Perceptron
 CodingSplash
CodingSplash
Introduction
Basic Components of Perceptron Perceptron is a type of artificial neural network, which is a fundamental concept in machine learning. The basic components of a perceptron are:
Input Layer: The input layer consists of one or more input neurons, which receive input signals from the external world or from other layers of the neural network.
Weights: Each input neuron is associated with a weight, which represents the strength of the connection between the input neuron and the output neuron.
Bias: A bias term is added to the input layer to provide the perceptron with additional flexibility in modeling complex patterns in the input data.
Activation Function: The activation function determines the output of the perceptron based on the weighted sum of the inputs and the bias term. Common activation functions used in perceptrons include the step function, sigmoid function, and ReLU function.
Output: The output of the perceptron is a single binary value, either 0 or 1, which indicates the class or category to which the input data belongs.
Training Algorithm: The perceptron is typically trained using a supervised learning algorithm such as the perceptron learning algorithm or backpropagation. During training, the weights and biases of the perceptron are adjusted to minimize the error between the predicted output and the true output for a given set of training examples.
Overall, the perceptron is a simple yet powerful algorithm that can be used to perform binary classification tasks and has paved the way for more complex neural networks used in deep learning today
Types of Perceptron:
Single layer: Single layer perceptron can learn only linearly separable patterns.
Multilayer: Multilayer perceptrons can learn about two or more layers having a greater processing power. The Perceptron algorithm learns the weights for the input signals in order to draw a linear decision boundary
Note:
A machine-based algorithm used for supervised learning of various binary sorting tasks is called Perceptron.
How Does Perceptron Work?
Perceptron is considered a single-layer neural link with four main parameters. The perceptron model begins with multiplying all input values and their weights, then adds these values to create the weighted sum. Further, this weighted sum is applied to the activation function ‘f’ to obtain the desired output. This activation function is also known as the step function and is represented by ‘f
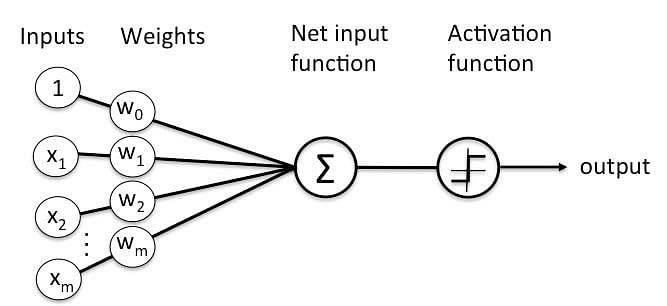
Types of Perceptron models
Single Layer Perceptron model: One of the easiest ANN(Artificial Neural Networks) types consists of a feed-forward network and includes a threshold transfer inside the model. The main objective of the single-layer perceptron model is to analyze the linearly separable objects with binary outcomes. A Single-layer perceptron can learn only linearly separable patterns.
Multi-Layered Perceptron model: It is mainly similar to a single-layer perceptron model but has more hidden layers.
Forward Stage: From the input layer in the on stage, activation functions begin and terminate on the output layer.
Backward Stage: In the backward stage, weight and bias values are modified per the model’s requirement. The backstage removed the error between the actual output and demands originating backward on the output layer.
A multilayer perceptron model has a greater processing power and can process linear and non-linear patterns. Further, it also implements logic gates such as AND, OR, XOR, XNOR, and NOR
Limitation of Perceptron Model – perceptron does not work on non-linear data
1. The output of a perceptron can only be a binary number (0 or 1) due to the hard-edge transfer function.
2. It can only be used to classify the linearly separable sets of input vectors. If the input vectors are non-linear, it is not easy to classify them correctly.
Advantages:
A multi-layered perceptron model can solve complex non-linear problems.
It works well with both small and large input data.
Helps us to obtain quick predictions after the training.
Helps us obtain the same accuracy ratio with big and small data.
Disadvantages:
In multi-layered perceptron model, computations are time-consuming and complex.
It is tough to predict how much the dependent variable affects each independent variable.
The model functioning depends on the quality of training.
Activation Function

Types of Activation Function

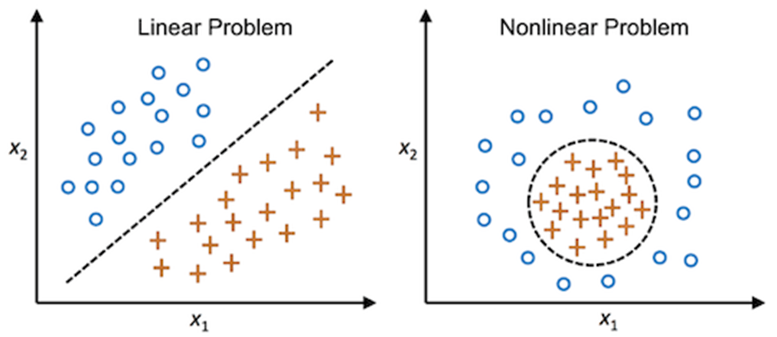
Linear and Non-Linear Separable Data
Linear Separability refers to the data points in binary classification problems which can be separated using linear decision boundary. if the data points can be separated using a line, linear function, or flat hyperplane are considered linearly separable. Linear separability is an important concept in neural networks
When we cannot separate data with a straight line we use Non – Linear SVM. In this, we have Kernel functions. They transform non-linear spaces into linear spaces. It transforms data into another dimension so that the data can be classified.
Subscribe to my newsletter
Read articles from CodingSplash directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
CodingSplash
CodingSplash
I am Data Science student, has a little bit knowledge on Web Development. I also love writing and editing as my hobby. Passionate to explore the world.