How to Attach a Default Lakehouse to a Notebook in Fabric
 Sandeep Pawar
Sandeep PawarI wrote a blog post a while ago on mounting a lakehouse (or generally speaking a storage location) to all nodes in a Fabric spark notebook. This allows you to use the File API file path from the mounted lakehouse.
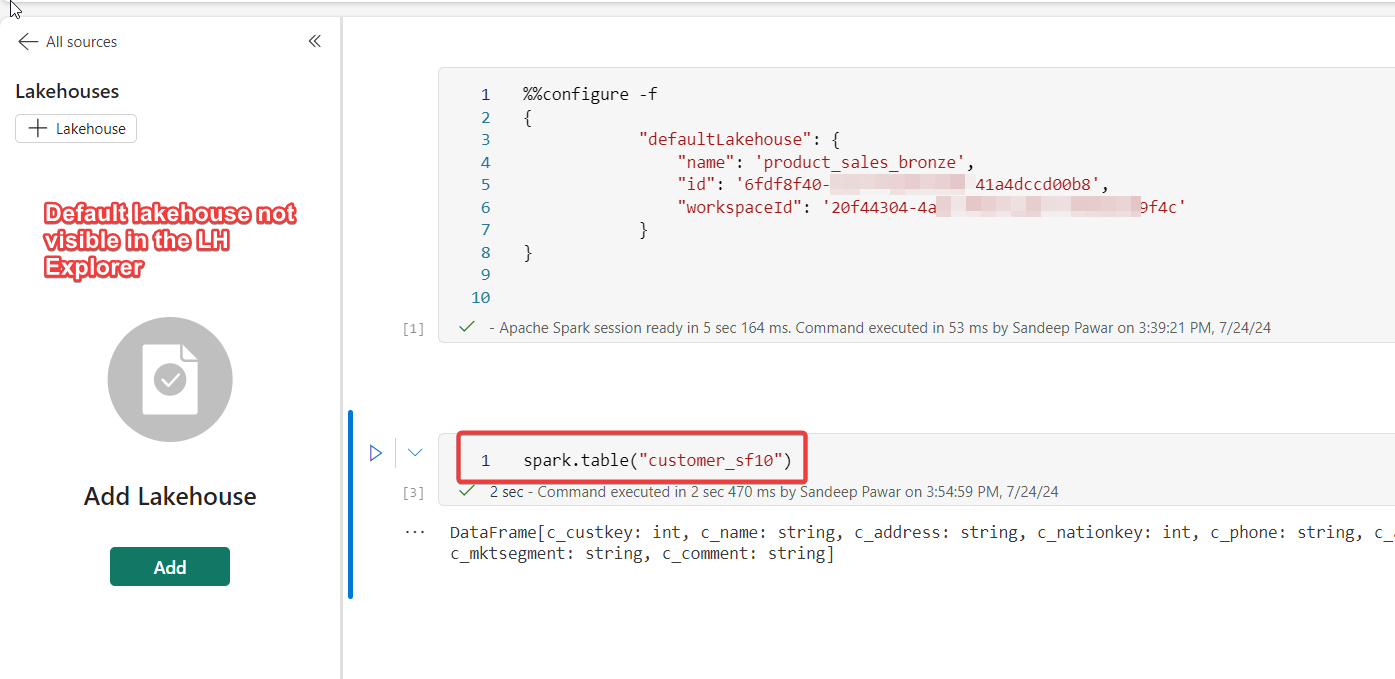
Mounting a lakehouse using mssparkutils.fs.mount() doesn't define the default lakehouse of a notebook. To do so, you can use the configure magic as below:
%%configure -f
{
"defaultLakehouse": {
"name": '<name of the lakehouse>',
"id": '<lakehouse id>',
"workspaceId": '<workspace id of the lakehouse>'
}
}
This should be the first cell in your notebook. It will define the default lakehouse for the scope of the session. Once configured, you can query the Tables and files from Files section using the relative path for spark or the File API path. Note that unlike the GUI option of adding the lakehouse, you will not see the default lakehouse in the lakehouse explorer. You will not see the lakehouse to notebook lineage either in the workspace.
Notes:
Configure magic can be parameterized to use it in pipelines
You can add other configuration options as well for spark, default environments etc.
If you are running the notebook in a pipeline, pipeline will fail if configure magic is not on the first cell
The %%configure used in mssparkutils.notebook.run is going to be ignored but used in %run notebook will continue executing
I will also add that beyond being able to use the local filesystem, I don't think adding a default lakehouse does anything more. If you don't add a default lakehouse, you can always use the abfs paths in spark to query any table or file from any workspace you have access to.
The limitation of this method is that since the configure magic has to be the first cell, you can't programmatically assign the lakehouse id in the configure json. I thought of using the update
notebookitem API (see below) but it didn't work. I got 200 response code so the request went through successfully but the default lakehouse didn't get attached. There is an update notebook definition API which may work but it needs payload to be a base64 encoded ipynb. So the user will have to first get the current notebook definition using an API, edit the json to addmetadata.trident.lakehouseproperties, encode again and send it in a POST request - too much work. Let me know if you get it to work.## THIS CODE DIDN'T WORK FOR ME - AS OF 7/26/2024 ## import sempy.fabric as fabric payload = { "displayName": "<notebookname>", #keep the name of the existing notebook otherwise the API call fails "metadata": { "trident": { "lakehouse": { "default_lakehouse": "xxxxxxxxxxx", "default_lakehouse_name": "xxxxxxxxxx", "default_lakehouse_workspace_id": "xxxxxxxxx" } } } } client = fabric.FabricRestClient() wsid= "xxxxxxxxxx" nbid="xxxxxxxx" client.patch(f"v1/workspaces/{wsid}/items/{nbid}", json=payload) #response code 200
Subscribe to my newsletter
Read articles from Sandeep Pawar directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Sandeep Pawar
Sandeep Pawar
Principal Program Manager, Microsoft Fabric CAT helping users and organizations build scalable, insightful, secure solutions. Blogs, opinions are my own and do not represent my employer.