Machine Learning : Natural Language Processing -NLP (Bag of words model) (Part 25)
 Md Shahriyar Al Mustakim Mitul
Md Shahriyar Al Mustakim MitulNatural Language Processing (or NLP) is applying Machine Learning models to text and language. Teaching machines to understand what is said in spoken and written word is the focus of Natural Language Processing. Whenever you dictate something into your iPhone / Android device that is then converted to text, that’s an NLP algorithm in action.
You can also use NLP on a text review to predict if the review is a good one or a bad one. You can use NLP on an article to predict some categories of the articles you are trying to segment. You can use NLP on a book to predict the genre of the book. And it can go further, you can use NLP to build a machine translator or a speech recognition system, and in that last example you use classification algorithms to classify language.
Speaking of classification algorithms, most of NLP algorithms are classification models, and they include Logistic Regression, Naive Bayes, CART which is a model based on decision trees, Maximum Entropy again related to Decision Trees, Hidden Markov Models which are models based on Markov processes.
A very well-known model in NLP is the Bag of Words model. It is a model used to preprocess the texts to classify before fitting the classification algorithms on the observations containing the texts.
Types of NLP
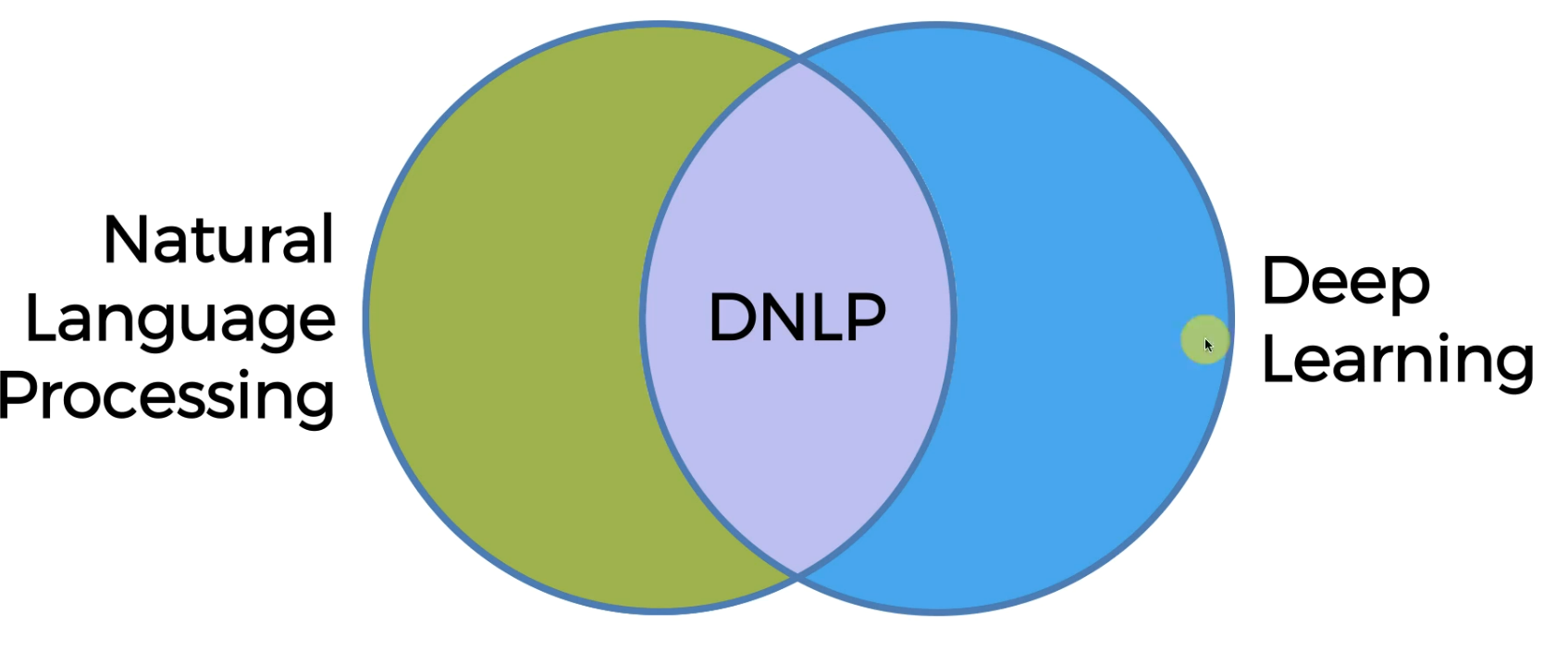
DNLP is deep NLP using Neural networks
Alsowe have sequence to sequence models within DNLP
Classical vs Deep Learning Models
Examples of NLP:
- Earlier examples of creating chatbots

Speech recognition
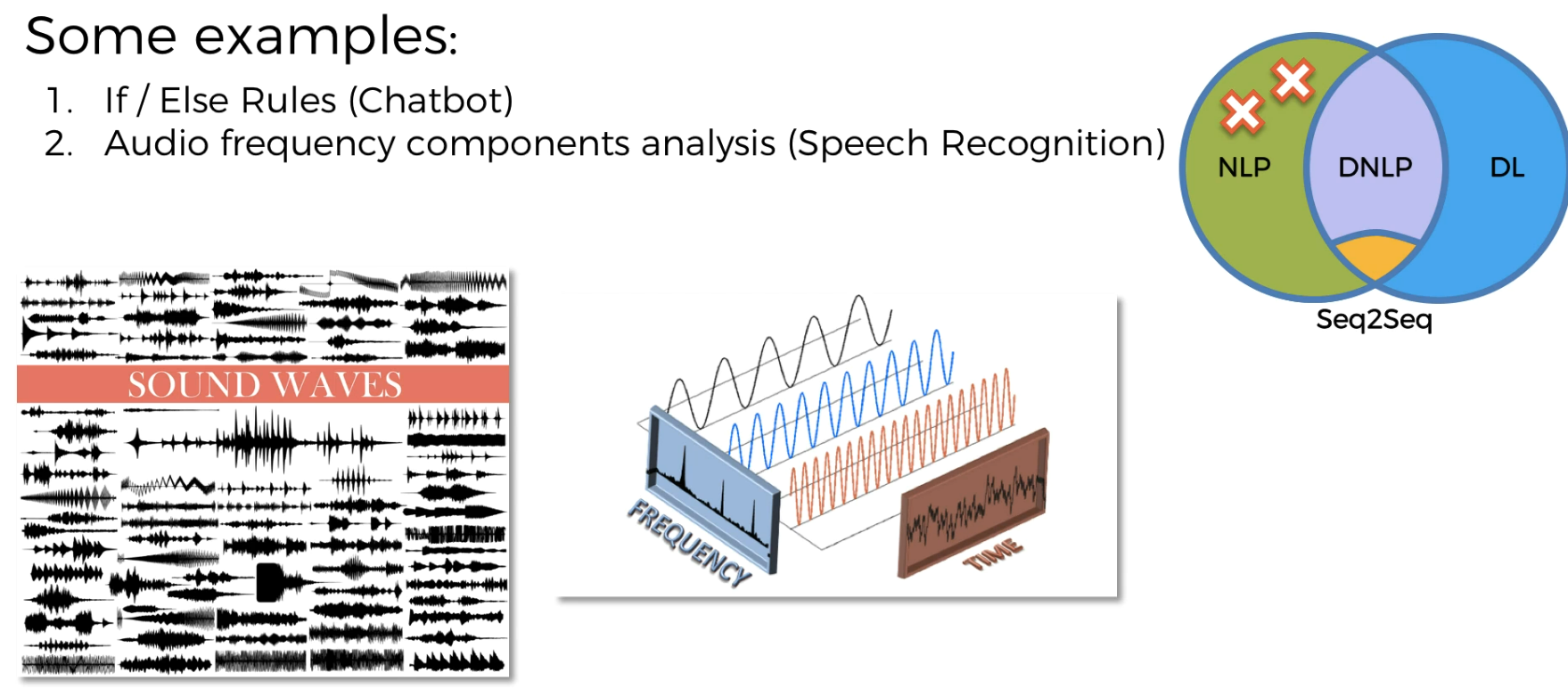
Bag of words
here the model remembers things and use it later. How? Assume a teacher passed comment to students

"Great job" was mentioned to a student who passed the exam. So, he got 1
Also "Try harder next time " was mentioned to a failed student and got 0.
So, this model will keep it in mind that words like great is associated with 1 and words like harder, try are associated with 0
So, if a teacher mentions great, the model will guess the point 1.
