Kubernetes Event-Driven Autoscaler (KEDA)
 Bruno Gatete
Bruno Gatete
Scalability is a critical aspect for modern container-based application deployments. Autoscaling has become essential across all cloud platforms, and microservices, often deployed as containers or pods, are no exception. Microservices, with their flexible and decoupled design, are ideal for autoscaling as they are easier to create on-demand compared to virtual machines.
The main advantage of autoscaling, when properly configured and managed, is that the workload receives exactly the computational resources it needs at any given moment. This optimization ensures cost efficiency, as we only pay for the server resources we actually use.
Given that Kubernetes has become the standard for container orchestration and is widely adopted across industries, it's crucial to consider how to scale applications deployed on Kubernetes both on demand and during periods of low activity. Most cloud providers support the Cluster Autoscaler, which, when combined with container autoscaling, provides a powerful tool to efficiently scale applications and minimize cloud costs.
Cluster Autoscaler
To handle varying application demands, such as fluctuations during the workday versus evenings or weekends, clusters need a way to automatically scale. Cloud providers like Azure, AWS, and GCP support Kubernetes Autoscalers. The Cluster Autoscaler adds or removes computing resources (machines or VMs) at runtime based on the workload. Kubernetes clusters generally scale in and out in two primary ways:
Cluster Autoscaler: This component monitors pods that cannot be scheduled due to resource constraints and increases the number of nodes to accommodate these pods. Conversely, if nodes are underutilized with no running pods, the Cluster Autoscaler will remove these nodes to save costs.
Horizontal Pod Autoscaler (HPA): This uses the Metrics Server in a Kubernetes cluster to monitor pod resource demand. If an application requires more resources, the HPA automatically increases the number of pods to meet the demand.
In this tutorial, we will not demonstrate the Cluster Autoscaler feature for node autoscaling. However, in real-world scenarios, enabling both Cluster Autoscaler and Pod Autoscaling can significantly reduce cloud costs. Using KEDA, we can scale down pods when they are not needed, prompting the Cluster Autoscaler to remove the corresponding nodes, thereby optimizing resource usage and costs.
What is KEDA?
KEDA (Kubernetes-based Event Driven Autoscaler) is a Kubernetes component that drives the scaling of containers based on event-driven processing needs. KEDA handles triggers that respond to events in other services and scales workloads accordingly.
KEDA is a single-purpose, lightweight component that can be integrated into any Kubernetes cluster. It works alongside standard Kubernetes components like the Horizontal Pod Autoscaler, extending their functionality without duplication. With KEDA, we can specifically map which applications should scale while others continue to operate normally. This makes KEDA a flexible and safe option to run alongside any Kubernetes applications or frameworks.
Scalers
KEDA includes a variety of scalers that can detect when a deployment should be activated or deactivated, feeding custom metrics based on specific event sources.
ScaledObject
ScaledObject is deployed as a Kubernetes Custom Resource Definition (CRD). It defines how KEDA should scale an application and specifies the triggers to use.
Leveraging KEDA for Autoscaling
In this tutorial, we will explore how to use KEDA to autoscale microservices deployed as containers or pods in a Kubernetes cluster, based on the following events:
External event or trigger
HTTP event
While the example used here is simple, it effectively demonstrates KEDA's capabilities. We will explore some of the scalers supported by KEDA through the following steps:
Installing KEDA
Deploying a sample application
Deploying a KEDA Event Scaler
Testing autoscaling with the Event Scaler
Deploying an HTTP Scaler
Testing autoscaling with the HTTP Scaler
Prerequisites
Kubernetes Cluster: A running Kubernetes cluster. If not available, follow instructions to set up a Kubernetes cluster.
kubectl: Refer to the "Install and Set Up kubectl" page for details on installing kubectl.
Helm: Helm will be used to deploy KEDA. Refer to the Helm installation guide.
1. Installing KEDA
Below are the various options which can be used to install KEDA on Kubernetes Cluster.
Here, we will use Helm Chart to deploy KEDA.
