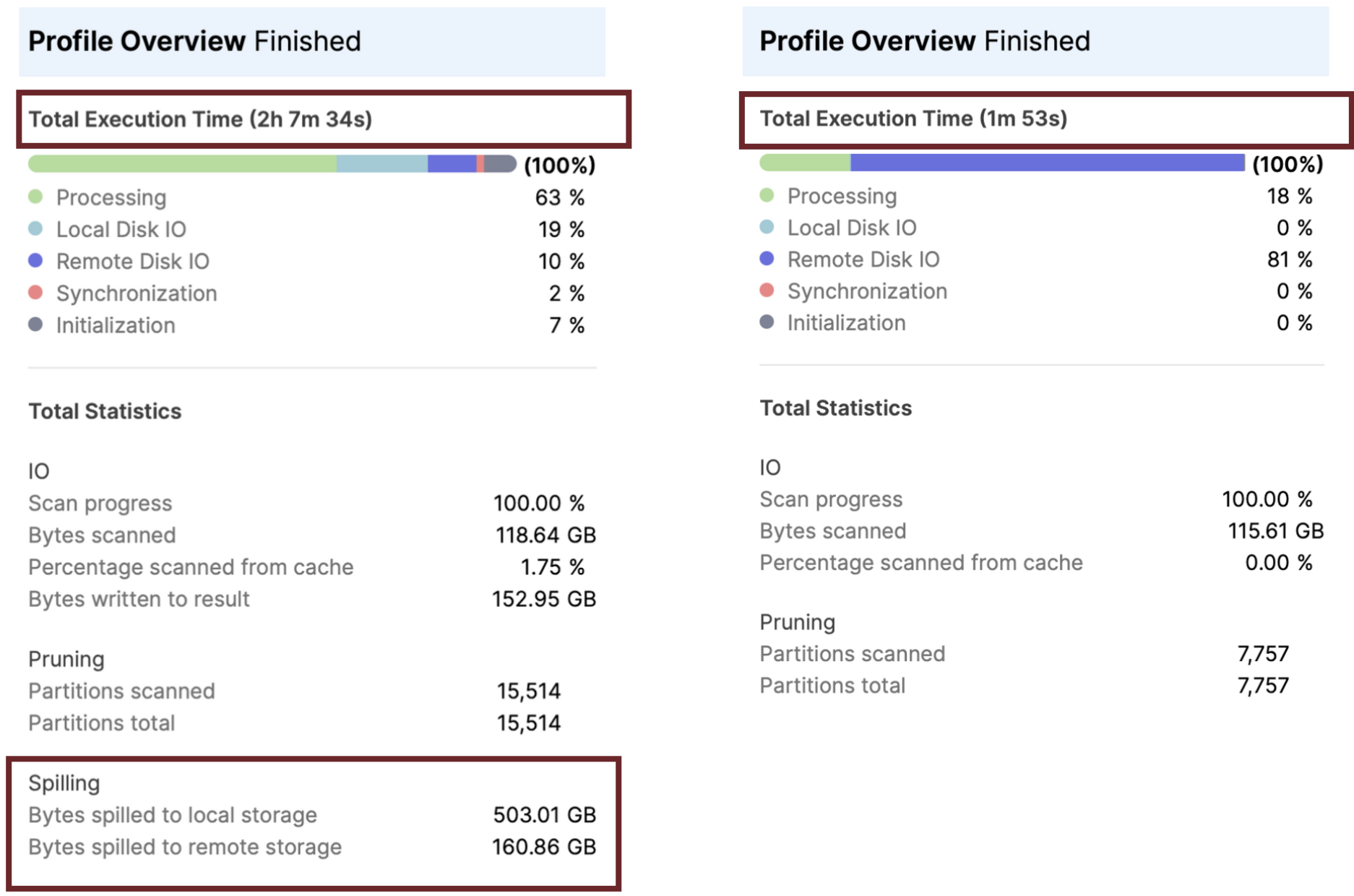
It's worth noting that the LIMIT clause was pushed down into the query, halved the partitions scanned, and eliminated both local and remote spilling. Finally, both queries were executed on an X-Small warehouse, demonstrating the potential cost saving of this simple change
How to identify Spilling to Storage?