Example of Deep NLP
CNN for text recognition(image/video processing)
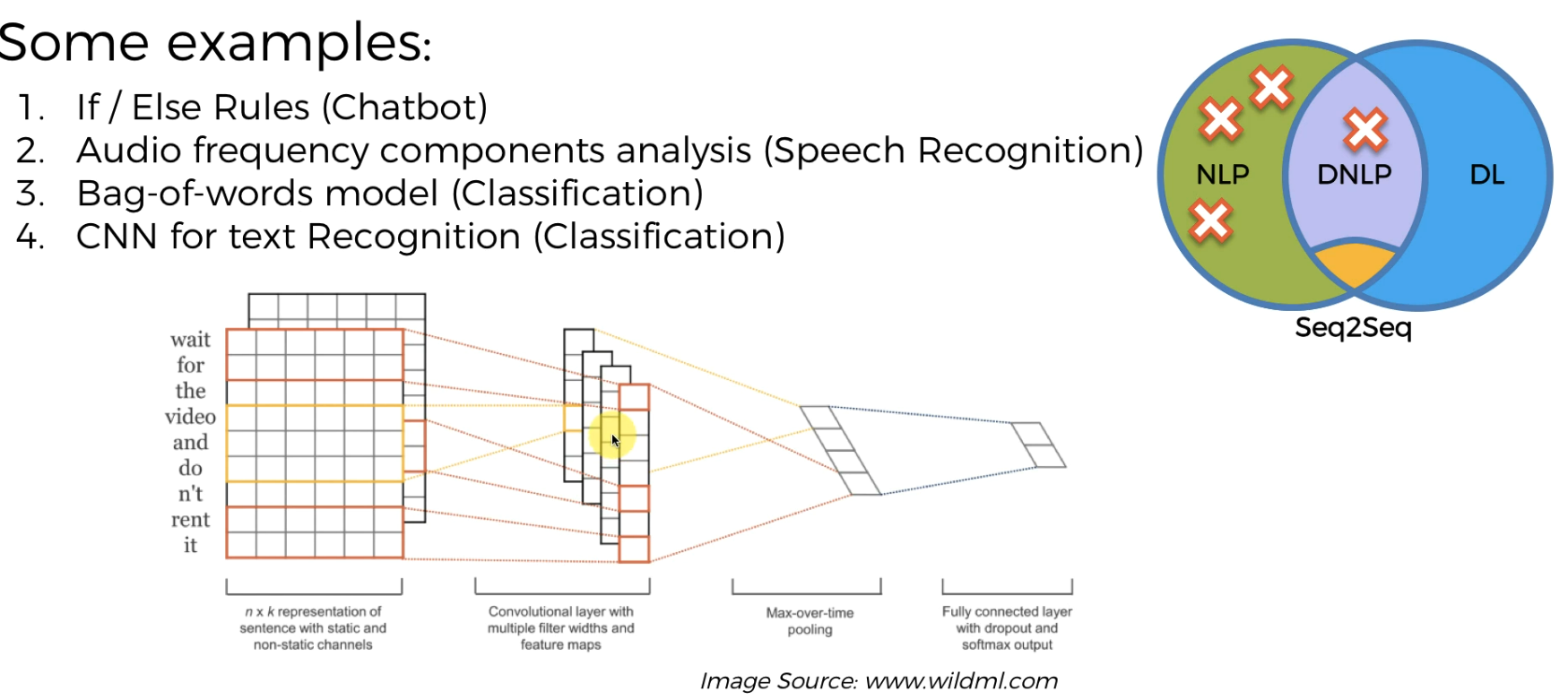
Basically words are turned to matrix and then processed to get our required result.
Example of Seq2seq
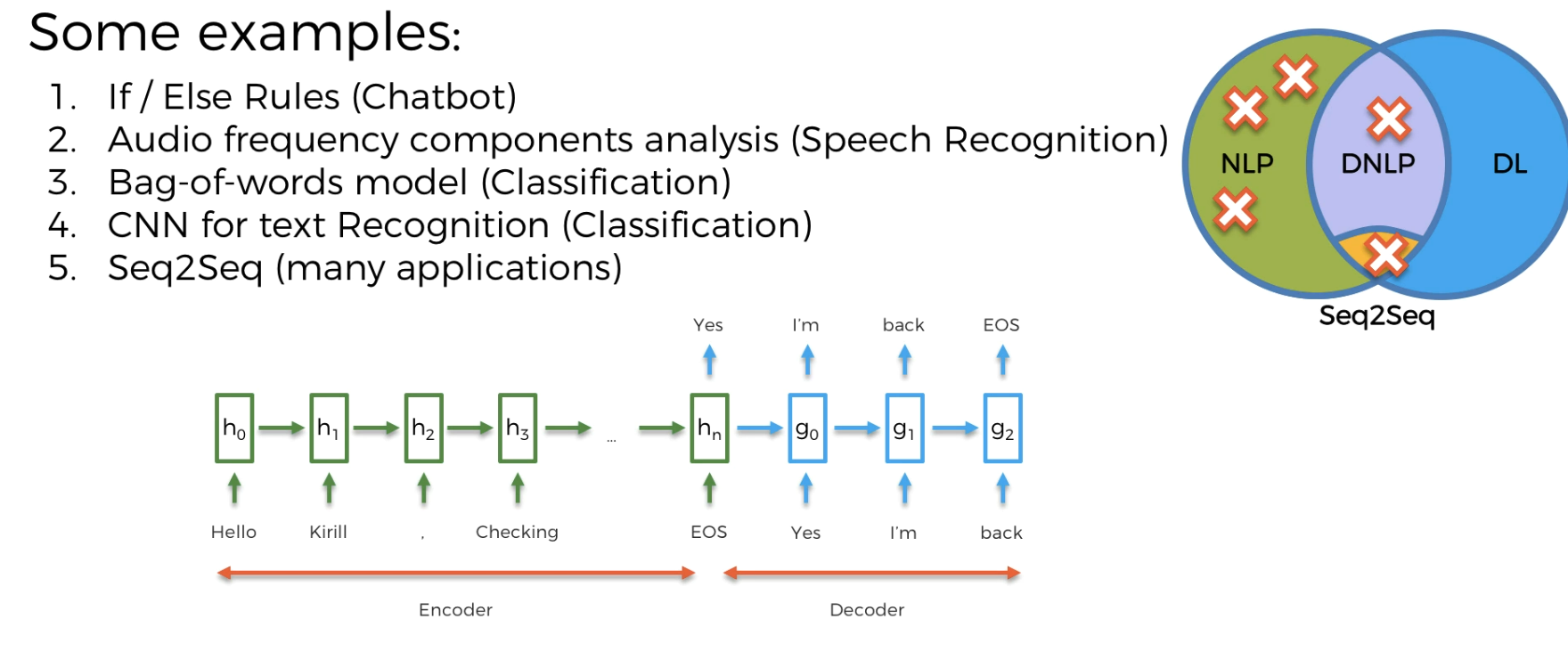
No need to worry for now. We will learn about it sooner.
Bag of words model
Assume that we have received this mail
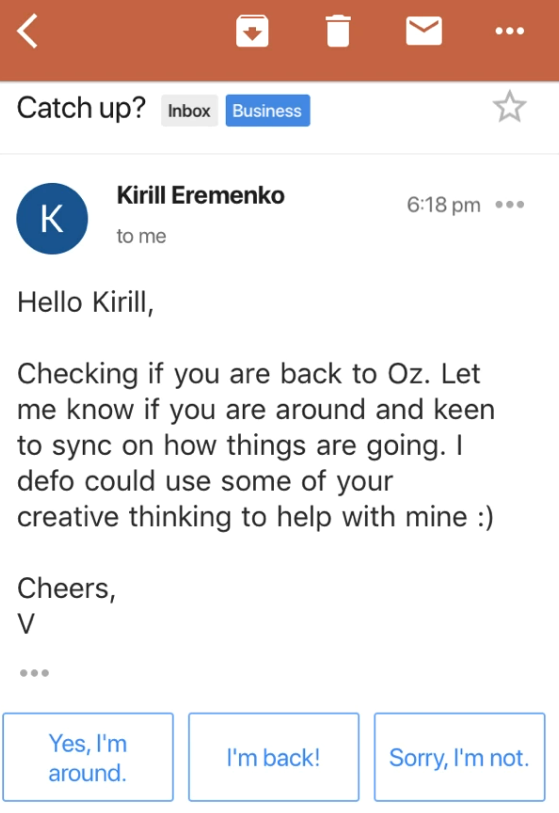
now you can see based on our mail, google already suggests some sentences like 'Yes, I am around' , 'Sorry I'm not'
Isn't this what bag of words is?
They automatically suggested some results.Just like the teacher mentioned great and the model suggests point 1 we saw earlier.
So let's take a target to get Yes/No

Let's take a list of 20k 0's because a person in general knows 20k words in general.
