Container Networking Explained (Part I)
 Ranjan Ojha
Ranjan OjhaTable of contents
If you have worked in the tech field for the last few years chances are you have at least heard of containers. Containers have certainly been crowned as one of the best innovations to be had in the last few years and have taken the web world by the storm. And if you are also like most people, I included, we are mostly content to know that it uses cgroups and namespacing to achieve this separation. Until recently I got super fascinated about networking in general and started to unravel all the layers of onion that built up the container networking stack. And I am here to share some of what I have gathered during my journey of learning about container networking.
Before starting a few points to note. Since this is the very first step in understanding container networking I have chosen to use docker as an example. Much of what Kubernetes does is mostly the same but with a few differences. Going through these differences could be a good next step, which I might possibly explore. Also, since we are only dealing with networks we will only be doing network namespacing. This means that despite running the processes in separate network namespaces they will share the same files. This point will be more relevant a little later. Similarly, a lot of network-related changes we will be doing here are done using ip command. If you don't have this utility, you can get it using iproute2 package in most Linux distributions.
As I said previously, we will be looking closely at Docker's implementation of Container Networking, so here is the link to the official design docs for Docker networking, https://github.com/moby/moby/blob/master/libnetwork/docs/network.md
Note: I am currently running a Fedora vm inside Arch host machine. My Fedora box does not have Docker installed. The reason this is important is because Docker will by default enable some
sysctlsettings. These settings configure how networking is handled by the Kernel so some variations may occur. Please let me know if you run into any issues. Now, with all of that out of the way let's finally get to the fun part.
Setting up "container" network namespace
In our containerless world, a single network namespace itself will represent an actual container in Docker or a pod in Kubernetes. For the users of Kubernetes, this might seem odd since a pod in Kubernetes can have more than containers inside of it. But for them, I would like to remind you that while a pod can have more than 1 container, they all share the same network namespace. This is why the containers inside a pod can communicate with each other using localhost.
Create namespace
We create such a namespace using ip util as,
fedora@localhost:~$ sudo ip netns add container-1
fedora@localhost:~$ ip netns list
NOTE: For those of you running Docker and excited to see the namespaces for your running containers, the above command will not list them out. I know, I did it and was confused until I found that Docker stores their network namespaces under,
/var/docker/netnsdirectory whileiproute2stores it under/var/netnsdirectory.
Running Webserver inside the namespace
Our next step is now to run a process inside this namespace. While we can run any processes inside the namespace, we currently want to run a web service. As that will allow us to test the networking connectivity. For this purpose you may use any web service of your choice, just be sure that they expose an endpoint you can curl to get a response.
I chose to write a very simple, golang web application. I will largely skip over what the application itself does and just put a few relevant bits here.
port := flag.String("p", "8000", "port to listen")
flag.Parse()
type Response struct {
Header http.Header `json:"header"`
Body string `json:"body"`
}
// http.Handle("GET /echo", http.HandlerFunc(GetEchoHandler))
func GetEchoHandler(w http.ResponseWriter, r *http.Request) {
resp := Response{
Header: r.Header,
Body: "Echo response",
}
logger.Info("GET /echo response")
WriteJson(w, resp)
}
I have a command line option to change the port, with the default value set to 8000. And a GET /echo endpoint that just returns a json payload of headers and a message body.
In fact, if you have a python installed in your system you could also just run a Python webserver from the shell without writing a single line of code.
fedora@localhost:~$ python -m http.server # runs by default on port 8000
fedora@localhost:~$ python -m http.server 8080 # change the port number to 8080
For the remaining, I will be using my echo-server but please bear in mind you can just as well substitute with the above Python web server. Get started by running,
fedora@localhost:~$ sudo ip netns exec container-1 ./echo-server
and, you should see your application starting. To verify that we are indeed running the application inside our namespace, you can run,
fedora@localhost:~$ sudo ip netns pid container-1
This should give out the pid of the web server.
Connecting to local namespace
If you are an experimenter, you might have already noticed that you actually cannot currently reach your web server on localhost.
fedora@localhost:~$ sudo ip netns exec container-1 curl localhost:8000/echo
curl: (7) Failed to connect to localhost port 8000 after 0 ms: Couldn't connect to server
The answer to this can be found by running,
fedora@localhost:~$ sudo ip netns exec container-1 ip a
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
Our loopback interface is down. So we start by setting the loopback interface up, then trying to curl again,
fedora@localhost:~$ sudo ip netns exec container-1 ip link set lo up
fedora@localhost:~$ sudo ip netns exec container-1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
fedora@localhost:~$ sudo ip netns exec container-1 curl -s localhost:8000/echo | jq
{
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/8.6.0"
]
},
"body": "Echo response"
}
This time we are met with success.
With this, any number of processes you launch inside the namespace can now reach each other using localhost.
