Implementing Efficient Mobile OCR: A Developer’s Guide
 Idera Dev Tools
Idera Dev Tools
Optical Character Recognition/OCR technology is widely used in various industries today. It has totally transformed the way we extract textual information from documents. OCR basically allows us to automatically extract text (printed or handwritten text) from scanned documents, PDF files, and images. With the advent of mobile OCR data capture, OCR has become even more accessible and integral to a variety of modern apps. Fortunately, various OCR SDKs and APIs are available for iOS and Android, making it even easier to integrate OCR functionality in mobile apps. Filestack is one such tool.
Filestack offers a specialized SDK for both iOS and Android. You can use these SDKs to integrate Filestack file management capabilities seamlessly into your mobile apps. Filestack also offers advanced OCR capabilities through its processing API, which you can use for mobile data extraction.
In this comprehensive guide, we’ll:
Discuss the implementation of efficient OCR data capture using Filestack’s mobile SDK.
Provide tips and techniques to optimize OCR for various data types, enhance capture accuracy, and process extracted data on mobile devices.
Setting Up Filestack’s Mobile OCR SDK
Filestack offers powerful OCR functionality as a part of its intelligence services. We can use it through Filestack processing API.
Filestack’s OCR uses advanced machine learning models and neural networks to recognize and extract text accurately. Moreover, Filestack OCR is backed by advanced document detection and pre-processing solutions. This enables the OCR engine to detect complex documents, such as rotated, folded, and wrinkled documents.
The illustration below shows how Filestack OCR software works:
Integration Steps for Filestack iOS SDK
Here, we’ll show you the basic steps for integrating Filestack iOS SDK into your apps. This SDK essentially integrates Filestack’s powerful file uploader in your iOS app. We can use this uploader for mobile scanning and to upload scanned documents for OCR. We’ll implement the OCR functionality through Filestack Processing API.
First, we’ll install the iOS SDK through CocoaPods.
gem install cocoapods
Now, we need to integrate FilestackSDK into our Xcode project (remember to specify it in your Podfile):
source 'https://github.com/CocoaPods/Specs.git'platform :ios, '16.0'
use_frameworks!
target '<Your Target Name>' do
pod 'Filestack', '~> 2.0'
end
Next, run the following command:
pod install
Here is how you can present the Filestack File Picker/Uploader in your app:
// Create `Config` object.
let config = Filestack.Config.builder
.with(appUrlScheme: "YOUR-APP-URL-SCHEME")
.with(availableCloudSources: [.dropbox, .googledrive, .googlephotos, .customSource])
.with(availableLocalSources: [.camera, .photoLibrary, .documents])
.build()
// Instantiate the Filestack `Client` by passing an API key obtained from https://dev.filestack.com/
// If your account does not have security enabled, then you can omit this parameter or set it to nil.
let client = Filestack.Client(apiKey: filestackAPIKey, config: config)
// Store options for your uploaded files.
// Here we are saying our storage location is S3 and access for uploaded files should be public.
let storeOptions = StorageOptions(location: .s3, access: .public)
// Instantiate picker by passing the `StorageOptions` object we just set up.
let picker = client.picker(storeOptions: storeOptions)
// Optional. Set the picker's delegate.
picker.pickerDelegate = self
// Finally, present the picker on the screen.
present(picker, animated: true)
Output
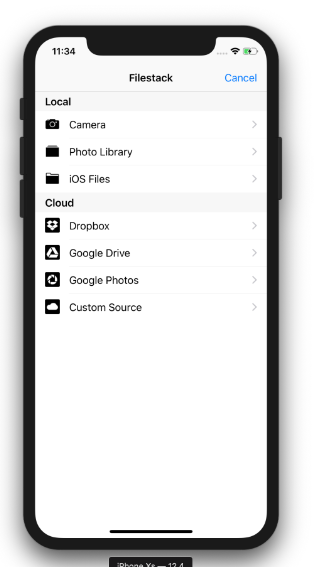
iOS OCR implementation
We can use this CDN URL to implement OCR through Filestack processing API:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL>
Here is an example code for implementing the OCR mobile data extraction in your app:
func performOCRwithProcessingAPI(fileURL: String) {
// Construct the Processing API URL
let processingAPIURL = "https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL>"
// Create the URLRequest
var request = URLRequest(url: URL(string: processingAPIURL)!)
request.httpMethod = "POST"
// Set up the request body with the file URL
let requestBody = ["url": fileURL]
request.httpBody = try? JSONSerialization.data(withJSONObject: requestBody)
// Create a URLSession task to make the API request
let task = URLSession.shared.dataTask(with: request) { (data, response, error) in
// Handle the API response
if let error = error {
print("Error: \(error)")
} else if let data = data {
// Parse and handle OCR results
if let ocrResults = try? JSONSerialization.jsonObject(with: data, options: []) as? [String: Any] {
print("OCR Results: \(ocrResults)")
}
}
}
// Start the URLSession task
task.resume()
}
Integration Steps for Filestack Android SDK
Include the following Filestack Android SDK dependency in your app’s build.gradle file:
implementation 'com.filestack:filestack-android:6.0.0'
Here is how you can set up and configure the Filestack picker in your Android app:
FilestackPicker picker = new FilestackPicker.Builder()
.config(...)
