[트러블 슈팅] 재고 관리 서비스의 동시성 테스트 및 문제 해결(1) - DB Lock
 Myonee
Myonee동시성 환경에 대한 이해
스프링 부트는 멀티 스레드 환경이기 때문에 여러 스레드가 동시에 데이터에 접근하고 수정할 수 있고, 이 때 동시성 관련 문제가 발생한다.
경쟁 상태 (Race Condition)
여러 스레드가 동시에 데이터를 수정할 때 "경쟁 상태(Race Condition)"가 발생할 수 있다. 서로의 변경사항을 고려하지 못할 때 데이터 일관성이 깨질 수 있는 것이다.데드락 (Deadlock)
두 개 이상의 트랜잭션이 서로가 소유한 자원을 기다리면서 무한 대기 상태에 빠지는 현상으로, 여러 트랜잭션이 중복된 자원에 순서만 다르게 접근할 때 발생할 가능성이 높다.불일치 읽기 (Inconsistent Read)
한 트랜잭션이 데이터를 읽는 동안 다른 트랜잭션이 데이터를 수정하여 읽은 데이터가 일관되지 않아 데이터 일관성이 깨지는 문제가 발생한다.
테스트 코드 실행
상품의 재고가 0일때 n개를 추가하고 해당 상품을 1개 주문하는 작업을 n개 요청한다면?
주문은 n번 성공하고 재고는 다시 0이 될 것으로 기대할 수 있다.
@BeforeEach
void setUp() { // 상품정보 저장
// concurrency
productDetail = new Product.Detail(
null, 0L, 0L, 0L
);
product = new Product(
null, "고양이 인형", new BigDecimal("100"), productDetail
);
catId = productService.saveProduct(product);
}
@Test
@DisplayName("상품 주문 동시성 테스트")
public void test_concurrency_deduct_stocks() throws InterruptedException {
// given - 고양이 인형 0 -> 5개 추가
stocks.add(new StockCommand(catId, 5L));
stockService.addStocks(stocks);
// given - 주문 객체 세팅
stocks = new ArrayList<>(); // 초기화
stocks.add(new StockCommand(catId, 1L));
// when
int numThreads = 5; //동시에 실행할 스레드 수
CountDownLatch doneSignal = new CountDownLatch(numThreads);
ExecutorService executorService = Executors.newFixedThreadPool(numThreads);
AtomicInteger successCount = new AtomicInteger();
AtomicInteger failCount = new AtomicInteger();
for (int i = 0; i < numThreads; i++) {
executorService.execute(() -> {
try {
stockService.deductStocks(stocks);
successCount.getAndIncrement();
} catch (InputValidationException e) {
failCount.getAndIncrement();
} finally {
doneSignal.countDown();
}
});
}
doneSignal.await(); //스레드 작업이 완료될 때 까지 대기
executorService.shutdown(); //작업이 완료된 후 스레드 풀 종료
// then
assertAll(
() -> assertThat(successCount.get()).isEqualTo(5),
() -> assertThat(failCount.get()).isEqualTo(0)
);
Product result = productService.findProduct(catId);
assertThat(result.getId()).isEqualTo(catId);
assertThat(result.getProductDetail().getQuantity()).isEqualTo(0L);
}
그러나 테스트는 다음과 같이 실패한다.
왜 실패하지?

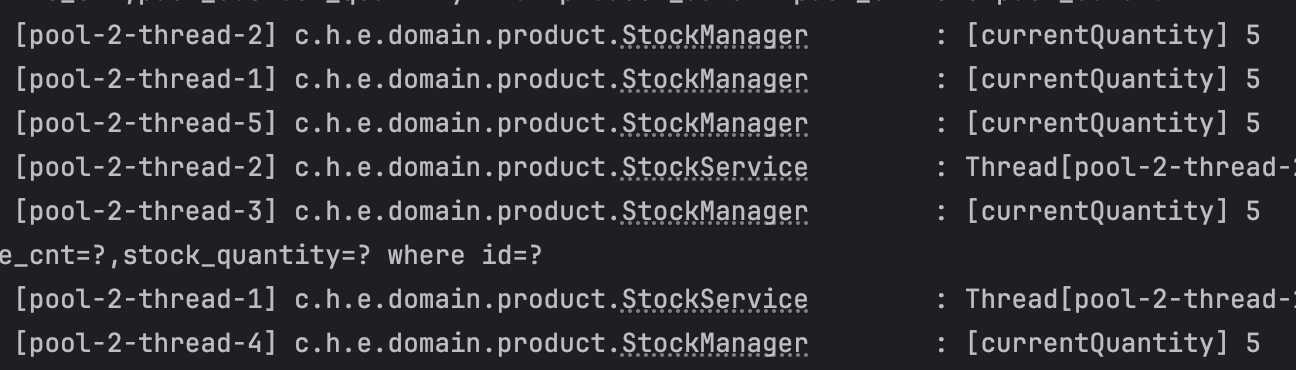
Quantity 체크에서 테스트가 실패했기 때문에 successCount까지는 통과했으므로 트랜잭션은 모두 제대로 실행되었는데, 결과가 0이 아닌 4가 되는 이유는 경쟁 상태가 발생했다고 추측해볼 수 있다.