1.1 Add Keda Core Repo to Helm: First, we will add the kedacore repository to our Helm instance by executing the below command.
helm repo add kedacore https://kedacore.github.io/charts
1.2 Update Helm repo: Then, let’s fetch the information on the new kedacore repo that we added above:
helm repo update
1.3 Install keda Helm chart: Finally, we need to create a namespace for KEDA and install kedacore using Helm chart:
kubectl create namespace keda
helm install keda kedacore/keda --namespace keda
Once the installation is successful, let’s verify whether the keda pods are up and running by executing the below command.
kubectl get deploy,crd -n keda
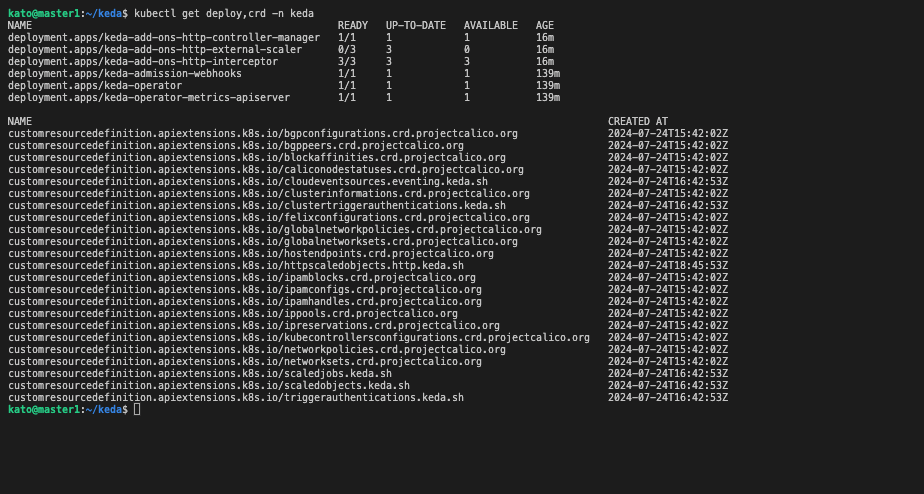
As we can see above in the image the keda pods are up and running.
2. Deploying Sample Application
It’s time to deploy a demo application. Here, we will use the official latest nginx image at Kubernetes. To deploy the sample application, we will execute the below commands. It creates a ReplicaSet to bring up nginx Pods.
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: nginx-http-scaledobject
spec:
host: http://192.168.1.60:30661/
targetPendingRequests: 1
scaleTargetRef:
deployment: nginx
service: nginx
port: 80
replicas:
min: 0
max: 3
create the Deployment using the above file.
kubectl apply -f nginx-deployment.yaml
Let’s check if the deployment was created successfully by executing the below command.
kubectl get deployments

To make our pods accessible via a web browser, we need to expose them to external traffic. One of the simplest methods to achieve this in Kubernetes is by using a NodePort service. A NodePort service opens a specific port on all the nodes (virtual machines) in the cluster and forwards any traffic received on this port to the designated service.
Creating a NodePort Service
We will create a NodePort service for our nginx deployment. This will allow us to access the nginx application from outside the cluster. Use the following command to create the NodePort service:
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get svc

3. Deploying KEDA Event Scaler
KEDA (Kubernetes-based Event Driven Autoscaler) is designed to integrate seamlessly with multiple event sources (Scalers) and uses Custom Resources (CRDs) to define the desired scaling behavior and parameters. By utilizing KEDA, we can dynamically scale Kubernetes Deployments or StatefulSets based on specific events. This means that KEDA will monitor your application and automatically adjust the number of instances based on the incoming workload, ensuring optimal resource usage.
3.1 Scaler
A Scaler in KEDA is responsible for detecting whether a deployment should be scaled up or down based on a specific event source. For this tutorial, we'll use a Cron Scaler to demonstrate auto-scaling. The Cron Scaler allows us to schedule scaling actions based on time, which is particularly useful for applications with predictable usage patterns, such as those that are heavily used during weekdays and less so on weekends.