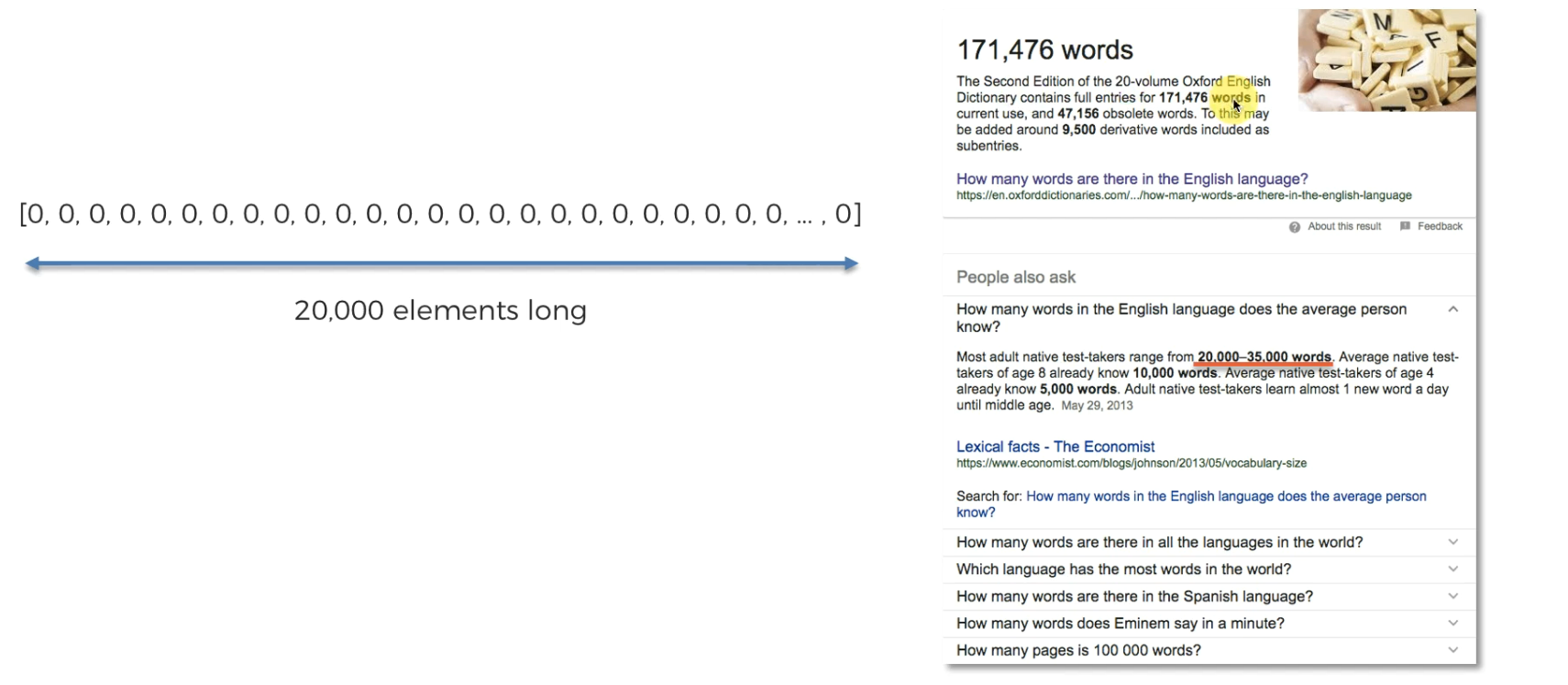
also , 3k words are most commonly used
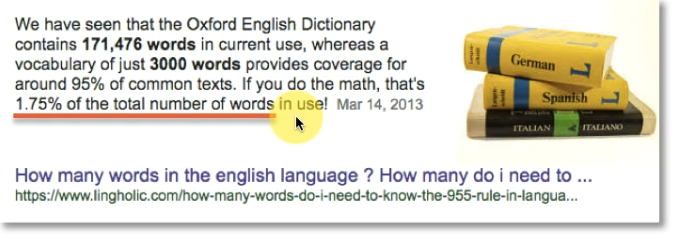
So, basically we will have every words possible in this list.

first 2 are kept start of sentence and then end of sentence and last is for all special words.
Let's fit the mail text to this list
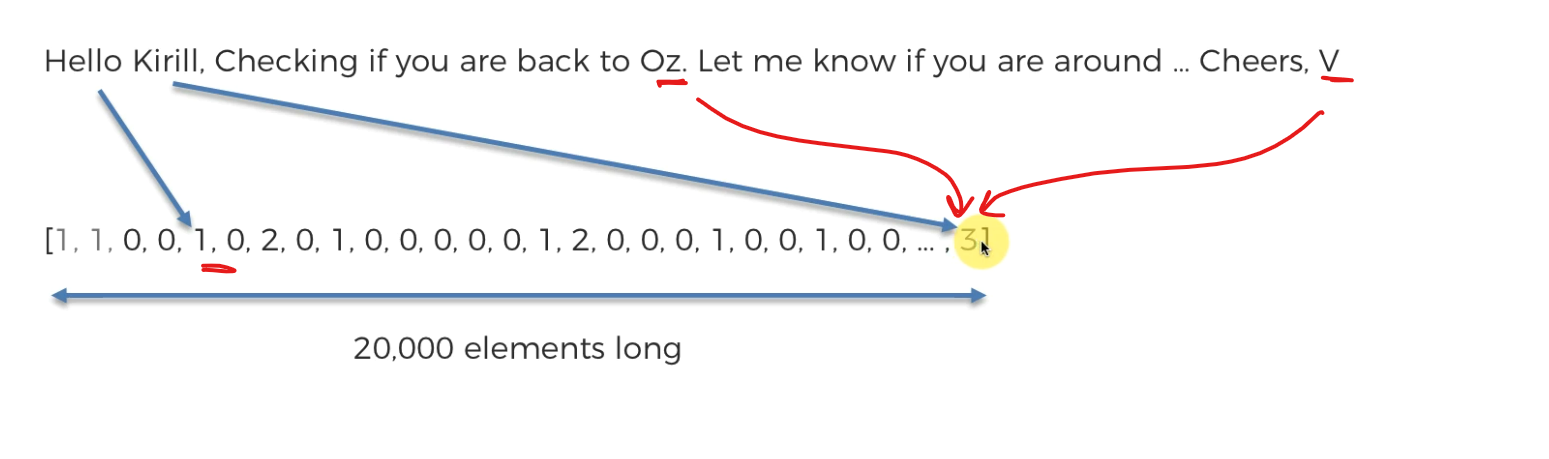
Here at position 5, we kept Hello word and as it's just 1 time in this sentence, the value is 1 there.
Also 'Kiril, Oz , V' are not English words and thus we count them as special words. So, kept at last and value is 3 as we have 3 words as special words.
and just like that, we can fill this whole list
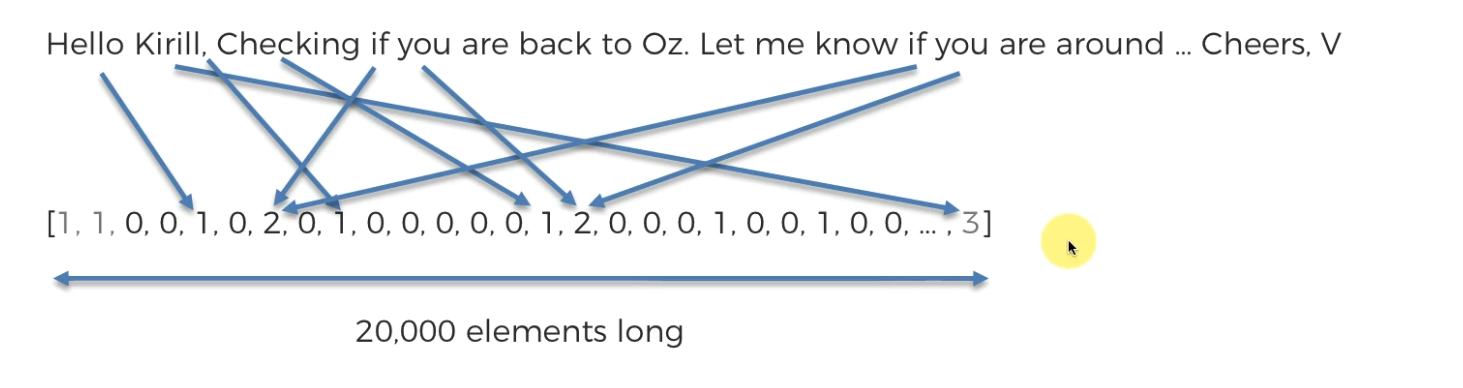
Our goal is to get yes/no by watching this list.
How can we do that?
We can check all of our mail replies previously given.

Now , we can turn those questions as list as well.

Now we can apply a model and depending on the model, we can guess what should be our answer for the recent mail.

How to do that?
we can apply "Logistic regression" and then use our list to know if we get "Yes" or "No". This is an example of 'NLP'
Or we can also use a Neural network to predict the answer.