.storageOptions(...)
.config(...)
.autoUploadEnabled(...)
.sources(...)
.mimeTypes(...)
.multipleFilesSelectionEnabled(...)
.displayVersionInformation(...)
.build();
picker.launch(activity); //use an Activity instance to launch a picker
You can then use Filestack OCR URL to perform OCR:
https://cdn.filestackcontent.com/<FILESTACK_API_KEY>/security=p:<POLICY>,s:<SIGNATURE>/ocr/<EXTERNAL_URL/CDN URL>
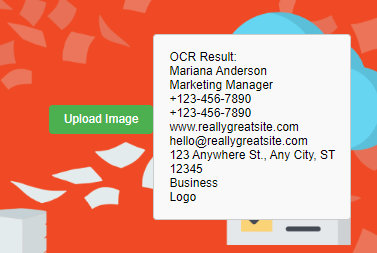
Filestack OCR Demo
Input image

Filestack OCR output
Optimizing Camera Capture for OCR Mobile Data Capture
Here are best practices for optimizing camera capture for physical documents:
Encourage users to avoid shadows, glare, and uneven lighting. This helps ensure the text in the document is clearly visible.
Display indicators for good lighting conditions. Provide feedback if the lighting is too low.
Utilize the device’s accelerometer and gyroscope to detect motion and encourage users to hold the device steady. You can also utilize auto-focus features and Optical image stabilization (OIS) for image stabilization.
Use overlays, such as bounding boxes or edge detection, to help users position the document correctly. This will ensure the document is properly aligned within the frame.
Implement real-time edge detection to detect document borders. Highlight the edges and provide visual feedback if the document isn’t properly within the frame.
Encourage users to capture images at a high resolution to improve OCR accuracy.
Provide guidelines for users to place the document against a contrasting background. This helps avoid blending with surroundings and ensures clear edges.
Use grid lines to assist users with capturing the document from the correct angle to prevent perspective distortion.
Apply pre-processing techniques such as cropping, deskewing, and contrast adjustment. This enhances the image quality and text visibility.
Implementing Real-Time OCR
Here are some techniques to consider to implement real-time OCR:
Capture frames continuously from the camera for instant data capture. Process each frame for text recognition.
Use efficient OCR engines for quick OCR data processing on mobile devices.
Configure OCR to focus only on detected text regions to reduce processing load.
Implement parallel processing to process different stages of the OCR process concurrently. These include image capture, preprocessing, text detection, and recognition. You can also use parallel processing to process large volumes of documents concurrently.
Adjust the frequency of frame processing dynamically, depending on computational load and available resources.
Utilize edge computing to offload heavy OCR processing tasks to nearby edge devices or servers.
Choose OCR systems or engines optimized for mobile and real-time applications.
Apply real-time image preprocessing to improve text visibility and OCR accuracy.
Structured Data Capture
Structured OCR data capture involves extracting specific text from forms and other structured documents. This includes:
Recognizing the document type
Identifying regions of interest/ relevant fields
Extracting the relevant data accurately
We can use template matching to extract data from structured documents. Template matching involves using predefined templates to match the structure of the document. The OCR engine then identifies key areas or regions of interest based on the template.
We can also use text detection and layout analysis techniques to locate fields within a specific document. Then, we can apply OCR to the detected fields to extract text.
It’s also crucial to implement validation rules. These rules help ensure the extracted data is accurate and correct, such as date formats. Using regular expressions and checksums for specific data types is also helpful for data validation.
Specialized OCR Use Cases
OCR has various use cases across different industries. Here are some specialized OCR use cases:
Invoice Scanning and Data Extraction
Extracting data, such as invoice numbers, dates, and vendor details, from invoices is a common task for invoice processing. OCR automates this process by extracting relevant data from invoices accurately. This eliminates the need for manual data entry and reduces human errors.
You can utilize a specialized OCR solution for invoice data extraction. These OCR solutions are specially designed to detect various invoice formats and extract relevant data from different types of invoices.
For example, Filestack OCR can efficiently extract data from invoices.
Business Card Information Capture
Advanced OCR solutions, such as Filestack, can also extract useful details from business cards accurately. These include names, phone numbers, email addresses, and company details.
Businesses can use these automated OCR solutions to directly import useful data into their CRM platforms or contact management systems. This helps with lead management, personalized marketing, and effective communication with clients.
ID Document Scanning and Verification
OCR is also quite helpful in ID card verification. We can use it to extract accurate information from various types of ID cards automatically. These include national IDs, driver’s licenses, and passports. This information can then be used for identity verification processes for security, access control, and registration purposes.
Filestack OCR is designed to efficiently extract relevant information for ID cards.