In our example, we'll configure the Cron Scaler to scale out our application during a specified period and then scale it back down after that period. This approach ensures that resources are utilized efficiently and cost-effectively.
3.2 ScaledObject
A ScaledObject is a Kubernetes Custom Resource Definition (CRD) that defines the relationship between an event source and a specific workload (such as a Deployment or StatefulSet) for scaling purposes. It contains the necessary information for KEDA to monitor the specified event source and trigger scaling actions based on the defined criteria.
To deploy the ScaledObject, we need to create a configuration file, typically named scaledobjects.yaml. This file will include the details of the event source that KEDA will monitor and the scaling parameters for our sample application.
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: nginx-deployment
namespace: default
spec:
scaleTargetRef:
apiVersion: apps/v1 # Optional. Default: apps/v1
kind: Deployment # Optional. Default: Deployment
name: nginx # Mandatory. Must be in the same namespace as the ScaledObject
pollingInterval: 5 # Optional. Default: 5 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
minReplicaCount: 0 # Optional. Default: 0
maxReplicaCount: 5 # Optional. Default: 100
fallback: # Optional. Section to specify fallback options
failureThreshold: 3 # Mandatory if fallback section is included
replicas: 1 # Mandatory if fallback section is included
advanced: # Optional. Section to specify advanced options
restoreToOriginalReplicaCount: true # Optional. Default: false
horizontalPodAutoscalerConfig: # Optional. Section to specify HPA related options
name: keda-hpa-nginx # Optional. Default: keda-hpa-{scaled-object-name}
behavior: # Optional. Use to modify HPA's scaling behavior
scaleDown:
stabilizationWindowSeconds: 600
policies:
- type: Percent
value: 100
periodSeconds: 15
triggers:
- type: cron
metadata:
# Required
timezone: Asia/Kolkata # The acceptable values would be a value from the IANA Time Zone Database.
start: 30 * * * * # Every hour on the 30th minute
end: 45 * * * * # Every hour on the 45th minute
desiredReplicas: "5"
Let us explain the above
apiVersion and kind
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
apiVersion: Specifies the API version of the KEDA Custom Resource Definition (CRD). Here, it'skeda.sh/v1alpha1.kind: Specifies the type of Kubernetes resource being created. In this case, it's aScaledObject.
metadata
metadata:
name: nginx-deployment
namespace: default
name: The name of theScaledObject. It is namednginx-deployment.namespace: Specifies the Kubernetes namespace where thisScaledObjectis deployed. Here, it'sdefault.
spec
The spec section defines the behavior and settings for the ScaledObject.
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nginx
scaleTargetRef: Specifies the target Kubernetes resource that KEDA will scale.apiVersion: The API version of the target resource. Here, it'sapps/v1. This field is optional and defaults toapps/v1.kind: The type of resource to be scaled. It is aDeploymentby default.name: The name of the target resource. It must be in the same namespace as theScaledObject. Here, it'snginx.
pollingInterval: 5
cooldownPeriod: 300
minReplicaCount: 0
maxReplicaCount: 5
pollingInterval: Optional. The interval (in seconds) at which KEDA checks the event source. Default is 5 seconds.cooldownPeriod: Optional. The period (in seconds) to wait before scaling down after the last trigger. Default is 300 seconds.minReplicaCount: Optional. The minimum number of replicas for the target resource. Default is 0.maxReplicaCount: Optional. The maximum number of replicas for the target resource. Default is 100.
fallback:
failureThreshold: 3
replicas: 1
fallback: Optional. Defines fallback behavior if the scaling fails.failureThreshold: Mandatory if the fallback section is included. The number of consecutive failures before fallback behavior is triggered.replicas: Mandatory if the fallback section is included. The number of replicas to scale to in case of failure.