Connecting to Host
We would now like to have the capability to connect to the host namespace itself.
Now if we want to connect 2 physical devices in real life, we might reach out for a Router, a switch, or a lot of other things. Which we will get to in a moment. But in its most basic form, we can simply connect the ethernet ports of our 2 devices with a wire and we can (after some configuration of course) communicate with another device.
Similarly, in our virtual world, we have a Virtual Ethernet Device, veth . Similar to an actual ethernet wire coming with 2 endpoints, our veth network device also comes with a pair. So we can already imagine to connect 2 namespaces, we attach one side of the veth interface in our host default namespace and the other interface in our container-1 namespace. This veth network interface is just one of many other network interfaces we can create and use in a Linux system. You can learn more about other devices we can create in this documentation from RedHat.
Connecting veth pairs
We will touch upon more of these devices later on but for now, let's create a veth pair.
fedora@localhost:~$ sudo ip link add veth1 type veth peer name vethc1
fedora@localhost:~$ sudo ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:a5:e0:0e brd ff:ff:ff:ff:ff:ff
inet 192.168.122.240/24 brd 192.168.122.255 scope global dynamic noprefixroute enp1s0
valid_lft 2547sec preferred_lft 2547sec
inet6 fe80::5054:ff:fea5:e00e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: vethc1@veth1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:15:d3:43:3b:31 brd ff:ff:ff:ff:ff:ff
4: veth1@vethc1: <BROADCAST,MULTICAST,M-DOWN> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 92:b2:24:76:93:41 brd ff:ff:ff:ff:ff:ff
With this, we now have a veth pair. They are currently attached to the default namespace. We now wish to send one of these pairs to our container namespace.
fedora@localhost:~$ sudo ip link set veth1 netns container-1
fedora@localhost:~$ sudo ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:a5:e0:0e brd ff:ff:ff:ff:ff:ff
inet 192.168.122.240/24 brd 192.168.122.255 scope global dynamic noprefixroute enp1s0
valid_lft 2377sec preferred_lft 2377sec
inet6 fe80::5054:ff:fea5:e00e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: vethc1@if4: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 3e:15:d3:43:3b:31 brd ff:ff:ff:ff:ff:ff link-netns container-1
fedora@localhost:~$ sudo ip netns exec container-1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
4: veth1@if3: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN group default qlen 1000
link/ether 92:b2:24:76:93:41 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Allocating IP
Now that we have the two namespaces connected, we are almost ready to communicate between the 2 namespaces. We currently don't have any IP assigned to our namespaces, and if you know about TCP/IP. IP is the address we use to identify devices.
I am going to use, 172.18.0.0/24 as my CIDR range. If you have any experience of installing Kubernetes this is what the Pod IP CIDR range specifies. Without going into any more detail, here is the IP configuration I am going to be using,
| Namespace | IP |
| Host | 172.18.0.1/24 |
| Container-1 | 172.18.0.2/24 |
Configuring veth pairs
We now only need to assign the IP to the veth pairs, then set the interface up.
fedora@localhost:~$ sudo ip a add 172.18.0.1/24 dev vethc1
fedora@localhost:~$ sudo ip link set vethc1 up
fedora@localhost:~$ sudo ip netns exec container-1 ip a add 172.18.0.2/24 dev veth1
fedora@localhost:~$ sudo ip netns exec container-1 ip link set veth1 up
fedora@localhost:~$ ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host noprefixroute
valid_lft forever preferred_lft forever
2: enp1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 52:54:00:a5:e0:0e brd ff:ff:ff:ff:ff:ff
inet 192.168.122.240/24 brd 192.168.122.255 scope global dynamic noprefixroute enp1s0
valid_lft 3011sec preferred_lft 3011sec
inet6 fe80::5054:ff:fea5:e00e/64 scope link noprefixroute
valid_lft forever preferred_lft forever
3: vethc1@if4: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 3e:15:d3:43:3b:31 brd ff:ff:ff:ff:ff:ff link-netns container-1
inet 172.18.0.1/24 scope global vethc1
valid_lft forever preferred_lft forever
inet6 fe80::3c15:d3ff:fe43:3b31/64 scope link tentative proto kernel_ll
valid_lft forever preferred_lft forever
fedora@localhost:~$ sudo ip netns exec container-1 ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host proto kernel_lo
valid_lft forever preferred_lft forever
4: veth1@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 92:b2:24:76:93:41 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.2/24 scope global veth1
valid_lft forever preferred_lft forever
inet6 fe80::90b2:24ff:fe76:9341/64 scope link proto kernel_ll
valid_lft forever preferred_lft forever
With this now you should be able to ping the namespaces.
fedora@localhost:~$ ping 172.18.0.2 -c 3
PING 172.18.0.2 (172.18.0.2) 56(84) bytes of data.