해당 로직에서 읽어온 재고를 확인해보면 역시나 모두 수량 5개를 가져오고 있는 것을 확인할 수 있다.
트랜잭션 격리 레벨
테스트용 h2 DB는 별도의 설정이 없다면 Read Committed가 기본 설정이다.
Read committed
https://www.h2database.com/html/advanced.html
This is the default level. Dirty reads aren't possible; non-repeatable reads and phantom reads are possible. To enable, execute the SQL statement SET SESSION CHARACTERISTICS AS TRANSACTION ISOLATION LEVEL READ COMMITTED
Spring 트랜잭션에서 기본적인 격리 수준은 'DEFAULT' 이다. 즉, 스프링 트랜잭션에서 격리 수준은 현재 사용하고 있는 RDBMS가 채택하는 기본 트랜잭션 격리 수준을 따라간다.
h2의 격리수준은 jpa 로 설정해줄 수 있는데, 기본 Read Committed로 동작하겠지만 DB가 바뀌어도 해당 격리수준을 최소로 유지하기 위해 isolation 레벨을 설정해줄 수 있다.
jpa:
hibernate:
ddl-auto: create
show-sql: true
properties:
hibernate:
format_sql: true
connection:
isolation: 2 # 해당 숫자 기입하면 변경 가능
# 1: READ UNCOMMITTED
#2: READ COMMITTED (default)
#4: REPEATABLE READ
#8: SERIALIZABLE
READ COMMITTED 레벨에서는 커밋된 값만을 읽을 수 있기때문에 DIRTY READ 문제는 없다.
그러나 같은 트랜잭션 내에서 SELECT 쿼리로 여러번 조회할 경우 중간에 다른 트랜잭션에 의해 데이터가 변경된다면 결과가 달라질 수 있다. 이런 문제를 NON-REPEATABLE READ 라고 한다.
그런데 JPA의 영속성 컨텍스트(1차 캐시)는 트랜잭션 격리 수준이 READ COMMITTED여도 애플리케이션 내에서 REPEATABLE READ가 가능하다.
영속성 컨텍스트는 내부에 캐시를 가지고 있는데 이것을 1차 캐시라 하고, find를 할 경우 1차 캐시에서 식별자 값으로 엔티티를 찾은 뒤 해당 엔티티가 없을 때만 DB를 조회한다. 스프링에서는 이 영속성 컨텍스트의 생존 범위가 트랜잭션 범위와 같다. 그리고 트랜잭션 커밋 시 영속성 컨텍스트를 플러시한다.
그렇기 때문에 READ COMMITTED레벨에서도 한 트랜잭션 내에서는 데이터의 정합성이 유지된다. 트랜잭션이 유지되는 동안에는 다른 트랜잭션에 의한 변경사항, 불일치 읽기 (Inconsistent Read)를 방지할 수 있다. 그러나 이 1차 캐시로는 경쟁 상태 (Race Condition)를 방지할 수는 없다.
락(Lock) 구현
경쟁 상태를 방지하기 위해 상품 재고 조회 로직을 동시에 실행하지 못하도록 해야 한다. 한 스레드가 트랜잭션을 실행하고 있다면 다른 스레드가 접근하지 못하도록 막아야 하는 것이다. 이렇게 트랜잭션을 선점할 수 있도록 하는 것이 락(Lock) 이다.
Optimistic Lock
트랜잭션이 서로 거의 충돌하지 않는다는 가정 하에 락을 걸지않고 버전을 체크하는 방법이다. 데이터 저장 시, 즉 트랜잭션이 종료되는 시점에 버전을 확인하여 조회했던 버전과 달라지면 트랜잭션이 실패한다. 재고가 남아있더라도 버전이 다르면 요청이 실패하기 때문에 (따로 재시도 로직이 없다면)동시 요청 발생시 가장 먼저 트랜잭션을 선점한 스레드만 요청에 성공한다.
