Detecting Fraud in Real-Time with Apache Pinot and Serverless Kafka
 Baseer Baheer
Baseer BaheerIn today’s digital economy, real-time fraud detection is crucial for safeguarding financial transactions. By integrating Apache Pinot with Serverless Kafka, you can build a robust and scalable system for detecting fraudulent activities as they happen. This example walks you through setting up such a system using Upstash’s Serverless Kafka.
Step 1: Set Up Your Kafka Cluster
First, create a Kafka cluster using the Upstash Console:
- Create Kafka Cluster: Navigate to the Upstash Console and create a new Kafka cluster.
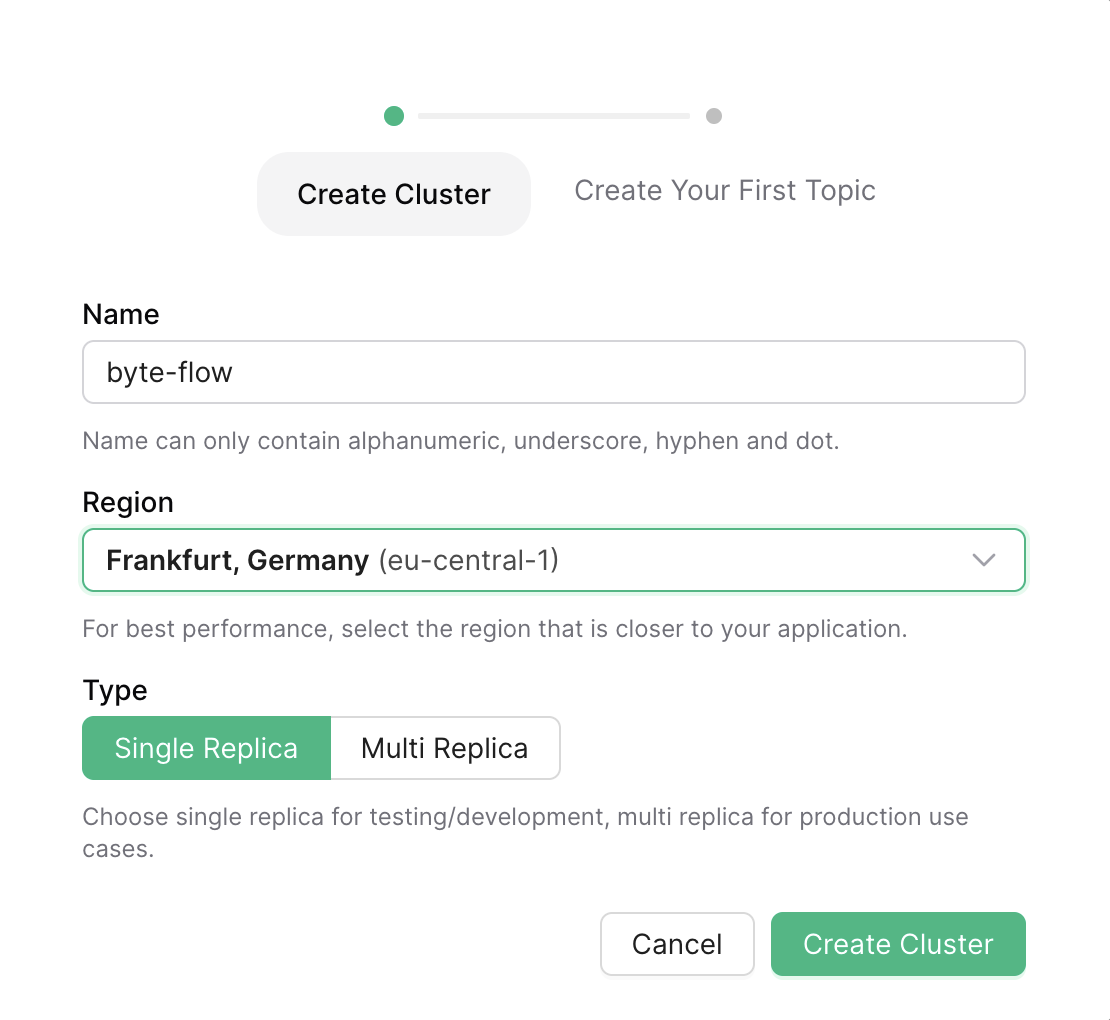
- Create Topic: Create a topic named
fraud-detection. This topic will hold the transaction data streams.