advanced:
restoreToOriginalReplicaCount: true
horizontalPodAutoscalerConfig:
name: keda-hpa-nginx
behavior:
scaleDown:
stabilizationWindowSeconds: 600
policies:
- type: Percent
value: 100
periodSeconds: 15
advanced: Optional. Defines advanced scaling options.restoreToOriginalReplicaCount: Optional. If true, restores the original replica count when scaling is no longer needed. Default is false.horizontalPodAutoscalerConfig: Optional. Configures the Horizontal Pod Autoscaler (HPA) related options.name: Optional. The name of the HPA object. Defaults tokeda-hpa-{scaled-object-name}.behavior: Optional. Defines the HPA's scaling behavior.scaleDown: Defines the behavior for scaling down.stabilizationWindowSeconds: The period (in seconds) to stabilize scaling down actions.policies: Specifies the policies for scaling down.type: The type of policy. Here, it'sPercent.value: The value for the policy. Here, it's 100%, meaning scaling down by 100%.periodSeconds: The period (in seconds) within which the policy applies. Here, it's 15 seconds.
triggers
triggers:
- type: cron
metadata:
timezone: Asia/Kolkata
start: 30 * * * *
end: 45 * * * *
desiredReplicas: "5"
triggers: Defines the events that trigger scaling actions.type: The type of scaler. Here, it'scron.metadata: Contains the specific configuration for the cron trigger.timezone: The timezone in which the cron trigger should run. It must be a value from the IANA Time Zone Database. Here, it'sAsia/Kolkata.start: The cron expression defining when the scaling should start. Here, it’s every hour on the 30th minute.end: The cron expression defining when the scaling should end. Here, it’s every hour on the 45th minute.desiredReplicas: The desired number of replicas during the specified period. Here, it’s set to "5".
Here we have used Cron scaler as a trigger event. The above ScaledObject Custom Resource is used to define how KEDA will scale our application and what the triggers are. The minimum replica count is set to 0 and the maximum replica count is 5.
Let’s create the ScaledObject using the below command.
kubectl apply -f scaledobjects.yaml
Key Parameters in Cron Trigger
The Cron trigger, which is a type of event source in KEDA, contains the following important parameters:
timezone: Specifies the time zone for the cron schedule. It must be one of the acceptable values from the IANA Time Zone Database. You can find the list of timezones here.start: A cron expression indicating when the scaling should start.end: A cron expression indicating when the scaling should end.desiredReplicas: The number of replicas to scale the resource to during the period defined by thestartandendcron expressions.
Once the ScaledObject is created, the KEDA controller automatically syncs the configuration and starts watching the deployment nginx created above. KEDA seamlessly creates a HPA (Horizontal Pod Autoscaler) object with the required configuration and scales out the replicas based on the trigger-rule provided through ScaledObject (in this case it is Cron expression).
4. Testing Auto-Scaling with Event Scaler
Once the ScaledObject is created for an application with a relevant trigger, KEDA will start monitoring our application. We can check the status of ScaledObjects using the below command.
kubectl get scaledobjects

As we can see above in the image our ScaledObject is deployed successfully with a minimum replica count of 0 and a maximum replica count of 3 which we have specified in our ScaledObject definition. Once the event is triggered then KEDA will scale out our application automatically. Let’s check the KEDA logs to monitor the events.
We can use the below command to list the KEDA pods.