The query below will quickly identify each warehouse size and extent of spilling to storage. As this is based upon query-level statistics, it is possible to drill down to identify specific SQL.
select warehouse_name
, warehouse_size
, count(*) as queries
, round(avg(total_elapsed_time)/1000/60,1) as avg_elapsed_mins
, round(avg(execution_time)/1000/60,1) as avg_exe_mins
, count(iff(bytes_spilled_to_local_storage/1024/1024/1024 > 1,1,null)) as spilled_queries
, round(avg(bytes_spilled_to_local_storage/1024/1024/1024)) as avg_local_gb
, round(avg(bytes_spilled_to_remote_storage/1024/1024/1024)) as avg_remote_gb
from query_history
where true
and warehouse_size is not null
and datediff(days, end_time, current_timestamp()) <= 7
and bytes_spilled_to_local_storage > 1024 * 1024 * 1024
group by all
order by 7 desc
limit 10;
The screenshot below shows the output of the query. It shows the top 10 warehouses resulting in spilling to storage in the past 7 days. The worst offender on average spilled nearly 3TB to local storage on an X2LARGE warehouse, with an average execution time of around 40 minutes.
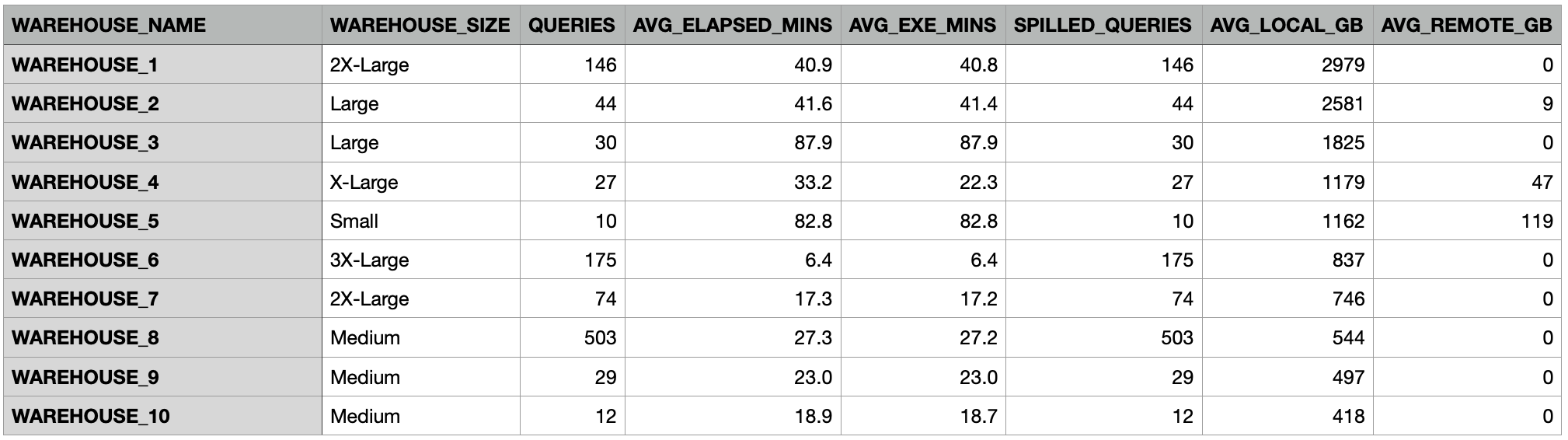
Warehouse 5 illustrates another insight into spilling as this SMALL warehouse spilled an average of 1.1TB to local storage and 119GB to remote storage.
It is however, worth noting that it's almost impossible to completely eliminate spilling to storage, and you should largely ignore any queries that spill less than a gigabyte of data to LOCAL storage.
Also keep in mind, that queries sometimes spill to storage as a result of too many large queries being executed concurrently, although this tends to lead to relatively lower levels of spilling which can be largely ignored.
Conclusion
Clearly on Snowflake, spilling to local storage can have a significant impact upon query performance and any query that spills more than a gigabyte of storage is a candidate to run on a larger warehouse. Typically, if a query includes significant spilling to storage is will execute twice as fast for the same cost on the next size virtual warehouse.
You should however, avoid the temptation to simply increase the warehouse size. In my experience, while this may improve query performance for the largest queries causing the spilling to storage, it likewise increases the overall cost of the warehouse.
Spilling to remote storage impacts both performance and cost as Snowflake charges per second for virtual warehouse utilization and spilling to remote storage extends the query elapsed time. Eliminating remote storage therefore leads to a reduced cost when the query is executed on a larger warehouse. While this may seem a paradox, the results shown here are consistent with my personal experience.
Be aware however, that spilling to local storage is only important when it exceeds the gigabyte level, although remote spilling should always be avoided

.
Subscribe to my newsletter
Read articles from John Ryan directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
John Ryan
John Ryan
After 30 years of experience building multi-terabyte data warehouse systems, I spent five years at Snowflake as a Senior Solution Architect, helping customers across Europe and the Middle East deliver lightning-fast insights from their data. In 2023, he joined Altimate.AI, which uses generative artificial intelligence to provide Snowflake performance and cost optimization insights and maximize customer return on investment. Certifications include Snowflake Data Superhero, Snowflake Subject Matter Expert, SnowPro Core, and SnowPro Advanced Architect.