64 bytes from 172.18.0.2: icmp_seq=1 ttl=64 time=0.022 ms
64 bytes from 172.18.0.2: icmp_seq=2 ttl=64 time=0.032 ms
64 bytes from 172.18.0.2: icmp_seq=3 ttl=64 time=0.026 ms
--- 172.18.0.2 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2046ms
rtt min/avg/max/mdev = 0.022/0.026/0.032/0.004 ms
fedora@localhost:~$ sudo ip netns exec container-1 ping 172.18.0.1 -c 3
PING 172.18.0.1 (172.18.0.1) 56(84) bytes of data.
64 bytes from 172.18.0.1: icmp_seq=1 ttl=64 time=0.041 ms
64 bytes from 172.18.0.1: icmp_seq=2 ttl=64 time=0.022 ms
64 bytes from 172.18.0.1: icmp_seq=3 ttl=64 time=0.029 ms
--- 172.18.0.1 ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2030ms
rtt min/avg/max/mdev = 0.022/0.030/0.041/0.007 ms
And how about curl from host?
fedora@localhost:~$ curl -s 172.18.0.2:8000/echo | jq
{
"header": {
"Accept": [
"*/*"
],
"User-Agent": [
"curl/8.6.0"
]
},
"body": "Echo response"
}
Wonderful, with this we have a network connection between the host and container.
Fun fact, if you are running Docker or Kubernetes on your host machine, you will be able to see
vethpairs on your system for each container running on your machine. Although you will see a difference, in that none of thevethdevices have an IP assigned to them. This we will come back to when launching multiple containers.
Connecting to the outside world
If you have tried to reach outside the host you will quickly find out that it's not possible.
fedora@localhost:~$ sudo ip netns exec container-1 ping example.com
ping: connect: Network is unreachable
The answer can be found by inspecting the current routing rule.
fedora@localhost:~$ sudo ip netns exec container-1 ip r
172.18.0.0/24 dev veth1 proto kernel scope link src 172.18.0.2
Setting container routes
Remember how we manually assigned static IP to our container? Well, we now have to also manually set up IP routes.
fedora@localhost:~$ sudo ip netns exec container-1 ip r add default via 172.18.0.1 dev veth1 src 172.18.0.2
fedora@localhost:~$ sudo ip netns exec container-1 ip r
default via 172.18.0.1 dev veth1 src 172.18.0.2
172.18.0.0/24 dev veth1 proto kernel scope link src 172.18.0.2
To explain more of what our ip r[oute] add is doing, we are adding a default route (also known as gateway route) through 172.18.0.1 which is our host address. This route traverses through the veth1 interface. Any packet leaving through this interface using this route must have the source IP of 172.18.0.2. A default route is the route the IP packet must take if the device has no idea how to route the IP it received. The gateways are connected to more network interfaces and hopefully, they know how to route the packets, but if they too don't know how they just send the packet down their gateway until some higher-level network can.
Of course, this alone is not enough. Our Linux machines are general network endpoints first and then routers second. So kernel has been set up so that if it receives any packet that doesn't belong to it, it simply drops it. We now have to configure our host system to act as a router. Why is this important, well for one our containers are now in a virtual network only routable through our host system. So we must configure our host to act as a router proper for our containers.
Configuring host as a router
Enable IP Forwarding
We start by allowing our Linux machine to do ip forwarding. This is the setting that tells the Linux kernel what to do when it receives IP that does not belong to this device.
fedora@localhost:~$ sysctl net.ipv4.ip_forward
net.ipv4.ip_forward = 0
There are various ways we can enable (set to 1) this setting.
Temporary
fedora@localhost:~$ sudo sysctl -w net.ipv4.ip_forward=1
net.ipv4.ip_forward = 1
Permanent
fedora@localhost:~$ echo "net.ipv4.ip_forward=1" | sudo tee -a /etc/sysctl.d/10-ip_forward.conf
NOTE: You can load the configuration file by
sysctl -p, or rebooting. If you choose to do reboot, you will have to start from beginning as all the configuration we are currently doing is temporary.
Setting up Masquerading rule
After setting up IP forwarding rules, the next thing to consider is NAT. If you don't know much about NAT, The basic idea is any network our host is on knows how to reach our host, but doesn't know about the virtual network inside our host. Every router has this step of IP Masquerading where it changes the source IP to be originating from the router, so that when the reply does come back it will return to the router which it can forward back to the origin host. This is the protocol over which entire the Internet works.