kubectl get pods -n keda
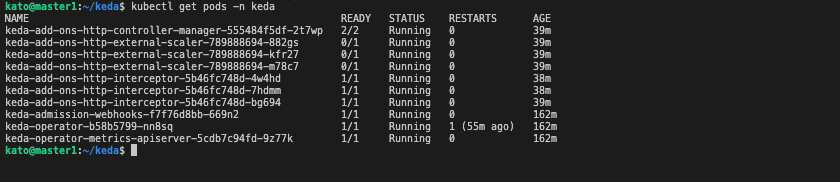
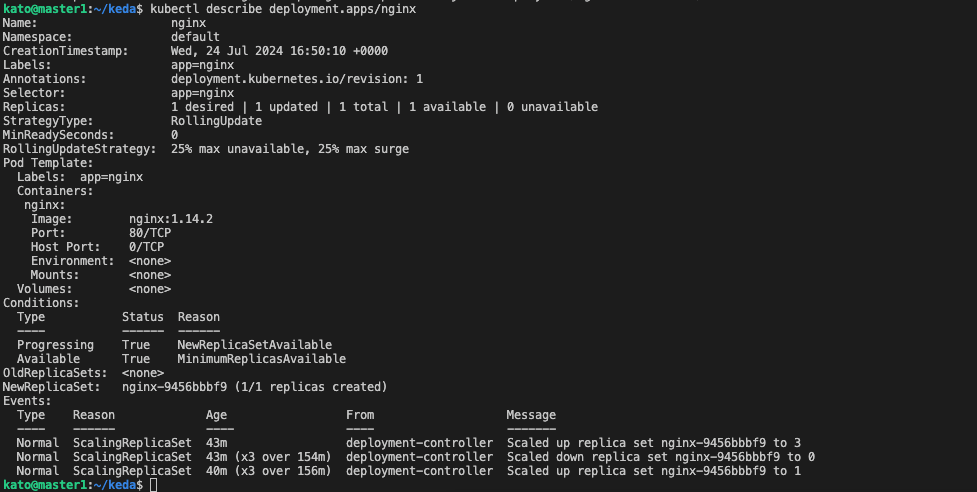
Once the operator is successfully deployed the nginx application is scaled down to 0 as you can see on the events shown above .
5. Deploying HTTP Scaler
In the previous section, we explored how to scale our application based on events using KEDA. However, what if we have an application that doesn’t generate events but relies solely on HTTP traffic? How can we scale such applications?
There are two primary methods to scale applications based on HTTP traffic using KEDA:
Using Prometheus Scaler: This method involves creating scaling rules based on metrics related to HTTP events.
Using KEDA HTTP Add-on: This method directly leverages HTTP traffic to determine scaling needs.
In this section, we will focus on the KEDA HTTP Add-on.
5.1 Install HTTP Add-on
The KEDA HTTP Add-on allows Kubernetes users to automatically scale their applications up and down, including scaling to and from zero, based on incoming HTTP traffic. This add-on provides a more direct and efficient way to handle HTTP-based scaling compared to relying solely on metrics.
KEDA doesn’t include an HTTP scaler by default, so it needs to be installed separately. To install the HTTP Add-on on your Kubernetes cluster, execute the following command:
helm install http-add-on kedacore/keda-add-ons-http --namespace keda
5.2 Defining an Autoscaling Strategy for HTTP Traffic
With KEDA and the HTTP Add-on installed, we can now define an autoscaling strategy specifically for HTTP traffic. For demonstration purposes, we will delete the previously deployed ScaledObject. Note that in a production environment, you wouldn’t need to delete existing ScaledObject configurations, as different scaling strategies can be applied to different applications simultaneously. However, to keep this demonstration simple, we'll remove the previously deployed ScaledObject to focus on our HTTP traffic scaling example.
Deleting the Previously Deployed ScaledObject
To delete the previously deployed ScaledObject, follow these steps:
Get the Name of the Deployed ScaledObject: First, identify the name of the deployed
ScaledObjectusing the following command:kubectl get scaledobject
Then delete the ScaledObject using the below command.
kubectl delete scaledobject nginx-deployment
Let’s now start defining the new ScaledObject for HTTP Trigger. The KEDA HTTP add-on exposes a CRD where we can describe how our application should be scaled. Let’s create a new file with the name “scaledobjects-http.yaml” with the below contents.
kind: HTTPScaledObject
apiVersion: http.keda.sh/v1alpha1
metadata:
name: nginx-http-scaledobject
spec:
host: http://192.168.1.60:30661/
targetPendingRequests: 1
scaleTargetRef:
deployment: nginx
service: nginx
port: 80
replicas:
min: 0
max: 3
The above code defines a ScaledObject of type HTTPScaledObject. It will listen to the requests which come from http://192.168.1.60:30661/ . The minimum replica count is set to 0 and the maximum replica count is 3.