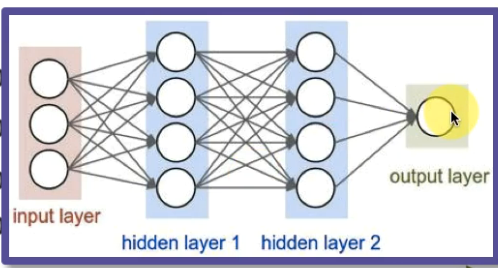
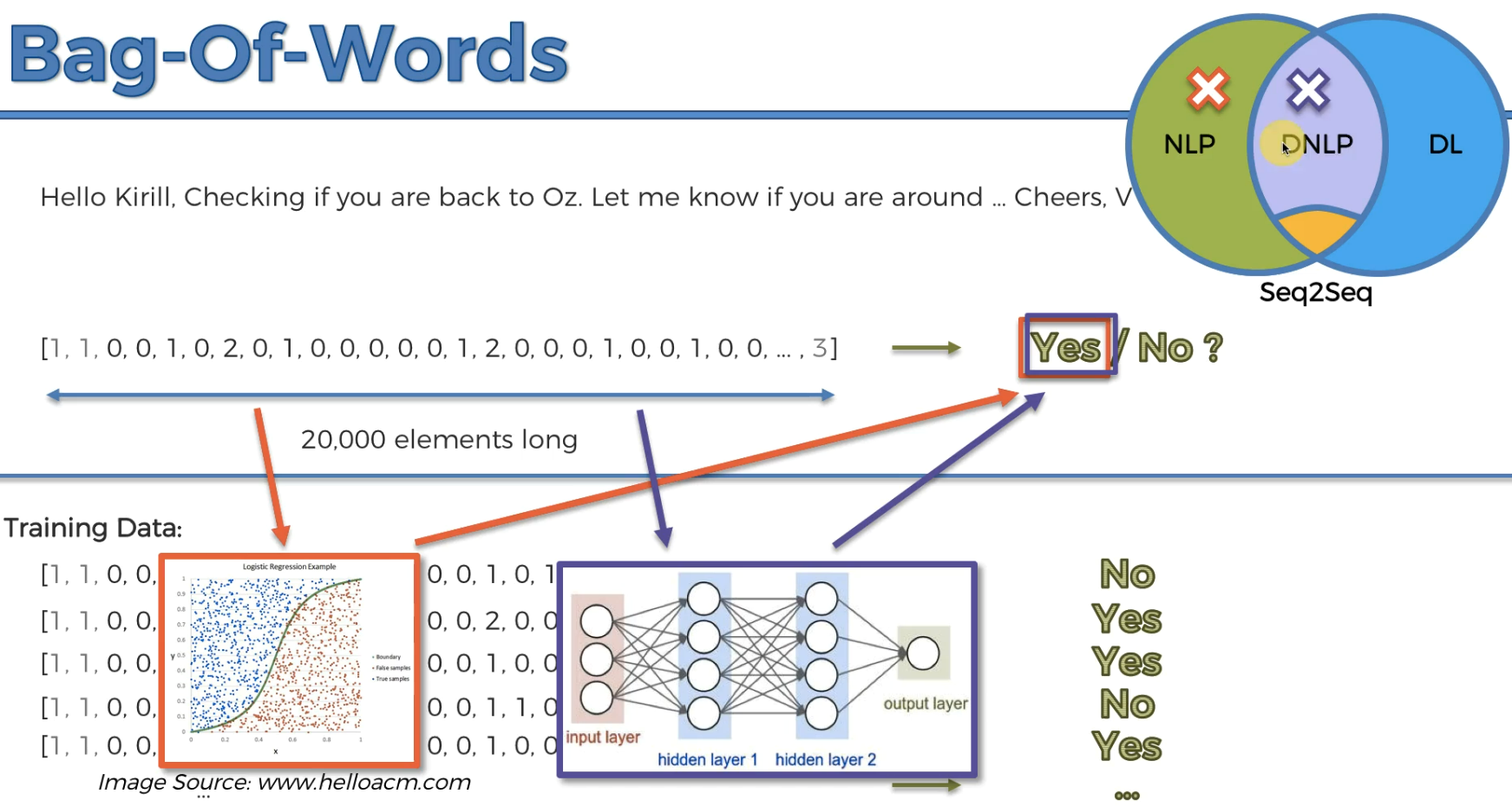
This is an example of Deep NLP as using Neural Networks.
Let's code this down.
This time we will use tsv files (separated by tabs) whereas previously we did use csv(separated by comma).
Why?
Because our input might have commas now. So, we have to be cautious.
Problem statement:

We have lots of texts and values which understand if we expressed like (1) or dislike (0)
Let's import the libraries

Importing the dataset
let's import the tsv file. we need to add delimiter='\t' to mean it's a tsv file separated by tabs and also to make sure the file can read things within "" inverted commas we will add
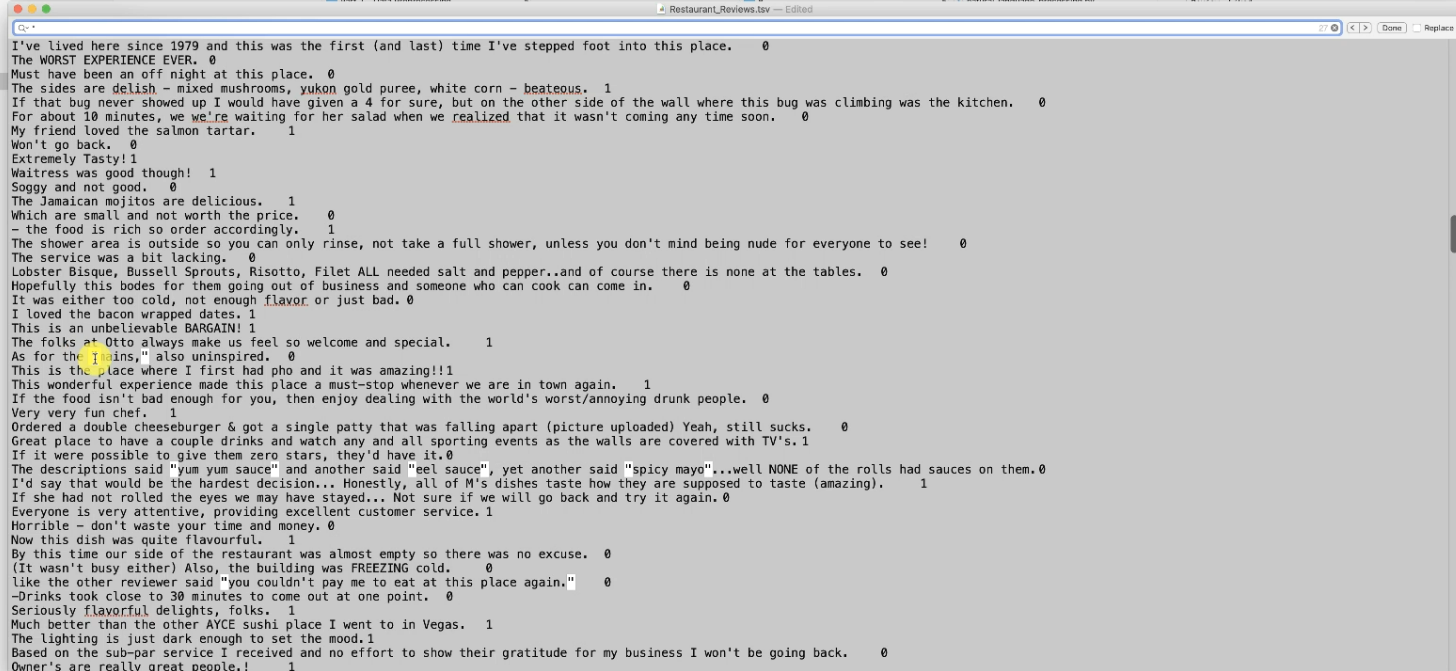
quoting =3

we have to clean the text and before that, we can't get X and Y matrix
#import libraries
import re #for regular expressions and work with texts
import nltk #Words we don't want help us getting any output. Example 'and' etc.nltk.download('stopwords') #let's download all of those words from nltk.corpus import stopwords #now import stopwords
from nltk.stem.porter import PorterStemmer ##if, we have 'oh I loved the hotel', it will turn that to 'love'#Meaning to have just the stem word which does not change the meaning.All clean sentences will be listed in corpus after removing stopwords, stemmed etc.
corpus= []
for i in range(0,1000): #we have 1000 reviews removing punctuation
review = re.sub('[^a-zA-Z]',' ',dataset['Review'][i])
To remove punctuations, we replace them (^ means anything not inside) with a space-> ' '. #^a-zA-Z Means all words not within a-z and A-Z #to get all values within the column 'Review', use dataset['Review'][i] review.lower()#review everything in lower words.stemming: To do that we need each words and then modify them to get only stem words.