낙관적 락이 제대로 작동하는 지 확인하기 위해선 테스트 코드를 수정할 필요가 있다.
successCount와 failCount의 개수를 확인하는 코드는 지우고, 성공한 트랜잭션의 수만큼 재고를 차감하는지 확인하는 코드를 추가한다.
assertThat(result.getProductDetail().getQuantity())
.isEqualTo( 5L - ((long) successCount.get()*1L));
@Version
private Long version; /* 버전 관리 */
가장 처음 트랜잭션을 선점한 요청 외에는 모두 ObjectOptimisticLockingFailureException 에러를 반환한다.
Exception in thread "pool-2-thread-5"
org.springframework.orm.ObjectOptimisticLockingFailureException:
Row was updated or deleted by another transaction
(or unsaved-value mapping was incorrect) :
[xxx.xxx.xxx.infrastructure.product.ProductDetailEntity#3]
테스트엔 성공했지만 요청을 모두 성공시키진 못했다. 요청을 모두 처리하기 위해 테스트 코드에서successCount와 failCount를 다시 확인하고, 이번엔 서비스 메서드에 재시도로직을 추가한다.
스프링에선 @Retryable 어노테이션으로 간단하게 구현할 수 있다.
dependencies {
implementation 'org.springframework.retry:spring-retry'
implementation 'org.springframework:spring-aspects'
}
@Retryable(
retryFor = {ObjectOptimisticLockingFailureException.class},
maxAttempts = 3,
backoff = @Backoff(1000) // 밀리초 : 1초
)
@Recover
public void recover(ObjectOptimisticLockingFailureException e) {
// 재시도 후에도 실패 시 실행할 로직
throw new IllegalArgumentException(STOCK_DEDUCT_FAILED.getMessage());
}
그리고 테스트 코드를 실행하면 실패한다.
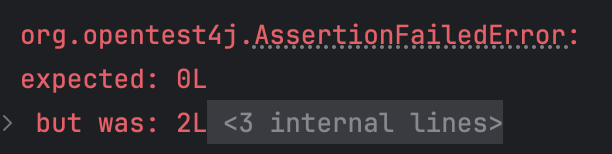
정확히 재시도 횟수만큼 성공하고 나머지 요청은 모두 실패하는데, 재시도 간격과 상관없이 재시도 횟수를 5회이상 시도할 경우에만 성공했다.
n개의 스레드에서 동시에 트랜잭션이 실행되고 한 개의 트랜잭션만 성공 ⇢ 나머지 스레드 실패 및 재시도 간격 이후 재시도 이 동작을 반복하기 때문에 재시도 간격이 일정하다면 대부분 계속 충돌이 발생한다. 그래서 n개의 동시 스레드 요청을 처리하려면 거의 n번의 retry가 필요한 것이다.
backoff = @Backoff(delay = 500, maxDelay = 600, random = true)
재시도 간격을 랜덤하게 처리할 경우 충돌 가능성이 줄어들어 재시도 요청 수가 n개보다 적은 경우도 성공할 수 있다. delay와 maxDelay사이 간격을 5밀리초 정도로 줄여봐도 재고 차감 5회 요청시 4~5회 성공하는 것을 확인할 수 있었다.
그러나 재고가 남아있음에도 버전차이로 실패해서 재시도하는 건 비효율적이다. 게다가 낙관적 락은 트랜잭션이 종료되는 시점에 요청의 성공여부를 확인할 수 있기 때문에 실패하기 전까지 트랜잭션을 길게 유지하여 시스템 자원을 불필요하게 점유하게 된다.
요청 완료까지 걸리는 총 시간은 582~1124ms 가량이다.
Pessimistic Lock
순차로 진행될 때 차례로 공유자원에 접근하도록 하여 성공시킬 수 있도록 하는 방법은 비관적 락(Pessimistic Lock)이다. 특정 자원에 대해 Lock을 설정하고 선점해 정합성을 보장하는 방식으로, 낙관적 락과는 달리 실제로 자원에 락이 걸린다. 재고가 남아있을 때 까지 재시도와 실패없이 모든 요청을 성공시키기 위해서 비관적 락을 사용할 수 있다.
테스트를 위해 서비스의 @Retryable 코드는 제거한다.
JPA에서 락은 어노테이션으로 간단하게 구현할 수 있다. LockModeType은 PESSIMISTIC_WRITE와 PESSIMISTIC_READ가 있는데, PESSIMISTIC_WRITE을 사용한 이유는 좀 더 아래에서 설명하도록 하고, 우선 for update 로 구현해보자.
