Building a Top-tier AI/ML Project (Template)
 Rahul Saini
Rahul Saini
Let’s Dive in!
Code: https://github.com/RahulSainy/mlprojects.git
Project Overview
In this project, we aim to:
Ingest a dataset containing student performance data from sources like Kaggle.
Prepare and preprocess the data to ensure it's suitable for machine learning models.
Train multiple regression models to predict student math scores.
Integrate the best-performing model into a Flask web application to enable real-time predictions.
Develop a user-friendly interface where users can input student attributes and receive instant predictions.
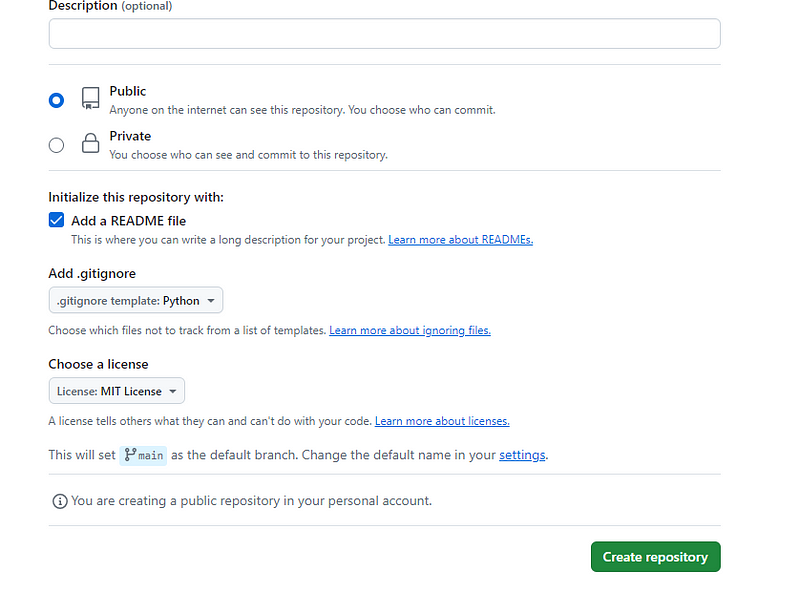
Creating a Repository on GitHub
Create a new repository on GitHub using your preferred name.
Select options: Check the box for README.md, .gitignore, and choose Python in .gitignore.
Add license: Choose MIT License, a simple and permissive license with conditions only requiring copyright and license notices preservation.
Setting Up Conda Virtual Environment
Open the terminal/command line in your editor
Create aConda virtual environment named venv with Python 3.8:
conda create -p venv python=3.8 -y
- A venv folder will be created in a local environment (venv/) where we’ll manage all Python packages.
Activate the virtual environment:
conda activate venv/
Initializing Git Repository
Run-
git init
Create a README.md file: Create a Markdown file (README.md) and add your project description, e.g., ## End to End ML Projects Template for me.
Now let’s add our first commit:
git add README.md
git commit -m "First commit with README.md"
We can check our status with
git status
It shows you’re on the main branch and have 1 commit ahead of origin/main.
Working with Git Branches
Now check out our branch to dev since we are starting so we can make development changes without affecting the production with —
git branch -m dev
git branch: This command is used for various branch-related operations like listing, creating, deleting, and renaming branches.
-m: This flag stands for “move” and is used to rename a branch.
dev: This is the new name you want to give to the current branch.
Connecting to Remote Repository
Link your local repository to the remote on GitHub:
Replace <your git repo URL> with your actual GitHub repository URL. Now let’s use the repo we created
git remote add origin <your git repo url>
Verify the remote repository:
To check out changes —
git remote -v
it prints
origin https://github.com/RahulSainy/mlprojects (fetch)
origin https://github.com/RahulSainy/mlprojects (push)
Pushing Changes to the Remote Repository
- Push your changes to the dev branch:
git push -u origin dev
This uploads your commits to GitHub. Check outputs for confirmation and a link to create a pull request on GitHub.
PS: If push fails, configure Git to log in using your Git account: Git First-Time Setup.
Pull updates from the remote repository
git pull
Setting Up Project Development
Create necessary files: Create requirements.txt for listing pip dependencies and setup.py for project configuration.
requirements.txt: List all necessary packages for your project.
setup.py: Configure Python package installation and build for ML project packaging and deployment.
requirements.txt
pandas
numpy
seaborn
-e .
setup.py
# Importing necessary functions from the setuptools library
from setuptools import find_packages, setup
# Importing List type from the typing module to specify return type
from typing import List
# !important to include "-e ." in requirements.txt to trigger setup.py correctly
HYPEN_E_DOT = "-e ."
def get_requirements(file_path: str) -> List[str]:
'''
Reads the requirements from a specified file and returns them as a list.