review=review.split()
keeping sentence splitted to words.
ps=PorterStemmer() #stemming object.
review= [ps.stem(word) for word in review if not word in set(stopwords.words('english'))]
We are creating a list of all words in review "for word in review" . if not word in set(stopwords.words('english') means all the stopwords in english to be avoided. Now stem that using ps.stem(word)
review=' '.join(review)
This adds space to each word in review. Finally, addig all reviews to the corpus
corpus.append(review)
Once we have cleaned, we got this
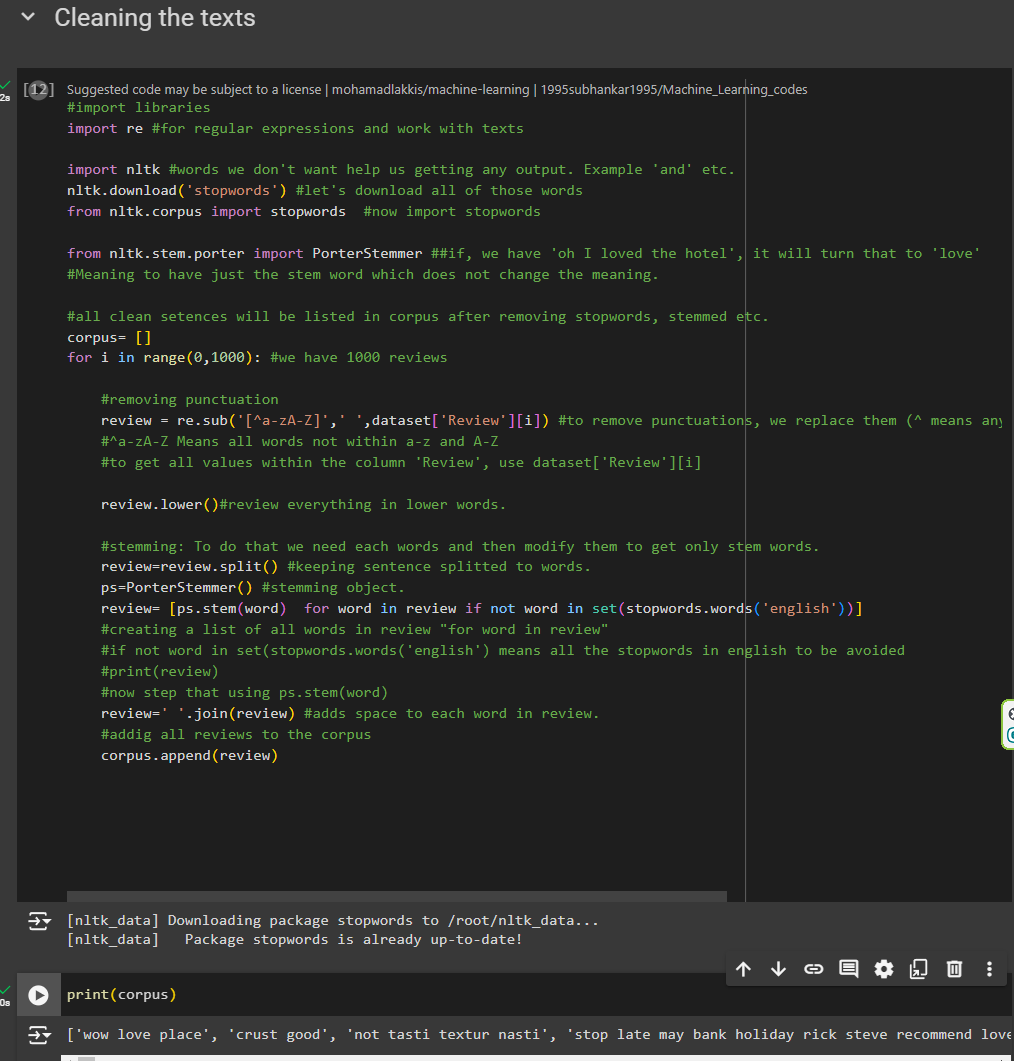
from here, we can see the corpus with sentences like 'wow love place' etc.
Whereas in the real dataset we had,

"Wow... Loved this place." This has turned to "wow love place"
all the words are in lower form and nothing unnecessary like full stops (.) and Loved has been lowered and stemmed to love.
Also, "Curst is not good' has been turned to 'crust good'
But here is an issue we saw and that is, crust not good should have been here but as we removed all stopwords, we eliminated that too.
So, let's list all_stopwords and don't include the word 'not'
all_stopwords=stopwords.words('english')
all_stopwords.remove('not') #removing not from stopwords because we have words like 'Crust is not good' which means an emotion here.