]@NonNull
@Lock(LockModeType.PESSIMISTIC_WRITE)
@Query("select p from ProductDetailEntity p WHERE p.id = :id")
Optional<ProductDetailEntity> findByIdWithLock(@Param("id") Long id);
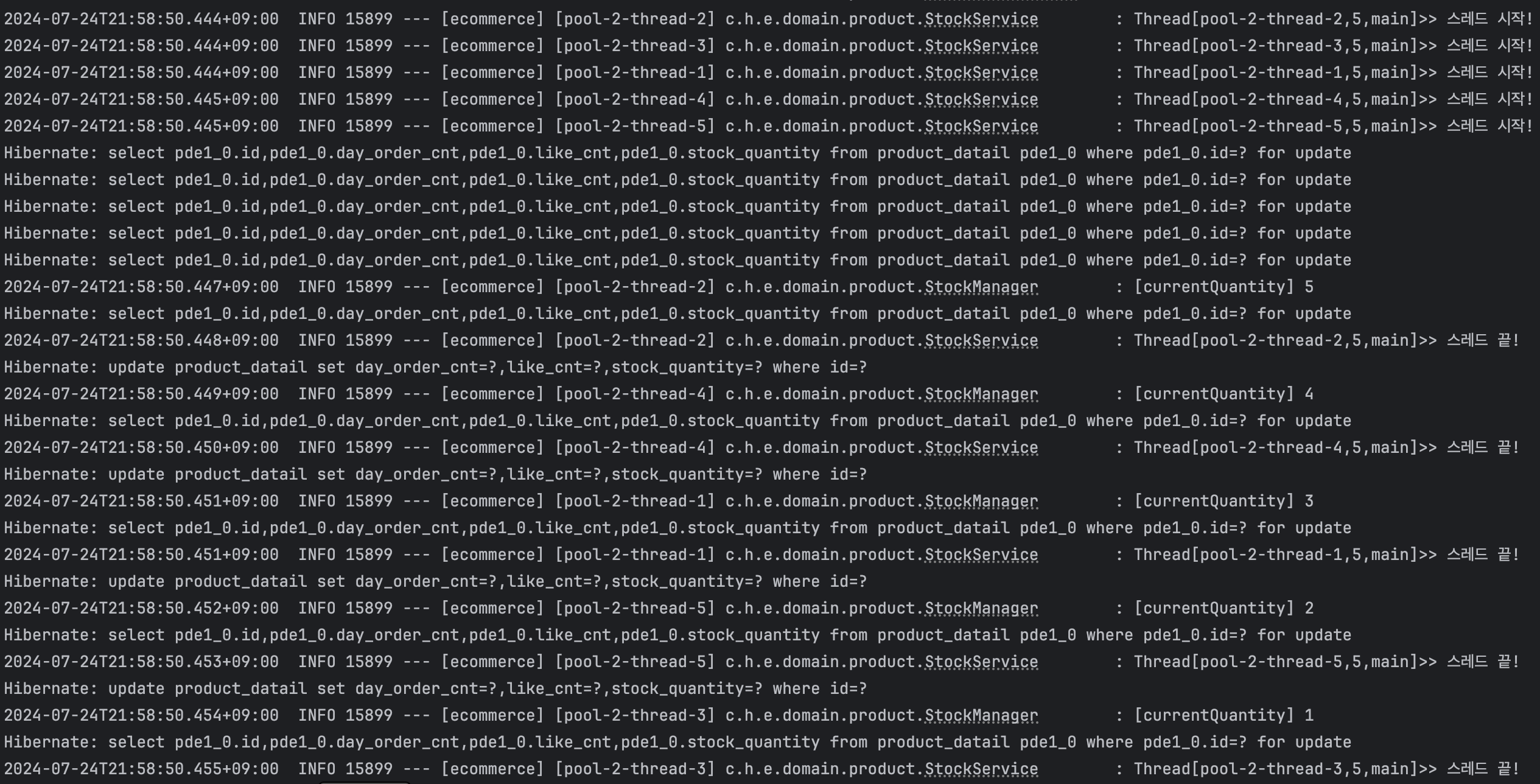
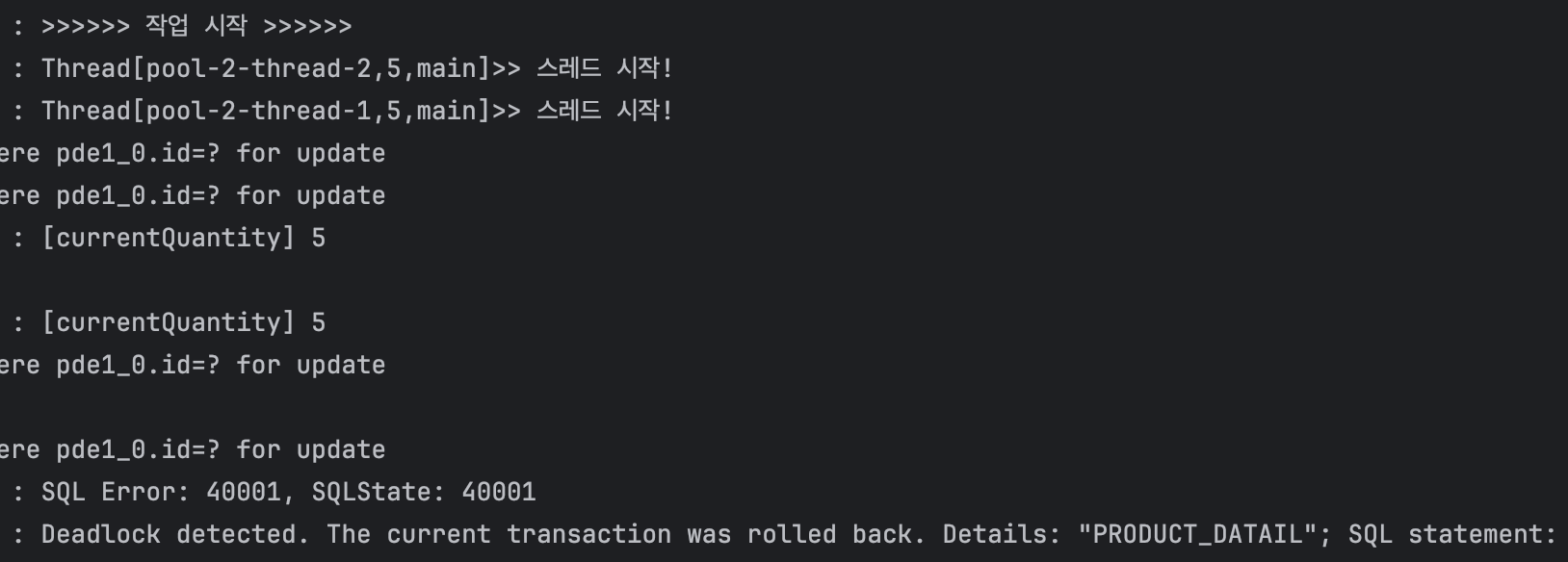
테스트 로그를 확인해보면 select ... for update 쿼리를 통해 비관적 락(Pessimistic Lock)을 획득하고, 나머지 스레드가 선점한 스레드의 트랜잭션이 완료될 때까지 기다린 후 차례대로 로직을 시작하여 재고가 하나씩 차감되는 것을 확인할 수 있다.