'''
requirements = []
# Opening the specified file_path (like 'requirements.txt')
with open(file_path) as file_obj:
# Reading all the lines from requirements.txt into a list
requirements = file_obj.readlines()
# Stripping newline characters from each requirement
requirements = [req.strip() for req in requirements]
# Removing "-e ." if it's there to prevent setup.py from running into itself
if HYPEN_E_DOT in requirements:
requirements.remove(HYPEN_E_DOT)
return requirements
# Configuration settings for setup.py
setup(
# Name of the project
name='mlproject',
# Version of the project
version='0.1',
# Author of the project
author='Rahul Saini',
# Finding all packages to include (looking for directories with __init__.py files)
packages=find_packages(),
# Specifying the minimum required Python version
python_requires='>=3.7',
# List of dependencies to install, obtained from requirements.txt
install_requires=get_requirements('requirements.txt'),
# Using the get_requirements function to fetch requirements from requirements.txt
)
And then in the terminal run
pip install -r requirements.txt
This will install all the dependency calls in the setup.py
Now again run
git add.
git commit -m "setup.py and requiremets.txt files added"
git push -u origin dev
Now we will try and understand the complete folder structure and files of our program
“Right now we are going to create with the manual approach for better understanding at last of the section we will use a file called template.py that will do this automatically”
So start with creating a folder file structure as
src/
└── __init__.py "This will be the main file where the control starts"
Let’s create a components folder This will have all the modules we use
src/
|── __init__.py
|── components/ “This will be having all the modules we use ”
| |── data_ingestion.py “This will be having all the data we want to get from different sources and handle them”
| |── data_transformation.py “This will contain modules that help in handling data features like one hot encoding, labeling…”
| |── model_trainer.py “all different types of model and their parameters”
| |── __init__.py
Now we create pipelines
src/
|── __init__.py
|── components
|── pipeline/
| |── train_pipline.py "This will contain the training code"
| |── predict_pipline.py "This will be testing or predicting"
| └── __init__.py "as always the landing file by default"
exception.py-
Even if a statement or expression is syntactically correct, it may cause an error when an attempt is made to execute it
import sys # System-specific parameters and functions
import logging
# learn form https://docs.python.org/3/tutorial/errors.html
def error_message_detail(error, error_detail: sys):
'''
This function is used to get the error message with the line number and file name
The exc_info() method returns a tuple containing three elements: exc_type, exc_value, and exc_traceback. In this case, we only need the exc_traceback as it contains the line number and file name.
'''
_, _, exc_tb = error_detail.exc_info()
file_name = exc_tb.tb_frame.f_code.co_filename # Get the file name
error_message = f"Error occured in python script name [{0}] line number [{1}] with error message [{2}]".format(
file_name, exc_tb.tb_lineno, str(error)
)
return error_message
class CustomException(Exception):
'''This class is used to create custom exception'''
def __init__(self, error_message, error_detail: sys):
'''
This function is used to initialize the custom exception
super() is a built-in function that allows you to call a method from a parent class. In this case, it is being used inside the __init__ method of a class that is inheriting from the Exception class.
'''
self.error_detail = error_detail
self.error_message = error_message_detail(error_message, error_detail = error_detail)
super().__init__(
self.error_message
) # since we are inheriting form the Exception class we need to call the super class constructor
# when we raise custom exception it will inherit the custom exception class and the error message will be displayed
def __str__(self):
'''
This function is used to return the error message when we raise the exception
'''
#when we raise the exception it will return the error message to print it
return f"{self.error_message}"
logger.py
you can think of the logger.py file as a digital diary or a secret agent that keeps track of what’s happening in your code. Just like a diary, it records important events and messages that occur
# Lern from https://docs.python.org/3/library/logging.html
import logging
import os
from datetime import datetime
# Create a custom logger
LOG_FILE = f"{datetime.now().strftime('%d-%m-%Y__%H_%M_%S')}.log"
logs_path = os.path.join(os.getcwd(), "logs", LOG_FILE)
# logs path is the path where the logs will be stored
os.makedirs(logs_path, exist_ok=True)
# exist_ok= true if the directory already exists still create the directory
# log_file_path is the path where the log file will be stored
LOG_FILE_Path = os.path.join(logs_path, LOG_FILE)
#logging.basicConfig is used to configure the root logger it is built-in function
logging.basicConfig(
filename=LOG_FILE_Path,
datefmt="%d-%m-%Y %H:%M:%S",
format="[%(asctime)s]- %(clientip)-15s - %(user)-8s - %(lineno)d %(name)s - %(levelname)s %(message)s",
# example print [2022-01-01 12:34:56] 192.168.0.1 admin - 10 logger - INFO This is a log message.
level=logging.INFO,
)
# # Only to test the logger
# if __name__ =="__main__":
# logging.info("This is an info message")
# # it creates the output as [16-07-2024 05:11:45] - 28 root - INFO This is an info message
The output will be visible in the logs folder with time-stamp files. You can also add code in exception.py and run it to test if it is showing the logs
In exception.py — add and run
# to test logger.py from exception.py
from src.logger import logging # Import the logging module
if __name__ =="__main__":
try:
a = 1/0
except Exception as e:
logging.info("Divide by Zero error")
raise CustomException(e,sys)
Now to push changes to git-hub run
git add .
git commit -m "logging and exception added"
git push -u origin dev
git pull
Starting to build ML
We are going to build the Ml Model for students' performance Indicator to be beginner-friendly
Student Performance Indicator
The life cycle of Machine learning Project
Understanding the Problem Statement
Data Collection
Data Checks to perform
Exploratory data analysis
Data Pre-Processing
Model Training
Choose the best model
So let’s start understanding our problem statement -
This project aims to analyze how student performance, specifically test scores, is influenced by gender, ethnicity, parental level of education, lunch habits, and participation in test preparation courses.
