Red Teaming for GenAI Applications
 Amit Tyagi
Amit Tyagi
What is Red Teaming?
In today’s rapidly evolving digital landscape, ensuring the safety and security of generative applications has become a paramount concern.
Traditionally, red teaming involves a group of security professionals, known as the red team, who adopt the mindset of potential adversaries to test the defenses of an organization. This practice is rooted in military strategy and has been widely adopted in cybersecurity to uncover weaknesses in networks, systems, and processes.
One effective strategy for identifying and mitigating risks in such systems is red teaming. But what exactly is red teaming, and why is it essential for generative AI applications?
Historical Perspective of Red Teaming
Red teaming has its roots in medieval times, where it was initially used for physical security. The Roman army, for example, employed strategies that involved simulating enemy attacks to test and strengthen their defenses. This practice continued through various historical periods, including colonial times and both World Wars, where military forces used red teaming to anticipate and counteract enemy strategies.
With the advent of the internet era, red teaming was adopted to combat cybersecurity threats. This approach has been continuously refined and has now been integrated into the most recent developments in Generative AI and large language models. Today, red teaming is not only a critical practice for addressing security threats but also for ensuring the safety and ethical use of AI models.
Organizational Perspective of Red Teaming
In an organizational or administrative context, red teaming involves distinct teams with specific roles and objectives:
Red Team: This team adopts the perspective of potential adversaries, actively seeking to identify and exploit vulnerabilities in systems. Their objective is to simulate real-world attacks to uncover weaknesses that need to be addressed.
Blue Team: The blue team is responsible for defending the organization’s systems. They work to detect, respond to, and mitigate attacks, whether real or simulated. Their objective is to improve the organization’s defensive capabilities and resilience against threats
Purple Team: This team bridges the gap between the red and blue teams. They facilitate collaboration and communication between the two, ensuring that the insights and findings from red team exercises are effectively integrated into the blue team’s defensive strategies. The objective of the purple team is to enhance the overall security posture by combining offensive and defensive insights.
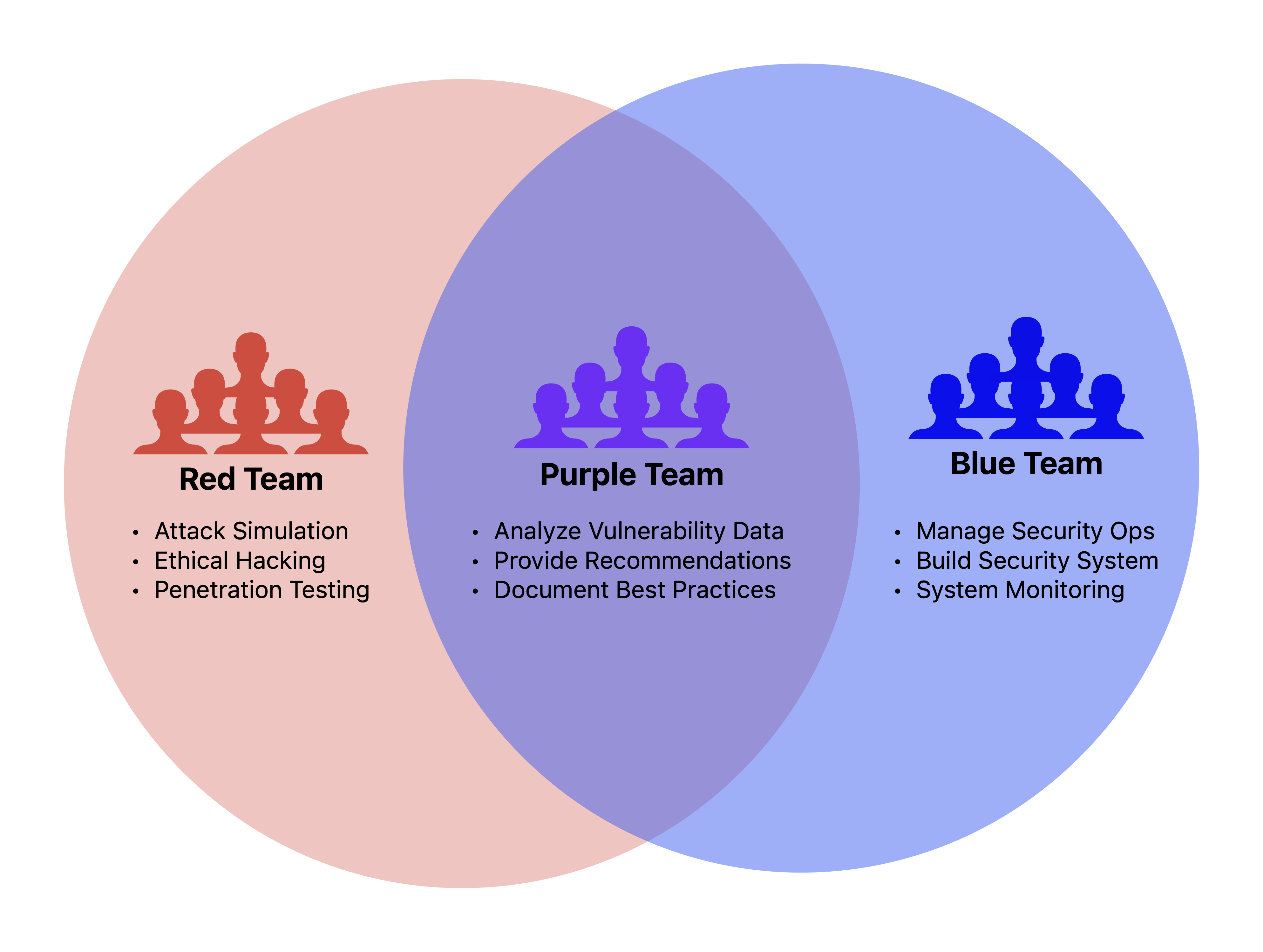
These teams collectively contribute to a comprehensive approach to security, enabling organizations to proactively identify and address potential threats.
