How to use Kubernetes Horizontal Pod Autoscaler
 Bala
Bala
What is Autoscaling and Why it is important?
Autoscaling means dynamically allocating cluster resources such as CPU and memory to your application based on real time demand. This ensures that your application is having the right amount of resources to handle different levels of load which directly improves application performance and availability.
In kubernetes, you have three main types of Autoscaler to choose from:
Horizontal Pod Autoscaler (HPA)
Vertical Pod Autoscaler (VPA)
Kubernetes Event Driven Autoscaler (KEDA)
In this guide we will discuss about Horizontal Pod Autoscaler (HPA)
Horizontal Pod Autoscaler (HPA)
HPA is a kubernetes feature that automatically scales the number of Pod replicas in a Deployment, ReplicaSet, or StatefulSet based on certain metrics like CPU utilization or custom metrics. Horizontal scaling is the most basic autoscaling pattern in kubernetes.
HPA sets two parameters, 1) Target Utilization level and 2) Minimum and Maximum number of replicas allowed. When the utilization of a Pod exceeds the target, HPA will automatically scale up the number of replicas to handle the increased load. Similarly when the usage drops, HPA will scale down the number of replicas to conserve resources.
When to use HPA ?
Scalability based on workload: HPA is ideal when you want to scale the number of replicas up or down based on the workload or incoming traffic.
Resource utilization scaling: HPA is useful for scenarios where you want to ensure CPU or memory utilization pods remains within a certain threshold.
Example: How to set up a new kubernetes HPA
Pre-requisites:
Kubectl
metrics-server
Steps:
- Create the manifest files
apiVersion: apps/v1
kind: Deployment
metadata:
name: demo
spec:
selector:
matchLabels:
app: demo
template:
metadata:
labels:
app: demo
spec:
containers:
- name: demo
image: registry.k8s.io/hpa-example:latest
ports:
- containerPort: 80
resources:
requests:
cpu: 500m
---
apiVersion: v1
kind: Service
metadata:
name: demo
spec:
ports:
- port: 80
selector:
app: demo
Save the file, and use kubectl apply command to apply it.
kubectl apply -f app.yaml

- Creating Horizontal Pod Autoscaler
The following manifest file creates the HPA and sets the minimum and maximum number of pods in order to maintain average CPU utilization of 50%
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: demo
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: my-app
minReplicas: 3
maxReplicas: 9
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 50
Here's the breakdown of the components:
apiVersion: autoscaling/v2 - Specifies the API version for the HPA resource.
kind: HorizontalPodAutoscaler - Specifies the kind of resource as its an HPA.
metadata: Name of the HPA
scaleTargetRef: Deployment that the HPA will scale
apiVersion: This is for the deployment version.
kind: The kind of resource it will scale.
name: Name of the deployment
minReplicas: Atleast 3 replicas will be running
maxReplicas: At high demand, it will scale up to a max of 9 replicas.
metrics: Specifies the metrics used for autoscaling.
type: Resource metrics used for autoscaling.
resources: Specifies the resource.
name: Specifies CPU metric will be used.
target: Specifies the target.
type: Indicates the target is set to type utilization.
averageUtilization: Specifies the target utilization should be around 50%.
- Apply the HPA using the below command
kubectl apply -f hpa.yaml
- Now check the HPA status
kubectl get hpa

- Also check the deployment status.
kubectl get deployments

The deployment has scaled upto 3 replicas automatically. This is the same replica count which we mentioned inside the HorizontalPodAutoscaler manifest file.
- Generate load test.
kubectl run -it --rm load-test --image=busybox:1.28 --restart=Never -- /bin/sh -c "while sleep
0.01; do wget -q -O- http://demo; done"
Wait for a minute to see the increased load, you can observe the same using the get hpa command.
kubectl get hpa

This time the CPU is 20% and the load is increasing slowly. Now if you check again after sometime there will be more increase in the load which will significantly increase the number of pods.
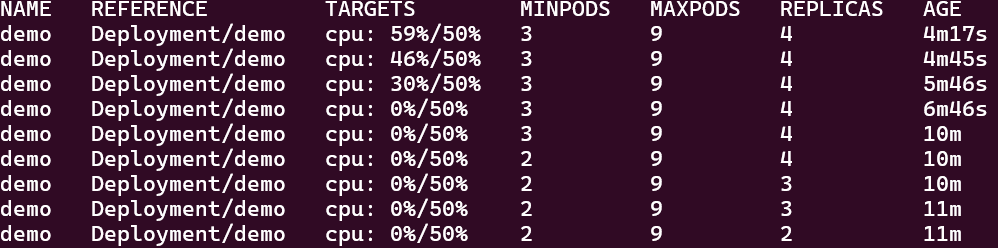
In this series of events, you can see that as the load increases beyond the target utilization, the HPA will try to maintain the limit by increasing the number of pods. The replica count rises to match the resource usage. Later, when the load test is stopped, the HPA scales down the number of pods, which is exactly what we needed.
We've successfully used HPA to automate our application. HPA is powerful mechanism for scaling your application workloads.
Conclusion:
In this blog, we covered the basics of HPA and how to create an HPA using YAML configuration. The HPA reacts to changes in the metrics and adjusts the number of replicas. In the upcoming blogs we will discuss about the remaining types of Autoscaler.
If you found this post useful, give it a like👍
Repost♻️
Follow Bala for more such posts 💯🚀
Subscribe to my newsletter
Read articles from Bala directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by