Data Collection
Dataset Source - https://www.kaggle.com/datasets/spscientist/students-performance-in-exams?datasetId=74977
The data consists of 8 columns and 1000 rows.
Save this data in the folder
data/
├── stud.csv
Exploratory data analysis
EDA, or Exploratory Data Analysis, refers to analyzing and analyzing information units to uncover styles, pick out relationships, and gain insights.
Let's start with creating a .ipynb file
notebooks/
├── EDA.ipynb “For Data Analysis”
“Since we are here to learn the professional way you can follow the code added here to get a reference as you can try with your project and we focus on building the structure, I’m including the code files here for easy access to copy and run the code.
PS: you can try your code this is just an easy example
Data Pre-Processing
👉🏻 You can refer to my article — How to perform EDA on any Dataset EASY Way for a detailed explanation and code
to see our dataset's first 5 rows-
df.head()
Model Training
notebooks/
├── EDA.ipynb
└── ModelTrainig.ipynb “for model Training”
You can refer to my article where I have performed Model training to better understand and also follow the code
Now we have our normal old ipynb file which we are going to transform into a professionally structured format
We will distribute code from our modelTrainer.ipyb notebook to data_ingestion.py, data_transformation.py, model_trainer.py
In a working environment, a separate big data team can do all the ETL (extract, transform, and load), but you have to read that transformed data source. So We will do Data Ingestion - read data and split it to train and test and then in Data Transformation of all the data we have like if there is a categorical feature, numerical feature thing will be handled.
src/
|── __init__.py
|── components/
| |── data_ingestion.py
| |── data_transformation.py
| |── model_trainer.py
| |── __init__.py
Data Ingestion
data_ingestion.py
import os
import sys # for using custom exception
from src.exception import CustomException
from src.logger import logging
import pandas as pd
from sklearn.model_selection import train_test_split
from dataclasses import dataclass # for data validation
# In datIngestion there should be some inputs like where to save the data, what is the data type, etc
# so for this we will create DataIngestion class
@dataclass # decorator that will call the DataIngestion class
#The @dataclass decorator automatically generates the __init__, __repr__, and __eq__ methods for the class.
# DataIngestionConfig class will have input as data_path, data_type, test_size:
class DataIngestionConfig:
train_data_path: str = os.path.join(
"artifacts", "train.csv"
) # default path for train data
test_data_path: str = os.path.join(
"artifacts", "test.csv"
) # default path for test data
raw_data_path: str = os.path.join("data", "data.csv") # default path for raw data
class DataIngestion:
def __init__(self, config: DataIngestionConfig):
self.ingestion_config = (
DataIngestionConfig()
) # object of DataIngestionConfig this will get the values of class (file paths) in the variable
def intiate_data_ingestion(self):
"""
This function is used to intiate and read the data from the raw data path
"""
logging.info("Data Ingestion Started")
try:
df = pd.read_csv("data/stud.csv")
logging.info("Dataset read successfully")
os.makedirs(
os.path.dirname(self.ingestion_config.train_data_path), exist_ok=True
) # create a directory if it does not exist
# save the data in the raw data path
df.to_csv(self.ingestion_config.raw_data_path, index=False, header=True)
logging.info("Train test split initiated")
# split the data into train and test
train_set, test_set = train_test_split(df, test_size=0.2, random_state=42)
# save the data in the train and test data path
train_set.to_csv(
self.ingestion_config.train_data_path, index=False, header=True
)
test_set.to_csv(
self.ingestion_config.test_data_path, index=False, header=True
)
logging.info("Train test split completed")
return (
self.ingestion_config.train_data_path,
self.ingestion_config.test_data_path,
) # return the train and test data set for data transformation
except Exception as e:
raise CustomException(
e, sys
) # raise the custom exception if any error occurs
# to test the data_ingestion.py
if __name__ == '__main__':
data_ingestion = DataIngestion(DataIngestionConfig())
data_ingestion.intiate_data_ingestion()
Now we have a structured approach to streamline data preparation tasks, enhancing the efficiency and reliability of machine learning workflows by automating data ingestion, storage, and initial processing steps.