For this we finally use iptables.
fedora@localhost:~$ sudo iptables -t nat -A POSTROUTING -s 172.18.0.0/24 ! -o vethc1 -j MASQUERADE
If you haven't been using iptables regularly, this syntax looks like magic. But in the simplest form, we are adding a rule to the nat table. This is the table that houses rules for any form of NAT that takes place in Kernel. Similarly, we are hooking into the POSTROUTING chain. Packets in Kernel pass through this chain when all the routing decisions have already taken place, if you change Source or Destination IP at this stage it doesn't change the destination the packet is going to next. We are then applying filter so that only the packets that have source IP in 172.18.0.0/24 CIDR range is transformed and additionally, they should not be going through the vethc1 interface. The reasoning on why we add the later filter makes sense once we start adding multiple containers. Finally, we have the jump rule defined by -j. This basically tells where in the chain should the packet head to if it passes all the filters. In our case, we set it to the default MASQUERADE chain that is responsible for IP masquerading.
Configuring DNS resolver
Once you have added the rule, our container is mostly ready for communicating with the outside world. However, depending on how resolv.conf is set up, we could still have issues.
Remember how we only did network namespacing and did not employ the use of any other namespacing? Well if you check your host resolv.conf it's also the same resolv.conf used by our container. Depending on how your system has its DNS resolution setup it could still fail to resolve domain name to IP address.
nameserver 127.0.0.53
options edns0 trust-ad
search .
This is my resolv.conf and as you can see it's pointed to search in 127.0.0.53, which if you know your localhost CIDR (127.0.0.0/8) is a loopback IP. And we have no process running inside our containers resolving DNS names in localhost. We can get around this by giving the namespace their own resolv.conf set to your own DNS server. I will be using Cloudflare DNS in my example which would be, 1.1.1.1.
fedora@localhost:~$ sudo mkdir -p /etc/netns/container-1
fedora@localhost:~$ echo "nameserver 1.1.1.1" | sudo tee -a /etc/netns/container-1/resolv.conf
nameserver 1.1.1.1
Luckily for us, ip-netns is configured to use this convention to map resolv.conf as can be seen from the man page.
Result
Bringing all of this together,
fedora@localhost:~$ sudo ip netns exec container-1 ping example.com -c3
PING example.com (93.184.215.14) 56(84) bytes of data.
64 bytes from 93.184.215.14: icmp_seq=1 ttl=44 time=101 ms
64 bytes from 93.184.215.14: icmp_seq=2 ttl=44 time=154 ms
64 bytes from 93.184.215.14: icmp_seq=3 ttl=44 time=102 ms
--- example.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2003ms
rtt min/avg/max/mdev = 100.828/119.025/154.437/25.042 ms
fedora@localhost:~$ sudo ip netns exec container-1 dig example.com
; <<>> DiG 9.18.26 <<>> example.com
;; global options: +cmd
;; Got answer:
;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 33889
;; flags: qr rd ra ad; QUERY: 1, ANSWER: 1, AUTHORITY: 0, ADDITIONAL: 1
;; OPT PSEUDOSECTION:
; EDNS: version: 0, flags:; udp: 1232
;; QUESTION SECTION:
;example.com. IN A
;; ANSWER SECTION:
example.com. 3403 IN A 93.184.215.14
;; Query time: 8 msec
;; SERVER: 1.1.1.1#53(1.1.1.1) (UDP)
;; WHEN: Wed Jul 24 15:30:05 CEST 2024
;; MSG SIZE rcvd: 56
Finally, we have a single "container" running in our system. It is serving a web server on port 8000 that is reachable from inside the "container" system and from our host system. It also can connect to the Internet using our host system.
Let's have a high-level overview of our current system.
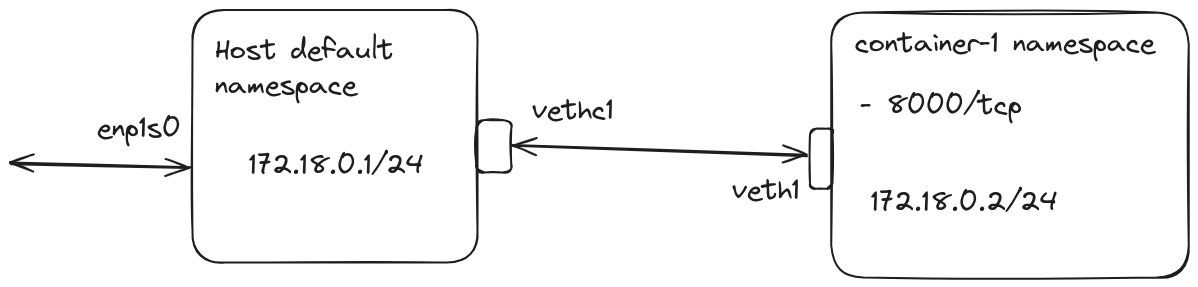
But we are only getting started, head over to Part II of the series to find out how to handle multiple "containers".
Cleanup
To clean up every change we did, you could either backtrace and remove changes one by one or just reboot your system.
Subscribe to my newsletter
Read articles from Ranjan Ojha directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by