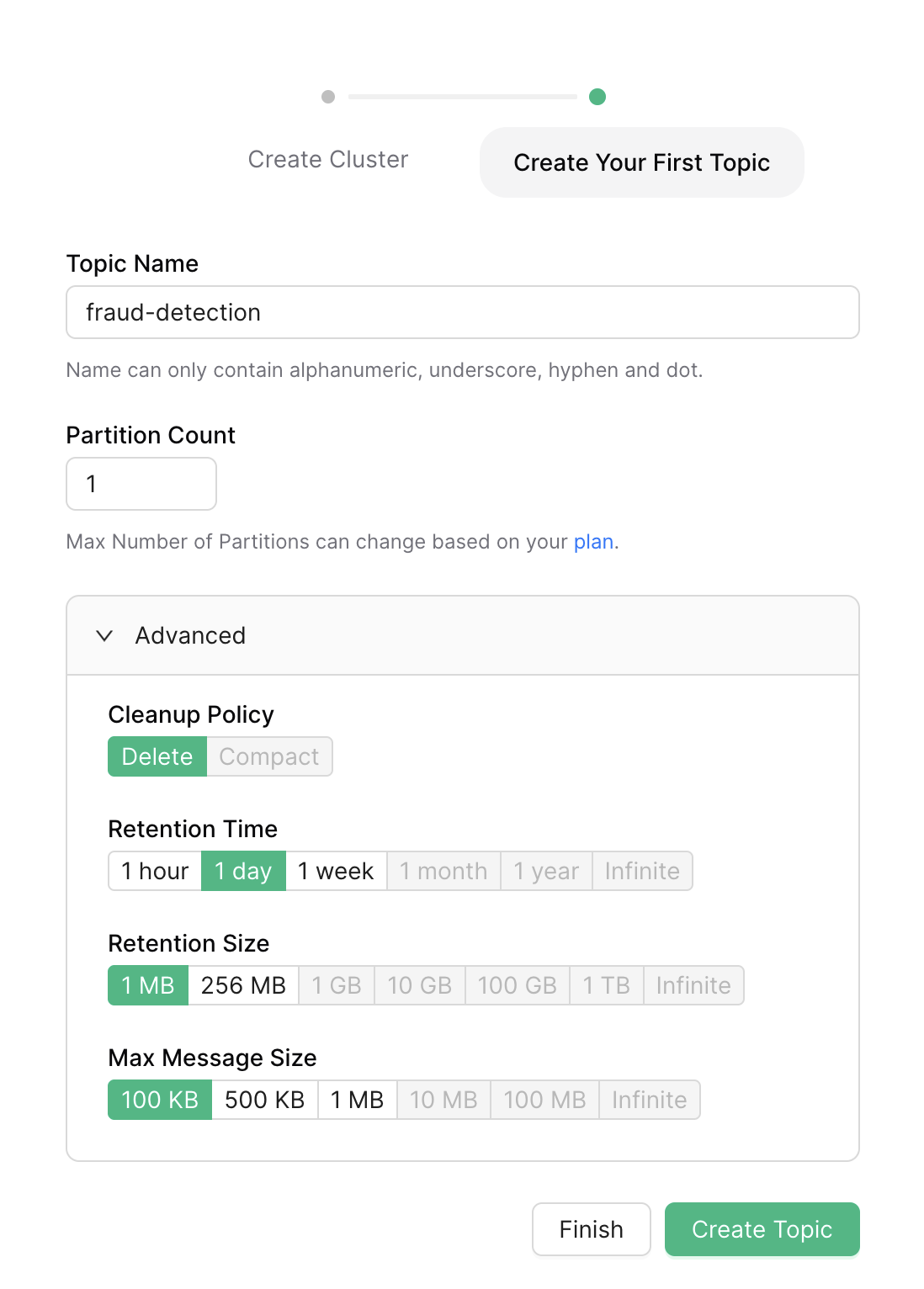
Step 2: Configure Apache Pinot
Download and Run Pinot: Use Docker to run Apache Pinot
docker run -d -p 9000:9000 -p 8000:8000 -p 7001:7000 -p 6000:6000 --name pinot apachepinot/pinot:latest QuickStart -type hybrid
Now, you should add table to your Pinot to store the data streamed from Kafka topic.
You need to open http://localhost:9000/ on your browser.

Click on “Tables” section.