Now again run
git add .git commit -m "Data Ingestion"git push -u origin devgit pull
Data transformation
Now we will distribute our ipynb file code to DataTransformation.py for handling missing values, creating the pipeline,encoding and scaling
dataTransformation.py
import os
import sys
from src.logger import logging
from src.exception import CustomException
from dataclasses import dataclass
import numpy as np
import pandas as pd
from sklearn.compose import ColumnTransformer # for data transformation
from sklearn.impute import SimpleImputer # for handling missing values
from sklearn.pipeline import Pipeline # for creating the pipeline
from sklearn.preprocessing import (
OneHotEncoder,
StandardScaler,
) # for encoding and scaling
from src.utils import save_object
# data transformation config class will have input as train_data_path, preprocessor_obj_path
@dataclass # The @dataclass decorator automatically generates the __init__, __repr__, and __eq__ methods for the class.
class DataTransformationConfig:
preprocessor_obj_file_path: str = os.path.join("artifacts/preprocessor.pkl")
class DataTransformation:
def __init__(self):
self.data_transformation_config = (
DataTransformationConfig()
) # object of DataTransformationConfig this will get the values of class (file paths
def get_data_transformer_object(self):
"""
This function is used to for the data transformation and create all the pickel files inorder to perform standard scaling and one hot encoding
"""
logging.info("Data Transformation Started")
try:
# since we already did EDA, we know all the data analysis
numerical_columns = ["reading score", "writing score"]
categorical_columns = [
"gender",
"race/ethnicity",
"parental level of education",
"lunch",
"test preparation course",
]
# create the pipeline for numerical columns on training data
num_pipline = Pipeline(
steps=[
# impute - means fill the missing values
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]
)
logging.info("Numerical columns standard scaling completed")
# create the pipeline for categorical columns on training data
categorical_pipeline = Pipeline(
steps=[
# impute - means fill the missing values
("imputer", SimpleImputer(strategy="most_frequent")),
# since while performing EDA we know there were very less number of categorical columns so we can use one hot encoding otherwise we can use label encoding or targetguided encoding
("onehot", OneHotEncoder()),
("scaler",StandardScaler(with_mean=False))
]
)
logging.info(f"Categorical columns: {categorical_columns}")
logging.info(f"Numerical columns: {numerical_columns}")
# combine the numerical and categorical columns pipeline
preprocessor = ColumnTransformer(
transformers=[
("num_pipline", num_pipline, numerical_columns),
("cat_pipline", categorical_pipeline, categorical_columns),
]
)
return preprocessor
except Exception as e:
raise CustomException(
e, sys
) # raise the custom exception if any error occurs
def initiate_data_transformation(self,train_path,test_path):
try:
train_df=pd.read_csv(train_path)
test_df=pd.read_csv(test_path)
logging.info("Train and Test data read successfully")
logging.info("Obtaining preprocessing object")
preprocessing_obj = self.get_data_transformer_object()
target_column_name = "math score"
numerical_columns = ["reading score", "writing score"]
input_feature_train_df = train_df.drop(columns=[target_column_name], axis=1)
target_feature_train_df = train_df[target_column_name]
input_feature_test_df=test_df.drop(columns=[target_column_name],axis=1)
target_feature_test_df=test_df[target_column_name]
logging.info(
f"Applying preprocessing object on training dataframe and testing dataframe."
)
# The fit_transform method is used to both fit a preprocessing object to the training data and transform the training data using that object.
input_feature_train_arr=preprocessing_obj.fit_transform(input_feature_train_df)
# The transform method is used to apply the learned parameters of the preprocessing object to new data.
input_feature_test_arr=preprocessing_obj.transform(input_feature_test_df)
# The reason for using fit_transform on the training data and transform on the test data is to prevent data leakage. Data leakage occurs when information from the test data is used to inform the model training process, leading to overly optimistic performance estimates.
train_arr = np.c_[
input_feature_train_arr, np.array(target_feature_train_df)
]
test_arr = np.c_[input_feature_test_arr, np.array(target_feature_test_df)]
logging.info("Save the preprocessed data in the train and test data path")
# save the data in the train and test data path using utils.py save
save_object(
file_path=self.data_transformation_config.preprocessor_obj_file_path,
obj=preprocessing_obj,
)
return (
train_arr,
test_arr,
self.data_transformation_config.preprocessor_obj_file_path,
)
except Exception as e:
raise CustomException(e, sys)
utils.py - our first utility code to save file in pickel format
import os
import sys
import numpy as np
import pandas as pd
import dill
import pickle
from src.exception import CustomException
def save_object(file_path, obj):
"""
This function is used to save the object in the pickle format
:param obj: object to save
:param file_path: file path to save the object
"""
try:
dir_path = os.path.dirname(file_path)
os.makedirs(dir_path, exist_ok=True)
with open(file_path, "wb") as file_obj:
pickle.dump(obj, file_obj)
except Exception as e:
raise CustomException(e, sys)
In dataIngestion.py we add and call the data tranformation to connect it and run
from src.components.data_transformation import DataTransformation
from src.components.data_transformation import DataTransformationConfig
#Our previous code……….