review= [ps.stem(word) for word in review if not word in set(all_stopwords)]
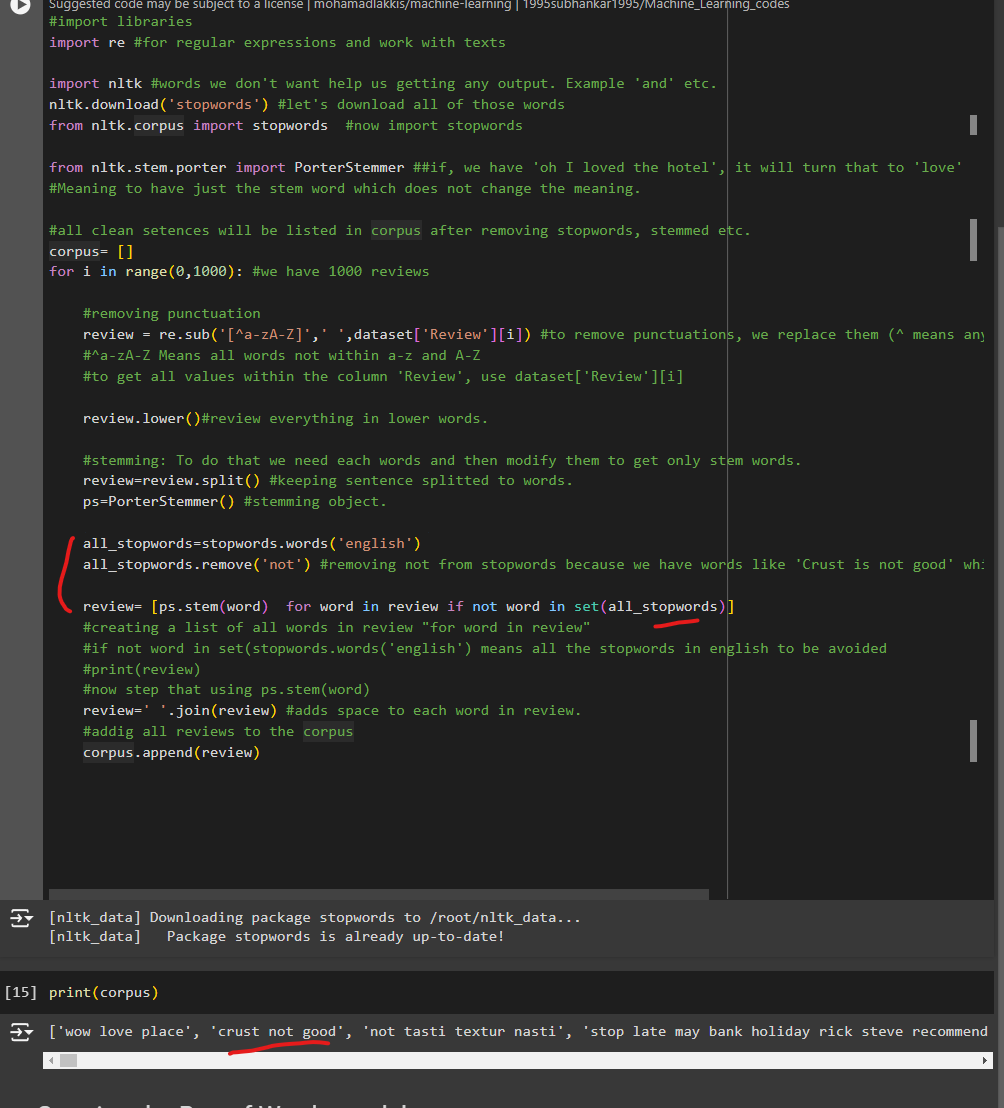
Now, we have got 'crust not good'
Creating the Bag model
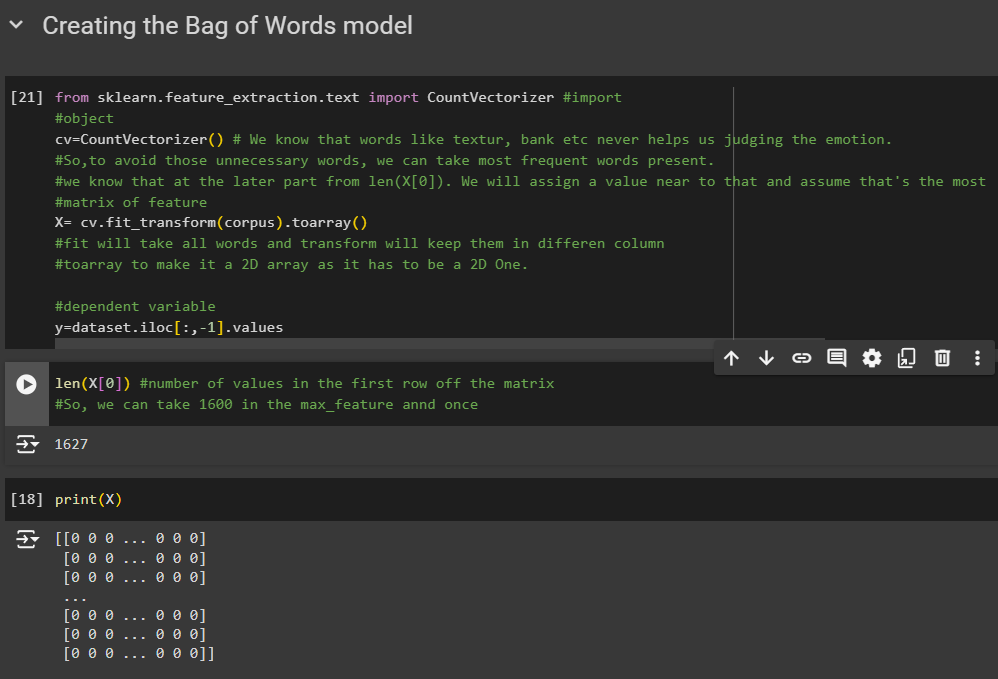
Importing
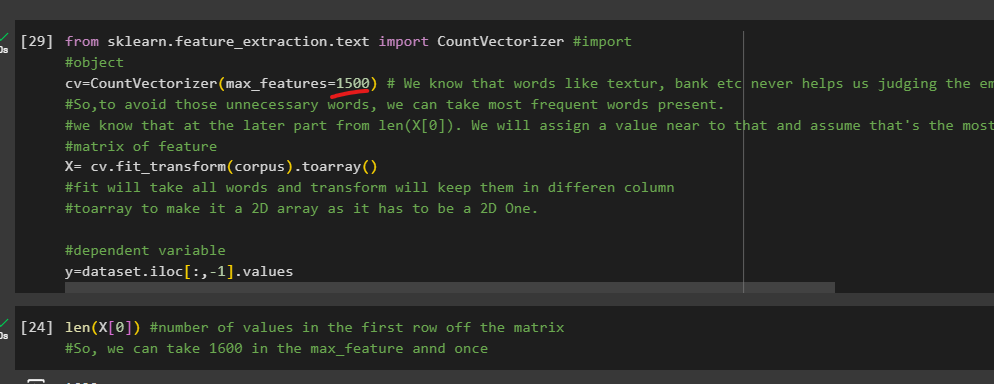
from sklearn.feature_extraction.text import CountVectorizer #import
Object creation
cv=CountVectorizer()
Her is an important part.We know that words like textur, bank etc never helps us judging the emotion. So,to avoid those unnecessary words, we can take most frequent words present.
Matrix of feature
X=cv.fit_transform(corpus).toarray()
This 'fit' will take all words and 'transform' will keep them in different column. toarray is used to make it a 2D array as it has to be a 2D One.
y=dataset.iloc[:,-1].values
y matrix takes all of the values of 'Liked ' column
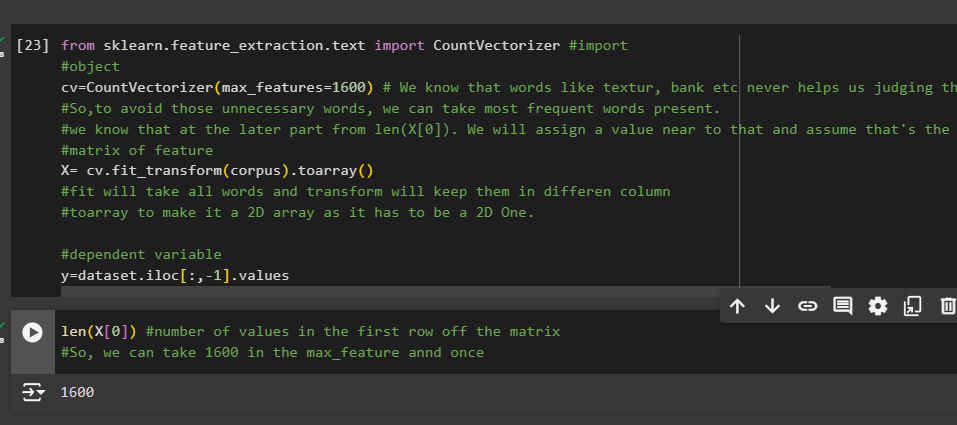
Then we check the length of values we have in first column of X which is 1627.
This is the most frequent words.
So let's use it at cv=Count......()
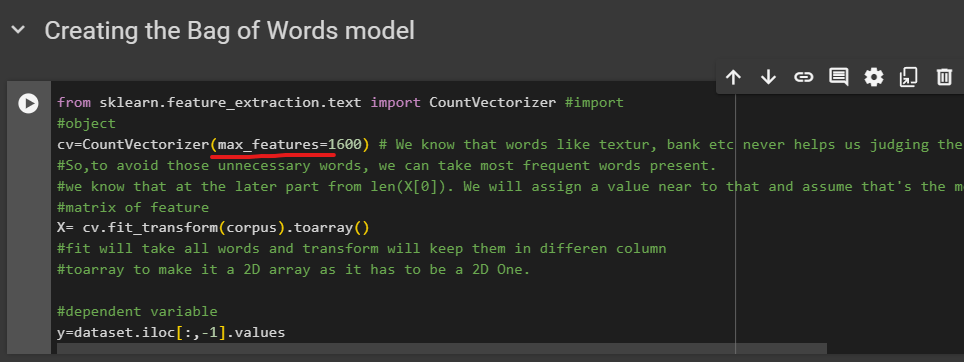
We have set value near 1627
Now , once we run this, event len(X[0]) will also have values limited to 1600
We splitt 20% of data as training data

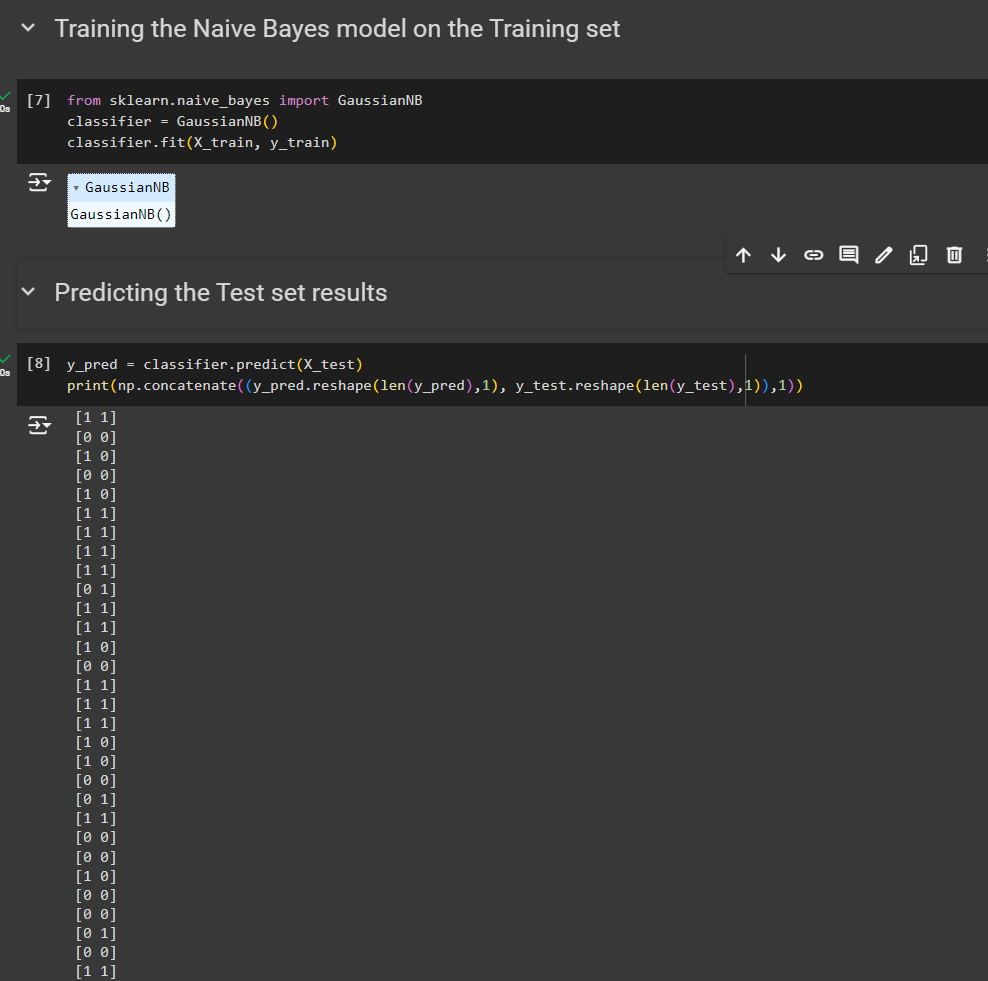
Then we can apply a model. Here we are using Naive Bayes model.