Let’s now deploy the above ScaledObject using the below command.
kubectl apply -f scaledobjects-http.yaml
When we deploy the above ScaledObject, our application will be scaled down to 0. This is because we have set the minimum replica count to 0.
6. Testing Auto-Scaling with HTTP Scaler
A Kubernetes Service called keda-add-ons-http-interceptor-proxy was created automatically when we installed the Helm chart for HTTP-add-on.

For autoscaling to work appropriately, the HTTP traffic must route through the above service first. We can use kubectl port-forward to test this quickly in our local setup.
kubectl port-forward svc/keda-add-ons-http-interceptor-proxy -n keda 30661:8080
Here, connections made to local port 30661 are forwarded to port 8080 of the keda-add-ons-http-interceptor-proxy service that is running in Kubernetes Cluster.
Let’s now make some requests to our application pretending the request comes in .
curl localhost:30661 -H 'Host: http://192.168.1.60:30661/'
If we inspect the pods, we will notice that the deployment was scaled to a single replica. So when we routed the traffic to the KEDA’s service, the interceptor keeps track of the number of pending HTTP requests that haven’t had a reply yet.

Understanding KEDA HTTP Scaler and Deployment
In this section, we will delve into how KEDA's HTTP scaler operates and how to deploy it for handling HTTP traffic. The HTTP scaler is designed to dynamically adjust the number of replicas of a deployment based on the incoming HTTP requests. This ensures efficient resource usage and optimal performance.
How KEDA HTTP Scaler Works
The KEDA HTTP scaler periodically checks the size of the queue of the HTTP interceptor and stores these metrics. The KEDA controller then monitors these metrics and scales the number of replicas up or down as required. For example, if a single request is pending, the KEDA controller will scale the deployment to a single replica to handle that request.
Here’s a brief overview of the process:
Metric Collection: The scaler collects metrics related to HTTP request queues.
Monitoring and Scaling: The KEDA controller uses these metrics to determine the number of replicas needed.
Automatic Scaling: Based on the metrics, the KEDA controller automatically scales the deployment up or down to meet the current demand.
Network Accessibility
By default, the Service created by the KEDA HTTP Add-on will be inaccessible over the network from outside the Kubernetes cluster. While it is possible to access the service using the kubectl port-forward command, this approach is not suitable for production environments. Instead, it is recommended to use an ingress controller to route external traffic to the KEDA interceptor service. This setup provides a more robust and scalable solution for managing HTTP traffic in a production setting.
Conclusion
In this article, we explored KEDA and its key concepts, focusing on its ability to scale applications based on various event triggers. We demonstrated its functionality by scaling a sample NGINX application within a Kubernetes cluster. By combining Kubernetes pod auto-scaling with the Cluster Autoscaler, we can achieve efficient on-demand scaling with minimal cloud costs. This combination ensures that our applications can handle varying workloads efficiently while optimizing resource usage and reducing expenses.
KEDA’s HTTP scaler, in particular, offers a powerful solution for applications that rely heavily on HTTP traffic, providing seamless scaling capabilities based on real-time traffic patterns. By implementing KEDA and its HTTP Add-on, you can ensure your applications are both performant and cost-effective, adapting dynamically to changing traffic demands.
Cheers 🍻
Subscribe to my newsletter
Read articles from Bruno Gatete directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Bruno Gatete
Bruno Gatete
DevOps and Cloud Engineer Focused on optimizing the software development lifecycle through seamless integration of development and operations, specializing in designing, implementing, and managing scalable cloud infrastructure with a strong emphasis on automation and collaboration. Key Skills: Terraform: Skilled in Infrastructure as Code (IaC) for automating infrastructure deployment and management. Ansible: Proficient in automation tasks, configuration management, and application deployment. AWS: Extensive experience with AWS services like EC2, S3, RDS, and Lambda, designing scalable and cost-effective solutions. Kubernetes: Expert in container orchestration, deploying, scaling, and managing containerized applications. Docker: Proficient in containerization for consistent development, testing, and deployment. Google Cloud Platform: Familiar with GCP services for compute, storage, and machine learning.