# to test the data_ingestion.py
if __name__ == '__main__':
data_ingestion = DataIngestion(DataIngestionConfig())
# data_ingestion.intiate_data_ingestion()
train_data, test_data = data_ingestion.intiate_data_ingestion()
#to test data_transformation.py
# initiate the data transformation
data_transformation = DataTransformation()
data_transformation.initiate_data_transformation(train_data, test_data)
The described workflow encapsulates a structured approach to preparing data for machine learning models, focusing on automation, flexibility, and reliability in data preprocessing tasks. By separating data ingestion and transformation concerns, the pipeline facilitates modular and maintainable machine learning workflows.
Now again run
git add .git commit -m "Data Tranformation"git push -u origin devgit pull
Model Training
Now we will provide models and run over our train and test data in model trainer.py
import os
import sys
from dataclasses import dataclass
from sklearn.ensemble import (
AdaBoostRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
import os
import sys
from sklearn.ensemble import (
AdaBoostRegressor,
GradientBoostingRegressor,
RandomForestRegressor,
)
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
from sklearn.neighbors import KNeighborsRegressor
from sklearn.tree import DecisionTreeRegressor
from xgboost import XGBRegressor
# from catboost import CatBoostRegressor
from src.exception import CustomException
from src.logger import logging
from src.utils import save_object, evaluate_models
@dataclass
class ModelTrainerConfig:
trained_model_file_path = os.path.join("artifacts", "model.pkl")
class ModelTrainer:
def __init__(self):
self.model_trainer_config = ModelTrainerConfig()
def initiate_model_trainer(self, train_array, test_array):
"""
This function initiates the model training process by calling the necessary functions.
X_train = train_array[:,:-1] selects all rows (:) and all columns except the last one (:-1) from the train_array. This means it is selecting all the features or input data for training.
y_train = train_array[:,-1] selects all rows (:) and the last column (-1) from the train_array. This means it is selecting the target or output data for training.
X_test = test_array[:,:-1] selects all rows (:) and all columns except the last one (:-1) from the test_array. This means it is selecting all the features or input data for testing.
y_test = test_array[:,-1] selects all rows (:) and the last column (-1) from the test_array. This means it is selecting the target or output data for testing.
"""
try:
logging.info("Spliting Training And Testing Input Data")
# Splitting the data into training and testing data using a tuple unpacking method
X_train, y_train, X_test, y_test = (
train_array[:, :-1],
train_array[:, -1],
test_array[:, :-1],
test_array[:, -1],
)
models = {
"Random Forest": RandomForestRegressor(),
"Decision Tree": DecisionTreeRegressor(),
"Gradient Boosting": GradientBoostingRegressor(),
"Linear Regression": LinearRegression(),
"K-Neighbors Classifier": KNeighborsRegressor(),
"XGBRegressor": XGBRegressor(),
"AdaBoost Classifier": AdaBoostRegressor(),
# "CatBoost Regressor": CatBoostRegressor(verbose=False), # some issue with catboost
}
# Parameters for the models to be used in the model training process
params={
"Decision Tree": {
'criterion':['squared_error', 'friedman_mse', 'absolute_error', 'poisson'],
# 'splitter':['best','random'],
# 'max_features':['sqrt','log2'],
},
"Random Forest":{
# 'criterion':['squared_error', 'friedman_mse', 'absolute_error', 'poisson'],
# 'max_features':['sqrt','log2',None],
'n_estimators': [8,16,32,64,128,256]
},
"Gradient Boosting":{
# 'loss':['squared_error', 'huber', 'absolute_error', 'quantile'],
'learning_rate':[.1,.01,.05,.001],
'subsample':[0.6,0.7,0.75,0.8,0.85,0.9],
# 'criterion':['squared_error', 'friedman_mse'],
# 'max_features':['auto','sqrt','log2'],
'n_estimators': [8,16,32,64,128,256]
},
"Linear Regression":{},
"XGBRegressor":{
'learning_rate':[.1,.01,.05,.001],
'n_estimators': [8,16,32,64,128,256]
},
# "CatBoosting Regressor":{
# 'depth': [6,8,10],
# 'learning_rate': [0.01, 0.05, 0.1],
# 'iterations': [30, 50, 100]
# }, "AdaBoost Regressor":{
'learning_rate':[.1,.01,0.5,.001],
# 'loss':['linear','square','exponential'],
'n_estimators': [8,16,32,64,128,256]
}
}
# Evaluating the model function in utils.py
# This function will run the model and return the model report
model_report: dict = evaluate_models(
X_train=X_train,
y_train=y_train,
X_test=X_test,
y_test=y_test,
models=models,
param=params)
# Sorting the model report in descending order from dict
best_model_score = max(sorted(model_report.values()))
best_model_name = list(model_report.keys())[
list(model_report.values()).index(best_model_score)
]
best_model = models[best_model_name]
if best_model_score < 0.6:
raise CustomException("No best model found", sys)
logging.info(
f"Best Model found on both trainig and testing dataset: {best_model_name}"
)
# Saving the best model in the trained_model_file_path as model.pikel
save_object(
file_path=self.model_trainer_config.trained_model_file_path,
obj=best_model,
)
predicted = best_model.predict(X_test)
r2_square = r2_score(y_test, predicted)
return r2_square
except Exception as e:
raise CustomException(e, sys)
In utils.py add
from sklearn.metrics import r2_score
from sklearn.model_selection import GridSearchCV
# ...Existing Code
def evaluate_models(X_train, y_train,X_test,y_test,models,param):
"""
This function is used to evaluate the model
:param X_train: training data
:param y_train: training target
:param X_test: testing data
:param y_test: testing target
:param models: models to evaluate
:return: model_report
"""
try:
report = {}
for i in range(len(list(models))):
model = list(models.values())[i]
para=param[list(models.keys())[i]]
gs = GridSearchCV(model,para,cv=3)
gs.fit(X_train,y_train)
model.set_params(**gs.best_params_)
model.fit(X_train,y_train)
#model.fit(X_train, y_train) # Train model
y_train_pred = model.predict(X_train)
y_test_pred = model.predict(X_test)
train_model_score = r2_score(y_train, y_train_pred)
test_model_score = r2_score(y_test, y_test_pred)
report[list(models.keys())[i]] = test_model_score
return report
except Exception as e:
raise CustomException(e, sys)
add in data_ingestion.py this code
from src.components.model_trainer import ModelTrainerConfig
from src.components.model_trainer import ModelTrainer
# exsiting code ......
# to test the model_trainer.py
if __name__ == '__main__':
data_ingestion = DataIngestion(DataIngestionConfig())
# data_ingestion.initiate_data_ingestion()
train_data,test_data=data_ingestion.initiate_data_ingestion()
#to test data_transformation.py
# initiate the data transformation
data_transformation=DataTransformation()
train_arr,test_arr,_=data_transformation.initiate_data_transformation(train_data,test_data)
#to test model_trainer.py
# initiate the model trainer
model_trainer = ModelTrainer()
print(model_trainer.initiate_model_trainer(train_arr, test_arr))
The described workflow simplifies the process of training multiple regression models, evaluating their performance, and saving the best model for deployment. By integrating with earlier stages of data ingestion and transformation, it creates a complete pipeline for developing and deploying machine learning models efficiently.
Buildig the UI and Backend to intract with model
We will now build a user interface so user can interact with model prediction using their own data and we are going to modularise it
src/
|── init.py
|── components/
|── pipeline/
||──predict_pipline.py "to run the test data over model and predict"
|──templates/ "important to create this as the name"'
||──index.html "default page"
||──home.html "form page"
└──app.py "flask file"
**predict_pipline.py -**Provides functionality to load the trained model and preprocessing pipeline, and make predictions on user input data.
import os
import sys
import pandas as pd
from src.exception import CustomException
from src.logger import logging
from src.utils import load_object
class PredictPipeline:
def __init__(self):
pass
def predict(self, features):
try:
model_path = os.path.join("artifacts", "model.pkl")
preprocessor_path = os.path.join('artifacts', 'preprocessor.pkl')
print("Before Loading")
model = load_object(file_path=model_path)
preprocessor = load_object(file_path=preprocessor_path)
print("After Loading")
data_scaled = preprocessor.transform(features)
preds = model.predict(data_scaled)
return preds
except Exception as e:
raise CustomException(e, sys)
class CustomData:
def __init__(
self,
gender: str,
race_ethnicity: str,
parental_level_of_education,
lunch: str,
test_preparation_course: str,
reading_score: int,
writing_score: int,
):
self.gender = gender
self.race_ethnicity = race_ethnicity
self.parental_level_of_education = parental_level_of_education
self.lunch = lunch
self.test_preparation_course = test_preparation_course
self.reading_score = reading_score
self.writing_score = writing_score
def get_data_as_data_frame(self):
try:
custom_data_input_dict = {
"gender": [self.gender],
"race/ethnicity": [self.race_ethnicity], # Fixed key name
"parental level of education": [self.parental_level_of_education], # Fixed key name
"lunch": [self.lunch],
"test preparation course": [self.test_preparation_course], # Fixed key name
"reading score": [self.reading_score], # Fixed key name
"writing score": [self.writing_score], # Fixed key name
}
return pd.DataFrame(custom_data_input_dict)
except Exception as e:
raise CustomException(e, sys)
app.py - Implements the Flask web application to handle user interface interactions and backend processing.