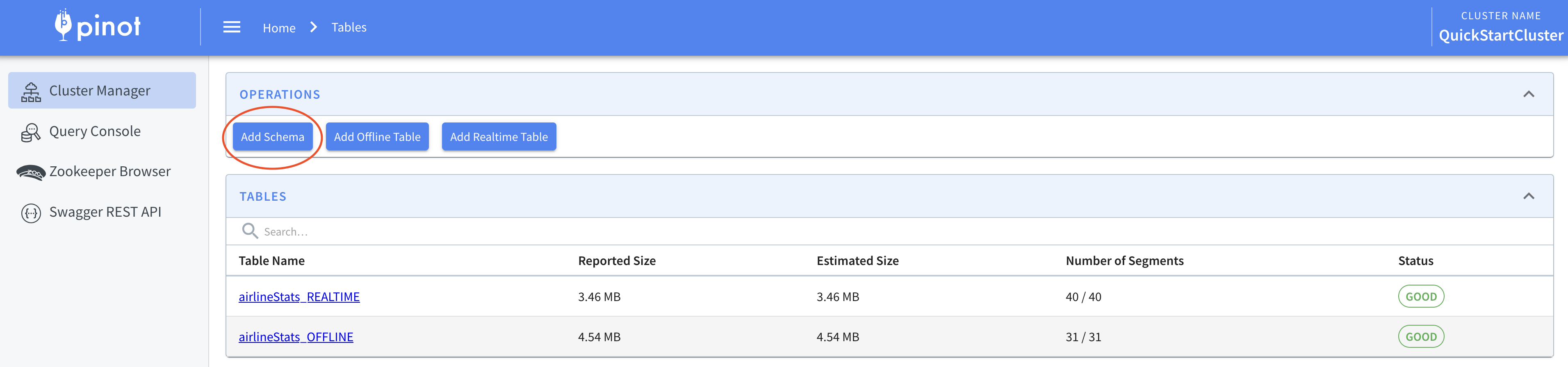
First, click on “Add Schema” and fill it until you see the following JSON as your schema config.
{
"schemaName": "fraudDetection",
"enableColumnBasedNullHandling": false,
"dimensionFieldSpecs": [
{
"name": "transactionId",
"dataType": "STRING",
"notNull": false
},
{
"name": "userId",
"dataType": "STRING",
"notNull": false
},
{
"name": "transactionAmount",
"dataType": "DOUBLE",
"notNull": false
},
{
"name": "merchantId",
"dataType": "STRING",
"notNull": false
},
{
"name": "transactionType",
"dataType": "STRING",
"notNull": false
}
],
"dateTimeFieldSpecs": [
{
"name": "transactionTime",
"dataType": "LONG",
"notNull": false,
"format": "1:MILLISECONDS:EPOCH",
"granularity": "1:MILLISECONDS"
}
]
}
Click save and click to “Add Realtime Table” since we will stream the data real-time.
On this page, table name must be the same name with the schema name, which is “fraudDetection” in this case.
Then, go below on this page and replace “segmentsConfig” and “tableIndexConfig” sections in the table config on your browser with the following JSON. Do not forget to replace UPSTASH-KAFKA-* placeholders with your cluster information.
{
"tableName": "fraudDetection",
"tableType": "REALTIME",
"tenants": {
"broker": "DefaultTenant",
"server": "DefaultTenant",
"tagOverrideConfig": {}
},
"segmentsConfig": {
"schemaName": "fraudDetection",
"timeColumnName": "transactionTime",
"replication": "1",
"replicasPerPartition": "1",
"retentionTimeUnit": null,
"retentionTimeValue": null,
"completionConfig": null,
"crypterClassName": null,
"peerSegmentDownloadScheme": null
},
"tableIndexConfig": {
"loadMode": "MMAP",
"invertedIndexColumns": [],
"createInvertedIndexDuringSegmentGeneration": false,
"rangeIndexColumns": [],
"sortedColumn": [],
"bloomFilterColumns": [],
"bloomFilterConfigs": null,
"noDictionaryColumns": [],
"onHeapDictionaryColumns": [],
"varLengthDictionaryColumns": [],
"enableDefaultStarTree": false,
"starTreeIndexConfigs": null,
"enableDynamicStarTreeCreation": false,
"segmentPartitionConfig": null,
"columnMinMaxValueGeneratorMode": null,
"aggregateMetrics": false,
"nullHandlingEnabled": false,
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.topic.name": "fraud-detection",
"stream.kafka.broker.list": "UPSTASH-KAFKA-ENDPOINT:9092",
"stream.kafka.consumer.type": "lowlevel",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"realtime.segment.flush.threshold.rows": "0",
"realtime.segment.flush.threshold.segment.rows": "0",
"realtime.segment.flush.threshold.time": "24h",
"realtime.segment.flush.threshold.segment.size": "100M",
"security.protocol": "SASL_SSL",
"sasl.jaas.config": "org.apache.kafka.common.security.scram.ScramLoginModule required username=\"UPSTASH-KAFKA-USERNAME\" password=\"UPSTASH-KAFKA-PASSWORD\";",
"sasl.mechanism": "SCRAM-SHA-256"
}
},
"metadata": {},
"ingestionConfig": {
"filterConfig": null,
"transformConfigs": null
},
"quota": {
"storage": null,
"maxQueriesPerSecond": null
},
"task": null,
"routing": {
"segmentPrunerTypes": null,
"instanceSelectorType": null
},
"query": {
"timeoutMs": null
},
"fieldConfigList": null,
"upsertConfig": null,
"tierConfigs": null
}
Whenever you make any changes to the schema in Apache Pinot, it is important to reload the table segments to ensure the new schema is applied correctly. Here’s a step-by-step guide on how to do this:
1. Access the Pinot Controller UI:
Open your web browser and go to the Pinot Controller UI at http://localhost:9001.