Just take this part from our previous .ipynb file
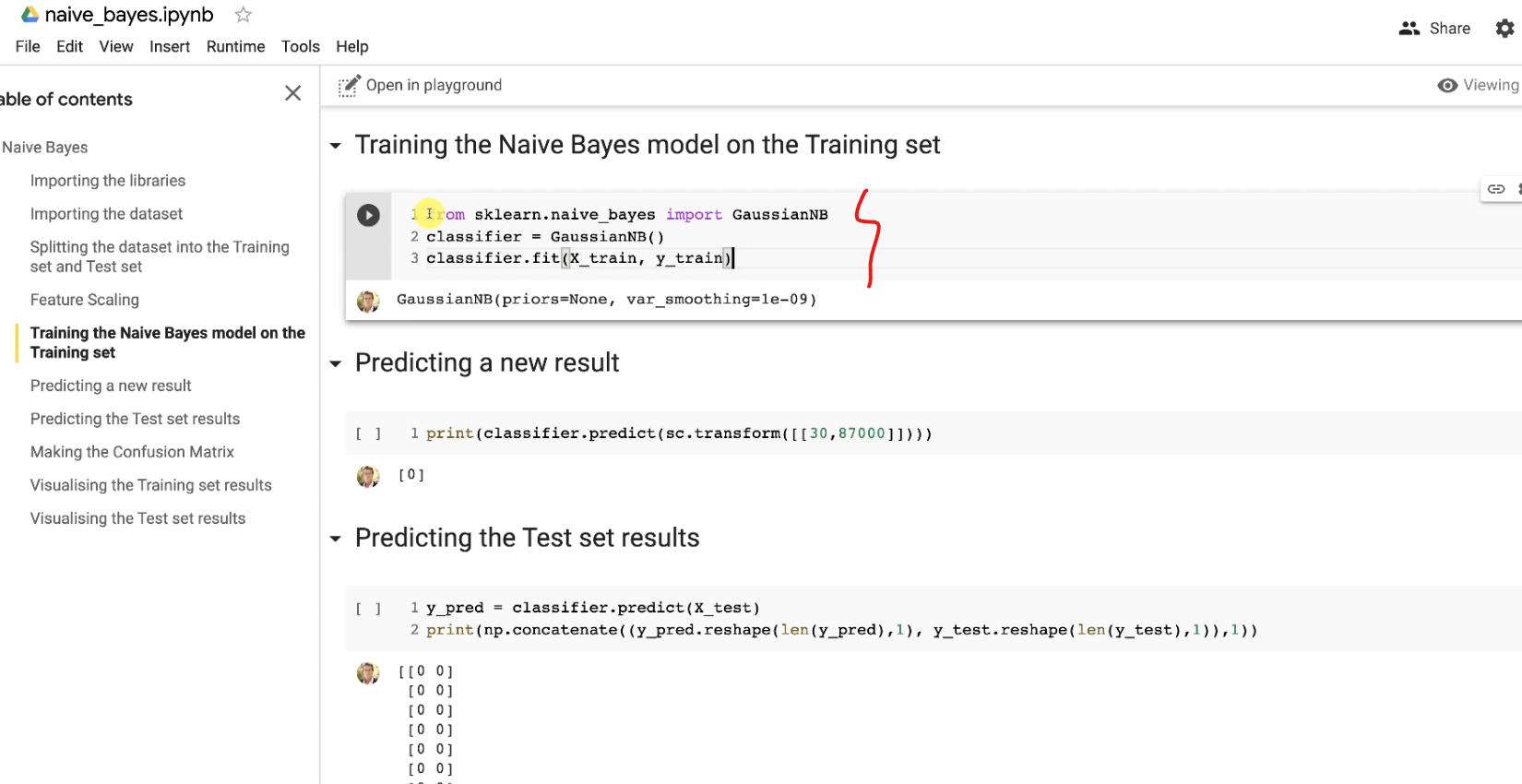
Check the blog on Naive Bayes
Also predicting the test set results
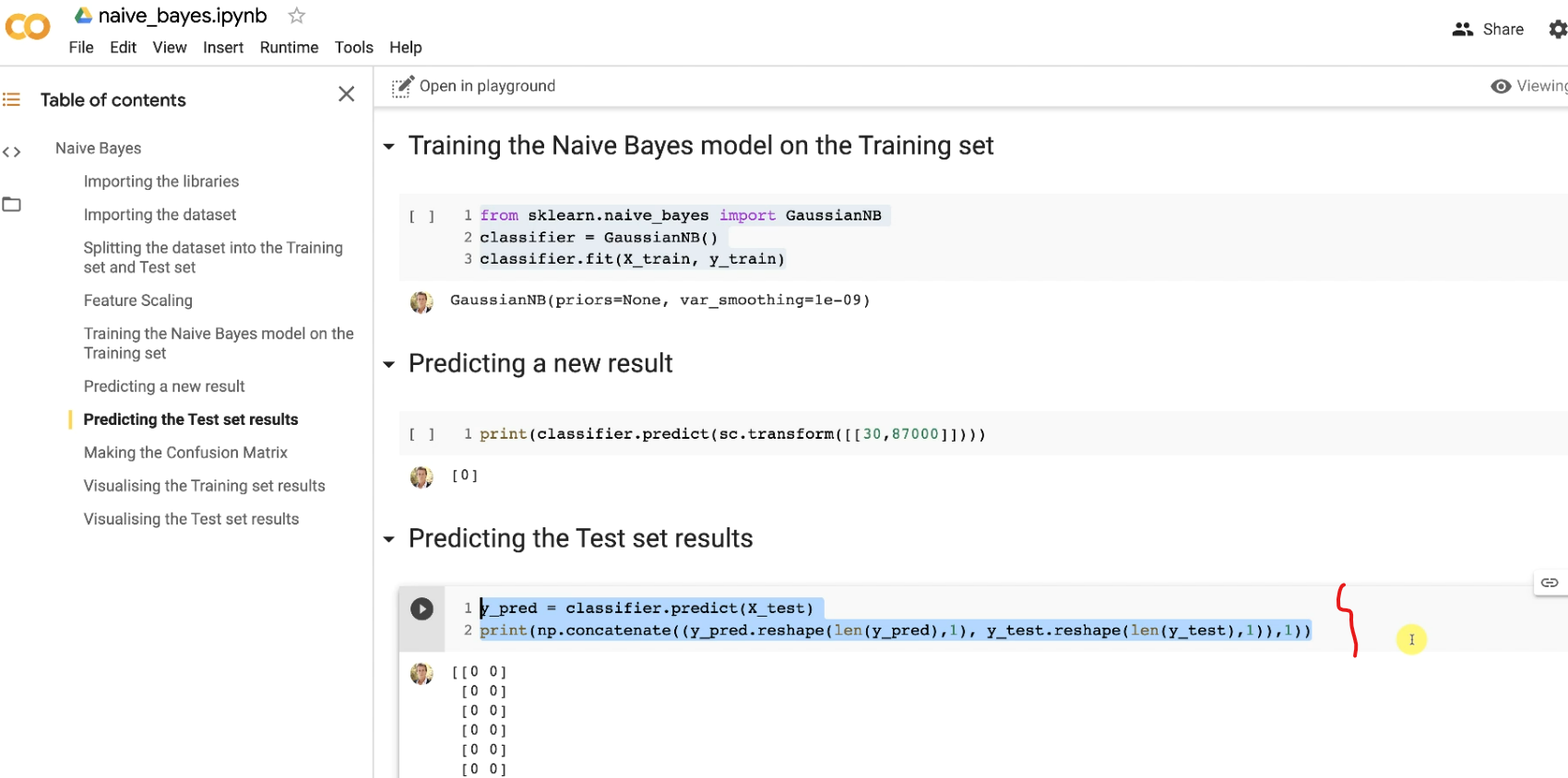
to be copied.