from flask import Flask, render_template, request
import pandas as pd
from src.pipeline.predict_pipline import PredictPipeline, CustomData
app = Flask(__name__)
@app.route("/")
def index():
return render_template("index.html")
@app.route("/predictdata", methods=["GET", "POST"])
def predict_datapoint():
if request.method == "GET":
return render_template("home.html")
else:
data = CustomData(
gender=request.form.get("gender", "female"), # Provide default value
race_ethnicity=request.form.get("race_ethnicity", "group A"), # Provide default value
parental_level_of_education=request.form.get("parental_level_of_education", "high school"), # Provide default value
lunch=request.form.get("lunch", "standard"), # Provide default value
test_preparation_course=request.form.get("test_preparation_course", "none"), # Provide default value
reading_score=float(request.form.get("reading_score", 0)), # Provide default value
writing_score=float(request.form.get("writing_score", 0)) # Provide default value
)
pred_df = data.get_data_as_data_frame()
print(pred_df)
predict_pipeline = PredictPipeline()
results = predict_pipeline.predict(pred_df)
return render_template("home.html", results=results[0])
if __name__ == "__main__":
app.run(host="0.0.0.0", debug=True)
Developing the UI
|──templates/ #important to create this as the name
||──index.html #default page
|└──home.html #form page
index.html - Landing page with a link to navigate to the prediction form.
<h1>Welcome to the Student Marks prediction</h1>
<a href="predictdata">Go to Prediciton Form</a>
home.html - Form page where users can input their data for prediction.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Student Exam Performance Indicator</title>
<style>
body {
font-family: 'Arial', sans-serif;
line-height: 1.6;
background-color: #f8f9fa;
padding: 20px;
}
.login {
max-width: 600px;
margin: 0 auto;
background-color: #fff;
padding: 30px;
border-radius: 8px;
box-shadow: 0 0 10px rgba(0,0,0,0.1);
}
h1 {
color: #007bff;
text-align: center;
margin-bottom: 30px;
}
h2 {
text-align: center;
margin-top: 30px;
color: #6c757d;
}
fieldset {
border: 1px solid #ddd;
padding: 20px;
border-radius: 6px;
margin-bottom: 20px;
}
legend {
font-size: 1.2em;
font-weight: bold;
margin-bottom: 10px;
}
.form-group {
margin-bottom: 20px;
}
.form-label {
display: block;
margin-bottom: 5px;
font-weight: bold;
color: #495057;
}
.form-control {
width: 100%;
padding: 10px;
border: 1px solid #ced4da;
border-radius: 4px;
font-size: 16px;
}
select.form-control {
appearance: none;
padding-right: 30px; /* to accommodate the arrow */
background: transparent;
background-image: url('data:image/svg+xml;utf8,<svg xmlns="http://www.w3.org/2000/svg" width="12" height="12" viewBox="0 0 24 24" fill="none" stroke="%23495057" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"><polyline points="6 9 12 15 18 9"></polyline></svg>');
background-repeat: no-repeat;
background-position-x: calc(100% - 10px);
background-position-y: center;
}
.btn-primary {
padding: 12px 24px;
background-color: #007bff;
color: #fff;
border: none;
border-radius: 4px;
cursor: pointer;
font-size: 16px;
transition: background-color 0.3s;
}
.btn-primary:hover {
background-color: #0056b3;
}
</style>
</head>
<body>
<div class="login">
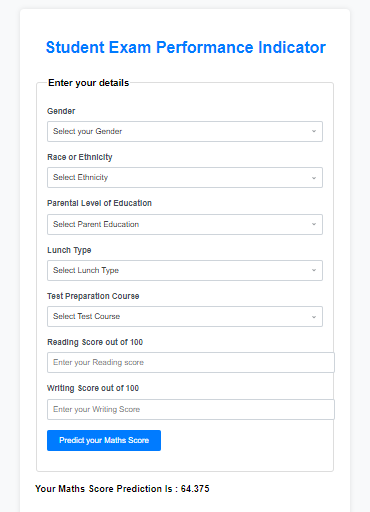
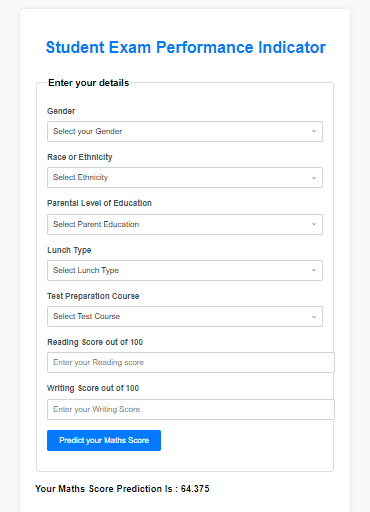
<h1>Student Exam Performance Indicator</h1>
<form action="{{ url_for('predict_datapoint')}}" method="post">
<fieldset>
<legend>Enter your details</legend>
<div class="form-group">
<label class="form-label" for="gender">Gender</label>
<select class="form-control" id="gender" name="gender" required>
<option value="" disabled selected>Select your Gender</option>
<option value="male">Male</option>
<option value="female">Female</option>
</select>
</div>
<div class="form-group">
<label class="form-label" for="ethnicity">Race or Ethnicity</label>
<select class="form-control" id="ethnicity" name="ethnicity" required>
<option value="" disabled selected>Select Ethnicity</option>
<option value="group A">Group A</option>
<option value="group B">Group B</option>
<option value="group C">Group C</option>
<option value="group D">Group D</option>
<option value="group E">Group E</option>
</select>
</div>
<div class="form-group">
<label class="form-label" for="parental_education">Parental Level of Education</label>
<select class="form-control" id="parental_education" name="parental_level_of_education" required>
<option value="" disabled selected>Select Parent Education</option>
<option value="associate's degree">Associate's Degree</option>
<option value="bachelor's degree">Bachelor's Degree</option>
<option value="high school">High School</option>
<option value="master's degree">Master's Degree</option>
<option value="some college">Some College</option>
<option value="some high school">Some High School</option>
</select>
</div>
<div class="form-group">