OCR technology is also widely used for:
Converting scanned documents into machine-readable text data
Reducing manual data entry processes
Digitizing paper documents
Offline OCR Capabilities
We need to perform OCR locally to implement OCR functionality without an internet connection or offline mobile OCR. This allows apps to work even in areas with no internet connectivity.
We can use on-device/user’s device OCR libraries to perform OCR locally. For example, we can use:
Apple’s Vision framework for iOS. The framework includes OCR capabilities that work offline.
Use Google’s ML Kit for Android. It supports on-device text recognition.
It’s also essential to manage offline data and sync it with a server once connectivity is restored. For example, we can store the OCR results locally using local file storage or a database. We also need to implement a queuing mechanism to track data that needs to be synced.
We can use Filestack capabilities to manage and store OCR data.
Optimizing OCR Performance on Mobile
Here are some effective tips and techniques for optimizing OCR performance on mobile:
Resize images before processing to reduce memory consumption. However, it’s crucial to find the right balance between image size and quality. This optimizes performance while improving OCR accuracy.
Use image formats like JPEG or PNG. These formats don’t consume too much memory.
Apply pre-processing techniques to enhance image quality. These can include noise reduction, binarization, adjusting contrast, and applying filters,
Fine-tune API parameters, such as deskew and crop, to optimize OCR performance for different document types.
Implement lazy loading to load images only when required. It’s also recommended to unload images from memory once processing is complete.
Process multiple images in batches to minimize memory overhead.
Manually trigger garbage collection. For example, you can use Java for Android.
Reuse memory for temporary objects instead of allocating and deallocating memory frequently.
Perform OCR in a background thread to keep the main thread responsive.
Configure OCR libraries or engines to use appropriate settings for optimal processing time.
Distribute processing tasks evenly across available CPU cores. This way, we can avoid overloading a single core.
Minimize the frequency of OCR operations. You can use strategies like event-based triggers instead of continuous polling.
Enhancing User Experience
Here’s how you can enhance user experience in your OCR mobile data capture applications:
Keep the OCR interface simple and avoid clutter.
Provide clear instructions on how to capture images for OCR. For example, you can use tooltips and overlays to guide users.
Use bounding boxes to help users position and align the document correctly.
Display a real-time preview of the capture area. Also, consider implementing automatic adjustments to improve the capture quality.
Show progress indicators to inform users that the OCR processing is in progress.
Provide quick feedback on the success or failure of the OCR data capture.
Highlight recognized text or areas in the image to visually display the OCR output.
OCR Security Considerations
Your OCR app may process documents containing sensitive and confidential information. Thus, it’s crucial to implement robust security features to protect user data.
If you’re using Filestack, you get the following security features:
End-to-end encryption
Powerful authentication and authorization mechanisms for API calls
Adherence to GDPR
HTTPS encryption for processing API, including OCR
TLS for encrypting the data transmitted between clients and servers
OAuth authentication
Filestack also supports network isolation. This provides an additional layer of security.
You can also implement Role-Based Access Control to protect OCR data.
Cross-Platform Mobile OCR Considerations
If you’re looking to create cross-platform OCR mobile data capture applications, you can consider using cross-platform frameworks like React Native, Flutter, or Xamarin. These frameworks allow developers to write a single codebase for both platforms (iOS and Android) while accessing native functionality.
Moreover, it’s essential to choose an OCR library or SDK that supports both iOS and Android, such as Tesseract OCR. It’s also recommended to implement the OCR logic into a separate module or service that can be shared across both platforms. This way, any changes to the OCR logic are applied on both platforms without duplication.
Conclusion
OCR technology is widely used in mobile devices (iOS and Android) these days. With various OCR SDKs and libraries for mobile OCR data capture, implementing OCR functionality in mobile devices is even easier.
For example, Filestack offers a specialized SDK for both iOS and Android. With these SDKs, you can seamlessly integrate Filestack file management capabilities and intelligence services (including OCR) into your mobile apps.
In this article, we’ve discussed the implementation of efficient mobile OCR data capture using Filestack’s mobile SDKs. We’ve also explored various techniques for:
Optimizing OCR for various data types
Enhancing capture accuracy
Processing extracted data on mobile devices
FAQs
How does Filestack’s mobile OCR perform in low-light conditions?
Filestack’s OCR SDK includes image enhancement features to improve performance in various lighting conditions. However, optimal lighting will always yield the best results.
Can Filestack’s mobile OCR SDK handle handwritten text?
Yes, the SDK can process handwritten text. However, accuracy may vary depending on the clarity of the handwriting.
How does implementing OCR affect app size and performance?
While OCR functionality can increase app size due to necessary libraries, Filestack’s SDK is optimized for mobile use.
This post was initially published on Filestack's blog.
Subscribe to my newsletter
Read articles from Idera Dev Tools directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Idera Dev Tools
Idera Dev Tools
Idera, Inc.’s portfolio of Developer Tools include high productivity tools to develop applications using powerful and scalable technology stacks.