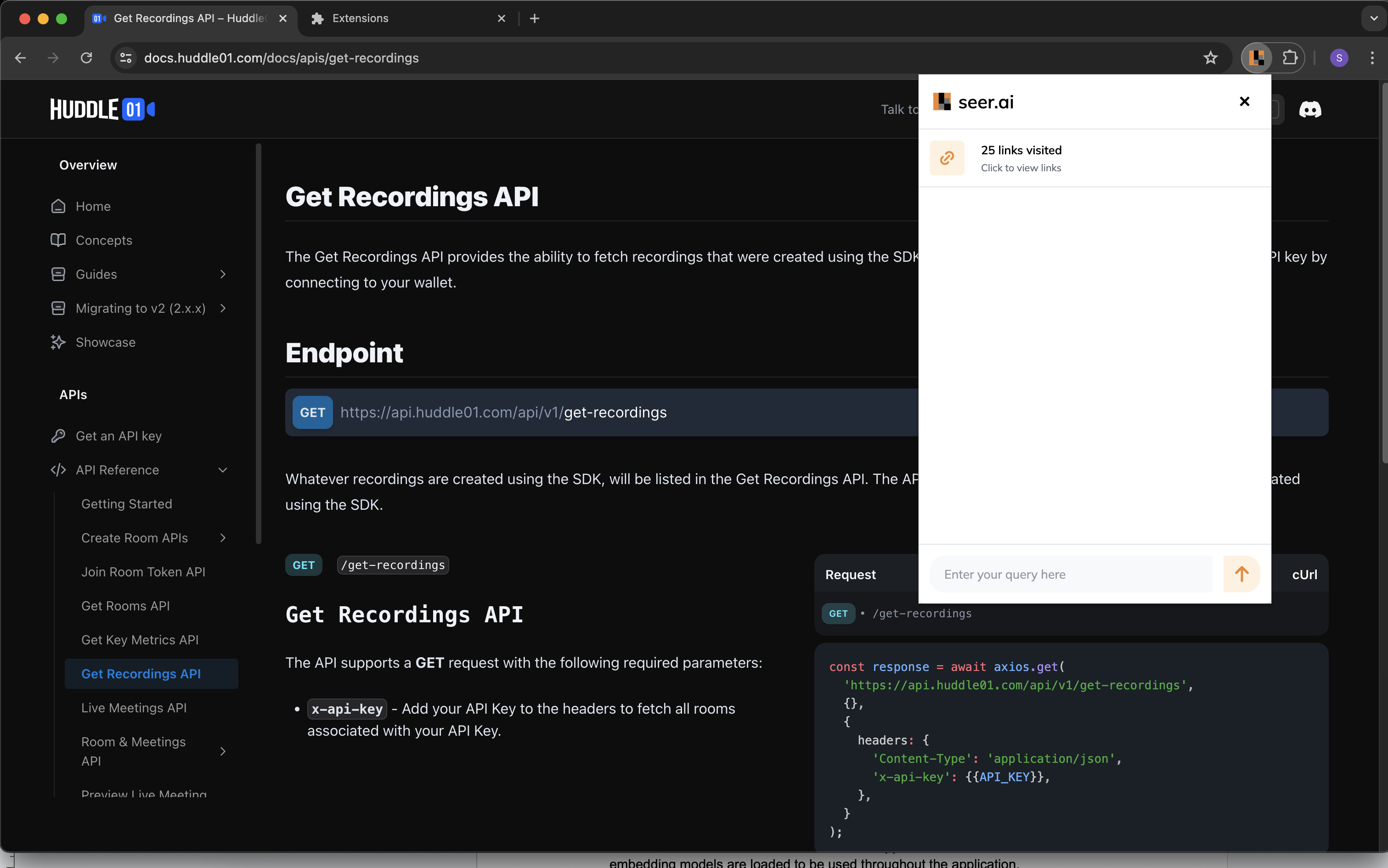
AI internet navigation assistant
 Satyam Singh
Satyam Singh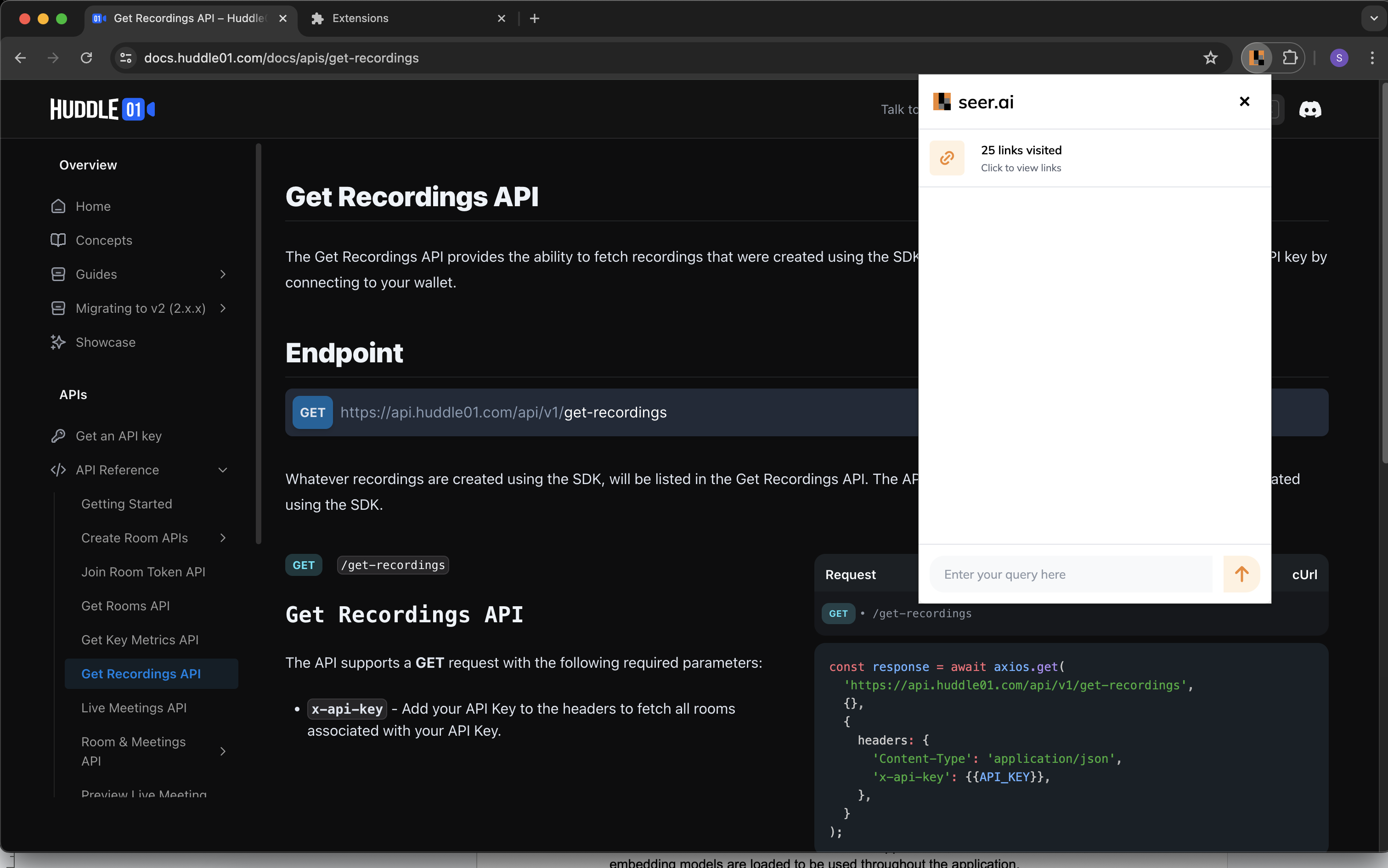
Inspiration
Back when I was applying for my Canadian visa, I had a lot of questions but didn't want to go through an agent and pay them my hard-earned money. At the same time, I didn't want to waste my time navigating those websites because they are complicated and it's hard to find the information I needed. Another problem I realized I was facing was finding the correct endpoints and arguments for a particular SDK at a hackathon. The fact that they are new makes it more difficult to navigate. So, we thought, why not build an extension that takes the latest information and, using RAG, helps us get the information we're looking for? Well, that's the Seer extension for you!