<label class="form-label" for="lunch">Lunch Type</label>
<select class="form-control" id="lunch" name="lunch" required>
<option value="" disabled selected>Select Lunch Type</option>
<option value="free/reduced">Free/Reduced</option>
<option value="standard">Standard</option>
</select>
</div>
<div class="form-group">
<label class="form-label" for="test_course">Test Preparation Course</label>
<select class="form-control" id="test_course" name="test_preparation_course" required>
<option value="" disabled selected>Select Test Course</option>
<option value="none">None</option>
<option value="completed">Completed</option>
</select>
</div>
<div class="form-group">
<label class="form-label" for="reading_score">Reading Score out of 100</label>
<input class="form-control" id="reading_score" type="number" name="reading_score" placeholder="Enter your Reading score" min="0" max="100" />
</div>
<div class="form-group">
<label class="form-label" for="writing_score">Writing Score out of 100</label>
<input class="form-control" id="writing_score" type="number" name="writing_score" placeholder="Enter your Writing Score" min="0" max="100" />
</div>
<div class="form-group">
<input class="btn btn-primary" type="submit" value="Predict your Maths Score" />
</div>
</fieldset>
</form>
<h3>
Your Maths Score Prediction Is : <b>{{results}}</b>
</h3>
</div>
</body>
</html>
This structured approach allows for seamless integration of machine learning model predictions into a web application. Users can interact with the prediction model through a user-friendly interface, inputting their own data and receiving predicted results in real-time. The modular design ensures maintainability and scalability, facilitating future enhancements or updates to the prediction pipeline or user interface.
In this blog series, we embarked on a journey to develop a machine learning-powered web application for predicting student performance based on various attributes. Let's recap the key components and achievements of our project:
1. Data Ingestion and Preparation
Data Ingestion: We started by ingesting the student performance dataset from a CSV file using Python's pandas library. The dataset included attributes like gender, ethnicity, parental education level, lunch type, test preparation course, and scores in reading, writing, and math.
Train-Test Split: Utilizing scikit-learn, we split our dataset into training and testing sets to facilitate model training and evaluation.
2. Data Transformation and Preprocessing
Pipeline Creation: We defined a data transformation pipeline to handle missing values, perform one-hot encoding for categorical variables, and standardize numerical features using scikit-learn's
PipelineandColumnTransformerclasses.Persistence: Saved the preprocessing pipeline (
preprocessor.pkl) for future use in transforming new data for predictions.
3. Model Training and Selection
Model Selection: Experimented with various regression models including Random Forest, Decision Tree, Gradient Boosting, Linear Regression, K-Nearest Neighbors, and XGBoost.
Evaluation: Evaluated each model's performance using R² score on the testing dataset to select the best-performing model.
4. Integration with Flask for Web Application
Flask Backend: Integrated the trained model into a Flask web application (
app.py) to create a user interface for predictions.User Interface: Developed HTML templates (
index.htmlandhome.html) to allow users to input student attributes and receive predictions on the student's math score.
5. Prediction Pipeline and Deployment
Prediction Pipeline: Implemented a
PredictPipelineclass (predict_pipeline.py) to load the trained model and preprocessing pipeline, preprocess user input, and generate predictions.Real-time Predictions: Enabled users to interact with the prediction model through a web form, providing instant predictions based on their input data.
6. Conclusion
Achievements: Successfully developed a machine learning web application capable of predicting student math scores based on demographic and educational attributes.
Impact: Empowered users, such as educators or administrators, to gain insights into student performance trends and make data-driven decisions to support student success.
Future Enhancements (you can do ): Opportunities exist to enhance the application by integrating more sophisticated models, improving user interface design, and scaling for larger datasets or additional features.
In conclusion, our journey from data ingestion to model deployment showcases the power of combining machine learning with web technologies to solve real-world problems. By leveraging Python libraries like pandas, scikit-learn, and Flask, we created a robust and user-friendly application that bridges the gap between data science and practical application in education.
Subscribe to my newsletter
Read articles from Rahul Saini directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by