다만 이 테스트는 id 가 동일한 하나의 데이터에 대한 요청이기 때문에 통과한다.
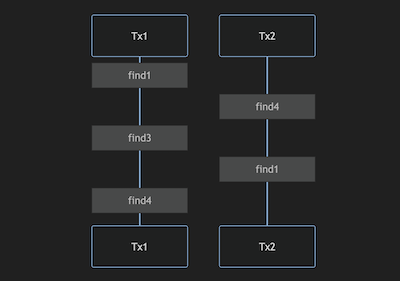
만약 여러 제품의 리스트가 순서가 뒤섞인 채로 락을 획득하게 된다면 그림과 같이 트랜잭션1에서는 3에대한 락을 획득한 후 4에 대한 락을 획득하려 하고, 트랜잭션2에선 4에 대한 락을 먼저 획득한 후 1에 대한 락을 획득하려 할 것이다. 그러나 두 트랜잭션이 동시에 진행되는 경우 트랜잭션이 완료되지 않은 채로 락을 유지하고 있기 때문에 영원히 교착상태에 빠지게 되는 **데드락(Deadlock)**이 발생할 것이다.
다음과 같이 데드락이 발생하는 경우의 테스트 코드를 작성하고 테스트를 진행하면 데드락을 확인할 수 있다.