Overview
This project is a web application built with Flask, designed to perform web crawling, store extracted data, and enable search functionality using a vector database. It integrates various external services and libraries, including Pinecone for vector search, OpenAI for embeddings, and BeautifulSoup for web scraping.
Architecture
Environment Setup
- Environment Variables: The application loads environment variables using dotenv to securely manage sensitive information such as API keys.
Flask Application
Blueprints and Routes: The Flask application is modularized using Blueprints. It registers two main sets of routes, main and common, to handle different parts of the application.
Endpoints:
/crawl: Initiates the crawling process.
/status: Checks the status of a crawling task.
/search: Searches the vector database with a given query.
Detailed Sectional Breakdown
Initialization and Configuration
Flask App Initialization: The Flask app is instantiated and configured with necessary API keys from environment variables.
Global Resources Initialization: Within the app context, Pinecone is initialized, and embedding models are loaded to be used throughout the application.
Routes
/crawl Route:
Purpose: Starts the crawling process for a given URL up to a specified depth.
Process:
Accepts a JSON payload with start_url and optional depth.
Calls start_crawl to begin the crawling process and returns the response and status code.
It calls the crawl api from the frontend as soon as the user opens up the extension so that the users can get started as soon as they open up the extension!
/status Route:
Purpose: Retrieves the status of an ongoing or completed crawling task.
Process:
Accepts a task_id as a query parameter.
Calls get_crawl_status to get the current status and returns it as a JSON response.
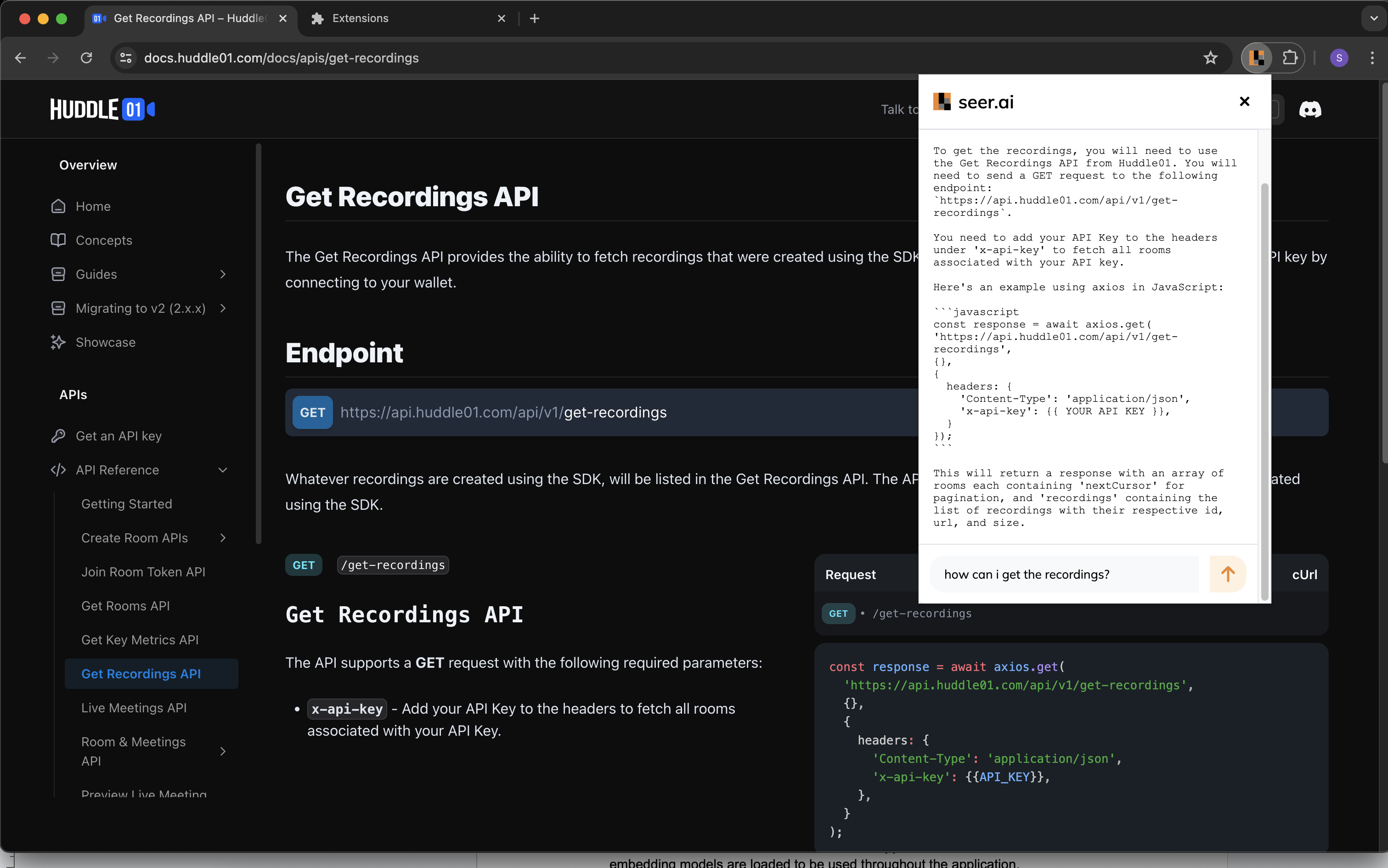
/search Route:
Purpose: Searches the vector database using a provided query.
Process:
Accepts a JSON payload with query.
Validates the query and calls search_with_query to perform the search.
Returns the search results as a JSON response.
Crawler Logic
Tasks Management: Manages tasks in an in-memory dictionary, tracking the status and visited URLs of each task.
Crawling Process:
Queue-based Crawling: Uses a queue to manage URLs to be crawled, with depth control to limit the extent of crawling.
Content Extraction: Extracts text content from web pages using BeautifulSoup and splits it into manageable chunks.
Vector Storage: Stores extracted text chunks as vectors in the Pinecone index.
Pinecone Integration
Embedding Generation: Uses OpenAI's API to generate embeddings for text content.