So, we end up like this
Finally we end up with the Confusion matrix which is also copied from the Naive bayes model
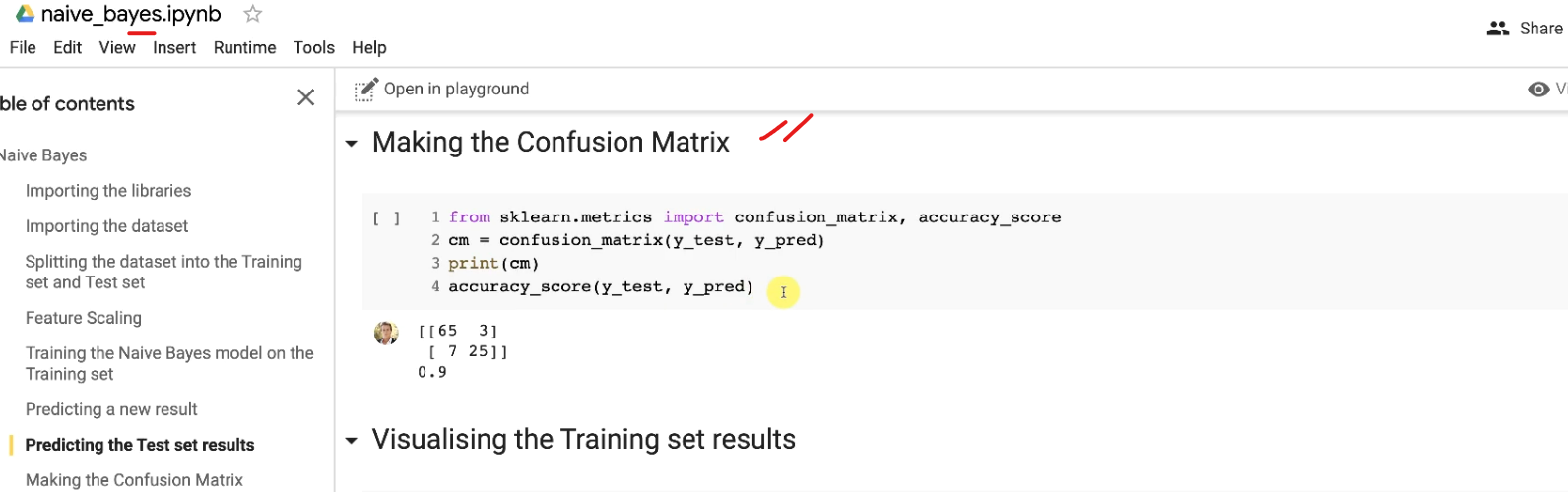
In our code:
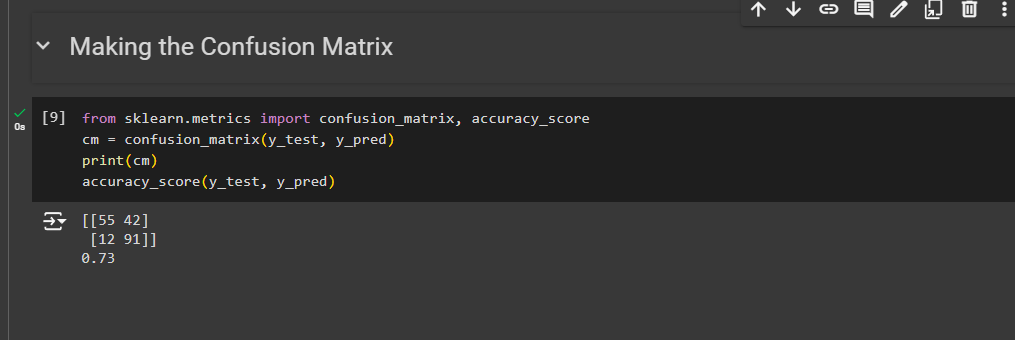
So, we have 73% of accuracy
Predicting if a single review is positive or negative
We will use our model to predict if the following review:
"I love this restaurant so much" is positive or negative.
new_review = 'I love this restaurant so much'
new_review = re.sub('[^a-zA-Z]', ' ', new_review) new_review = new_review.lower()
new_review = new_review.split()
ps = PorterStemmer()
all_stopwords = stopwords.words('english') all_stopwords.remove('not')
new_review = [ps.stem(word) for word in new_review if not word in set(all_stopwords)]
new_review = ' '.join(new_review)
new_corpus = [new_review]
new_X_test = cv.transform(new_corpus).toarray()
new_y_pred = classifier.predict(new_X_test)
print(new_y_pred)
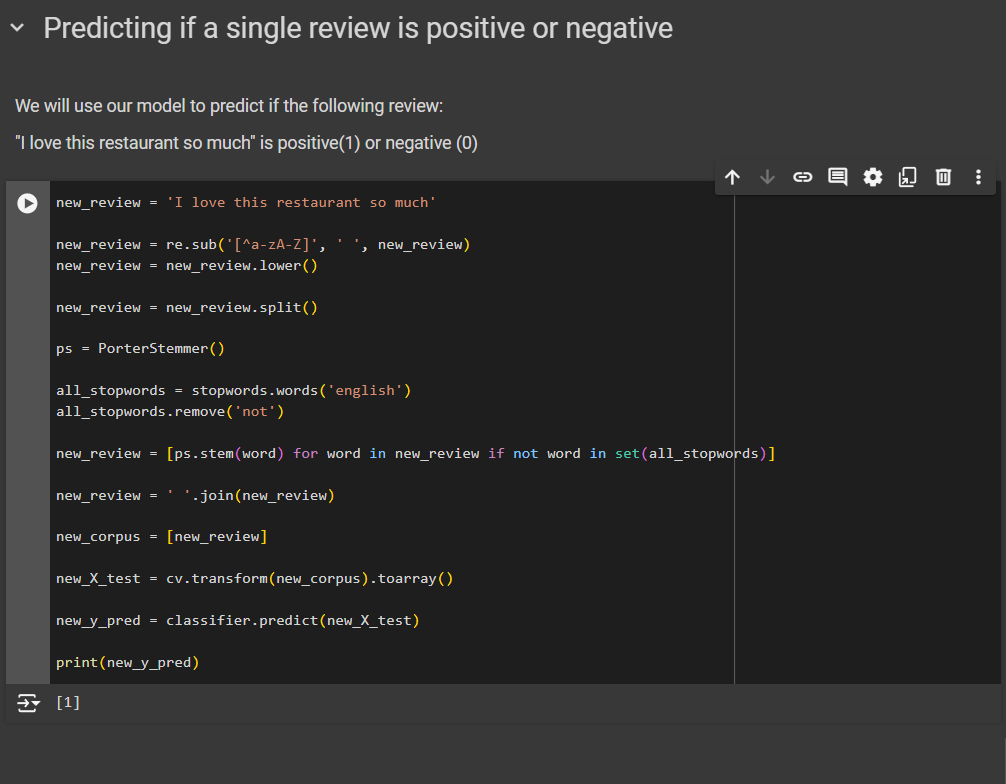
So, we can say that, ""I love this restaurant so much" is positive.
Note: While doing that, we had to set this to 1500 due to an error
if we train another sentence "I hate this restaurant so much"
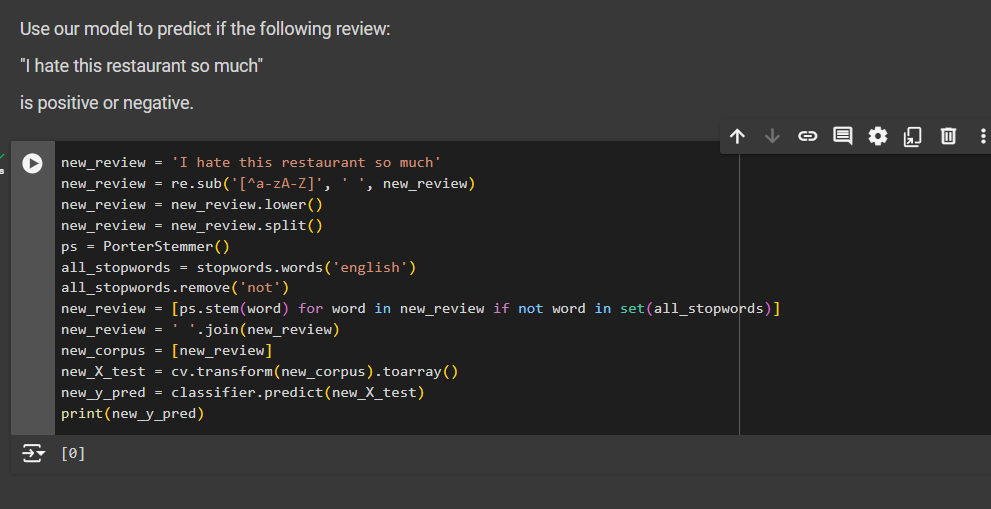
We see that sentence is negative as we got 0
Done!!
Subscribe to my newsletter
Read articles from Md Shahriyar Al Mustakim Mitul directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by