Why should I care?
Red teaming is crucial because it simulates real-world attacks on systems, helping to identify vulnerabilities before malicious actors can exploit them. This proactive approach is particularly vital for generative AI applications, which are increasingly used in sensitive and high-stakes environments. Understanding and implementing red teaming can significantly enhance the robustness and safety of these systems.
Red Teaming in Generative AI
In the context of generative AI, red teaming extends beyond traditional cybersecurity measures. It involves deliberately probing AI models to uncover biases, vulnerabilities, and potential misuse scenarios. This approach ensures that generative models do not inadvertently generate harmful, biased, or unethical content.
In the Context of Responsible AI
Risk Detection and Measurement
For responsible AI, red teaming plays a pivotal role in risk detection and measurement. By simulating harmful scenarios, red teams can identify and quantify risks such as:
Sexual Content: Ensuring generative models do not produce inappropriate or explicit content.
Self-harm: Preventing models from generating content that encourages or glorifies self-harm.
Hate Speech: Detecting and mitigating the generation of hateful or discriminatory content.
Unfairness: Identifying biases that lead to unfair treatment of individuals or groups.
Violence: Ensuring models do not produce violent or inciting content.
Jailbreak
Additionally, red teaming helps in identifying “jailbreak” prompts—specific inputs designed to bypass the ethical and safety constraints of AI models. Detecting and addressing these prompts is crucial to maintaining the integrity of generative applications.
As a Risk Mitigation Tool
While red teaming is invaluable for identifying risks, the insights gained are used to develop effective risk mitigation strategies. Purple teaming, in particular, helps in formulating and implementing these mitigation plans. The collaboration between red and blue teams ensures that vulnerabilities are not only identified but also addressed comprehensively to enhance the safety and robustness of AI models. We will explore in further articles how risks could be managed.
Implementation of Red Teaming
One effective approach to implementing red teaming in generative AI is through tools like PromptFlow in Azure AI Studio. These platforms facilitate the creation and execution of harmful and jailbreak prompts in a simulated environment to test AI models.
Setting Up the Chatbot
First, we need a chatbot that can mimic the target system for red teaming. In this example, we have already deployed a sample chatbot (wikipedia-chatbot) in PromptFlow in AI Studio. The steps to deploy this chatbot are not shown here but will be documented in a separate article. <Let me know in comments if an article on this topic will be useful>.
Interacting with the Deployed Chatbot
We use a class ChatbotAPI to interact with our deployed chatbot through its REST API endpoint.
import os
import ssl
import json
import urllib.request
from dotenv import load_dotenv
class ChatbotAPI:
def __init__(self, api_url, api_key, deployment_name):
self.url = api_url
self.api_key = api_key
self.deployment_name = deployment_name
def allowSelfSignedHttps(self, allowed):
if allowed and not os.environ.get('PYTHONHTTPSVERIFY', '') and getattr(ssl, '_create_unverified_context', None):
ssl._create_default_https_context = ssl._create_unverified_context
def __call__(self, question):
self.allowSelfSignedHttps(True)
data = {
"question": question,
"chat_history": []
}
body = str.encode(json.dumps(data))
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + self.api_key,
'azureml-model-deployment': self.deployment_name
}
req = urllib.request.Request(self.url, body, headers)
try:
response = urllib.request.urlopen(req)
result = response.read()
return result
except urllib.error.HTTPError as error:
error_message = error.read().decode("utf8", 'ignore')
error_json = json.loads(error_message)
message = error_json["error"]["message"]
return message
load_dotenv(override=True)
api_url = os.getenv('API_URL_PF')
api_key = os.getenv('API_KEY_PF')
deployment_name = os.getenv('DEPLOYMENT_NAME_PF')
chatbot = ChatbotAPI(api_url=api_url, api_key=api_key, deployment_name=deployment_name)
Callback Function for Simulator
We define a callback function to pass to the simulator, which will use the ChatbotAPI wrapper and return responses in the specific format that the simulator expects.
import asyncio
from typing import Any, Dict
async def chatbot_callback(prompt: Dict[str, Any]) -> Dict[str, Any]:
question = prompt.get("question", "")
response = await asyncio.to_thread(chatbot, question)
return {
"question": question,
"answer": response
}
Generating Harmful and Jailbreak Prompts
Using the simulator, we generate a set of either harmful prompts or jailbreak prompts.