// given - 주문 객체 세팅
List<StockCommand> stocksA = new ArrayList<>(); // 초기화
stocksA.add(new StockCommand(catId, 2L));
stocksA.add(new StockCommand(bearId, 1L));
List<StockCommand> stocksB = new ArrayList<>(); // 초기화
stocksB.add(new StockCommand(bearId, 1L));
stocksB.add(new StockCommand(catId, 2L));
공유자원의 순서를 일정하게 증가하거나 감소하도록 정렬해주면 차례대로 자원에 접근할 수 있다.
stocks.sort(Comparator.comparing(StockCommand::getProductId));
해당 코드를 서비스 메서드 내부에 추가해주면 테스트는 통과한다.
낙관적 락과 동일한 테스트를 실행할 경우 총 작업 시간은 8ms다.
일반적으로 비관적 락(Pessimistic Lock)보다 낙관적 락(Optimistic Lock)이 실제 데이터베이스에 락을 걸지 않고, 락 획득에 걸리는 시간이 없기 때문에 속도가 더 빠르다. 그러나 재고 관리 로직에서는 단순히 데이터의 정합성을 유지하는 것뿐만 아니라 재고를 최대한 많이 차감해야 하기 때문에, 속도는 상대적으로 덜 중요한 요소가 될 수 있다.
S-Lock (Shared Lock, 공유 락) : PESSIMISTIC_READ
여러 트랜잭션이 동시에 동일한 데이터에 대해 S-Lock을 획득할 수 있다.
여러 트랜잭션이 동시에 데이터를 읽을 수(S-Lock) 있지만, 데이터를 수정(X-Lock)할 수는 없다.
이 때 유의할 점은, 결국 데이터를 읽어 S-Lock 락을 획득하더라도 수정하기 위해서는 X-Lock을 획득해야한다는 점이다. 그렇다면 S-Lock이 해제되어야 X-Lock락을 획득할 수 있는데 데이터를 읽은 후 수정하는 로직이라면 동시에 여러개의 트랜잭션이 공유자원에 접근했을 때 X-Lock을 획득하기 위해 서로 S-Lock이 해제되길 기다리는 데드락이 발생할 수 있다는 점이다.
앞서 PESSIMISTIC_READ를 쓰지 않은 이유는 바로 이런 위험성도 있기 때문이다. 하지만 그 전에 애당초 H2 데이터베이스에서는 FOR SHARE 구문을 지원하지 않는다. 그래서 실제로 READ로 설정해도 for update 쿼리를 실행하는 것을 확인할 수 있다.
X-Lock (Exclusive Lock, 배타 락) : PESSIMISTIC_WRITE
- 한 번에 하나의 트랜잭션만 X-Lock을 획득할 수 있다. 즉, X-Lock이 걸린 데이터는 다른 트랜잭션이 읽거나(S-Lock) 수정(X-Lock)할 수 없다.
이외의 방법
Sort 없이 트랜잭션의 범위를 축소하여 데드락이 발생할 경우를 없앤다.
재고 차감 실패시 보상트랜잭션으로 차감된 재고를 체크하여 수동 롤백해줘야 하므로 구현이 번거롭다.
트랜잭션 단위로 더 넓은 범위의 락을 건다.
앞의 구현에선 해당 레코드에 락을 걸었다면, 트랜잭션을 한 묶음으로 처리하여 굳이 레코드에 락을 걸지 않고도 처리할 수 있다.
락 테이블 과 같은 방식으로 더미 데이터를 사용하여 구현할 수 있으며, 트랜잭션 실행시 해당 레코드에 접근함으로써 특정 레코드가 아닌 트랜잭션 전체를 잠글 수 있다.
단, 이 방식은 반드시 락 테이블에 해당 레코드가 존재해야 하며, 트랜잭션이 길어질 경우 성능 저하(스레드 점유, DB 커넥션 점유)가 일어날 수 있다는 단점이 있다.
락 테이블과 유사한 방식으로, DB 서버가 아닌 메모리에서 동시성 문제를 처리할 수 있도록 한 것이 바로 Redis의 분산 락이다. 인메모리 DB를 사용하면 간단하고 더 빠르게 락을 처리할 수 있다.
📘 참고자료
https://velog.io/@mohai2618/동시성-환경-테스트하기
https://studyandwrite.tistory.com/566 낙관적락
https://velog.io/@rg970604/데이터베이스-공유-락과-배타-락
https://velog.io/@sontulip/optimistic-lock-infinite-loop
https://tech.wonderwall.kr/articles/deadlock/
https://mangkyu.tistory.com/299
Subscribe to my newsletter
Read articles from Myonee directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by