Index Management: Stores vectors in Pinecone and performs search queries.
Helper Functions:
get_embedding: Generates embeddings using OpenAI.
store_vectors: Stores document vectors in Pinecone.
search_with_query: Searches the Pinecone index with a query embedding.
Utility Functions
Text Chunking: Splits large text content into smaller chunks to fit within token limits.
Domain Checking: Ensures URLs being crawled are within the same domain to avoid unnecessary external links.
Error Handling and Retries: Implements retry logic for failed HTTP requests and error handling during the crawling process.
Workflow
Starting a Crawl:
User initiates a crawl through the /crawl endpoint with a start URL and optional depth.
The application assigns a unique task ID and starts the crawling process in the background.
The process extracts text, generates embeddings, and stores them in Pinecone.
Checking Status:
User queries the status of the crawl using the /status endpoint with the task ID.
The application returns the current status and visited URLs of the task.
Searching Data:
User submits a search query through the /search endpoint.
The application generates an embedding for the query and searches the Pinecone index for the most relevant results.
Results are returned as a JSON response.
RAG: Using the top 3 chunks based on the similarity it uses the RAG implementation to answer the query
Demo:
We created a working demo video as well that you can watch below!
Conclusion
This architecture provides a robust solution for web crawling and semantic search. It leverages powerful tools like Pinecone for efficient vector search and OpenAI for generating high-quality embeddings, while Flask serves as the backbone for the web application, coordinating the different components and handling user interactions.
You can check it out on the links below!
Subscribe to my newsletter
Read articles from Satyam Singh directly inside your inbox. Subscribe to the newsletter, and don't miss out.
Written by
Satyam Singh
Satyam Singh
Hello, I'm Satyam Hitendra Singh, a Computer Science major at the University of Regina. Currently a software developer intern @ FCC / FAC in Canada, previously have worked at Push Protocol and Froker, I'm passionate about technology and thrive in hackathon environments I've participated in 35 hackathons globally out of which I won 25. As a Project Lead at URGDSC and Vice President at UOFRCyberSecurity, I foster a collaborative tech community. I'm a technology generalist, exploring various tech realms, and love sharing my knowledge to help others navigate the tech world. Let's connect and explore the endless possibilities of technology together!