2. Select Your Table: In the UI, find and click on the name of your table, in this case, f
raudDetection_REALTIME.3. Reload All Segments:
Once you are on the table details page, look for the option to reload the table segments. Click on “Reload All Segments” to apply the schema changes to all segments.

Test the Setup
Now, let’s create some events to our Kafka topic. Go to Upstash console, click on your cluster then Topics, click “fraud-detection”. Select Messages tab then click Produce a new message. Send a message in JSON format like the below:
{
"transactionId": "12345",
"userId": "user_01",
"transactionAmount": 250.75,
"merchantId": "merchant_99",
"transactionType": "purchase",
"transactionTime": 1627847280000,
"isFraud": false
}
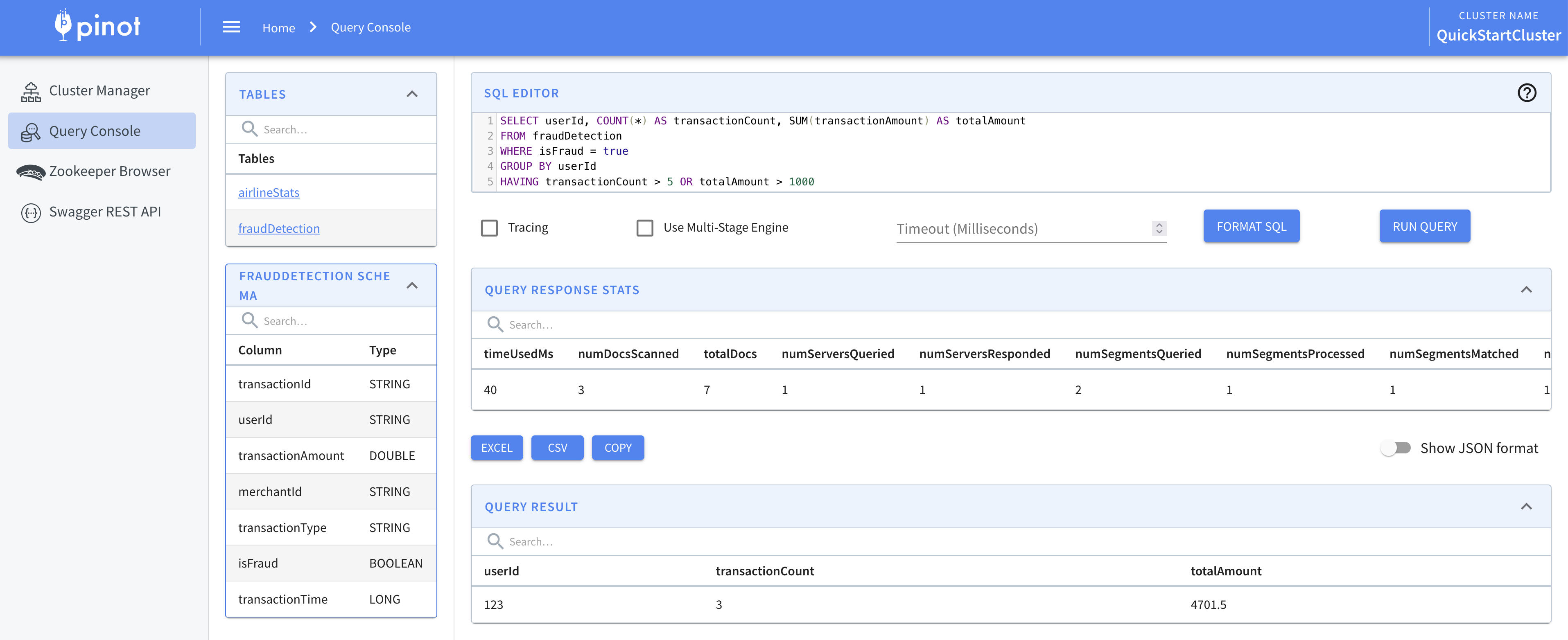
Running SQL Queries
You can run your SQL queries by navigating to the Query Console on the left sidebar.
SELECT userId, COUNT(*) AS transactionCount, SUM(transactionAmount) AS totalAmount
FROM fraudDetection
WHERE isFraud = true
GROUP BY userId
HAVING transactionCount > 5 OR totalAmount > 1000
Subscribe to my newsletter
Read articles from Baseer Baheer directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Baseer Baheer
Baseer Baheer
Passionate about spreading knowledge and supporting open-source projects. Computer and Data Scientist by profession, tennis player by passion. Always eager to learn and share new insights in technology and data.