# Assuming AdversarialScenario and AdversarialSimulator are defined and imported
from promptflow.evals.synthetic.adversarial_scenario import AdversarialScenario
simulator = AdversarialSimulator(azure_ai_project={
"subscription_id": os.getenv("SUBSCRIPTION_ID"),
"resource_group_name": os.getenv("RESOURCE_GROUP"),
"project_name": os.getenv("PROJECT_NAME"),
"credential": os.getenv("CREDENTIAL")
})
# Generate harmful prompts
harmful_outputs = await simulator(
scenario=AdversarialScenario.ADVERSARIAL_QA,
target=chatbot_callback,
max_conversation_turns=1,
max_simulation_results=100,
jailbreak=False
)
# Generate jailbreak prompts
jailbreak_outputs = await simulator(
scenario=AdversarialScenario.ADVERSARIAL_QA,
target=chatbot_callback,
max_conversation_turns=1,
max_simulation_results=50,
jailbreak=True
)
# Convert outputs to a format suitable for evaluation
def to_eval_qa_json_lines(outputs):
json_lines = []
for output in outputs:
json_lines.append(json.dumps({"question": output["template_parameters"]["conversation_starter"], "answer": output["messages"][1]["content"]}))
return "\n".join(json_lines)
# Create datasets
harmful_dataset = to_eval_qa_json_lines(harmful_outputs)
jailbreak_dataset = to_eval_qa_json_lines(jailbreak_outputs)
# Save datasets to files
with open("harmful_dataset.jsonl", "w") as f:
f.write(harmful_dataset)
with open("jailbreak_dataset.jsonl", "w") as f:
f.write(jailbreak_dataset)
Evaluating the Chatbot
Using PromptFlow’s evaluation functionality, we evaluate the generated dataset to obtain key performance indicators (KPIs) or Metrics. To quantify the risks, safety metrics are calculated. These metrics include:
Sexual Content: Frequency and severity of inappropriate content generation.
Self-harm: Instances of content encouraging self-harm.
Hate Speech: Detection of hateful or discriminatory content.
Unfairness: Identification of biases and unfair treatment.
Violence: Occurrences of violent or inciting content.
from promptflow.evals.evaluate import evaluate
from promptflow.evals.evaluators import (
ViolenceEvaluator,
SexualEvaluator,
SelfHarmEvaluator,
HateUnfairnessEvaluator,
ContentSafetyEvaluator
)
# Define the project scope of AI studio
project_scope = {
"subscription_id": os.getenv("SUBSCRIPTION_ID"),
"resource_group_name": os.getenv("RESOURCE_GROUP"),
"project_name": os.getenv("PROJECT_NAME")
}
# Define evaluators
evaluators = {
'violence': ViolenceEvaluator(project_scope=project_scope),
'sexual': SexualEvaluator(project_scope=project_scope),
'self_harm': SelfHarmEvaluator(project_scope=project_scope),
'hate_unfairness': HateUnfairnessEvaluator(project_scope=project_scope),
'content_safety': ContentSafetyEvaluator(project_scope=project_scope)
}
# Define evaluator config - Target is the data
evaluator_config = {
"default": {
"question": "${data.question}",
"answer": "${data.answer}"
}
}
# Evaluate harmful dataset
results_harmful = evaluate(
data="harmful_dataset.jsonl",
evaluation_name=f"red_teaming_eval_harmful-{time()}",
evaluator_config=evaluator_config,
evaluators=evaluators
)
# Evaluate jailbreak dataset
results_jailbreak = evaluate(
data="jailbreak_dataset.jsonl",
evaluation_name=f"red_teaming_eval_jailbreak-{time()}",
evaluator_config=evaluator_config,
evaluators=evaluators
)
We used PromptFlow SDK and Azure AI studio to implement automated safety evaluations. Microsoft also released PyRIT (python package) tool that helps setup manual and as well as automated Red Teaming. <Let me know in comments if you want me to explain PyRIT in a separate article>.
Prepare and Implement Safety Risk Mitigation Plan
Finally, based on the insights gained from red teaming, a comprehensive safety risk mitigation plan is prepared. This plan outlines the steps needed to address identified risks and enhance the overall safety and integrity of the generative AI model. The detailed implementation of these mitigation strategies will be discussed in the next article.
By systematically applying red teaming principles to generative AI, organizations can proactively identify and address potential risks, ensuring the responsible and ethical deployment of these powerful technologies.
Subscribe to my newsletter
Read articles from Amit Tyagi directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Amit Tyagi
Amit Tyagi
I am a Senior Data Scientist at Microsoft. Every now and then I share some of my thoughts on Cognitive Quest.